](https://deep-paper.org/en/paper/2511.06221/images/cover.png)
In the world of artificial intelligence, the dominant philosophy has long been “bigger is better.” Giants such as DeepSeek R1 (671B parameters) and Kimi K2 (over one trillion parameters) have defined cutting-edge reasoning capabilities, fueling an arms race toward scale. The prevailing belief? Complex reasoning is a playground for colossal models, and smaller ones simply can’t compete.
But what if that assumption is wrong?
What if a small, nimble model could think with the logical prowess of its massive counterparts?
A new technical report from Sina Weibo AI challenges that narrative, introducing VibeThinker-1.5B—a remarkably compact model built with just 1.5 billion parameters and a post-training cost below $8,000. Despite its size, it surpasses models hundreds of times larger on advanced math and coding benchmarks, rivaling commercial giants such as OpenAI’s o3-mini and Anthropic’s Claude Opus.
This isn’t a story of brute-force scaling. It’s a story of smart, efficient training. The secret lies in a novel methodology called the Spectrum-to-Signal Principle (SSP)—a paradigm that rethinks the post-training process from first principles.
In this article, we’ll unpack the core ideas behind VibeThinker-1.5B, explain how SSP works, and explore why this breakthrough could redefine the future of reasoning models.
Background: Building Blocks of a Reasoning Model
Before exploring the innovations of SSP, we need to understand the two pillars of model post-training: Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). These phases transform a general-purpose model into a capable reasoner.
Supervised Fine-Tuning (SFT)
Supervised Fine-Tuning adapts a pretrained model to specific tasks using labeled examples—such as math problems and their step-by-step answers. The goal is to minimize cross-entropy loss, effectively teaching the model to generate high-probability correct responses.
\[ \mathcal{L}_{\mathrm{SFT}}(\theta) = \mathbb{E}_{(x,y)\sim \mathcal{D}}\left[ -\log \pi_{\theta}(y|x) \right] \]Here, \( \pi_{\theta}(y|x) \) denotes the model’s probability of producing the correct answer \( y \) given \( x \).
Reinforcement Learning and GRPO
Once SFT establishes basic competence, Reinforcement Learning (RL) refines it through trial and reward. The model generates candidate outputs, assigns them scores via a reward function, and updates its parameters to favor high-reward results.
VibeThinker employs a variant called Group Relative Policy Optimization (GRPO). Instead of using a separate “critic” model, GRPO compares responses within a group sampled from the model’s own distribution. Each receives an advantage computed relative to the group’s mean reward:
\[ A_{i,t}(q) = \frac{r_i - \mu_G}{\sigma_G} \]This reduces variance and stabilizes training, allowing improvement without an external critic network.
Measuring Progress: Pass@K and Diversity
Complex reasoning tasks often allow multiple solutions. To evaluate exploration ability, researchers use Pass@K—the probability that at least one of \( K \) generated answers is correct.
\[ \operatorname{Pass}@K = \mathbb{E}_{x \sim \mathcal{D}, \{y_i\}_{i=1}^k \sim \pi_{\theta}(\cdot | x)}\!\left[\max\{R(x,y_1), \ldots, R(x,y_k)\}\right] \]High Pass@K means the model explores many possible reasoning paths—a direct measure of diversity. A model that produces varied hypotheses learns faster and uncovers better solutions.
The Core Idea: The Spectrum-to-Signal Principle (SSP)
Traditional pipelines optimize SFT for accuracy (Pass@1), then use RL to push that metric even higher. The result is often myopic optimization—a model that memorizes narrow solution patterns and struggles with novel reasoning.
The Spectrum-to-Signal Principle rethinks this relationship entirely.
Spectrum Phase (SFT): Instead of locking onto single solutions, the SFT stage cultivates a rich spectrum of plausible answers across diverse reasoning paths. The training explicitly maximizes Pass@K, not Pass@1—laying a foundation of varied, creative problem-solving routes.
Signal Phase (RL): Reinforcement Learning zooms into this spectrum, identifying the most effective patterns—the signal—and amplifying them via rewards. The RL algorithm learns which reasoning paths lead to success and increases their generation probability.
The result: RL works on a more fertile landscape of candidate solutions, pushing performance far beyond traditional pipelines.
The VibeThinker-1.5B Training Pipeline
This philosophy is encapsulated in a meticulous two-stage training framework shown below.
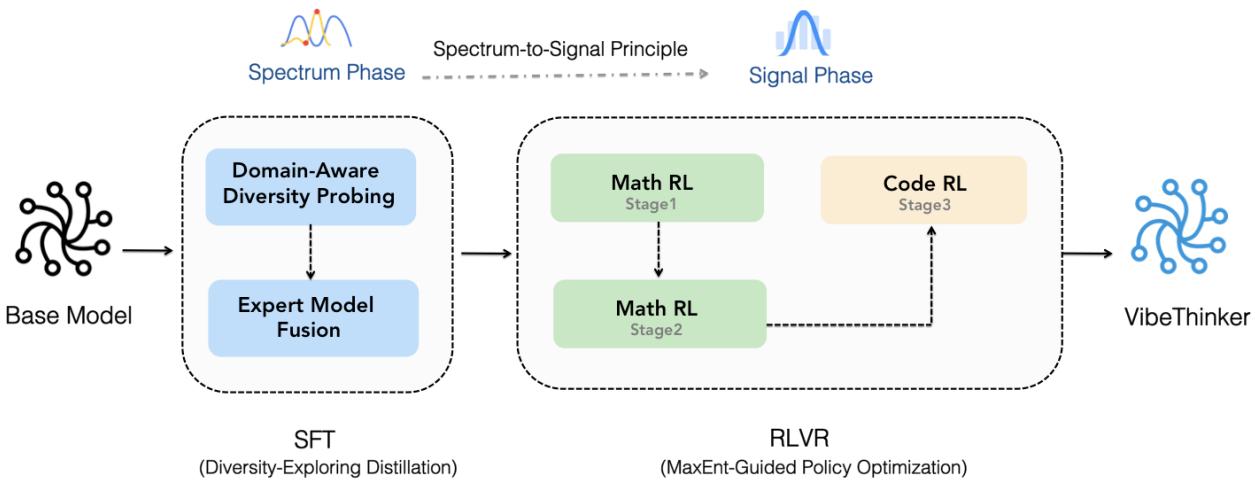
Figure 3. The Spectrum-to-Signal training pipeline: diverse spectrum creation during SFT followed by targeted signal amplification during RL.
Phase 1: Diversity-Exploring Distillation — Building the Spectrum
The goal of this stage is to train a diversity-rich model.
Domain-Aware Diversity Probing Mathematics comprises distinct subfields—algebra, geometry, calculus, statistics. The team fine-tuned the base model across these subdomains, saving intermediate checkpoints. Each was evaluated by Pass@K, identifying the checkpoint that best captured diverse reasoning for each subdomain:
\[ M_i^* = \arg\max_t P_i(t) \]The result: several “specialist” models, each tuned for diversity in a particular domain.
Expert Model Fusion These specialist models were merged into a unified SFT model through parameter averaging:
\[ \mathbf{M}_{\mathrm{Merge}}^{\mathrm{SFT}} = \sum_{i=1}^{N} w_i M_i^*, \quad w_i = \tfrac{1}{N} \]The merged model retained the most diverse capabilities from all subdomains—a wide spectrum ready for the RL phase.
Phase 2: MaxEnt-Guided Policy Optimization — Amplifying the Signal
Once the spectrum of solutions was built, RL refined it using MaxEnt-Guided Policy Optimization (MGPO)—a principled approach that identifies which problems the model learns most from.
Learning at the Edge
The most educational problems are those where the model’s correctness rate \( p_c(q) \) is around 50%—maximal uncertainty. Easy problems teach nothing; impossible ones provide no signal. MGPO uses this insight to prioritize informative samples.
\[ p_c(q) = \frac{1}{G}\sum_{i=1}^{G}\mathbb{I}(r_i = 1) \]Entropy Deviation Regularization
To quantify closeness to the ideal uncertainty (0.5), the researchers compute a Max-Entropy Deviation Distance:
\[ D_{\text{ME}}(p_c(q) \| p_0) = p_c(q)\log \frac{p_c(q)}{p_0} + (1-p_c(q))\log \frac{1-p_c(q)}{1-p_0}, \quad p_0=0.5 \]They then assign each problem a weight:
\[ w_{\text{ME}}(p_c(q)) = \exp(-\lambda \cdot D_{\text{ME}}(p_c(q)\|p_0)) \]Problems near 50% correctness receive high weight; those near 0% or 100% are downweighted. The adjusted advantage becomes:
\[ \mathcal{A}'_{i}(q) = w_{\mathrm{ME}}(p_{c}(q)) \cdot \mathcal{A}_{i}(q) \]This creates an implicit curriculum, automatically focusing learning on the frontier of the model’s uncertainty—where reasoning skills progress fastest.
Results: A Tiny Model’s Giant Leap
Unprecedented Cost Efficiency
Training VibeThinker-1.5B cost under $8,000—just 3,900 GPU hours on NVIDIA H800s. Comparable large reasoning models exceed $250,000 in training costs.

Figure. VibeThinker achieves state-of-the-art reasoning at a fraction of the cost, highlighting the impact of efficient design.
Such frugality doesn’t come at the expense of capability. The model reaches a score of 74.4 on AIME 2025, beating DeepSeek R1 (671B) with 70.0, while consuming <2% of its compute budget.
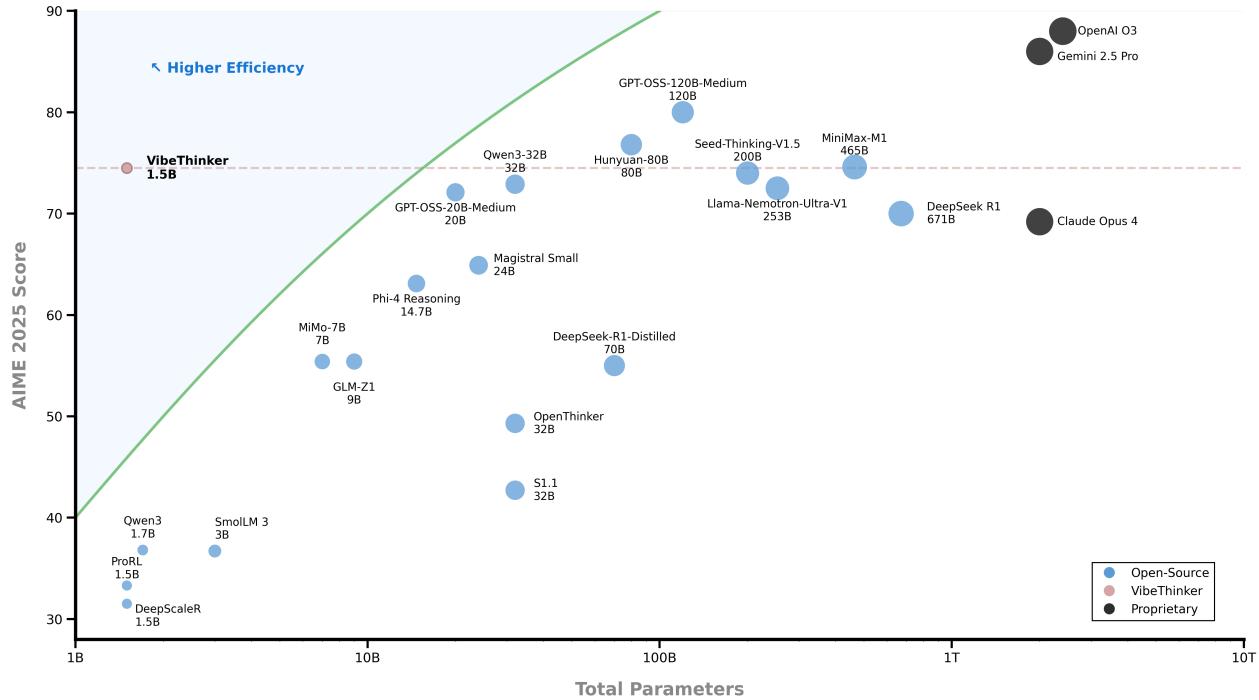
Figure 2. Performance vs. scale—VibeThinker sits in the “high-efficiency” region, outperforming models hundreds of times larger.
Dominating the Small-Model Arena
Among sub‑3B reasoning models, VibeThinker-1.5B redefines what “small” can achieve. Its scores jumped dramatically compared to its base model, Qwen2.5‑Math‑1.5B:
- AIME25: 4.3 → 74.4
- HMMT25: 0.6 → 50.4
- LiveCodeBench: 0.0 → 51.1
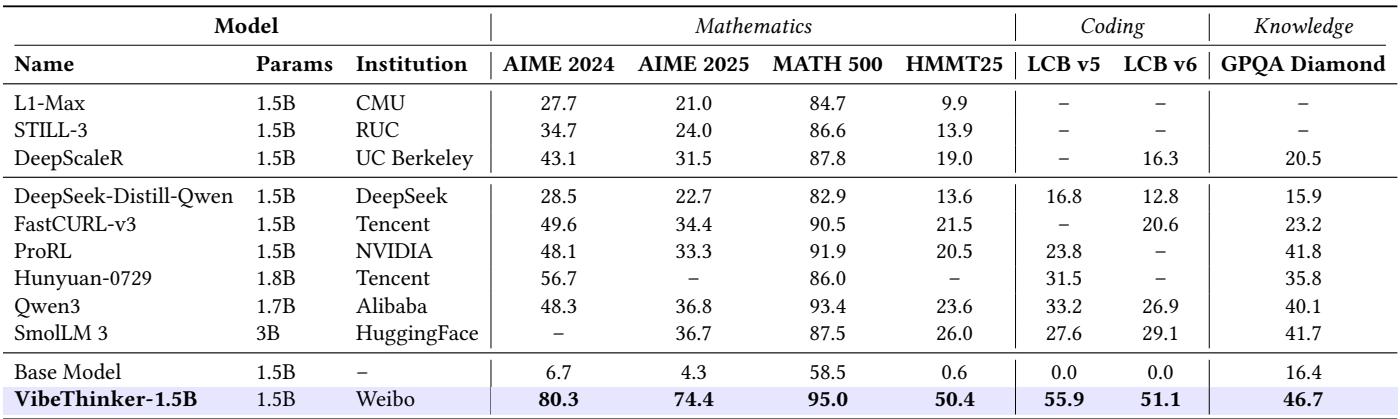
Figure. VibeThinker exceeds every other sub‑3B reasoning model benchmark—showing that careful training design rivals raw scale.
Challenging the Giants
When compared to industry leaders, VibeThinker‑1.5B performs astonishingly well.
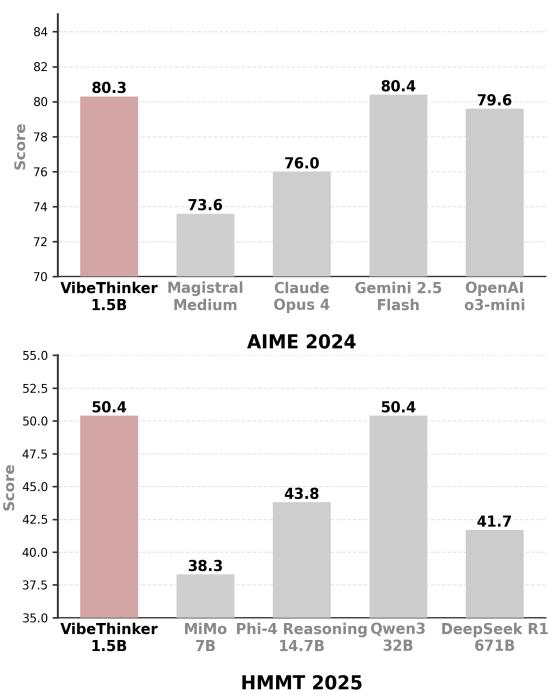
Figure 1. Benchmark comparison across AIME and LiveCodeBench tasks—VibeThinker matches or surpasses much larger reasoning models.
It outperforms DeepSeek R1 on all major math benchmarks and rivals or exceeds commercial reasoning models like Magistral Medium and Claude Opus 4.
- AIME24: 80.3 vs. 79.8 (DeepSeek R1)
- AIME25: 74.4 vs. 70.0
- HMMT25: 50.4 vs. 41.7
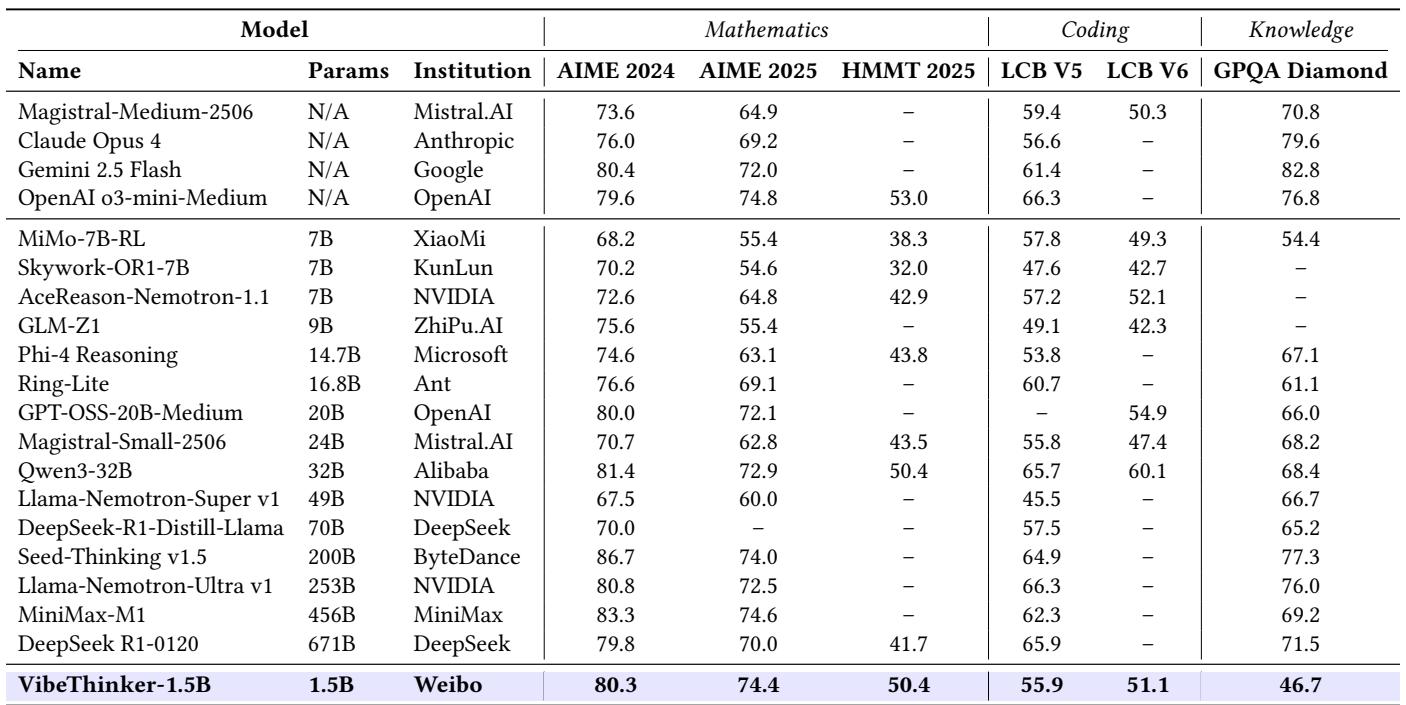
Figure. Despite its compact design, VibeThinker attains parity with or surpasses much larger reasoning systems.
Even against non-reasoning giants—such as Kimi K2 (1T parameters) and GPT‑4.1—VibeThinker maintains superior mathematical and coding scores.
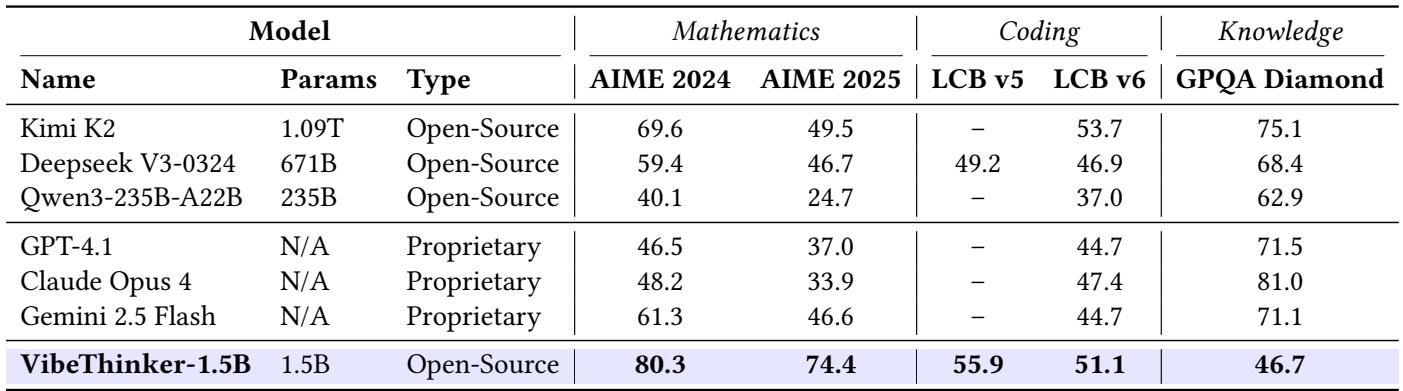
Figure. On math and code benchmarks, VibeThinker outperforms general-purpose models hundreds of times its size.
Limitations and Future Work
VibeThinker’s brilliance lies in structured reasoning. On encyclopedic knowledge benchmarks like GPQA, it lags behind large models by 20–40 points, reflecting the inherent trade-off between reasoning depth and broad factual coverage.
Nevertheless, the authors emphasize that algorithmic innovation can offset much of the scaling disadvantage, and future small models may integrate retrieval or modular memory systems to close this knowledge gap.
Conclusion: A New Path Forward
VibeThinker‑1.5B isn’t just a technical success—it’s a philosophical shift. It proves that intelligent algorithmic design can unlock reasoning capacity once thought exclusive to trillion‑parameter models.
Key implications:
Rethinking Scaling Laws: Reasoning prowess no longer scales linearly with size. Concepts like SSP offer new pathways to capability without exponential compute.
Democratizing AI Research: By achieving state‑of‑the‑art performance for under $8K, this work opens advanced reasoning research to universities, startups, and independent labs worldwide.
Efficient and Accessible AI: Small models drastically reduce inference costs and can run powerful reasoning tasks on local or edge devices—phones, cars, and embedded systems.
VibeThinker‑1.5B signals a new era: one where clever design beats sheer scale. It reminds us that in AI reasoning, big logic doesn’t depend on big parameters.