](https://deep-paper.org/en/paper/2511.06251/images/cover.png)
From Static Mockups to Working Prototypes
Imagine you’re a front-end developer handed a polished design mockup. Converting that picture into a fully working site—HTML for structure, CSS for style, JavaScript for behavior—is often a grind of repetitive work. Modern vision-language models (VLMs) can already produce markup that looks right, but most of what they generate is a visual “shell”: buttons that look clickable, menus that look drop-down, and forms that look fillable—yet don’t actually respond to user actions.
WebVIA, a recent research contribution, confronts that gap head-on. Instead of treating UI-to-code as a single-shot image-to-markup problem, WebVIA adds agency: an exploration agent first interacts with a UI to discover states and transitions, a UI2Code model uses those multi-state observations to synthesize executable interactive code, and a validation module automatically tests the resulting interface. The result: code that not only looks like the design but also behaves like it.
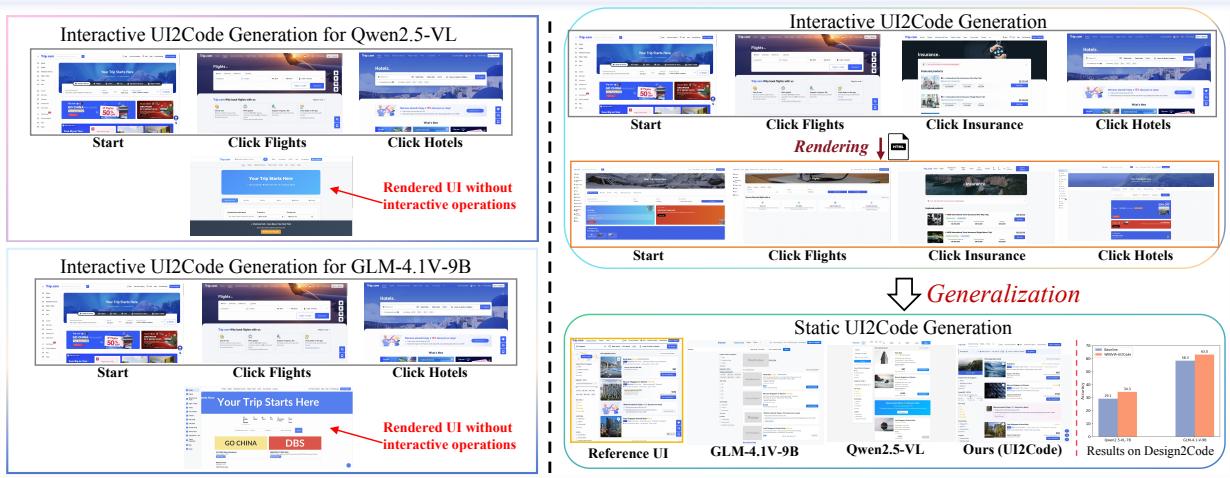
Figure 1: Motivating example illustrating the gap between static and interactive code generation. Static generators reproduce appearance but not behavior; WebVIA aims to capture both.
This article unpacks WebVIA’s ideas, design choices, datasets, and experimental evidence. If you build UIs or work on model-driven code generation, this walkthrough will show why exploration + multimodal supervision is a practical route toward interactive, verifiable UI synthesis.
Why static outputs fall short
Most UI-to-code systems are trained to reconstruct a single screenshot. That approach produces good pixel-level fidelity and plausible markup, but it cannot learn event wiring and multi-state behaviors: opening a modal, toggling tabs, showing/hiding elements, or updating content after a form submission.
Contrast that with how humans build UIs: we interact with the interface, observe consequences, and reason about the state machine underneath. WebVIA mirrors this process: make the model explore, capture the state graph, learn how states map to code, then verify that the produced code supports the same transitions.
The WebVIA pipeline — explore, generate, validate
WebVIA is an end-to-end framework with three tightly coupled components:
- Exploration agent (WebVIA-Agent) — interact with webpages to discover UI states and transitions.
- UI2Code model (WebVIA-UI2Code) — consume the interaction graph (multi-state screenshots + DOM snapshots + actions) and generate executable HTML/CSS/JavaScript (React/Tailwind in their setup).
- Validation module — execute the generated page and re-run the interaction traces to confirm behavioral parity.
The conceptual pipeline is illustrated below.
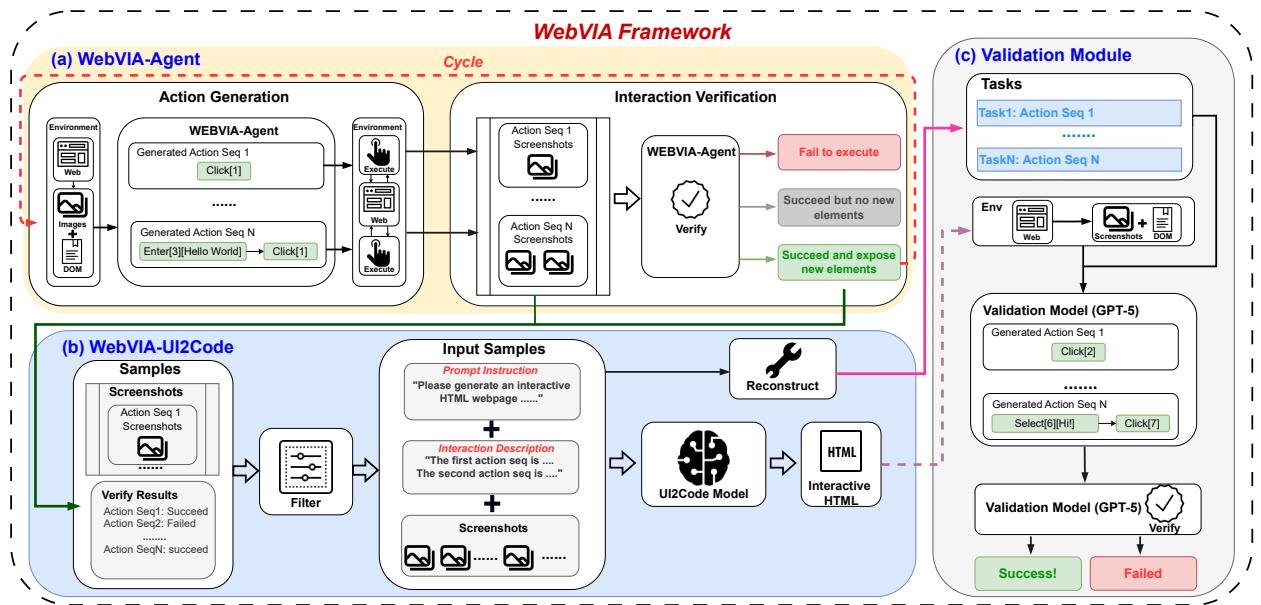
Figure 2: Overview of the WebVIA framework. The pipeline cycles from agentic exploration to code generation and task-based validation.
Let’s look at each piece in depth.
Part 1 — Exploration agent: perceive, act, verify
At the heart of WebVIA is a trained exploration agent. Treat the webpage as an environment \(\mathcal{E}\). At step \(t\) the agent observes a multimodal state \(s_t = (I_t, D_t)\) where \(I_t\) is a screenshot and \(D_t\) is a DOM snapshot. The agent proposes an action \(a_t\) (click, enter text, select), executes it in the browser, observes \(s_{t+1}\), and verifies whether the action produced a meaningful transition.
Key design choices:
- Action generation is conditioned on the current state and the agent’s trajectory history. Actions can be primitives (a single click) or short workflows (enter text then submit).
- Interaction verification compares screenshots and DOMs to classify outcomes into: failed/no-op, succeeded but no new elements, succeeded and revealed new interactive elements.
- Exploration strategy hybridizes breadth-first coverage (try many visible elements) with depth-first follow-through (expand promising multi-step flows).
The agent incrementally constructs an interaction graph \(\mathcal{G} = (\mathcal{S}, \mathcal{T})\): nodes are discovered states and edges are verified transitions. That graph becomes the rich multimodal input for the code generator.
Why verification matters: without it, agents loop on redundant clicks (low precision) or suggest every visible element (high recall but low utility). Verification prunes ineffective actions and focuses data collection on meaningful state changes.
Part 2 — UI2Code: from interaction graphs to executable front ends
The UI2Code model’s input is not a single screenshot but a structured interaction graph: multiple screenshots (states), the DOM snapshots, and the validated actions that transition between states. This gives the model explicit evidence about dynamic behavior: “clicking this produces that modal” or “entering text updates this field”.
Training procedure highlights:
- The authors synthesized a large dataset of interactive webpages (WebView) and used the WebVIA-Agent to collect multi-state traces for each page.
- For each interaction graph, ground-truth interactive HTML/CSS/JS was generated (they used a powerful multimodal model to author high-quality React + Tailwind code), validated by rendering, and then used to fine-tune base VLMs (Qwen-2.5-VL and GLM-4.1V).
- The model learns to map sequences of visual states and action traces to both layout markup and event handlers/state updates, enabling end-to-end executable pages rather than static facades.
The key advantage: multi-state supervision teaches the model causal relationships between GUI elements and behaviors, which single-screenshot supervision cannot encode.
Part 3 — Validation: test-driven generation
Generating code is one thing; proving it behaves the same is another. The validation module acts like an automated QA:
- It replays task sequences derived from the original interaction graph on the synthesized page (e.g., click Login → modal appears → enter credentials → click submit).
- If the replayed actions produce the expected visual and structural transitions, the page passes; otherwise it fails.
This task-oriented verification focuses on end-to-end behaviors rather than superficial layout similarity. It is powerful because it yields binary, reproducible evidence of interactive fidelity.
Building the training ground: synthetic webpages and datasets
WebVIA needed large amounts of reliable, interactive training data. Real webpages are noisy (ads, async loading), so the authors created a synthetic HTML synthesis pipeline to produce diverse, fully executable single-page apps (React + Tailwind) with constrained but meaningful interactivity.
From this pipeline they produced two main datasets:
- Action Generation dataset: pairs of (screenshot, DOM) with annotated valid action sequences.
- Interaction Verification dataset: tuples (pre-state, action sequence, post-states, success label) — used to teach whether an action produced a meaningful change.
For UI2Code training they assembled the WebView dataset: ~11k synthesized webpages, each with interaction graphs and validated ground-truth interactive code. The WebVIA-Agent explored the pages to produce the multi-state inputs, then a strong model (Claude-Sonnet-4 in their pipeline) generated executable code used as ground truth for fine-tuning UI2Code models.
Semi-automatic human checks and browser-side execution (via Playwright) ensured that retained pages and transitions were valid and reproducible.
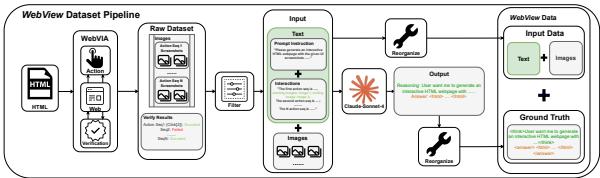
Figure 3: The WebView construction pipeline: generate interactive HTML, explore to collect traces, and pair multimodal inputs with executable ground-truth code.
Experiments: does exploration + interactive supervision pay off?
The evaluation is twofold: test the exploration agent itself, and test the UI2Code model’s ability to produce working interactive pages.
Agent-level evaluation (single-step)
Two subtasks isolate the agent:
- Action generation: given (screenshot, DOM), predict which actions are valid.
- Interaction verification: given pre/post screenshots, classify whether the action executed and whether it exposed new interactive content.
Key single-step results (UIExplore-Bench):
- WebVIA-Agent — Precision 82.37%, Recall 92.61%, F1 = 85.30%
- Strong baselines (examples): Gemini-2.5-pro (Precision 74.01, Recall 95.94, F1 81.70), Claude-Sonnet-4 (Precision 81.16, Recall 89.67, F1 83.38)
WebVIA-Agent trades a small drop in recall for higher precision and the best F1: it avoids hallucinating interactive elements while still finding the majority of real ones. Its verification accuracy is also the best among tested models, reliably identifying meaningful state changes.
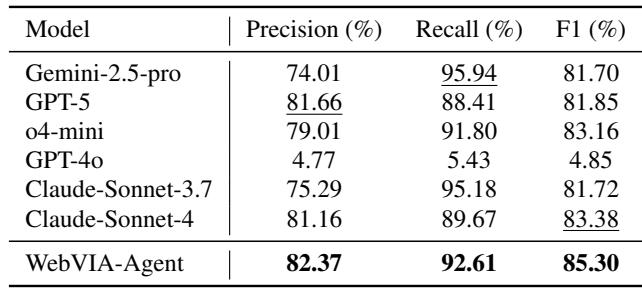
Table 1: Single-step action generation results. WebVIA-Agent achieves the top F1 score by balancing precision and recall.
Pipeline-level evaluation (end-to-end exploration)
Here the agent autonomously explores full pages and constructs interaction graphs. Metrics:
- Completeness: fraction of distinct actionable elements found.
- Correctness: accuracy of verification outputs.
- Deduplication rate: degree to which the agent avoids redundant interactions.
Aggregate score (weighted): Overall = 0.40·Comp + 0.35·Correct + 0.25·Dedup.
Pipeline results (UIExplore-Bench):
- WebVIA-Agent overall: 89.63%
- Completeness: 93.12%
- Correctness: 97.71%
- Deduplication: 72.73%
Compared to strong baselines, WebVIA-Agent attains the best overall performance by combining broad coverage with high verification correctness and reasonable efficiency.
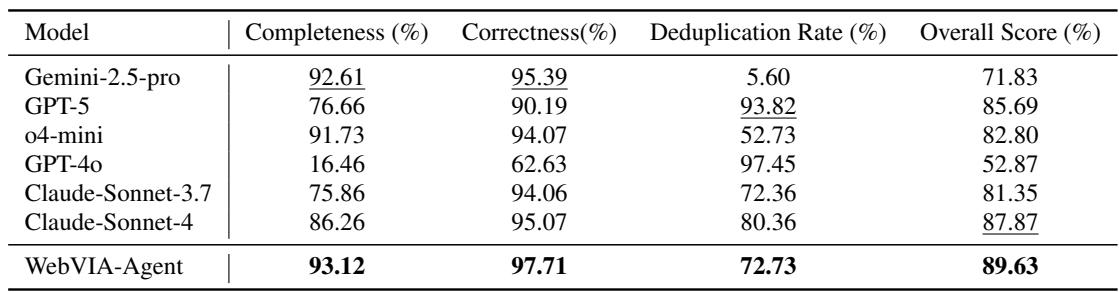
Table 2: Pipeline-level evaluation on full webpages. WebVIA-Agent leads on completeness and correctness, producing high-quality interaction graphs.
The authors also report that WebVIA-Agent strikes a good balance between mean interaction trace length (effort) and overall score — it doesn’t explore forever, but it explores deeply enough where needed. A correlation plot shows WebVIA-Agent in the top-right: high score with moderate trace length.
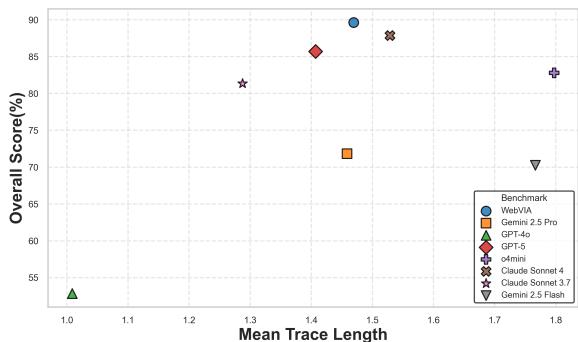
Figure 4: Mean trace length vs. overall exploration score — better agents achieve high scores without excessive steps.
Interactive code generation evaluation
This is the crucial test: can UI2Code models, fine-tuned under the WebVIA regime, produce interactive, executable pages that pass validation?
Benchmarks used:
- Design2Code — a standard static layout reconstruction benchmark.
- UIFlow2Code — a new interactive benchmark introduced by the authors that evaluates whether generated pages support annotated state transitions (task-based validation).
Representative results (selected):
- Qwen2.5-VL-7B (base) on Design2Code: 29.1
- WebVIA-UI2Code-Qwen (fine-tuned) on Design2Code: 34.3
- WebVIA-UI2Code-Qwen on UIFlow2Code: 75.9 (base Qwen failed on interactive benchmark)
- GLM-4.1V-9B (base) on Design2Code: 58.3
- WebVIA-UI2Code-GLM on Design2Code: 63.0
- WebVIA-UI2Code-GLM on UIFlow2Code: 84.9
A compact visualization in the paper summarizes these improvements: base models typically fail to generate usable interactive code; after WebVIA fine-tuning on WebView, the same backbones produce high interactive scores. That indicates interactive supervision is necessary and effective.
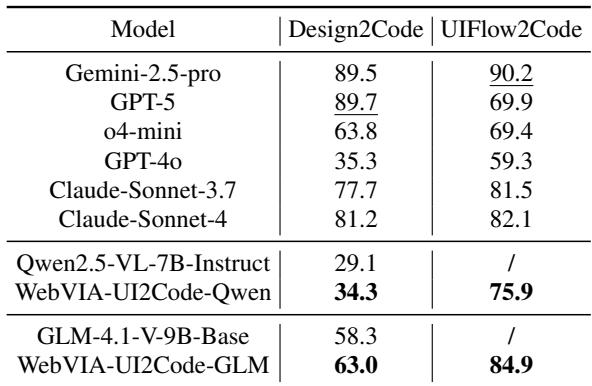
Table 3: WebVIA fine-tuning dramatically improves interactive code generation. Base models fail on UIFlow2Code; WebVIA variants pass many tasks.
Qualitative comparisons show that the WebVIA-trained models generate pages that not only render correctly but also wire event handlers and state updates so that actions (clicks, selects, inputs) cause the expected page transitions. A side-by-side visualization in the paper highlights cases where WebVIA outputs are functionally complete while baselines produce broken or non-interactive results.

Figure 5: Visual comparison of synthesized pages. WebVIA outputs (left) tend to be both visually accurate and functionally complete; baselines often miss interaction logic.
Limitations and practical caveats
The authors are candid about current limitations:
- Action set is restricted: Click, Enter, Select. More complex interactions like drag-and-drop or drawing require pixel-level control and are not covered.
- Training bias toward synthetic data: the agent is trained primarily on procedurally generated pages. While it generalizes surprisingly well to real sites, there remain domain gaps (e.g., calculators, plotting tools) where behavior patterns differ.
- Ground-truth generation used a strong model to author code; automating high-quality ground truth at very large scale is non-trivial and still requires careful filtering and validation.
These are important practical constraints: WebVIA is a convincing proof-of-concept and a step forward, not yet a drop-in replacement for full production UI engineering.
Takeaways for practitioners and researchers
- Interactive supervision matters. Training a UI2Code model on multi-state interaction graphs teaches it causal behavior mappings (what event should do), not just static layout reconstruction.
- Agentic exploration is a scalable way to collect such multi-state supervision: an exploration agent can systematically discover states and transitions to build rich datasets.
- Validation is essential. Task-oriented replay on synthesized pages gives a concrete pass/fail signal for interactivity—far more meaningful than pixel-similarity metrics.
- Synthetic environments are a practical compromise. By controlling page generation and execution, researchers can produce large, diverse, and verifiable datasets; the key is bridging the synthetic→real gap.
Where this leads next
WebVIA demonstrates a practical roadmap: combine agentic exploration with multimodal supervised fine-tuning and task-based validation to get closer to fully interactive UI synthesis. Future work could expand the action set, incorporate real-site fine-tuning, and explore stronger end-to-end generation (e.g., producing production-ready componentized code, accessibility features, or test suites alongside pages).
If you’re building developer tools, prototyping platforms, or automated UI pipelines, WebVIA’s central idea—teach models by letting them act and verify—offers a compelling direction for turning mockups into working prototypes that actually behave.
References and figures cited above are from the paper “WebVIA: A Web-based Vision-Language Agentic Framework for Interactive and Verifiable UI-to-Code Generation”.