](https://deep-paper.org/en/paper/2511.07587/images/cover.png)
Large Language Models (LLMs) are extraordinary—but they have a memory problem. Ask one to summarize a 10-page report, and it may perform brilliantly. Ask it to recall a specific detail from page seven while connecting it to an idea on page two of a 500-page novel, and the cracks begin to show. This isn’t due to a lack of intelligence, but rather a fundamental limitation of architecture: the context window.
Everything an LLM “knows” while performing a task must fit inside this finite space. Context windows are expanding into the millions of tokens, but they remain bounded. Worse yet, performance often degrades as they fill up—a phenomenon known as lost-in-the-middle, where details buried deep in the text gradually fade from the model’s grasp.
The common workaround is Retrieval-Augmented Generation (RAG). Instead of feeding the model the entire document, RAG retrieves only the most relevant pieces—typically paragraphs or short text chunks related to the query—and supplies them to the LLM at inference time. This is incredibly effective for fact-based queries such as “What is the capital of France?” But when the query depends on understanding a narrative, RAG begins to falter.
Most of the world’s information isn’t a tidy list of facts; it’s a collection of stories. Think of crime reports, news articles, legal filings, or project meeting notes. These texts describe actors (people or organizations) taking on roles (suspect, regulator, bidder), moving through states (arrested → arraigned → released), and interacting across specific times and places. Standard RAG, which treats text as a set of independent chunks, fails to connect these dots in a coherent way.
Humans, however, excel at this. We possess what cognitive psychologist Endel Tulving called episodic memory—the ability to mentally relive events. We don’t just remember facts; we remember them in context: who was there, what happened, where, and when. That structure allows us to build a coherent, evolving “world model” from experience.
A new study from researchers at UCLA introduces a framework to give LLMs a version of this ability. The Generative Semantic Workspace (GSW) is a neuro-inspired memory system that builds structured, story-like representations of ongoing situations. It goes well beyond simple fact retrieval, enabling language models to reason about how things happen, who is involved, and when events occur—with major improvements in both accuracy and efficiency.
From Fragmented Facts to Coherent Stories
To understand why GSW marks a major leap forward, we need to recognize where existing RAG systems fall short.
Standard RAG divides documents into self-contained chunks, encodes each chunk using an embedding model, and retrieves the most semantically similar passages to a query. This approach works fine when a question’s answer resides within a single text segment.
Its weakness lies in fragmentation. If the answer spans multiple parts of a document—say, paragraphs scattered throughout different chapters—standard RAG may retrieve only fractions of what’s needed. Because each chunk is indexed independently, contextual links between them are lost.
Structured RAG systems made progress by introducing knowledge graphs that capture relationships between entities and ideas across the corpus. They support multi-hop reasoning, connecting data points like “company” → “CEO” → “quarterly results.” Yet these systems are optimized for static, fact-rich resources like Wikipedia. They represent what is known, not how things unfold. They can’t easily model an actor’s evolving roles, or how an event changes across space and time.
GSW fills this gap—it’s designed for narratives, not static facts. Its memory builds a representation of who, what, where, when, and how within a story, mirroring the structure of human episodic reasoning.
A Brain-Inspired Blueprint for Memory
Neuroscience provides the guiding analogy. Human episodic memory arises from interaction between two complementary systems:
- Neocortex — stores hierarchical abstractions and patterns about entities and events.
- Hippocampus — binds those abstractions into coherent sequences anchored in time and space.
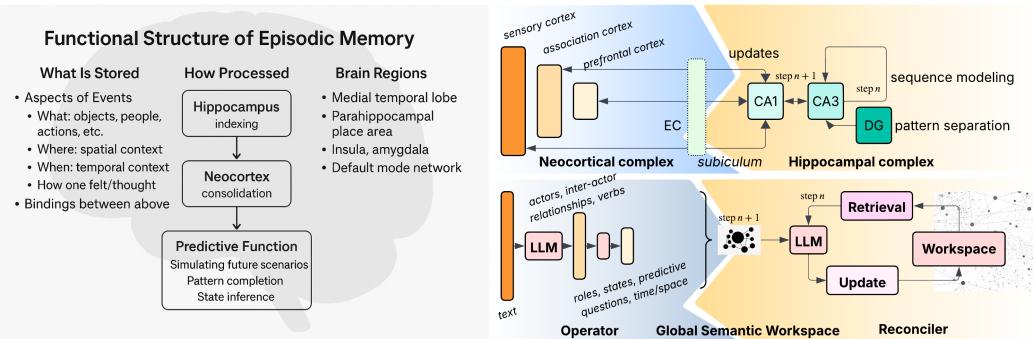
Figure 1: Unifying Brain-Inspired and Generative Semantics for Episodic Memory Modeling.
GSW mirrors this architecture using two core components:
- The Operator acts like the neocortex. It’s an LLM-driven module that analyzes each incoming text segment, extracting structured meaning—identifying actors, roles, states, actions, and relationships.
- The Reconciler parallels the hippocampus. It integrates those semantic snapshots into a persistent workspace, enforcing temporal, spatial, and logical coherence. It’s responsible for stitching events together into an evolving world model.
Together, they build a living memory of a text as it unfolds.
Inside the Generative Semantic Workspace
The goal of GSW is to convert raw, unstructured narrative into structured, interpretable memory. Let’s walk through the process.
The Operator: Understanding the Moment
The Operator examines a small text piece and constructs a semantic map—a compact representation of the situation. This map includes:
- Actors, Roles, and States:
- An actor can be any entity—a person, place, organization, or object.
- A role defines what the actor can do within a situation (e.g., suspect, judge, organizer).
- A state refines that role at a particular time (suspect at large vs. suspect captured).
Mathematically, the probability of one actor acting on another depends on their role and state:
\[ \pi_{r,s}(a_i \to a_j) = \pi_r(a_i \to a_j \mid s) \]Verbs and Valences: Verbs describe how and why roles or states change—how “arrest” transitions a person from at large to in custody. Valences encode these causal relationships.
Time and Space: The Operator grounds each event in its temporal and spatial context. If a text mentions “Officers apprehended Jonathan Miller in downtown Greenview,” the model connects both actors to that location and timestamp, ensuring they share context.
Forward-Falling Questions: These are predictive queries generated as part of memory construction—e.g., “When will Miller be indicted?” or “Where will the trial occur?” They help the system anticipate and link future narrative developments.
This structure transforms text into a single frame of an ongoing movie: a coherent snapshot of events.
A vivid example from the paper illustrates how GSW constructs memory around a hackathon involving Julian Ross.
The first text chunk shows Julian participating in the event but doesn’t mention time or place. The second chunk reveals the date—May 31, 2024—from his smartwatch.
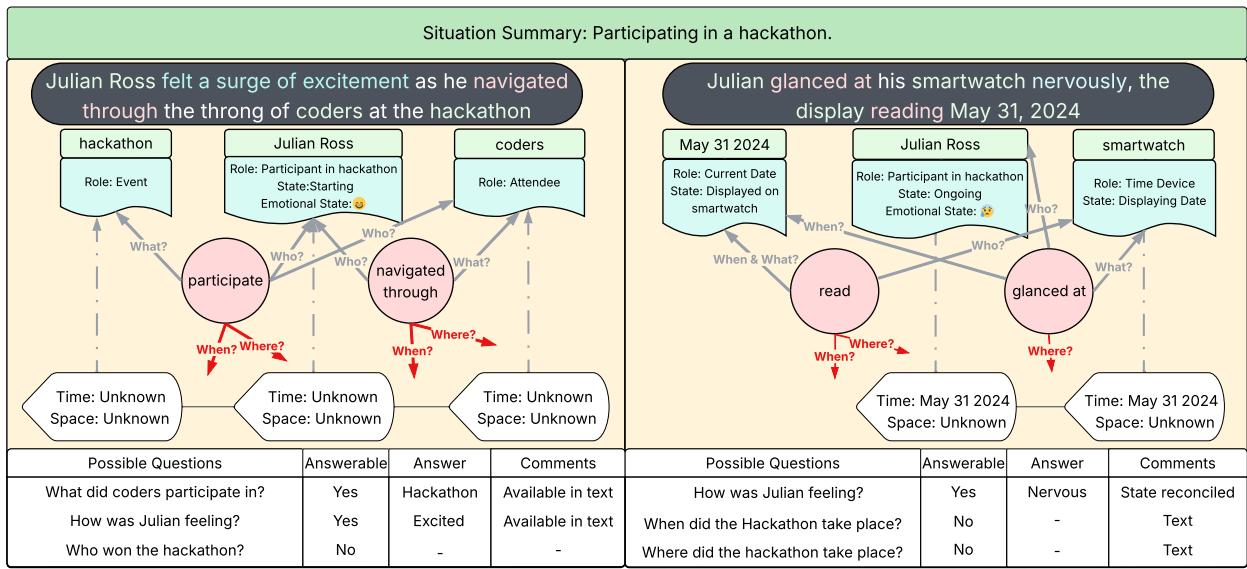
Figure 8: Operator example—two text chunks analyzed into structured semantic frames.
The Reconciler: Weaving the Story
The Reconciler takes individual Operator outputs and integrates them into consistent, evolving memory. It performs two essential types of reconciliation:
- Entity Reconciliation: It identifies that “Julian Ross” appearing across multiple chunks refers to the same person and merges attributes accordingly.
- Spatiotemporal Reconciliation: It uses newly discovered time or location details to update previous memory entries and propagate this information to related entities.
The merged result forms a unified, time-stamped representation of the event.
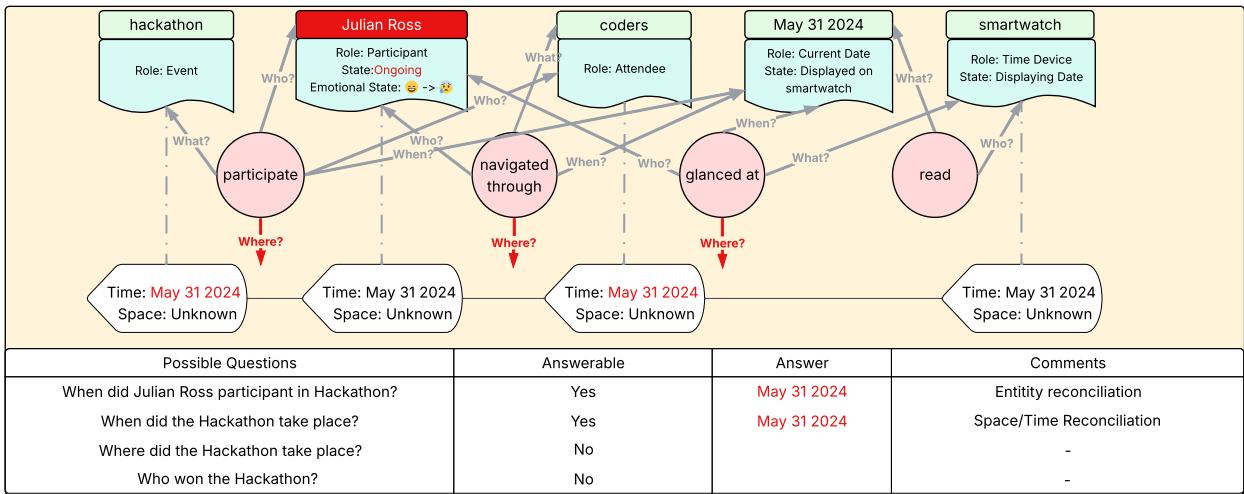
Figure 9: Reconciler example—linking entities and updating time continuity.
As new text appears (for example, revealing the location “Silicon Beach” and Ross’s victory), the Reconciler keeps updating. It answers previously created forward-falling questions and extends the semantic network into a fully coherent narrative trace.
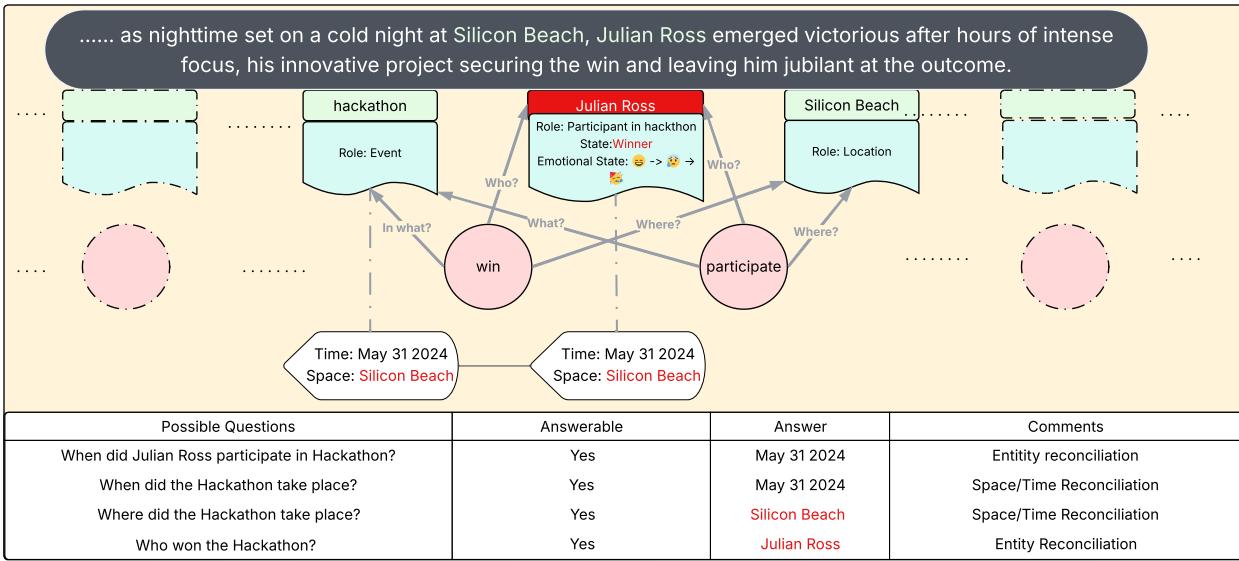
Figure 10: Final GSW—integrated actor, space/time, and resolved questions.
This stepwise process embodies how GSW builds memory over time, formally expressed as:
\[ P(\mathcal{M}_n | \mathcal{C}_{0:n}) = \sum_{\mathcal{M}_{n-1}, \mathcal{W}_n} P(\mathcal{M}_n | \mathcal{M}_{n-1}, \mathcal{W}_n) \, P(\mathcal{M}_{n-1} | \mathcal{C}_{0:(n-1)}) \, P(\mathcal{W}_n | \mathcal{C}_n) \]In simpler terms: New Memory = f(Old Memory, New Information).
Question Answering: Tapping the Memory
Once built, the GSW enables an elegant question-answering pipeline:
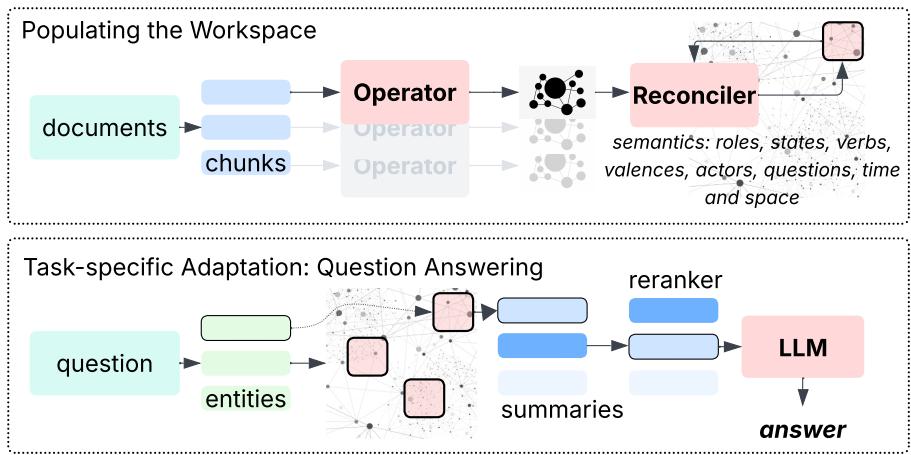
Figure 2: Episodic Memory Creation and QA—building and querying the workspace.
- Entity Matching: Identify entities mentioned in the query (e.g., “Carter Stewart,” “Scientific Conference”).
- Summary Generation: Retrieve concise, chronological summaries for those entities from the workspace—complete with roles, states, times, and places.
- Reranking: Sort the summaries by relevance to the query.
- Answer Synthesis: Pass the top summaries to an LLM to compose the final, contextually grounded answer.
This method pre-processes memory into compact, semantically rich summaries before the LLM ever sees them. The entire QA pipeline is exemplified below:

Figure 11: Illustrative example of the GSW QA framework—matching and reasoning over structured memory.
Putting GSW to the Test
To validate their approach, the authors evaluated GSW on the Episodic Memory Benchmark (EpBench), which tests an AI’s ability to recall and reason over evolving narratives. Two versions were used:
- EpBench-200 (~100k tokens, 200 chapters)
- EpBench-2000 (~1M tokens, 2000 chapters)
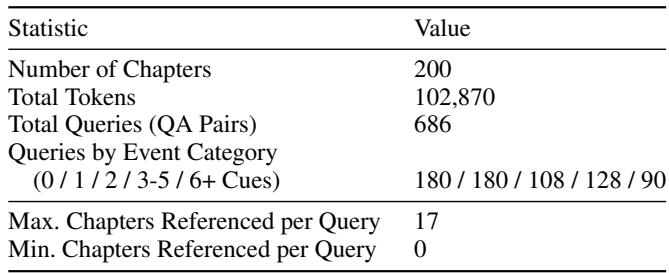
Table 1: EpBench-200 Dataset—structured narrative benchmark.
GSW was compared against strong baselines: a vanilla long-context LLM, standard embedding-based RAG, and structured RAG variants (GraphRAG, HippoRAG2, LightRAG).
Accuracy: When Context Gets Complicated
Across all difficulty levels, GSW showed superior accuracy.
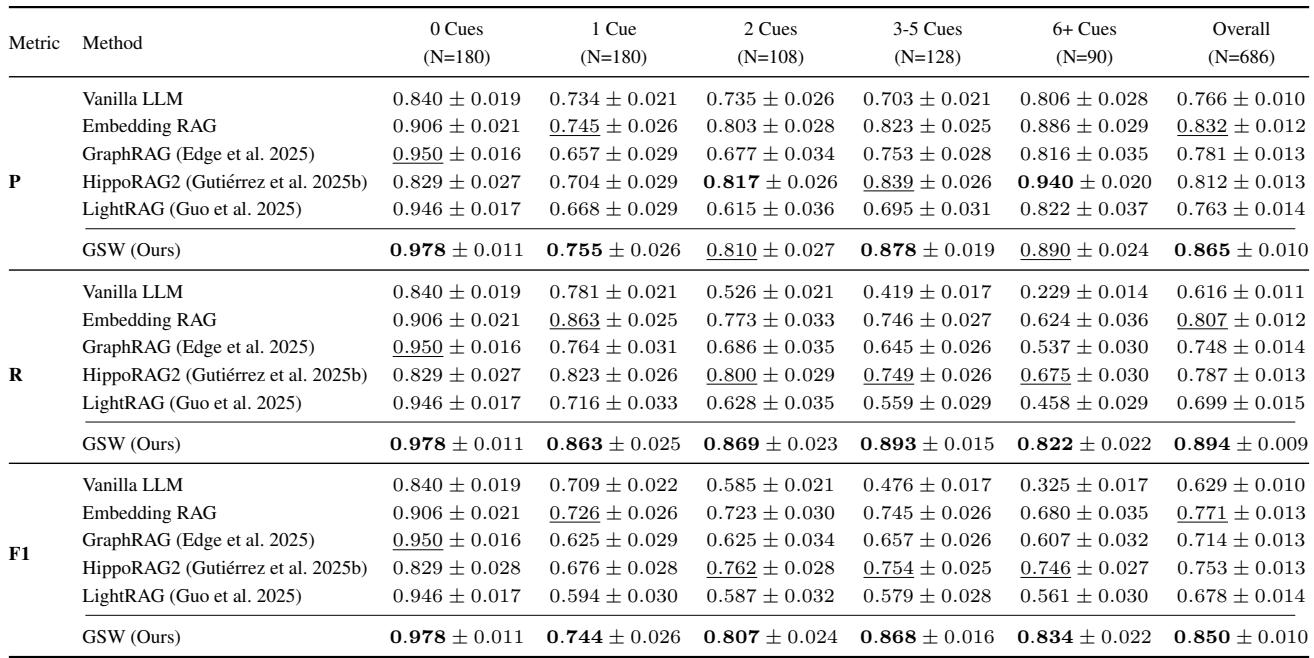
Table 2: GSW performance on EpBench-200.
The most revealing test was the “6+ Cues” category—questions requiring reasoning across up to 17 distinct chapters. GSW’s recall in this hardest class outperformed the next-best system, HippoRAG2, by 20%. Unlike competing frameworks whose recall collapses as complexity increases, GSW’s structured, coherent memory preserves its ability to track relevant episodes reliably.
Efficiency: Doing More with Fewer Tokens
GSW doesn’t just think better—it also thinks leaner. Because queries use summaries rather than raw document chunks, the number of tokens supplied to the LLM is drastically reduced.
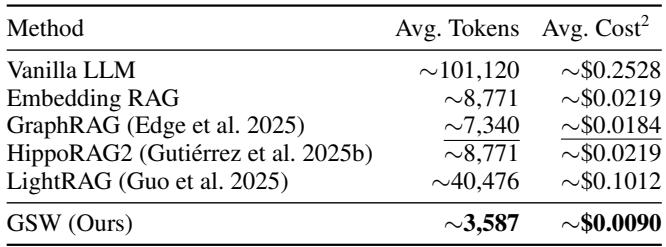
Table 3: GSW’s Efficiency—fewer tokens, lower costs.
GSW cuts average token usage by 51% compared to GraphRAG and by nearly 59% relative to embedding-based RAG. This means not only faster inference and lower cost but also fewer hallucinations, since the model focuses only on concise, relevant context.
Scalability: Holding Up at 10× Scale
On the massive 2000-chapter dataset, GSW maintained its lead—improving F1 by 15% and recall by 14% over all baselines.
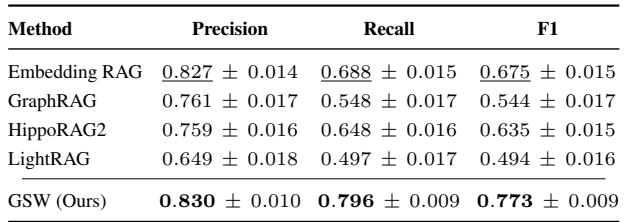
Table 4: GSW performance on the 2000-chapter benchmark.
These results demonstrate that GSW scales gracefully, retaining its reasoning power on long, complex narratives—crucial for real-world knowledge bases extending into millions of tokens.
Conclusion: Toward Human-Like AI Memory
The Generative Semantic Workspace offers a new way to equip LLMs with memory that is structured, interpretable, and dynamic. Instead of retrieving isolated facts, it builds an evolving semantic model that tracks actors, roles, states, and context—just as humans do when recalling a story.
GSW’s Operator and Reconciler form a neuro-inspired loop that translates text into a cohesive world model. This enables precise long-context reasoning, superior accuracy on complex episodic queries, and dramatic efficiency improvements.
While the current implementation relies on a large proprietary model, future directions include exploring open-source alternatives and extending GSW to multimodal inputs like video or sensor data. The long-term vision is compelling: LLMs that don’t merely read but remember—agents capable of understanding not just what happened, but how and why.
In short, GSW brings LLMs one step closer to true narrative comprehension—a bridge from language to lasting understanding, from facts to episodes, and from recall to reasoning.