](https://deep-paper.org/en/paper/2511.08923/images/cover.png)
Large Language Models (LLMs) have taken the world by storm, but anyone who has used them has noticed that slight pause as the model generates its response—one token at a time. This sequential, step-by-step generation is the hallmark of Autoregressive (AR) models, the powerhouse architecture behind GPT, Claude, and Llama. AR models are known for their striking coherence and accuracy—but they pay for this quality in speed. Because each new token depends on the last, they are inherently slow.
Enter Diffusion Language Models (dLMs). These models promise a different route: parallel generation. Instead of generating one token at a time, they can decode multiple tokens simultaneously, offering the tantalizing prospect of massive throughput gains. However, this speed usually comes with a trade-off in output quality. The independence assumption behind parallel decoding can disrupt linguistic coherence.
That leaves us with a core dilemma: should we choose the high-quality but slow AR models, or the fast but less consistent diffusion ones? What if we didn’t have to choose at all?
A recent paper from NVIDIA researchers introduces TiDAR (Thinking in Diffusion and Talking in Autoregression)—a groundbreaking hybrid model that merges the parallel “thinking” of diffusion with the high-quality “talking” of autoregression, all in a single, efficient forward pass. The result? TiDAR closes the quality gap with classic AR models while achieving a stunning 4.7× to 5.9× increase in generation throughput.
Let’s unpack the insights behind this leap forward.
The Bottleneck: Why Are Autoregressive Models Slow?
To understand TiDAR’s innovation, we first need to understand why traditional AR models are constrained. It’s not just about compute—it’s about memory bandwidth.
At each decoding step, an AR model must load billions of parameters and its Key-Value (KV) cache from GPU memory. This data transfer dominates latency. In contrast, the actual compute required to generate one token is incredibly fast once everything is loaded. That means GPUs often sit underutilized; the compute pipelines are idle despite abundant hardware capacity.
A profiling experiment from NVIDIA illustrates this perfectly:
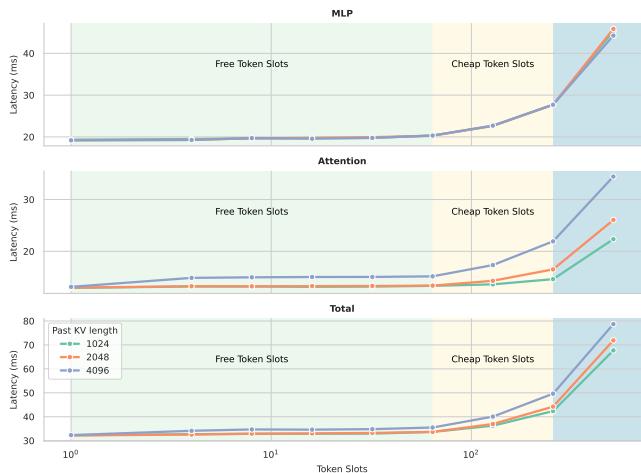
Figure 1 | Latency Scaling Over Token Slots: The latency of Transformer decoding on NVIDIA H100 remains nearly flat for the first group of tokens—these are “free” token slots that incur almost no additional latency. TiDAR exploits these free slots to maximize throughput.
The takeaway? Adding a few extra token positions during a single forward pass costs nearly nothing in latency. These “free token slots” present a hidden opportunity for parallel token generation—if we can maintain sequence quality.
That’s precisely where diffusion tries to help, but it has struggled so far. Here’s why.
The AR vs. Diffusion Quality Gap
AR and diffusion models differ fundamentally in how they model the probability of text sequences.
An autoregressive model represents the probability of a full sentence by chaining conditional probabilities, where each token depends on all previous ones:
\[ p_{\mathrm{AR}}(\cdot;\theta) = \prod_i p_{\theta}^{i}(x_i|\mathbf{x}_{\langle i};\theta) \]This left-to-right causal structure naturally fits language generation, resulting in fluent and consistent text.
A diffusion model, in contrast, learns to iteratively denoise corrupted sequences. When generating several tokens in parallel, diffusion models predict each token independently, conditioned on a shared noisy context:
\[ p_{\mathrm{Diff}}(\cdot;\theta) = \mathbb{E}_{\tilde{\mathbf{x}} \sim q(\cdot|\mathbf{x})} \prod_i p_{\theta}^{i}(x_i|\tilde{\mathbf{x}}) \]This independence assumption sacrifices the rich contextual dependency that drives human-like coherence. As studies have shown, diffusion LLMs such as Dream and LLaDA typically achieve their best quality when generating one token per step—negating their parallel advantage.
Wouldn’t it be ideal if a model could compute like diffusion but sample like autoregression?
That’s exactly what TiDAR accomplishes.
The Core Method: Thinking and Talking in a Single Pass
TiDAR unifies parallel diffusion drafting and autoregressive sampling inside a single forward pass, enabled by a structured hybrid attention mask. The model simultaneously “thinks” (drafts) and “talks” (samples)—hence its name.
Here’s how the workflow proceeds during generation:
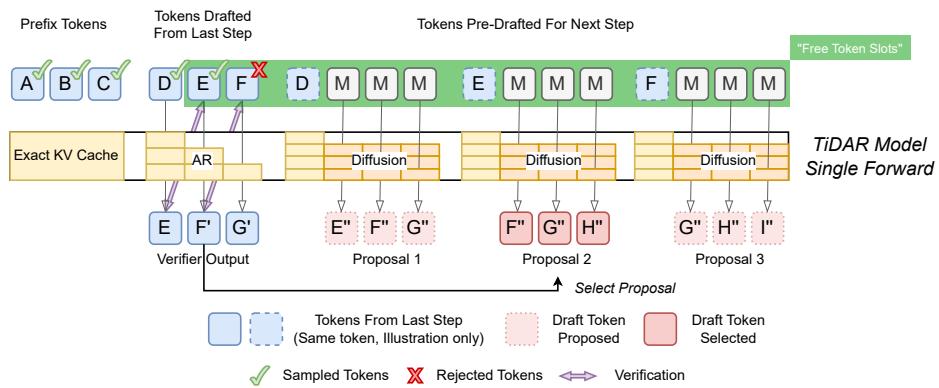
Figure 2 | TiDAR Architecture: Tokens are divided into three sections within each forward pass—prefix tokens, previously drafted tokens, and new pre-drafts for the next step—all processed efficiently in one pass.
Each generation step includes three token segments:
- Prefix Tokens: The verified tokens from previous steps.
- Drafted Tokens: Candidate tokens proposed during the prior iteration.
- Pre-Drafted Tokens: Mask tokens that will be baked into proposals for the next step.
TiDAR’s structured attention mask treats these segments differently:
- Prefix + Drafted Tokens: Processed with causal attention, following autoregressive semantics. The model predicts the high-quality next tokens and confirms drafts through rejection sampling.
- Pre-Drafted Tokens: Processed with bidirectional attention, enabling one-step diffusion drafting conditioned on the accepted prefix.
In a single forward pass, TiDAR accomplishes two tasks:
- Talking (Verification): It autoregressively checks drafted tokens against its causal predictions. Accepted tokens are cached for reuse, rejected ones are dropped.
- Thinking (Pre-Drafting): Simultaneously, it creates several parallel future token proposals for the next step using one-step diffusion.
Everything happens concurrently—dramatically increasing compute density and utilization while keeping quality in check through rejection sampling and KV cache reuse. Diffusion provides speed, autoregression provides quality, and both operate harmoniously.
Training a Two-in-One Model
To train the dual-mode backbone, TiDAR extends each sequence with a block of [MASK] tokens. This configuration enables simultaneous learning of autoregressive and diffusion objectives.
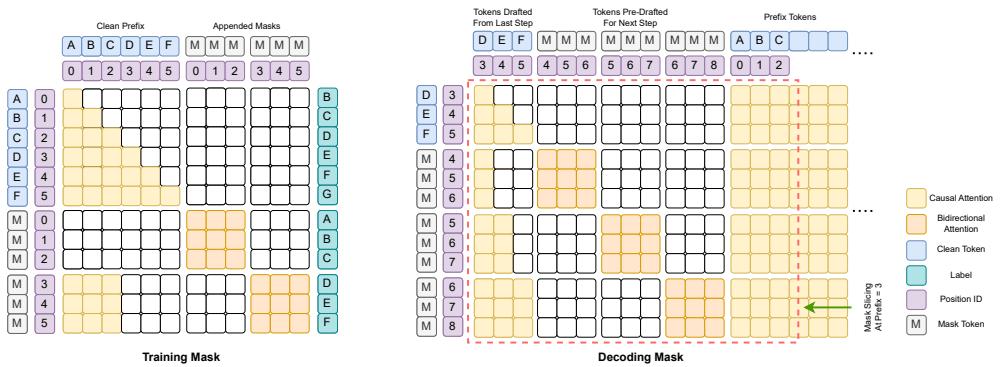
Figure 3 | Training vs. Decoding Masks: During training, clean tokens attend causally (orange) while masked tokens attend bidirectionally within diffusion blocks. At inference, the decoding mask smoothly combines both regimes for parallel generation.
During training:
- AR loss is applied to clean prefix tokens via a causal mask.
- Diffusion loss is applied to masked tokens via a bidirectional mask.
The team introduced an elegant simplification called the Full Mask strategy—instead of random masking, all tokens in the diffusion section are masked. This choice greatly simplifies training while providing:
- A densified diffusion loss signal.
- Consistent loss balancing between AR and diffusion components.
- Perfect alignment between training behavior and one-step diffusion inference.
The final training objective thus combines both modes seamlessly:
\[ \mathcal{L}_{TiDAR}(\theta) = \frac{1}{1+\alpha} \left( \sum_{i=1}^{S-1} \frac{\alpha}{S-1} \mathcal{L}_{AR}(x_i, x_{i+1}; \theta) + \sum_{i=1}^{S-1} \frac{1}{S-1} \mathcal{L}_{Diff}([mask], x_i; \theta) \right) \]This produces a single versatile model that understands language causally and bidirectionally at once—ready for ultra-efficient inference.
Putting TiDAR to the Test: Results and Analysis
The researchers tested TiDAR at two scales—1.5B and 8B parameters—across a wide range of tasks, including coding (HumanEval, MBPP) and math reasoning (GSM8K, Minerva Math).
Generative Quality and Speed
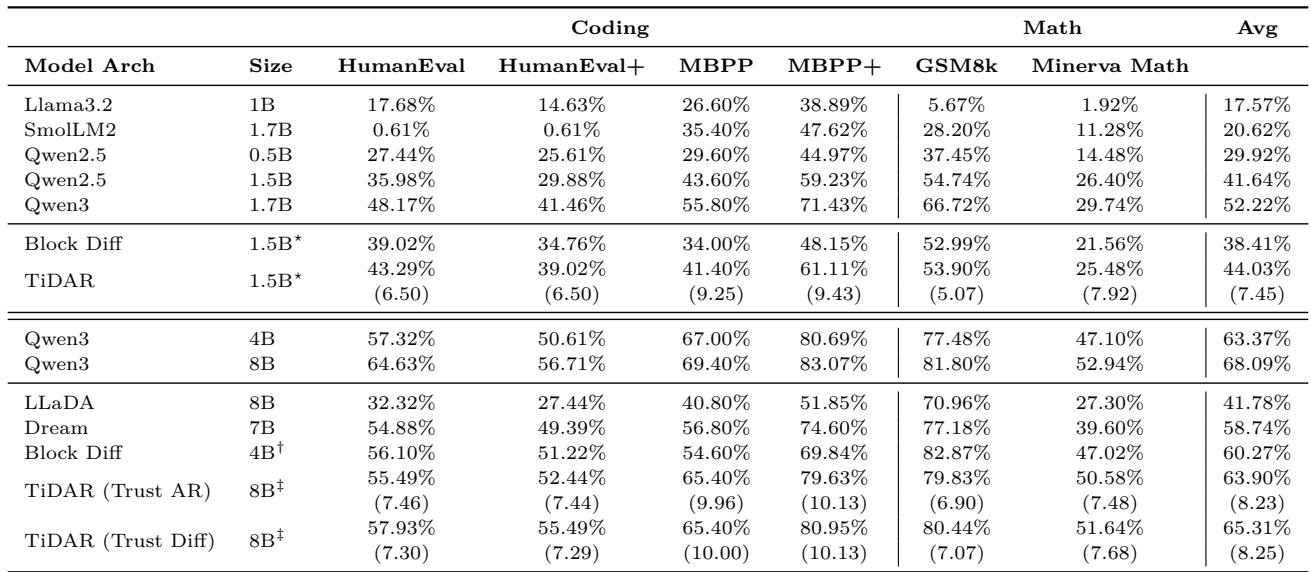
Figure 4 | Generative Evaluation: TiDAR achieves near-parity with leading AR models while generating multiple tokens per forward pass.
At the 1.5B scale, TiDAR matches the quality of its AR base model while generating an average of 7.45 tokens per forward pass. At 8B scale, it maintains minimal quality loss yet boosts throughput to 8.25 tokens per forward. This lifts token generation speed by almost sixfold, without sacrificing accuracy.
Wall-Clock Speedup: The Real Prize
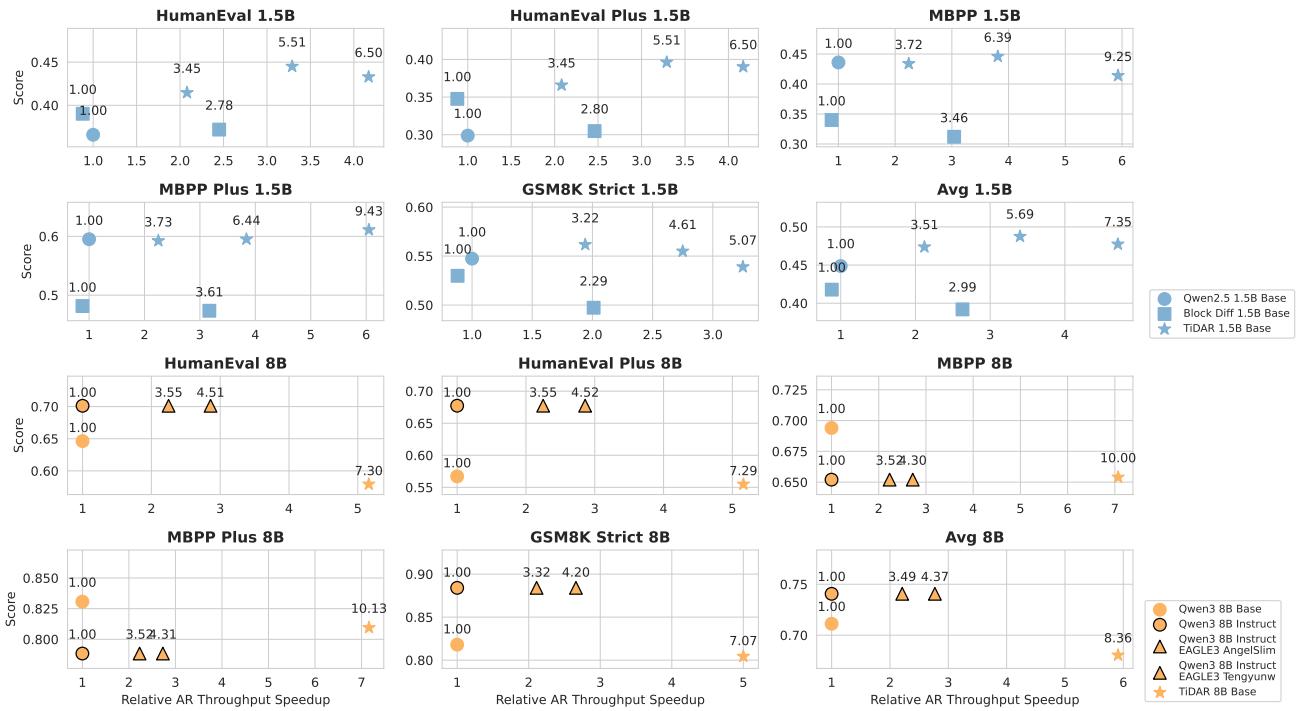
Figure 5 | Efficiency–Quality Benchmark: TiDAR 1.5B delivers 4.7× and TiDAR 8B delivers 5.9× speedup versus standard AR—exceeding speculative decoding methods.
Measured on NVIDIA H100 GPUs, TiDAR translates its parallelism into real-world gains:
- 4.71× throughput improvement over Qwen2.5 1.5B
- 5.91× improvement over Qwen3 8B.
Even against EAGLE-3 (a state-of-the-art speculative decoding system), TiDAR surpasses throughput efficiency—marking the first time a diffusion-based design has outperformed advanced speculative decoding while maintaining comparable quality.
Why Does It Work So Well? Key Ablations
The authors explored several ablation studies to identify which design choices drive performance.
1. Full Masking Strategy
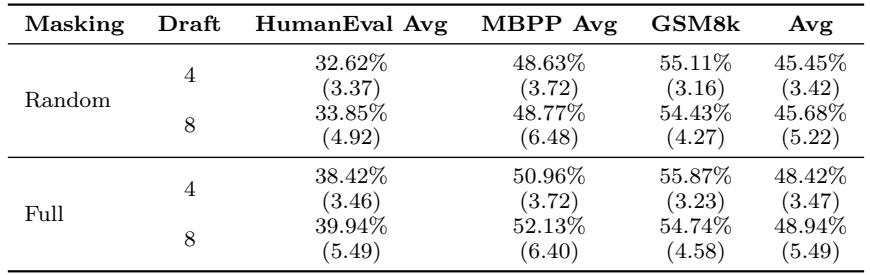
Figure 6 | Effect of Full Mask Training: Full masking leads to higher quality and efficiency across coding and math tasks.
Replacing random corruption with full masking significantly improved both quality and throughput, thanks to consistent train–test alignment and richer diffusion loss signals.
2. Balanced AR and Diffusion Verification
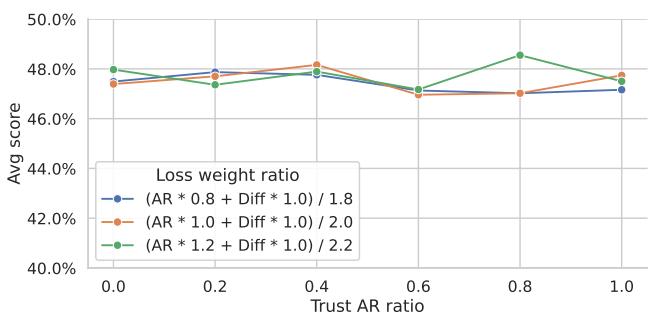
Figure 7 | Trusting AR vs Diffusion: TiDAR exhibits near-constant quality whether it trusts AR or diffusion logits—indicating balanced dual-mode training.
Experiments blending AR and diffusion logits proved that TiDAR performs equally well regardless of which prediction it “trusts.” The consistency underscores the robustness of its autoregressive rejection sampling, which ensures precision regardless of the drafting mechanism.
Conclusion: A New Frontier for Efficient Generation
TiDAR breaks a long-standing trade-off between quality and speed in language model inference. By building a sequence-level hybrid architecture that “thinks” in parallel diffusion and “talks” with autoregressive precision, it maximizes GPU utilization and minimizes latency—all without sacrificing coherence.
Its hallmark innovations—a structured hybrid attention mask, single-pass draft-and-verify mechanism, and full-mask training scheme—enable unprecedented decoding efficiency. Delivering up to 6× faster generation while maintaining autoregressive-level quality, TiDAR sets a new benchmark for next-generation LLM architectures.
For the first time, we see that diffusion models can meet and even surpass speculative decoding speeds—a clear signal that the future of LLM inference lies in hybrid thinking.