](https://deep-paper.org/en/paper/2511.09148/images/cover.png)
Large Language Models (LLMs) have transformed natural language processing, but their full potential emerges when they can interact with the external world. By learning to use tools—such as APIs, databases, or code execution functions—LLMs evolve from text generators into capable agents that can reason and act. Imagine an AI assistant that can book your flights, analyze sales data, and compile a business report—all seamlessly within one conversation. That’s the promise of tool-augmented language models.
However, teaching an LLM to use tools effectively is far from straightforward. The conventional training method relies on static, pre-generated datasets of tool-use examples. This approach poses two major challenges:
- Static Data: The data is created once and then frozen. The model keeps training on the same examples, even after it has mastered them, while never seeing enough of the tough cases that could improve its reasoning and decision-making.
- Noisy Labels: Automatically synthesized datasets often include subtle errors—wrong parameters, incomplete calls, or misaligned outputs—that confuse the model and degrade its performance.
What if this process could be smarter? What if the model itself could help direct and correct its own training data—identifying weaknesses, filtering noisy samples, and generating the right kind of challenging examples it needs?
That’s the core idea behind LoopTool, an automated, model-aware framework that transforms data generation and training into a continuous, closed loop. Instead of a one-way flow from data to model, LoopTool makes training iterative, adaptive, and self-correcting—producing dramatic gains in performance for tool-using LLMs.
The Problem with the Old Way: Static Pipelines
In most tool-learning systems, training follows a stagnant pipeline:
- Generate Data: A powerful model (often closed-source and expensive) like GPT-4 creates a huge dataset of tool-use conversations.
- Train Model: A smaller, open-source model is fine-tuned on this synthetic dataset.
- Hope for the Best: The results are evaluated after training is complete.
This process is disconnected. The data generator doesn’t know what the training model struggles with, and the training model cannot influence future data creation. It’s like handing a student a thousand-page textbook without ever testing which chapters they genuinely need help with. Worse, if the textbook itself has typos or conceptual errors, the student will learn those mistakes.
LoopTool replaces this disconnected paradigm with a dynamic, feedback-driven loop, where data generation, model diagnosis, and improvement continually feed each other.
The LoopTool Framework: How the Self-Refining Loop Works
LoopTool combines four tightly interlinked stages into a virtuous cycle: training, diagnosis, verification, and data expansion. As the loop runs, both the dataset and the model evolve, reinforcing each other.
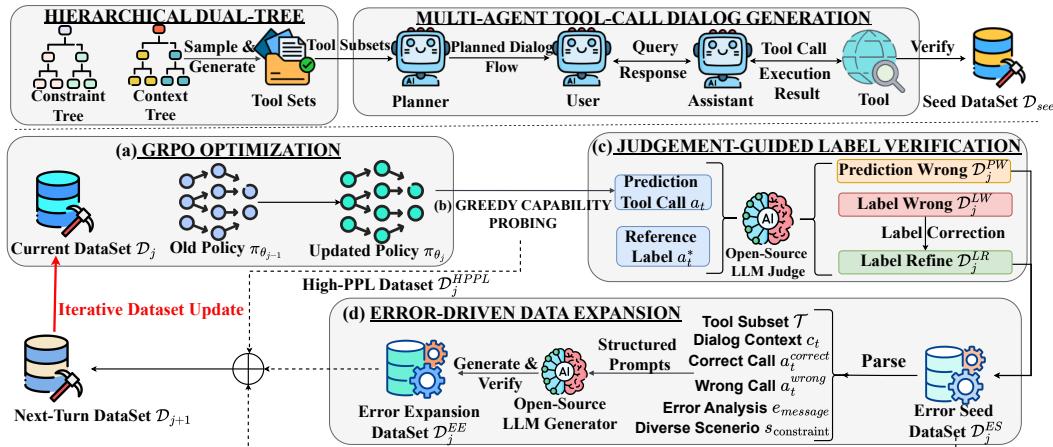
Figure 1: The overall closed-loop automated pipeline of LoopTool, coupling (a) GRPO optimization, (b) Greedy Capability Probing, (c) Judgement-Guided Label Verification, and (d) Error-Driven Data Expansion for iterative tool-use enhancement.
Step 0: Planting the Seed — Automated Data Construction
Before the loop begins, LoopTool needs a high-quality seed dataset as the foundation. The team built it using two innovative components:
Hierarchical API Synthesis: A dual-tree approach generates diverse, realistic APIs. The Context Tree defines the application domain (e.g., Travel → Flights → Search), while the Constraint Tree enforces structural validity (parameter types, naming, and formats). Sampling from both trees produces structured, coherent new APIs.
Multi-Agent Simulation: Four agents—a Planner, User, Assistant, and Tool Agent—simulate natural, multi-turn dialogues involving tool use. The Planner outlines the conversation flow; the User issues requests; the Assistant selects and invokes tools; and the Tool Agent returns simulated results. Each conversation mirrors real-world usage patterns.
All generated data is verified both by rule-based checks and an open-source LLM judge (Qwen3-32B), ensuring syntactic and semantic correctness before inclusion in the seed corpus.
Step 1: GRPO Optimization — Reinforcement Fine-Tuning
Training begins with GRPO (Grouped Reinforcement Policy Optimization), a reinforcement learning technique that rewards the model when it generates the correct tool call.
The reward function is simple yet effective:
\[ r(\mathcal{T}, c_t, a_t^*, a_t) = \begin{cases} 1, & \text{ToolMatch}(a_t, a_t^*) \\ 0, & \text{otherwise} \end{cases} \]Here, \(a_t^*\) is the correct tool call for a given context \(c_t\) and tool set \(\mathcal{T}\). The model’s goal is to maximize these binary rewards while maintaining stability from one version to the next.
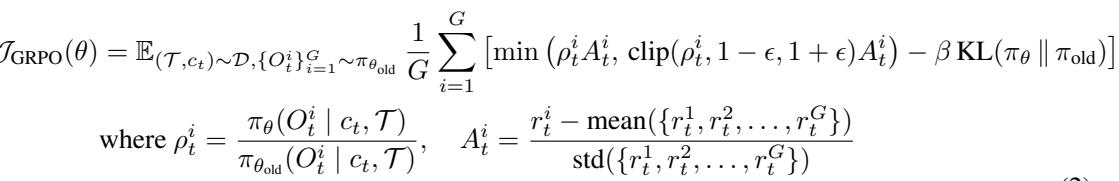
After this initial training round, the model has learned—but imperfectly. The next steps diagnose where it still falters and use that insight to upgrade both its data and knowledge.
Step 2: Greedy Capability Probing (GCP)
Once training concludes, the model’s capabilities are “probed” using greedy decoding—always picking the most probable next token. Each data sample falls into one of two categories:
- Mastered: The model predicts the correct tool call.
- Failed: The prediction doesn’t match the label.
Not all mastered samples are equally valuable. Some are easy wins; others sit near the decision boundary where the model was uncertain. To find those “borderline” cases, researchers calculate Perplexity (PPL):
\[ PPL_{(\mathcal{T},c_t)} = \exp\left(-\frac{1}{L}\sum_{i=1}^{L}\log p_{\theta}(o_i \mid \mathcal{T}, c_t, o_{1:i-1})\right) \]A high PPL indicates uncertainty. These samples, along with failed cases, are kept for further analysis, while trivial ones are discarded to keep subsequent training focused and efficient.
Step 3: Judgement-Guided Label Verification (JGLV)
Synthetic datasets often contain noisy or incorrect labels. Instead of assuming those labels are always right, LoopTool asks a judge—an open-source model like Qwen3-32B—to compare the model’s prediction with the reference label and objectively decide which one is better.
The judge’s verdict classifies each case as:
- PRED_WRONG: Model prediction is incorrect.
- LABEL_WRONG: The original label was wrong—the model’s prediction is actually better.
- BOTH_CORRECT / BOTH_WRONG: Other non-informative cases.
This produces two refined sets:
\[ \mathcal{D}_{j}^{PW} = \{(\mathcal{T}, c_t, a_t^*, a_t) \mid y_{\text{judge}} = \text{PRED_WRONG}\} \]\[ \mathcal{D}_{j}^{LW} = \{(\mathcal{T}, c_t, a_t^*, a_t) \mid y_{\text{judge}} = \text{LABEL_WRONG}\} \]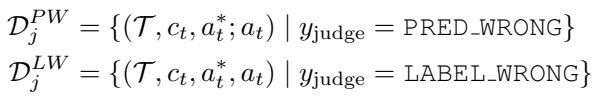
Figure 2: Classification of dataset samples according to the judge model’s verdict, distinguishing true model errors from label corrections.
In LABEL_WRONG cases, LoopTool replaces the incorrect label with the model’s improved output—automatically cleaning the dataset. As training iterates, this process purifies the supervision signal, allowing the model to learn from clearer, higher-quality examples without external human correction.
Step 4: Error-Driven Data Expansion (EDDE)
The system now knows what the model can’t do and what errors exist. Merely retraining on those mistakes isn’t enough. LoopTool turns verified failure cases into seeds for generating fresh challenges.
For each error case, a generator model is given the failure context, the wrong and correct tool calls, and a short error analysis. It then produces several new samples that preserve the underlying difficulty but vary in content—different user goals, domains, or parameters—to promote generalization.
This Error-Driven Data Expansion (EDDE) ensures the dataset grows dynamically, focusing precisely on what the model finds difficult while maintaining diversity.
Step 5: Closing the Loop and Repeating
At the end of an iteration, LoopTool merges all improved data sources to form the next training round’s dataset:
\[ \mathcal{D}_{j+1} = \mathcal{D}_j^{ES} \cup \mathcal{D}_j^{EE} \cup \mathcal{D}_j^{HPPL} \cup \mathcal{D}_j^{Seed-new} \]This combined corpus includes corrected examples, newly minted hard cases, high-PPL uncertainties, and a sprinkling of untouched seed samples. The model then re-enters GRPO training, starting a new, more challenging and cleaner learning cycle. Each iteration refines the model’s reasoning, accuracy, and robustness.
Experimental Results: Does It Work?
To validate the approach, the researchers trained a Qwen3-8B model entirely within the LoopTool framework and evaluated it on two industry-standard benchmarks: BFCL-v3 and ACEBench.
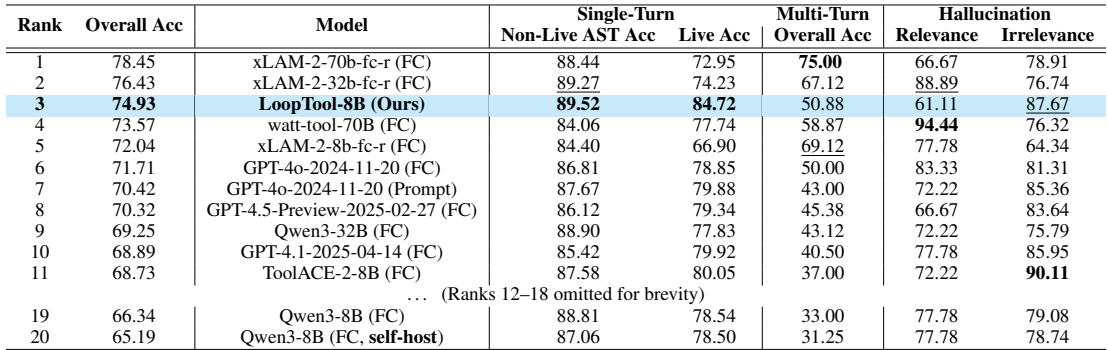
Table 1: Results on the BFCL-v3 benchmark. LoopTool-8B outperforms many larger models.
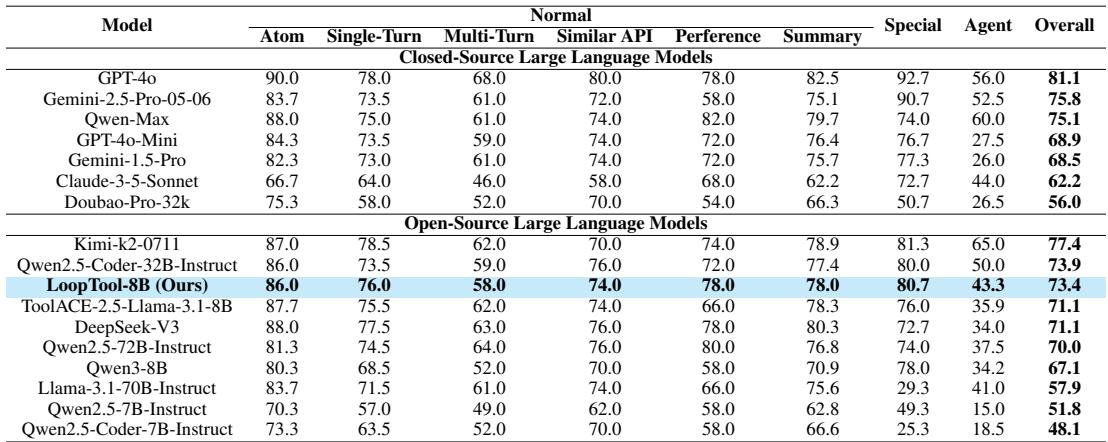
Table 2: Results on ACEBench. LoopTool-8B again achieves state-of-the-art results among 8B-scale models.
Across both benchmarks, LoopTool-8B achieves state-of-the-art performance for its scale, outperforming several models with four times more parameters. Most remarkably, the 8B LoopTool model even surpasses the 32B Qwen3 model—the very same model used to generate and judge its training data. This underscores how closed-loop refinement can amplify capability beyond the size of the teacher model.
The Power of Iteration
To demonstrate that iteration itself drives improvement, the team compared performance across four rounds of training with and without their adaptive loop.
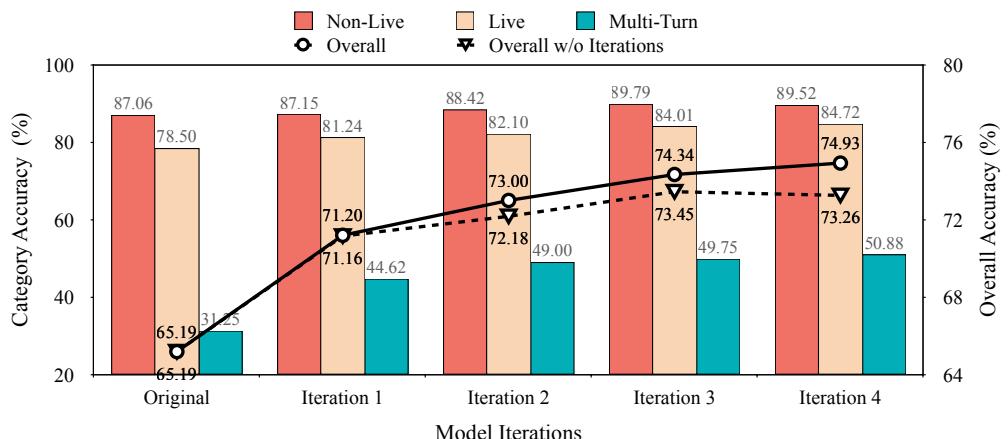
Figure 3: Iterative performance on BFCL-v3. LoopTool’s adaptive training curve rises steadily, while static data training quickly plateaus.
Each iteration produced consistent accuracy gains. In contrast, static training on the same seed dataset quickly hit diminishing returns. Without the self-evolving data curriculum, the model exhausted the available learning signal and began to overfit—highlighting the necessity of dynamic feedback.
Why Every Component Matters
An extensive ablation study confirmed that every module in LoopTool plays a critical role.
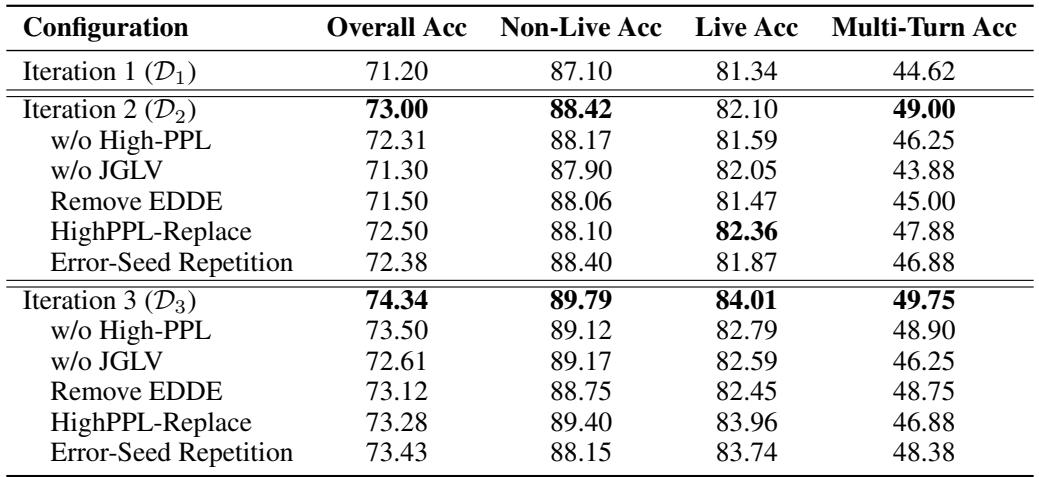
Table 3: Ablation study results. Removing any component—such as label verification or data expansion—hurts overall performance.
- Without JGLV (Label Verification): Accuracy dropped sharply. This shows that purifying noisy labels is essential to maintaining high-quality supervision.
- Without EDDE (Data Expansion): The system lost its ability to improve on tough cases. Reusing the same error examples yielded only marginal benefits, while EDDE-generated samples enabled broader generalization.
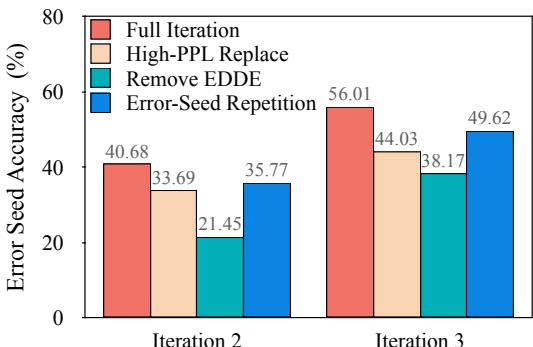
Figure 4: Comparison on original “error seed” samples. The full LoopTool setup with EDDE (red) produces the strongest recovery on historically difficult examples.
Together, these experiments show that LoopTool’s synergy—the interplay between diagnosis, correction, and targeted new data—is the secret to sustainable improvement.
Conclusion: Smarter, Self-Correcting AI Training
LoopTool signals a paradigm shift in training intelligent agents. Rather than relying on static, one-way pipelines, it builds a closed, self-refining ecosystem where data and models co-evolve. By continuously:
- Diagnosing weaknesses through Greedy Capability Probing,
- Purifying datasets via automatic label verification,
- Expanding coverage with error-driven data synthesis,
LoopTool enables smaller models to outperform larger ones trained the conventional way. The result is a robust, cost-efficient path toward smarter, more adaptive LLMs—achieved entirely using open-source tools.
The success of LoopTool demonstrates that future progress in AI may come not just from bigger models or more data, but from smarter training loops—systems that learn to improve themselves. LoopTool has closed the loop, and in doing so, has opened the door to a new era of truly adaptive, self-evolving language agents.