](https://deep-paper.org/en/paper/2511.09515/images/cover.png)
Imagine a robot that can follow your instructions: “pick up the red block and place it on the blue one.” This is the promise of Vision-Language-Action (VLA) models—a new frontier in robotics that combines vision, language understanding, and physical control. The most common way to train these models is through imitation learning: showing the robot thousands of examples of human demonstrations and having it mimic these behaviors.
But what happens when the robot makes a small mistake? If it encounters a situation it hasn’t seen in its training data, an imitation-trained policy can become brittle. It may push against an obstacle indefinitely or get stuck in a loop—unable to recover—because it only knows how to copy success, not how to learn from failure.
Reinforcement Learning (RL) offers a classic solution. It allows an agent to learn through trial and error, receiving rewards for success and penalties for failure. However, applying RL directly in the real world is a logistical nightmare: millions of interactions that are slow, expensive, and potentially dangerous for the robot and its surroundings.
So how can we give robots the powerful self-improvement capabilities of RL without the prohibitive cost of real-world trials? This is the central question addressed by a new research paper, “WMPO: World Model-based Policy Optimization for Vision-Language-Action Models.” The authors propose a fascinating solution—let robots learn in their imagination.
By training a high-fidelity “world model” that can simulate the physical world, a robot can practice, fail, and learn from its mistakes entirely in a simulated environment. This approach makes learning efficient, scalable, and far safer.
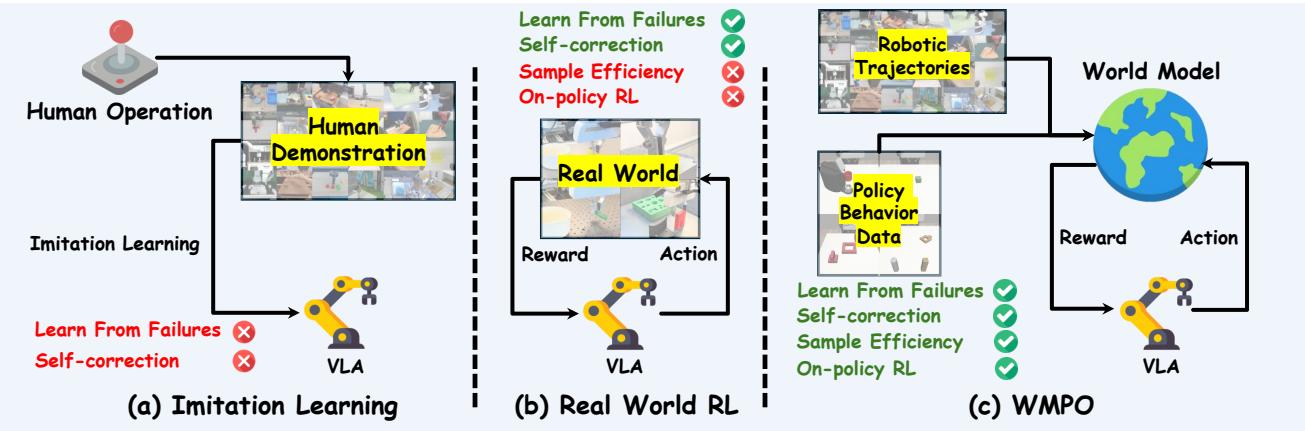
Figure 1. Three VLA training paradigms. WMPO bridges the gap between imitation learning and real-world RL, enabling sample-efficient on-policy learning within a learned world model.
The Challenge: Between Imitation and Interaction
Before diving into WMPO’s mechanics, let’s frame the landscape.
Vision-Language-Action (VLA) Models. VLAs map visual inputs and natural language instructions into robotic actions. They’re usually built on large vision-language foundation models and fine-tuned on datasets of robotic trajectories. Given a command like “open the drawer,” they interpret the visual scene and predict motor actions to achieve it. Despite their power, their reliance on imitation learning makes them brittle in unanticipated situations.
Reinforcement Learning (RL). RL helps agents learn from interaction. Through exploration, an RL policy learns to avoid mistakes and recover from failures by optimizing cumulative reward. The limitation is physical interaction: each trial uses real-world resources and time, which makes scaling nearly impossible.
World Models. A world model learns to predict how the environment evolves in response to actions. Given the current video frame and a robot action, it can “imagine” the next frame—essentially allowing virtual experimentation. Earlier world models operated in latent space, i.e., compressed representations of reality. But VLAs, pretrained on pixel-level visual data, expect realistic images—not abstract embeddings. The WMPO researchers argued that a pixel-based video world model is essential for consistency and compatibility with pretrained VLAs.
The WMPO Framework: Learning Inside the Machine’s Imagination
WMPO is a framework for policy optimization that happens entirely within a learned, pixel-based world model—a kind of Matrix for robot training. It operates as a closed learning loop where the policy and the world model interact continuously.
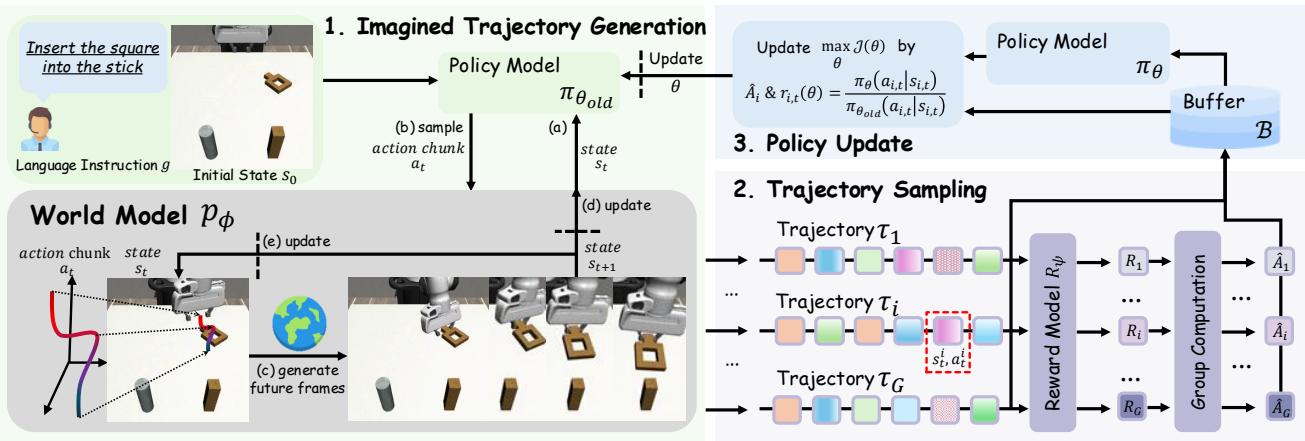
Figure 2. WMPO’s three-component loop: (1) imagined trajectory generation; (2) trajectory evaluation via a learned reward model; and (3) policy updates based on success and failure signals.
Let’s unpack these components.
1. The Generative World Model: The Dream Engine
The world model is the heart of the system. It simulates the robot’s world—producing “imagined” trajectories that combine realistic visuals with plausible robot actions.
Here’s how the cycle unfolds:
- The policy model \( \pi_{\theta} \) takes recent image frames and a language instruction as inputs.
- It predicts the next sequence of actions.
- The world model \( p_{\phi} \) uses these actions and previous frames to generate new frames: \[ I_{i:i+K} \sim p_{\phi}(I_{i-c:i}, a_{i:i+K}) \]
- Repeating this step forms a full imagined trajectory showing how the robot interacts with its environment.
To make the world model robust and realistic, WMPO introduced several innovations:
- Pixel-space generation: Rather than a low-dimensional latent representation, WMPO’s world model generates full-resolution frames using a 2D VAE. This ensures consistency with the visual data on which the VLA was pretrained.
- Noisy-frame conditioning: Autoregressive generation can accumulate errors over time, causing blur or drift. To combat this, input frames are slightly perturbed with noise during training. This makes the model resilient to imperfections in long sequences.
- Policy behavior alignment: The world model is first trained on massive data (Open X-Embodiment) but fine-tuned using a small number of trajectories from the current policy. This teaches it not only success but also the types of failures the policy might produce—allowing it to faithfully imagine both winning and losing scenarios.
2. The Reward Model: The Dream Judge
To evaluate imagined trajectories, WMPO relies on a learned reward model \( R_{\psi} \).
Instead of manually labeling thousands of videos, this compact classifier is trained on a modest real dataset to distinguish success and failure clips. During WMPO training, it reviews each imagined trajectory and assigns a sparse reward—1 for success, 0 for failure.
This automated signal guides the policy’s learning efficiently, reducing the need for costly manual supervision.
3. On-Policy Reinforcement Learning: Learning from Imagination
Once we can simulate and evaluate trajectories, the policy optimization begins. WMPO solves two major RL bottlenecks:
- Physical Interaction Bottleneck: Instead of executing millions of real actions, WMPO performs all training in the world model—no hardware wear, no safety risks.
- Off-Policy Bias: Traditional RL often uses off-policy data, which causes unstable value estimates. WMPO’s imagined environment allows on-policy training with the Group Relative Policy Optimization (GRPO) algorithm.
Here’s the essence of the GRPO loop:
- Trajectory Sampling: From one starting state, multiple imagined trajectories are sampled. The world model can reset to identical conditions—a capability impossible in physical settings. To maintain balanced learning, WMPO adopts Dynamic Sampling: if all trajectories succeed or all fail, they’re discarded and resampled.
- Policy Update: The policy is then adjusted to increase the likelihood of actions that led to success and decrease those that led to failure. The mathematical form looks complex: \[ \mathcal{J}(\theta) = \mathbb{E}\bigg[\frac{1}{G} \sum_{i=1}^{G}\frac{1}{T} \sum_{t=0}^{T} \min\!\left(r_{i,t}(\theta)\hat{A}_i, \text{clip}(r_{i,t}(\theta))\hat{A}_i\right)\bigg] \] with \(r_{i,t}(\theta)=\frac{\pi_{\theta}(a_{i,t}\mid s_{i,t})}{\pi_{\theta_{\text{old}}}(a_{i,t}\mid s_{i,t})}\), \( \hat{A}_i=\frac{R_i-\text{mean}(\{R_i\})}{\text{std}(\{R_i\})} \).
Conceptually: if a trajectory’s result was better than average, the policy strengthens the probability of its actions; if worse, it dampens them. The clipping terms keep updates stable.
Does Dreaming Work? The Empirical Results
The researchers validated WMPO in both simulated environments and on real robots—and the results are striking.
Superior Performance and Sample Efficiency
In simulation benchmarks with four manipulation tasks, WMPO was tested against online GRPO (RL within the physical environment) and offline DPO (a preference-based method).
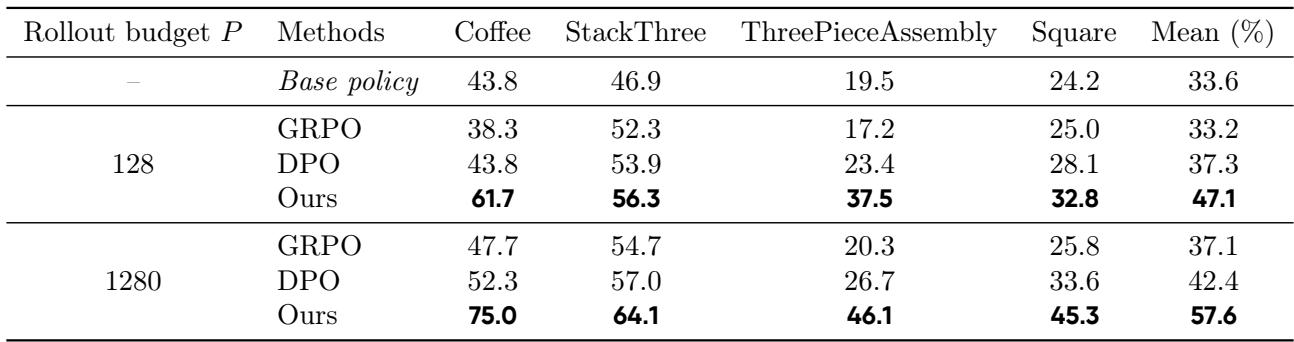
Table 1. WMPO achieves higher success rates with far fewer real trajectories, proving its sample efficiency and scalability.
Even with only 128 real trajectories used to fine-tune the world model, WMPO outperformed the best baseline by nearly 10 percentage points. As the rollout budget grew to 1280, its advantage widened further—demonstrating that WMPO scales efficiently with additional data.
Emergent Self-Correction
Beyond raw performance, WMPO-trained policies exhibited new behaviors absent in the training demonstrations—especially self-correction.
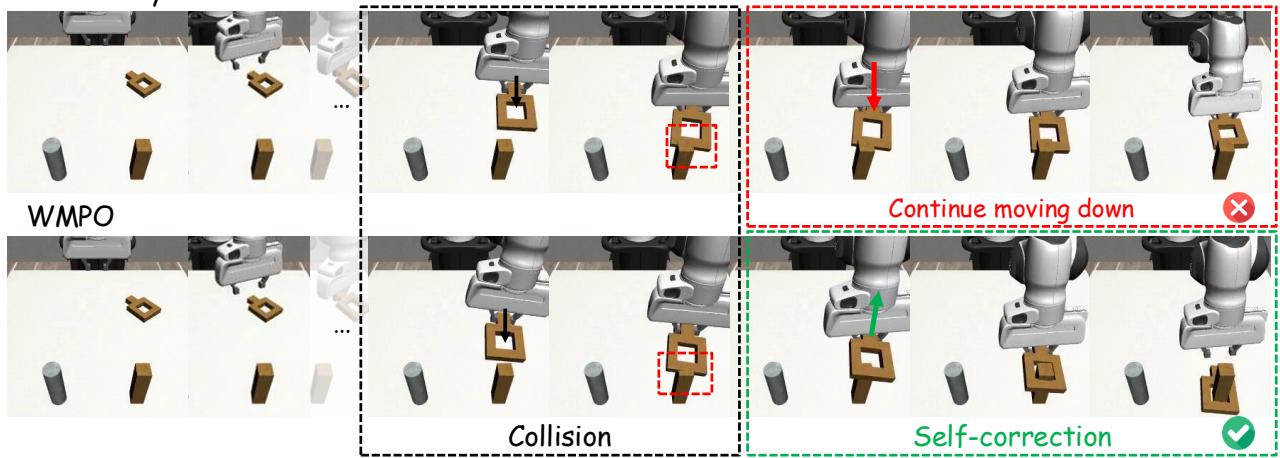
Figure 3. The WMPO-trained robot anticipates a collision, lifts the block, realigns, and succeeds—displaying learned self-correction.
In the “Square” insertion task, for example, the imitation policy continued to push a block against an obstacle until failure. WMPO’s policy, having imagined similar failures, instead lifted, realigned, and inserted successfully. This emergent adaptability marks a major step toward genuine learning.
Additionally, WMPO-trained policies executed tasks more smoothly and efficiently.
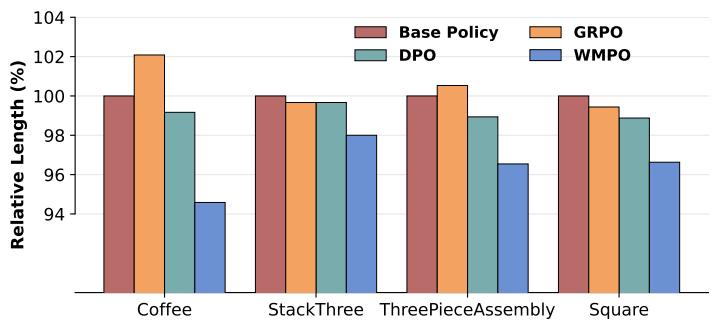
Figure 5. WMPO’s successful trajectories are shorter and more efficient than others, indicating reduced “stuck” behavior.
Generalization and Lifelong Learning
A strong robot policy should generalize beyond training conditions. WMPO excelled when tested under spatial, background, and texture variations.
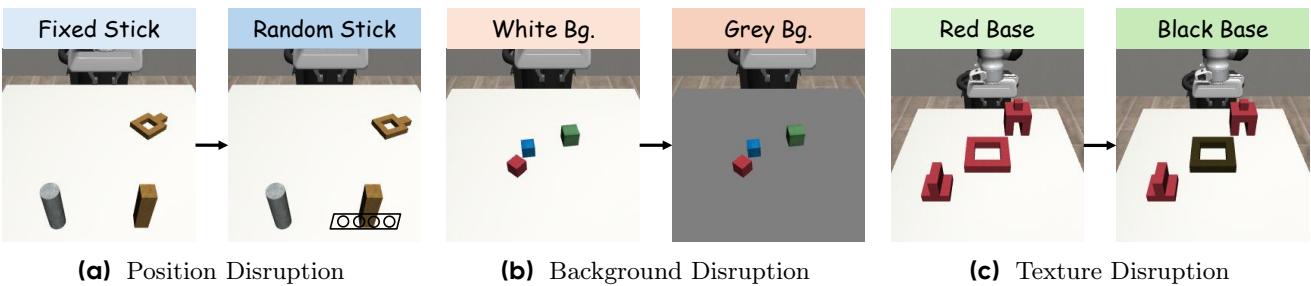
Figure 4. WMPO maintains stable performance under varied conditions, showing strong generalization.
While baselines degraded under unseen backgrounds or surfaces, WMPO sustained higher success rates—proof that learning within its imagination produced transferable skills.
Moreover, WMPO supports lifelong learning. After deployment, the robot can collect new data from its own experiences, retrain its world model, and continue refining the policy. Experiments showed this iterative process yielded consistent improvement, while other methods like DPO became unstable.
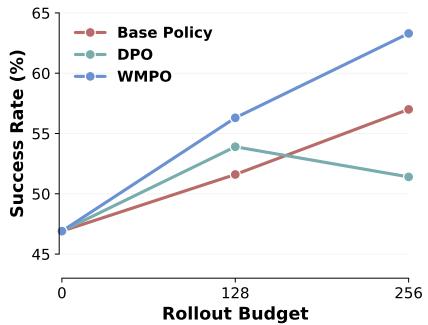
Figure 6. WMPO’s iterative improvement demonstrates its ability to learn continuously from new data.
Real-World Success
Finally, the researchers evaluated WMPO on a real robot performing the challenging insert-the-square-into-the-stick task with only 5 mm of clearance.

Figure 7. The world model accurately predicts real-world task dynamics from the same initial state.
Even without seeing these motions during training, the world model’s predictions matched physical reality remarkably well. After training via WMPO, real-world performance jumped from 53% (imitation) and 60% (offline DPO) to 70% success—validating the framework’s practicality.
Conclusion: Teaching Robots to Learn from Failure
WMPO represents a new paradigm for robot learning—a bridge between imitation and true interaction. By grounding on-policy reinforcement learning in a high-fidelity, pixel-based generative world model, it allows Vision-Language-Action systems to learn from imagined successes and failures.
Its key innovations—policy behavior alignment for realistic imagination, robust autoregressive video generation, and efficient on-policy optimization—unlock scalable self-improvement without expensive real-world experimentation.
In short, WMPO enables robots to train in their dreams, letting them make mistakes, correct themselves, and emerge wiser—just like humans do.