](https://deep-paper.org/en/paper/4280_better_to_teach_than_to_g-1734/images/cover.png)
Introduction: Teaching vs. Giving
In the world of deep learning, there is an old proverb that fits surprisingly well: “Give a man a fish, and you feed him for a day. Teach a man to fish, and you feed him for a lifetime.”
In the context of computer vision, specifically Domain Generalized Semantic Segmentation (DGSS), “giving a fish” is analogous to data augmentation or generating synthetic data. If you want your self-driving car model (trained on a sunny simulator) to recognize a rainy street, the standard approach is to generate thousands of rainy images and feed them to the model. While this works to an extent, it is computationally expensive and limited by the diversity of the data you can generate.
But what if we could “teach” the model the underlying laws of the scene instead? What if the model understood that “cars appear on roads” and “sky is above buildings,” regardless of whether the image looks like a photograph, a sketch, or a Van Gogh painting?
This is the premise behind QueryDiff, a novel framework proposed in the paper “Better to Teach than to Give.” Instead of just feeding the model more data, the researchers leverage the massive “brain” of a pre-trained Diffusion Model (like Stable Diffusion) to teach the segmentation network about the underlying structure of scenes.
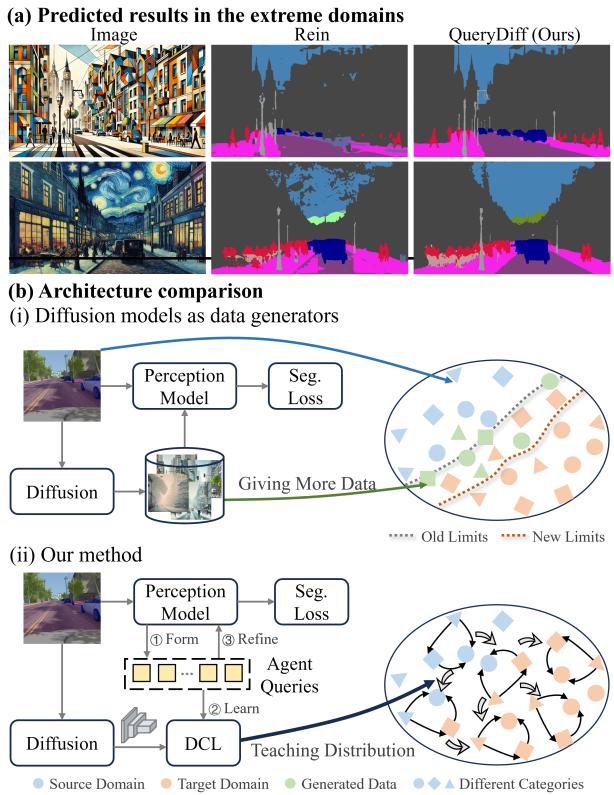
As shown in Figure 1, traditional methods (b-i) use diffusion models as data generators. QueryDiff (b-ii) uses diffusion models as teachers. The result? As seen in section (a), QueryDiff can segment images in extreme domains—like Cubist art—where traditional methods fail efficiently.
In this post, we will decode how QueryDiff works, diving into its unique architecture, the concept of “Agent Queries,” and how it extracts pure semantic knowledge from diffusion models without getting distracted by artistic style.
The Problem: Domain Generalization
Semantic segmentation is the task of assigning a class label (car, road, tree) to every pixel in an image. Models trained on labeled source domains (like the synthetic GTA5 video game dataset) often suffer a massive performance drop when tested on unseen target domains (like real-world Cityscapes data).
The core issue is Domain Shift. While the content is consistent (cars are still cars), the style (lighting, texture, rendering quality) changes drastically.
Most existing solutions rely on Domain Randomization—altering the visual appearance of training data to make the model robust. However, these methods often fail to capture the scene distribution: the spatial relationships and contextual dependencies between objects. A car isn’t just a metal box; it’s a metal box that sits on a road and usually below the sky. Capturing this “scene prior” is the key to robustness.
The Teacher: Diffusion Models
Before diving into the method, we need a brief primer on Diffusion Models. These generative models are famous for creating high-quality images from text prompts. They work by gradually adding noise to data (forward process) and then learning to reverse that noise to recover the image (reverse process).
The forward process is defined as:
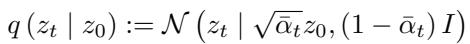
Here, \(z_0\) is the original data, and \(z_t\) is the noisy data at step \(t\).
The reverse process, which the model learns, is:
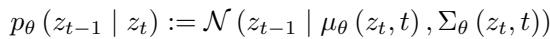
The key insight of QueryDiff is that to be good at generating images, diffusion models must implicitly learn powerful scene distribution priors. They know where objects belong. However, using diffusion models directly for segmentation is slow (due to iterative sampling) and noisy (they care about texture/color, which segmentation models should ignore).
The Solution: QueryDiff Architecture
The researchers propose a framework that uses Agent Queries as a bridge. Instead of feeding diffusion features directly into the segmentation network, the model creates “agents” that go and “ask” the diffusion model for guidance.
The architecture consists of three main stages, illustrated below:
- Agent Queries Generation: Compressing image features into query vectors.
- Diffusion-Guided Optimization: Using diffusion models to teach these queries about scene structure.
- Feature Refinement: Using the educated queries to improve segmentation.
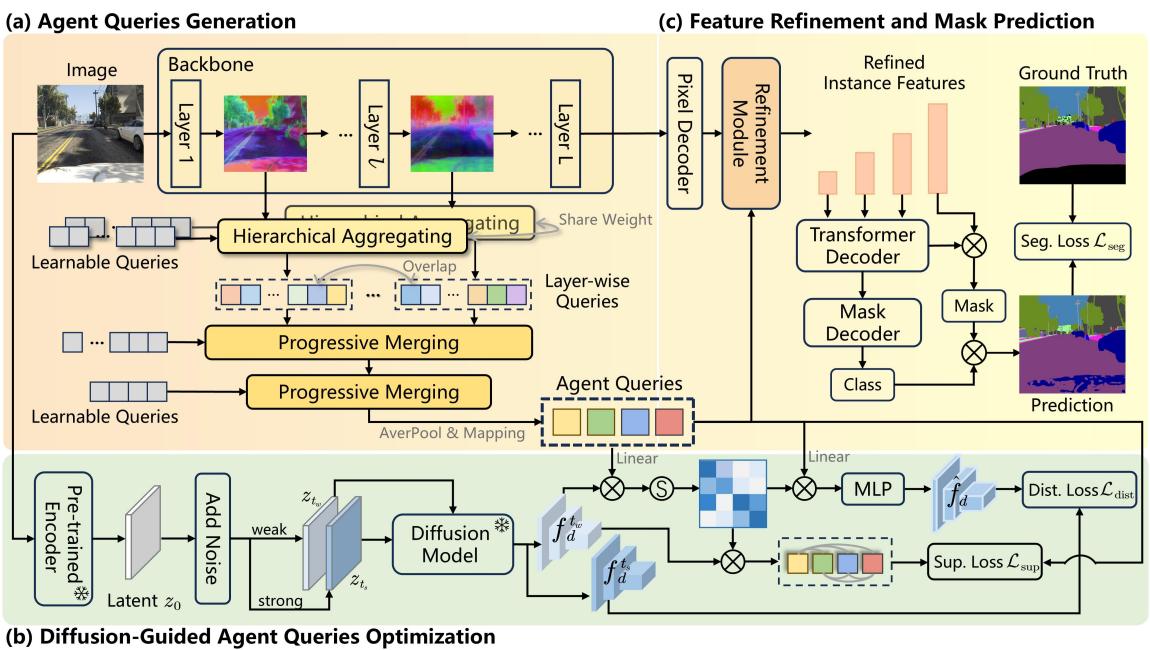
Let’s break these down step-by-step.
1. Agent Queries Generation
The first challenge is efficiency. We cannot run a heavy diffusion process for every pixel. Instead, QueryDiff aggregates information from the segmentation backbone into a small set of “Agent Queries.”
The process begins by taking hierarchical features from the backbone (like ResNet or MiT). For a feature layer \(l\), the model uses a set of learnable parameters \(q_{init}\) to extract layer-wise queries:
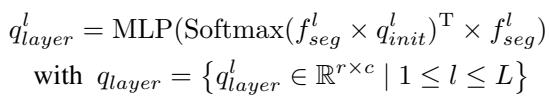
These queries represent instance-level information (e.g., “I think I see a car here”). However, different layers of a neural network see different things. To unify this, the authors use a Progressive Merging Strategy.
They merge queries from different stages using a mechanism similar to attention. Learnable queries \(q_{init}\) act as the query (\(Q\)), while the output from the previous stage acts as keys (\(K\)) and values (\(V\)):
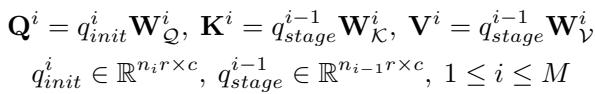
These are merged based on similarity:
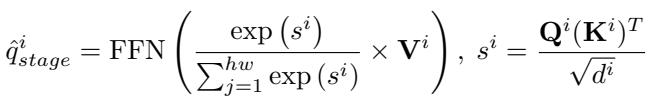
Finally, after passing through all stages, we get a unified set of Agent Queries (\(q_{agent}\)):
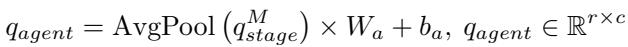
These queries now hold a condensed representation of the instances in the image. They are ready to be “taught.”
2. Diffusion-Guided Optimization
This is the core contribution of the paper. We want to inject the “wisdom” of the diffusion model into these agent queries. However, diffusion features contain two types of information:
- Scene Distribution (Semantics): “A car is on the road.” (Good for segmentation).
- Visual Appearance (Style): “The car is red and shiny.” (Bad for generalization).
To separate these, the authors exploit a property of diffusion time-steps.
- Weak Noise (\(t_w\)): Contains fine-grained details (texture, color).
- Strong Noise (\(t_s\)): Contains coarse-grained semantics (shapes, layout).
The model extracts features at both noise levels:
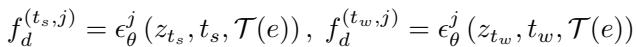
The Diffusion Consistency Loss (DCL)
The goal is to transfer the semantic knowledge without the stylistic noise. The authors propose a clever loss function called Diffusion Consistency Loss (DCL).
First, they calculate a similarity map between the Agent Queries and the Weak Noise features. The weak noise features have the structural details we want to locate objects, but also the style we want to ignore.
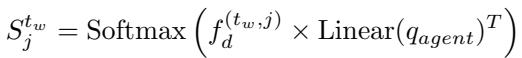
To “clean” this similarity map, they force it to reconstruct the Strong Noise features. Since strong noise features lack high-frequency details (style), forcing the reconstruction to match them ensures that the “visual details” in the weak noise map are stripped away, leaving only the structural distribution.
This is enforced via a distribution loss (KL divergence):
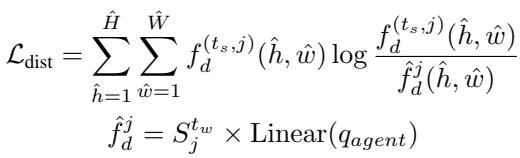
Here, \(\hat{f}_d\) is the reconstructed feature. If the similarity map \(S\) contained too much “style” information, it wouldn’t match the “structure-only” strong features.
Finally, the agent queries are updated using this “cleaned” semantic map:
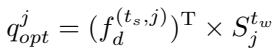
And supervised to ensure the original agent queries learn this distribution:
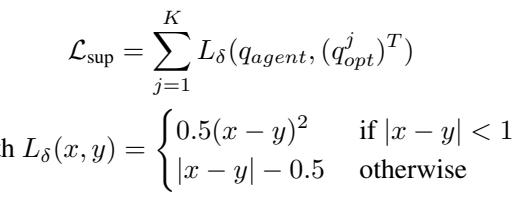
The total diffusion consistency loss combines the supervision and distribution components:
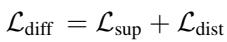
This process effectively “distills” the scene understanding of the massive diffusion model into the lightweight agent queries.
3. Feature Refinement and Prediction
Now that we have Optimized Agent Queries that understand the scene structure, we use them to refine the pixel-level features in the segmentation decoder.
This is done via a refinement module involving cross-attention. The decoder then produces masks and class probabilities. The final segmentation loss is a standard combination of Cross-Entropy and Dice loss:
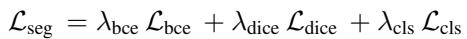
The total training objective combines the segmentation loss with the diffusion consistency loss:
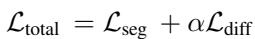
Crucially: During inference (testing), the diffusion branch is turned off. The model relies solely on the trained Agent Queries. This makes the method highly efficient at runtime.
Experiments and Results
The authors evaluated QueryDiff on standard Domain Generalization benchmarks. The classic setup involves training on synthetic data (GTA5) and testing on real-world datasets (Cityscapes, BDD100K, Mapillary).
Quantitative Performance
The results are impressive. As shown in Table 1, QueryDiff achieves state-of-the-art (SOTA) performance across different backbones (ResNet, MiT, DINOv2).
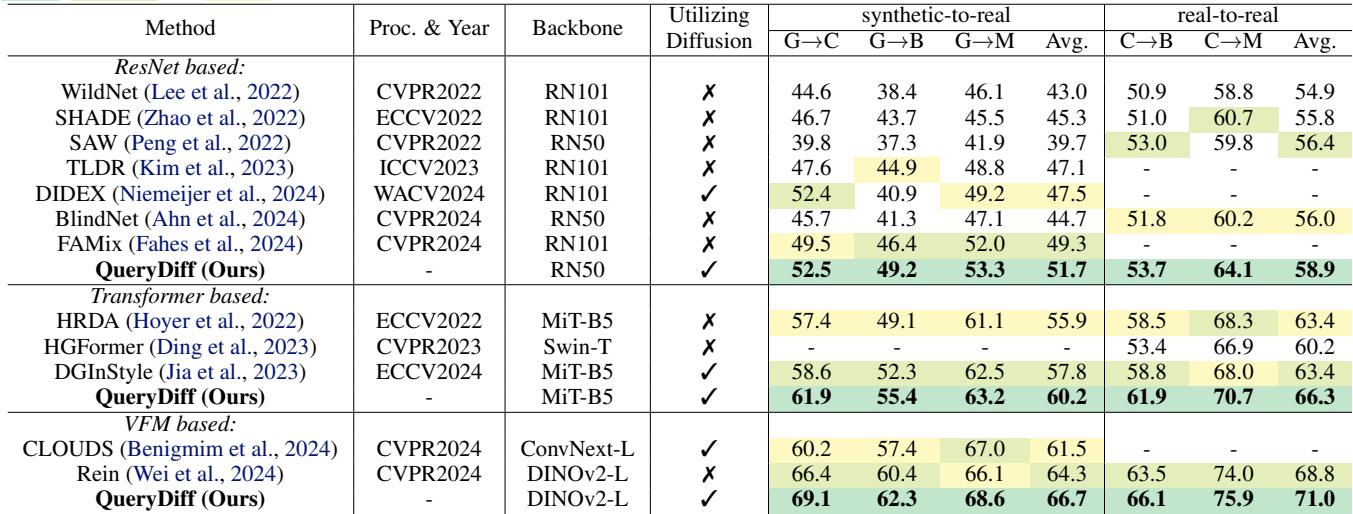
Notable takeaways:
- On the GTA \(\to\) Cityscapes task with a DINOv2 backbone, QueryDiff reaches 69.1% mIoU, significantly outperforming the previous best (Rein) at 66.4%.
- It consistently beats methods that simply use diffusion for data generation (like DIDEX).
Robustness to Adverse Weather
The model was also tested on generalization from normal weather to adverse conditions (Fog, Rain, Snow, Night) using the ACDC dataset.
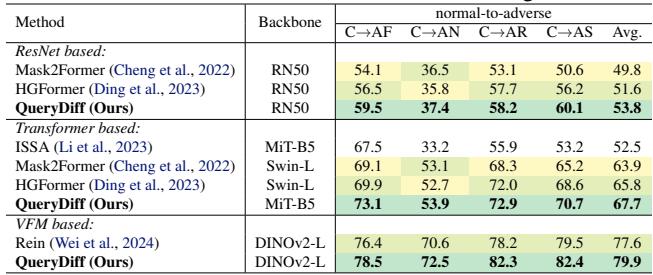
Again, QueryDiff demonstrates superior robustness, proving that learning scene distribution helps the model see through rain and darkness better than previous methods.
Visual Analysis
Qualitative results illustrate the “teaching” effect. In Figure 4, compare the predictions of Rein (center) vs. QueryDiff (right).
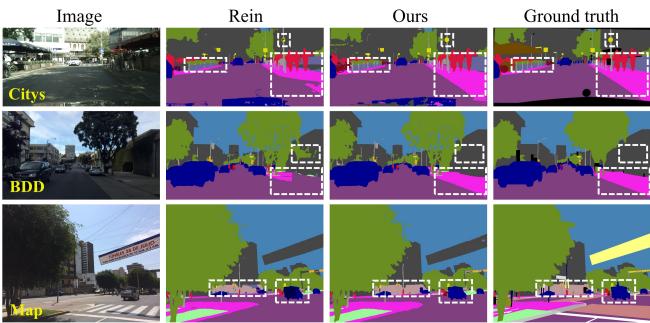
Notice the white dashed boxes. QueryDiff produces much cleaner boundaries and fewer artifacts in complex areas, closely resembling the Ground Truth.
Furthermore, looking at class-wise improvements (Figure 3), we see significant gains in “hard” classes like Riders, Motorcycles, and Trains.

Why does it work? (Ablation Studies)
The authors performed ablation studies to verify their design choices.
1. Do we need all components? Yes. Removing the Agent Queries or the specific losses (\(L_{sup}\), \(L_{dist}\)) drops performance.

2. Does the Foundation Model matter? QueryDiff improves performance regardless of whether the backbone is CLIP, SAM, or DINOv2. It effectively leverages the pre-trained knowledge of these giants.
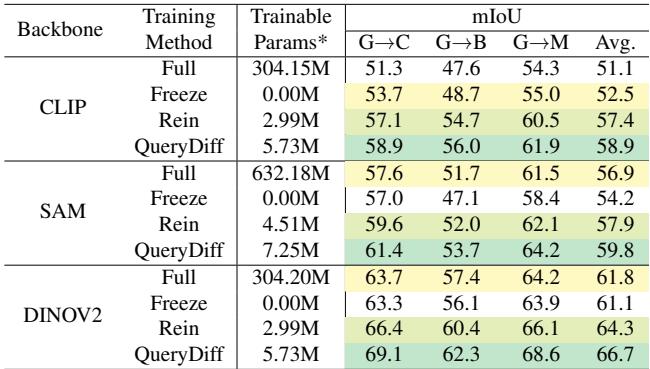
3. Does the choice of Diffusion Model matter? Interestingly, no. As shown in Table 6, using Stable Diffusion 1.4, 1.5, or 2.1 yields very similar results. This suggests the method is robust and captures universal scene priors present in all these models.

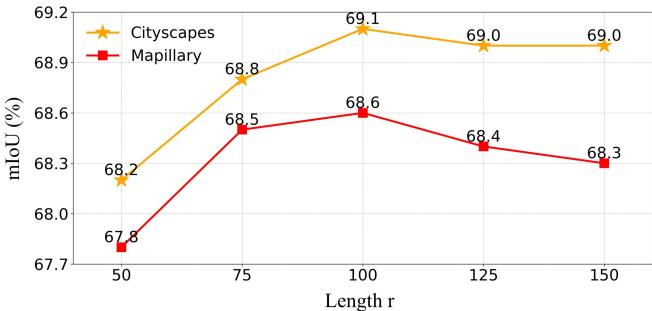
4. How many queries? The “Length \(r\)” of the agent queries refers to how many tokens are used. Figure 5 shows that performance peaks around \(r=100\). Too few queries miss details; too many might introduce noise.
Conclusion
The paper “Better to Teach than to Give” presents a compelling shift in how we approach Domain Generalization. Rather than bruteforcing the problem by generating infinite variations of training data (“giving fish”), QueryDiff extracts the deep, structural understanding of the world hidden inside diffusion models (“teaching to fish”).
By using Agent Queries as a lightweight interface and Diffusion Consistency Loss to filter out style, QueryDiff achieves state-of-the-art results on semantic segmentation. It allows models trained on video games to navigate real-world streets—even if those streets are painted in the style of Cubism.
This framework not only improves accuracy but also efficiency, as the heavy diffusion model is discarded after training, leaving behind a smarter, more robust segmentation network.