](https://deep-paper.org/en/paper/6011_efficient_and_separate_au-1708/images/cover.png)
Imagine you want to send a sensitive blueprint to a colleague. You don’t want to use standard encryption because a file named top_secret_plans.enc screams “look at me!” to any interceptor. Instead, you decide to hide the blueprint inside a harmless photo of a cat. This is steganography: the art of hiding information in plain sight.
For years, researchers have used deep learning to make this process incredibly effective. However, there has been a glaring security hole. In most existing systems, if you have the “reveal” network, you can see everything hidden in the image. There is no concept of a “key” or specific user authentication. If you hide five different secret images for five different people in one cover photo, anyone with the decoder sees all five.
Today, we are doing a deep dive into a fascinating paper titled “Efficient and Separate Authentication Image Steganography Network” (AIS). The researchers propose a novel architecture that not only introduces secure “locks” and “keys” to image hiding but does so while drastically reducing the model size and improving image quality.
If you are a student of computer vision or cybersecurity, this paper bridges the gap between generative deep learning and secure communication. Let’s break down how they did it.
The Problem: The “All-or-Nothing” Flaw
Traditional deep learning steganography usually employs Invertible Neural Networks (INNs). These networks are fantastic because they don’t lose information—they map data forwards (hiding) and backwards (revealing) perfectly.
However, current methods suffer from three critical defects:
- No Authentication: As mentioned, it’s an all-or-nothing access model. See Figure 1 below. In traditional methods (a), anyone with the receiver network gets the secret. In the proposed AIS method (b), specific keys are required.
- Quality Degradation: Authentication usually requires embedding extra “lock” information (like a password hash) into the image. This “noise” fights for space with the actual image data, lowering the quality of the final picture.
- Bloated Models: To hide multiple images (e.g., one for Alice, one for Bob), traditional methods run networks in series. To hide 5 images, you effectively need 5 stacked networks. This makes the model heavy and slow.

The researchers set out to prove that you can add authentication without ruining the image quality or making the model massive.
The Challenge: Why Encryption Hurts Quality
Before looking at the solution, we need to understand the mathematical friction between authentication and steganography.
When you introduce a “lock” or a key into a neural network, you are essentially introducing a condition. The network needs to learn a distribution of data where the output changes based on that condition.
The researchers analyzed this by comparing “Authentication-free” methods against standard “Authentication-based” methods.
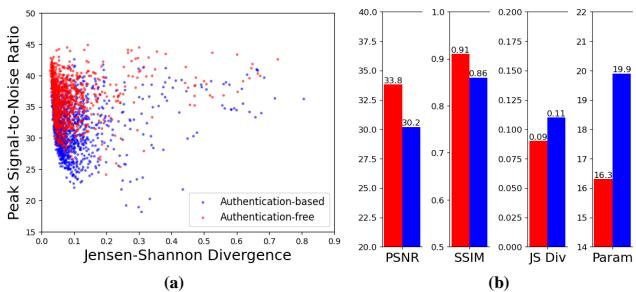
As shown in Figure 2 above:
- Graph (a): The blue dots (Authentication-based) generally show higher Divergence (more difference from the original) and lower PSNR (lower quality) than the red dots.
- Chart (b): Adding locks drops the PSNR from ~33.8 dB to ~30.2 dB.
Why? Because “lock” information looks like random noise (high entropy), while natural images have structure (lower entropy). Forcing a network to hide both a structured image and a noisy lock into a single cover image creates a “distribution mismatch.” The lock occupies valuable hiding space, degrading the visual results.
The Solution: The AIS Architecture
The researchers propose the Efficient and Separate Authentication Image Steganography Network (AIS).
The genius of this architecture is that it splits the problem into two distinct stages handled by two specialized networks:
- IAN (Invertible Authentication Network): Handles the “locking” and prepares the data.
- IHN (Invertible Hiding Network): Handles the actual embedding into the cover image.
Let’s look at the detailed architecture:
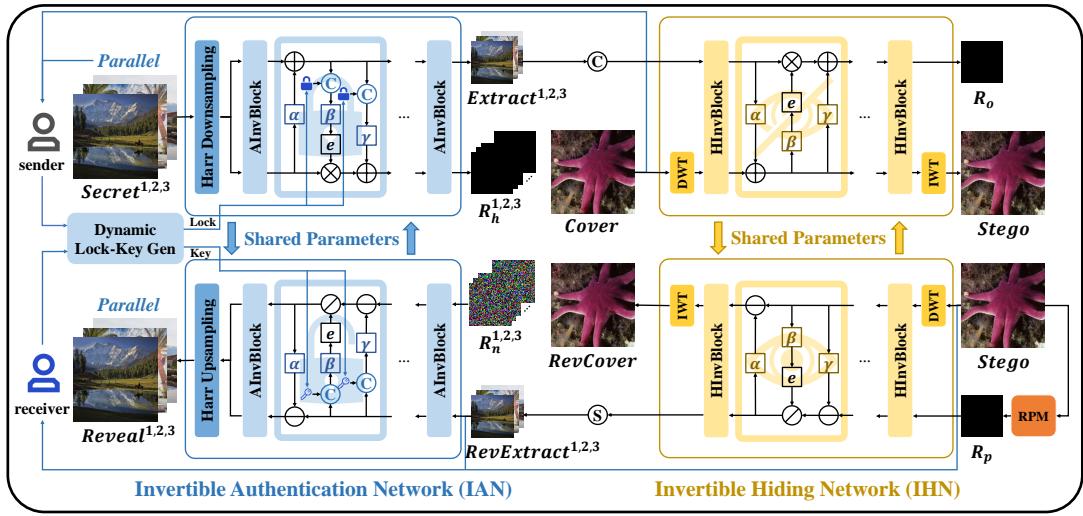
Stage 1: The Invertible Authentication Network (IAN)
The IAN is the “bouncer” of the system. It doesn’t touch the cover image yet; it only deals with the secret images. Its job is twofold: Security and Distribution Adaptation.
Dynamic Lock Generation
Static keys (like a single password for everyone) are risky. If one leaks, the whole system is compromised. AIS uses a Dynamic Generation Module.
It takes features from the specific secret image and generates a unique, dynamic lock. This means the key to open “Secret Image A” is mathematically coupled to “Secret Image A” itself.
Distribution Adaptation & Primary Information
This is the core innovation. Instead of trying to hide the full RGB secret image plus a lock, the IAN “fuses” them.
It processes the secret image and the lock through invertible blocks. The network learns to extract the most essential features—called Primary Information (\(S_c\))—and mixes the lock into this data.
By doing this, the network converts the “inconsistent” distribution of the lock and the secret image into a single, unified feature set that is easier to hide. It essentially compresses the secret and the lock into a “hiding-ready” format (\(S_c\)) consisting of just 3 channels.
The conditional probability flow can be described mathematically. The distribution of the secret image \(x\) is conditioned on the lock \(c\):
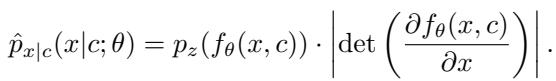
This equation ensures that the distribution of the hidden data is fundamentally altered by the lock. Without the correct lock \(c\), the distribution makes no sense, and the image cannot be recovered.
Stage 2: The Invertible Hiding Network (IHN)
Now that we have the “lock-infused primary information” (\(S_c\)), we need to hide it in the cover image. This is the job of the IHN.
Frequency Domain Processing
Notice in Figure 3 that the network uses Haar Downsampling or DWT (Discrete Wavelet Transform). Image steganography works best in the frequency domain (separating low-frequency colors from high-frequency details/edges) because the human eye is less sensitive to changes in high frequencies.
Parallel Hiding
This is where the “Efficient” part of the title comes in. In traditional methods, if you had 3 secrets, you would hide Secret 1, get a result, hide Secret 2 in that result, and so on (Serial processing).
Because the IAN has already pre-processed the secrets into compact “Primary Information,” the IHN can hide multiple secrets in parallel.
It concatenates the frequency components of the Cover Image (\(C_f\)) with the Primary Information of all secret images (\(S_c^{1,2,3}\)) and feeds them into the invertible block at once.
This single-pass approach means you only train one hiding network, regardless of how many secrets you are hiding.
Experimental Results
Does this two-stage, parallel approach actually work? The results are compelling.
1. Visual Quality
The primary goal of steganography is invisibility. The “Stego” image (cover + secret) should look identical to the original cover.

In Figure 4, look at the Residual columns (the difference between the original and the stego image, amplified x10).
- ISN and DeepMIH (Baselines): You can see significant “ghosting” or noise patterns. The hidden data is disturbing the cover image pixels.
- AIS (Ours): The residual is almost black. This means the changes to the cover image are minimal and virtually undetectable to the human eye.
The quantitative data backs this up. In Table 1 below, look at the Params (Parameters/Model Size) and PSNR (Peak Signal-to-Noise Ratio).
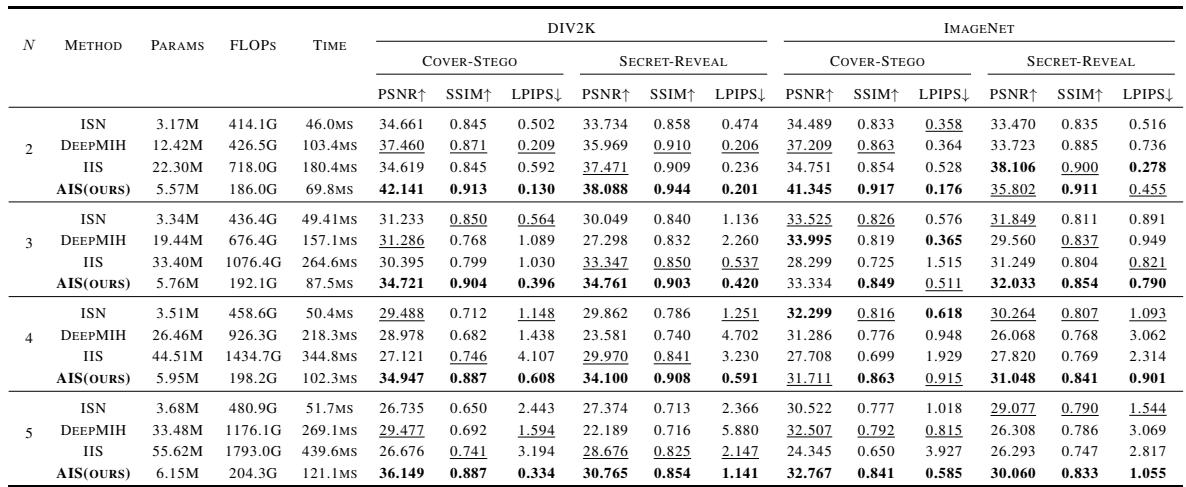
- Efficiency: When hiding 5 images (N=5), the baseline IIS requires 55.62 Million parameters. AIS requires only 6.15 Million. That is a massive reduction, making the model lightweight enough for mobile or edge devices.
- Quality: AIS consistently scores higher PSNR (better quality) for both the Stego image and the Revealed Secret.
2. Security Analysis
The “Separate Authentication” claim needs to be tested. What happens if you try to unlock the image with the wrong key?
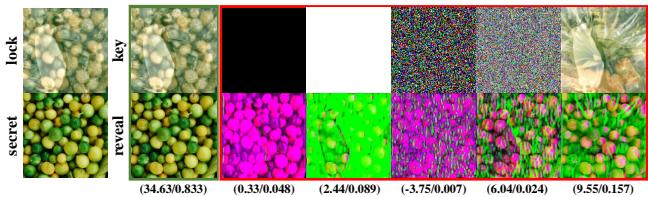
Figure 5 shows the result of using incorrect keys (random noise, all zeros, or a key from a different image). The output is unrecognizable static. This confirms that the IAN successfully entangled the image data with the lock. The secret image is mathematically inaccessible without the precise key.
3. Steganalysis (Anti-Detection)
There are AI models designed specifically to catch steganography (Steganalysis). A robust method should fool these detectors.
The researchers tested AIS against ManTraNet, a state-of-the-art forgery detection network.
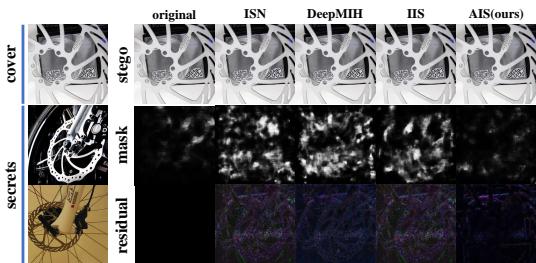
In Figure 6, the white pixels represent areas where ManTraNet thinks something is hidden.
- DeepMIH / IIS: The detector lights up, clearly outlining the hidden objects.
- AIS: The output is mostly black. The modifications made by AIS are so subtle and well-distributed that the detector fails to find the anomalies.
Why It Works: The Power of Distribution Adaptation
You might wonder, why does separating the process into two stages work so much better?
The researchers argue that the “Distribution Adaptation” in the first stage (IAN) is the key. By fusing the lock and secret before hiding, the network creates a new data representation that is more compatible with the cover image.
We can visualize this difference:

In Figure 10:
- Row (a): Shows the raw “Locks” used in one-stage methods. They look like greenish, messy noise. Hiding this “mess” is hard.
- Row (b): Shows the “Primary Information” extracted by AIS. It looks like a purple-tinted version of the original image. It retains structure. Hiding structured data inside structured data (the cover) is much easier for a neural network than hiding random noise.
Furthermore, statistical analysis confirms this. Figure 7(b) compares the statistical spread (mean vs. std dev) of the data.
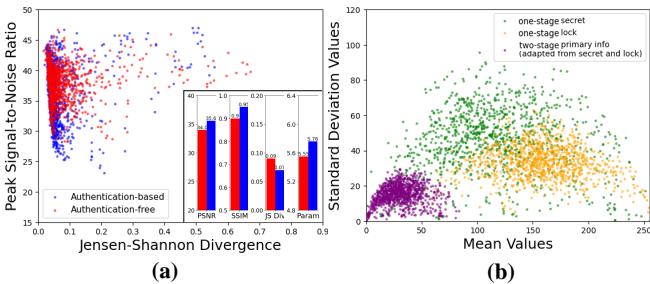
The purple dots (AIS Primary Info) are clustered differently than the raw secrets or locks, indicating that the network has learned a compact representation that minimizes the “hiding footprint.”
Large Capacity Potential
Finally, just how much can you hide? Because the model extracts only necessary “primary” information, it saves space. The researchers pushed the model to hide 8 different secret images inside a single cover.

As seen in Figure 9, even with 8 hidden images, the “Stego” image (top left columns) looks remarkably clean, and the revealed secrets (middle columns) are highly detailed. This level of capacity is difficult for traditional serial methods to achieve without destroying the cover image.
Conclusion
The Efficient and Separate Authentication Image Steganography Network (AIS) represents a significant step forward in secure data hiding. By rethinking the architecture—moving from a monolithic “hide everything” block to a specialized Authentication Stage followed by a Parallel Hiding Stage—the authors solved the triangle of trade-offs:
- Security: Achieved via dynamic, learnable locks.
- Quality: Achieved via distribution adaptation and frequency-domain embedding.
- Efficiency: Achieved via parallel processing, reducing model parameters by nearly 90% in large-capacity scenarios.
For students and researchers, this paper illustrates a valuable lesson in deep learning design: sometimes, decoupling a complex problem into specialized sub-networks is far more effective than trying to force a single network to learn conflicting tasks (like hiding structured images and random locks) simultaneously.
The full code for this project is available on GitHub for those who want to experiment with generating their own locked stego-images.