](https://deep-paper.org/en/paper/file-2856/images/cover.png)
Introduction: The Teacher’s Dilemma
If you have ever taught a class or mentored a junior colleague, you know the struggle: giving good feedback is hard. Giving good feedback at scale is nearly impossible.
In the world of education, feedback is the engine of improvement. A student writes an essay, receives comments, and (hopefully) revises the work to make it better. This cycle helps students develop critical thinking, self-assessment skills, and mastery of the subject. However, for educators, providing detailed, actionable, and personalized feedback for dozens or hundreds of students is an overwhelming time sink.
Enter Large Language Models (LLMs). Tools like GPT-4 and Llama have shown incredible prowess in generating text. Naturally, the education technology sector is buzzing with the idea of using these models to grade papers and offer feedback. But there is a massive, often overlooked problem: Just because an AI can write well doesn’t mean it knows how to teach.
Most current AI feedback systems are prompted to “act like a teacher,” but we don’t actually know if their feedback helps students improve. Does a polite suggestion help more than a direct correction? Does the AI focus on surface-level grammar or deep argumentation?
To solve this, researchers from the University of Michigan and ETH Zürich have proposed a novel framework called PROF (PROduces Feedback). Their approach flips the script: instead of training an AI on what feedback looks like, they train it based on what works. And to do this without experimenting on thousands of real students, they built something ingenious: Student Simulators.
In this post, we will dive deep into the PROF paper, exploring how they created a closed-loop system where AI teachers learn from AI students, resulting in feedback that is not only effective but pedagogically sound.
The Core Problem: The “Black Box” of Effectiveness
Before understanding the solution, we must understand why training an AI to give feedback is so difficult.
In standard Machine Learning, we train models using “Ground Truth”—verified, correct answers. If we want a model to classify images of cats, we show it thousands of pictures labeled “cat.” But in writing instruction, there is no single “correct” feedback.
- Subjectivity: Different teachers prioritize different things (grammar vs. content).
- Effectiveness is delayed: We only know if feedback was good after the student revises the essay.
- Data Scarcity: We have millions of essays, but very few datasets containing the Essay \(\rightarrow\) Feedback \(\rightarrow\) Revised Essay triplet.
Collecting this data with real humans is slow and potentially unethical (you don’t want to give bad experimental feedback to real students just to see what happens). This is where the PROF method comes in.
The PROF Pipeline: A Feedback Loop
The researchers’ hypothesis was simple but powerful: Effective feedback is defined by the quality of the revision it inspires.
If an AI suggests a change, and the resulting essay is significantly better, that feedback was “good.” If the resulting essay is worse or unchanged, the feedback was “bad.”
To operationalize this, they built a pipeline consisting of two main AI agents:
- The Feedback Generator: The model trying to learn how to teach.
- The Student Simulator: A model trained to act like a student revising their work.

As shown in Figure 1, the process works in a loop:
- Initial Writing: The process starts with a draft essay (\(x^j\)).
- Generation: The Feedback Generator (\(M_t\)) looks at the essay and proposes several different pieces of feedback (\(f_k\)).
- Simulation: The Student Simulator (\(S\)) takes the essay and the feedback, then rewrites the essay (\(y_k\)).
- Evaluation: A “Judge” (in this case, GPT-4 acting as an essay grader) scores the revised essays.
- Preference Creation: The system identifies which feedback led to the best revision (\(f_+\)) and which led to the worst (\(f_-\)).
- Optimization: The Feedback Generator is updated to produce more of \(f_+\) and less of \(f_-\) in the future.
This creates a self-improving cycle. The model isn’t just mimicking human teachers; it is optimizing for the outcome of the student’s revision.
The Optimization Mathematics (Simplified)
The training mechanism uses a technique called Direct Preference Optimization (DPO). Unlike traditional Reinforcement Learning (which creates a complex reward model), DPO optimizes the language model directly based on preference pairs (better vs. worse).
The goal is to update the model (\(M_{t+1}\)) to minimize the loss function:
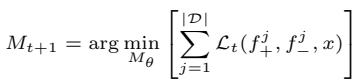
The loss function itself is designed to increase the probability of generating the “winning” feedback while decreasing the probability of the “losing” feedback. It looks like this:
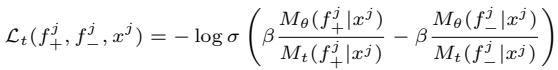
In simple terms, the equation pushes the model to distinguish between helpful and unhelpful advice, using the “Simulated Student’s” performance as the ground truth.
The Student Simulator: Faking the Classroom
The entire PROF pipeline relies on the Student Simulator being realistic. If the simulator blindly accepts every suggestion (even bad ones), the Feedback Generator will learn to just boss the student around. If the simulator is too random, the Generator won’t learn anything.
The researchers trained their simulators (using Llama-3-8b and GPT-3.5) on a dataset from an Economics 101 course. The data included initial essays, peer feedback, and the final revised essays submitted by real students.
How “Human” are the Simulators?
To test realism, the authors adjusted the “Temperature” of the model. In AI, temperature controls creativity or randomness. Low temperature means the model is predictable; high temperature makes it wilder.
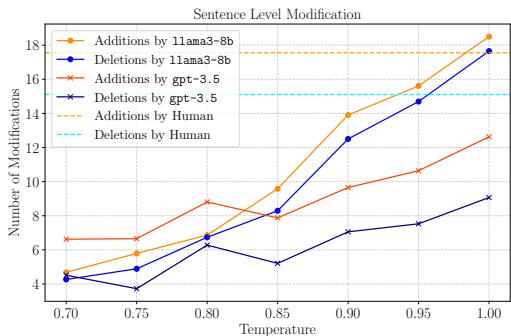
Figure 2 shows a fascinating trend. As temperature increases (x-axis), the simulators make more modifications (additions and deletions).
- The dashed/dotted lines (AI Simulators) show a sharp increase in changes as temperature rises.
- The horizontal lines (Human) show the static baseline of real student behavior.
This tells us that we can “tune” the simulator to behave like different types of students—conservative revisers who barely touch their draft, or radical revisers who rewrite everything.
However, quantity isn’t quality. Do the simulators actually improve the essays?
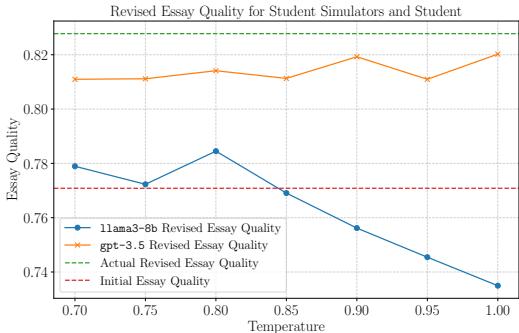
Figure 3 reveals a gap. The green dotted line at the top represents Actual Revised Essay Quality (what real students achieved). The orange (GPT-3.5) and blue (Llama-3-8b) lines are the simulators.
- Takeaway: Real students are still better at revising than AI simulators. They are more effective at integrating feedback to boost their score.
- Implication: This actually makes the training harder for the PROF model. It has to give really good feedback to get these “stubborn” AI simulators to improve their scores.
Faithfulness: Do Simulators Listen?
One of the funniest (and most human) findings was about “faithfulness.” Just because you give a student feedback doesn’t mean they will listen.
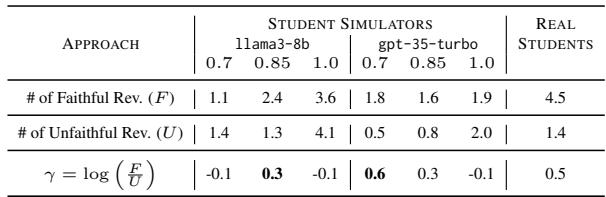
Table 1 compares “Faithful Revisions” (doing what was asked) vs. “Unfaithful Revisions” (doing something random). Real students (Right column) generally have a high ratio of faithful revisions. The simulators, especially at higher temperatures, tend to “hallucinate” revisions—making changes that weren’t asked for. The researchers had to carefully select the right temperature (0.85) to balance realism with responsiveness.
Does PROF Actually Work? (The Results)
The researchers pitted their PROF model (based on a relatively small 8-billion parameter Llama-3 model) against giants: GPT-3.5 and GPT-4.
They evaluated the models in two ways:
- Intrinsic Evaluation: Does the feedback look good pedagogically?
- Extrinsic Evaluation: Does the feedback actually improve the essay?
1. Pedagogical Quality (Intrinsic)
They used GPT-4 to judge the feedback based on four educational criteria:
- RGQ: Respects Guided Questions (Did it follow the assignment rubric?)
- EAL: Encourages Active Learning (Does it make the student think?)
- DM: Deepens Metacognition (Does it identify errors and misconceptions?)
- MSSC: Motivates Student Curiosity (Is the tone positive/encouraging?)
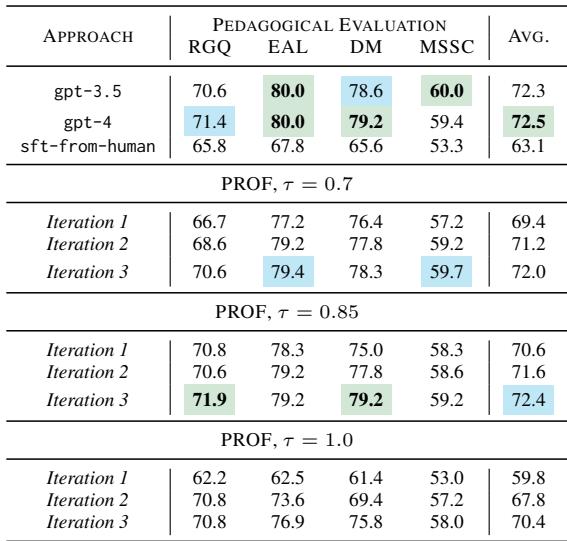
Table 2 shows the results. The baseline “sft-from-human” (Supervised Fine-Tuning on human peer reviews) scored quite low (avg 63.1).
- PROF (Iteration 3, \(\tau=0.85\)) scored 72.4, effectively matching GPT-4 (72.5) and beating GPT-3.5 (72.3).
- Key Insight: PROF achieved enterprise-level teaching quality using a much smaller, open-source model, simply by optimizing on student outcomes.
2. Implementation Utility (Extrinsic)
This is the real test. They took the feedback generated by the different models, fed it to a Student Simulator (the “test” student), and graded the final essay.
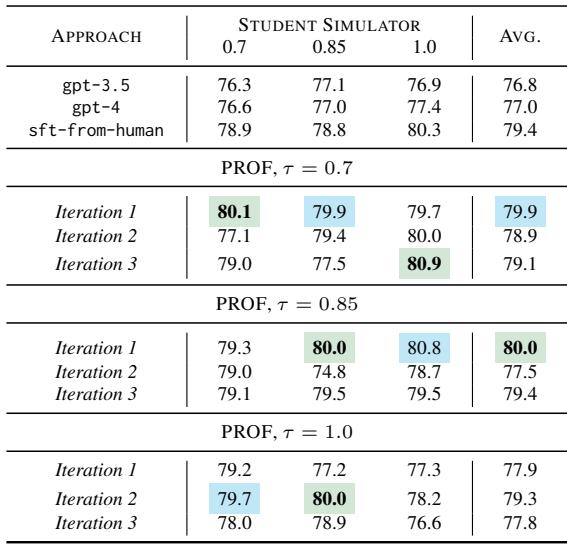
Table 3 highlights the victory of the PROF method.
- Green indicates the best performance; Blue is second best.
- PROF consistently outperformed GPT-3.5 and GPT-4 across almost all metrics.
- Even though GPT-4 is a “smarter” model, PROF was specifically optimized to cause improvement. It learned exactly what kind of prompts trigger a better revision.
What Did the AI Learn About Teaching?
One of the most profound aspects of this study is analyzing how the PROF model changed its behavior over the three iterations of training. Remember, the researchers didn’t tell the model “be nice” or “be strict.” The model purely chased higher essay scores.
The Death of Empty Praise
Educational psychology tells us that “empty praise” (e.g., “Good job!”, “Nice essay!”) feels good but doesn’t help learning. PROF discovered this mathematically.
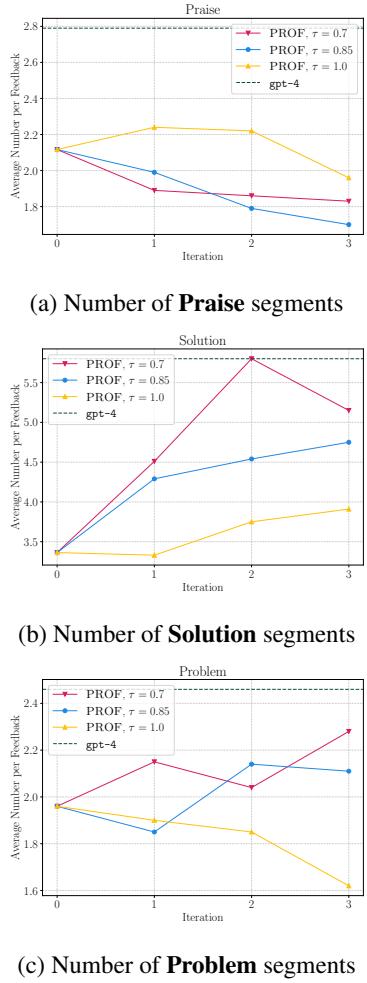
Look at Chart (a) in Figure 4. The number of Praise segments (magenta/blue/yellow lines) drops significantly as the model trains (Iterations 0 to 3). The model learned that wasting tokens on compliments didn’t improve the final essay score, so it stopped doing it.
Conversely, look at Chart (b). The number of Solution segments (actionable advice) skyrocketed. The model learned that to get a better score, it had to provide concrete solutions.
Specificity Matters
The researchers also analyzed the “scope” of the feedback—whether it was vague/global or specific/local.
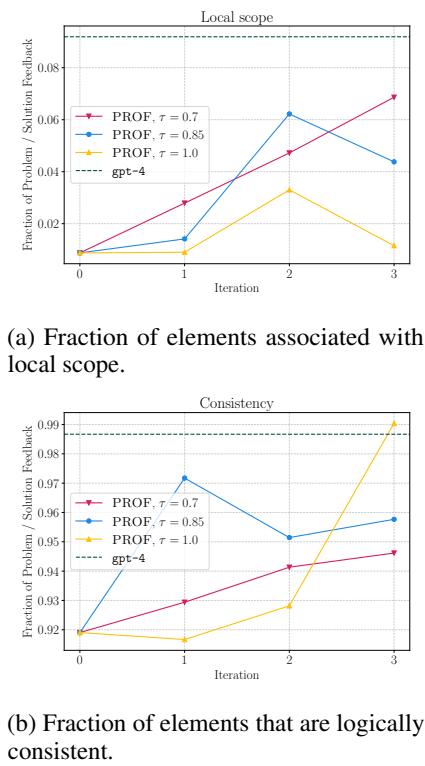
Figure 5 (a) shows that PROF learned to increase Local Scope feedback (targeting specific sentences or words). Vague feedback like “write better arguments” is hard for a simulator (and a real student) to implement. Specific feedback like “fix the supply curve definition in paragraph 3” is actionable.
Additionally, Figure 5 (b) shows that the Logical Consistency of the feedback improved over time. The model realized that giving contradictory or wrong advice led to bad revisions, so it self-corrected to become more logical.
Conclusion and Implications
The PROF paper represents a significant step forward in AI-assisted education. It moves beyond the “AI as a Content Generator” paradigm to “AI as an Outcome Optimizer.”
By closing the loop—using simulated students to test the efficacy of teaching—the researchers created a system that aligns with actual pedagogical goals without needing expensive human annotations.
Key Takeaways:
- Outcome-Based Training: We can train AIs not just to sound like teachers, but to effect change like teachers.
- Small Models can Win: A specialized 8B parameter model (PROF) outperformed the massive GPT-4 in specific teaching tasks.
- Simulations are Viable: While not perfect, “Simulated Students” are accurate enough to serve as a proxy for training, solving the data bottleneck in educational AI.
As these simulators become more “human-like” (perhaps by incorporating procrastination or misunderstanding!), the quality of the AI teachers trained on them will only increase. For now, PROF demonstrates that in the classroom of the future, the teacher might be an AI, and its first student might have been one too.