](https://deep-paper.org/en/paper/file-2930/images/cover.png)
Imagine a friend tells you, “I waved at my neighbor, but he didn’t wave back. He must hate me.” As a human, you likely recognize this as a leap in logic—perhaps the neighbor just didn’t see them. In psychology, this is known as a Cognitive Distortion (CoD)—an exaggerated or irrational thought pattern that perpetuates negative emotions, often associated with anxiety and depression.
While identifying these distortions is a critical part of Cognitive Behavioral Therapy (CBT), understanding the reasoning behind them is what truly allows for a breakthrough.
In a recent paper, researchers from IIT Patna and IIT Jodhpur introduced a groundbreaking framework called ZS-CoDR (Zero Shot Cognitive Distortion detection and Reasoning). This system doesn’t just flag a sentence as “distorted”; it watches the patient’s face, listens to their voice, reads the transcript, and then explains why the thought is distorted.
In this post, we will break down how this multimodal Large Language Model (LLM) framework works, why it outperforms text-only models, and how it could reshape mental health analysis.
The Problem: Detection is Not Enough
In the realm of Natural Language Processing (NLP) for mental health, most existing models focus on classification. They take a sentence like “I’m a total failure” and output a binary label: Cognitive Distortion: YES.
While helpful, this is insufficient for clinical settings. A therapist needs to understand the context. Is the patient catastrophizing? Are they engaging in “all-or-nothing” thinking? What triggered this thought?
To bridge the gap between AI and clinical utility, we need systems that provide Explainability. As shown in the figure below, a truly useful system identifies the emotion, detects the distortion, and provides a reasoning block explaining that the patient is interpreting a lack of evidence as confirmation of negative bias.
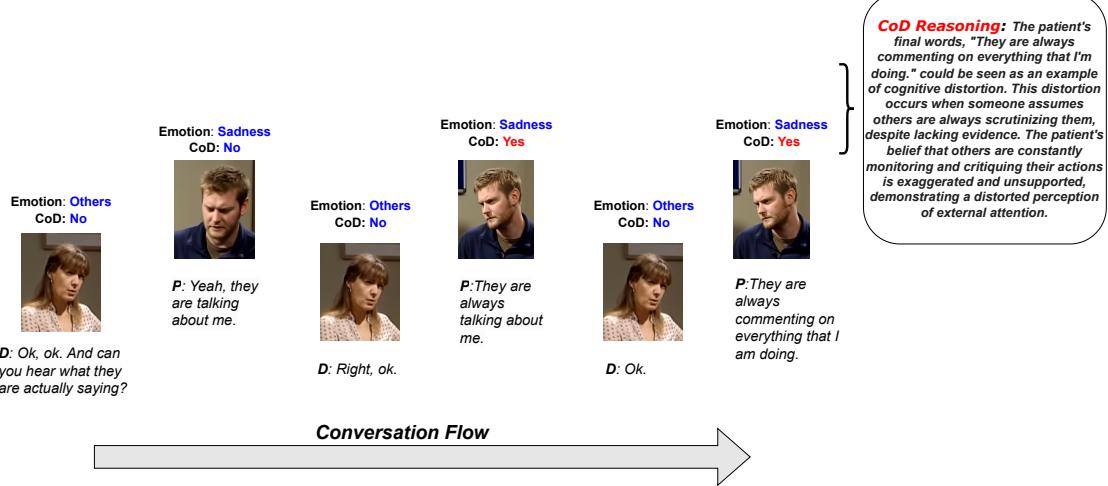
The researchers tackled two massive challenges to achieve this:
- Lack of Data: There were no large-scale datasets containing doctor-patient conversations annotated with both distortions and the reasoning behind them.
- The Modality Gap: Sarcasm, hesitation, and distress are often found in the tone of voice or a facial expression, not just the text. A text-only model misses half the story.
The Solution: ZS-CoDR Framework
The proposed solution is ZS-CoDR. The name hints at its core capability: Zero-Shot Cognitive Distortion detection and Reasoning. “Zero-shot” means the model can perform these tasks without being explicitly trained on thousands of specific examples of every possible distortion scenario, relying instead on its generalized understanding.
The Architecture
The framework is complex, integrating three different types of data (modalities): Video, Audio, and Text. Let’s visualize the architecture before breaking it down.

1. The Encoders: Processing the Senses
The system first needs to “see” and “hear” the conversation. It uses three distinct encoders:
- Text Encoder (LLaMA-7B): Processes the transcript of the conversation.
- Audio Encoder (WHISPER): The researchers use the WHISPER model, a state-of-the-art multilingual speech recognition model. It converts audio waves into rich feature representations.
- Video Encoder (3D-ResNet-50): This is where it gets interesting. To understand facial expressions and body language, the system uses a 3D-ResNet.
To make the video encoder effective, the researchers utilized a Spatiotemporal Contrastive Learning framework. In simple terms, the model learns by comparing video clips. If two clips come from the same video segment, the model is penalized if it thinks they are different, and rewarded if it recognizes they are similar. This is achieved using the InfoNCE loss function:
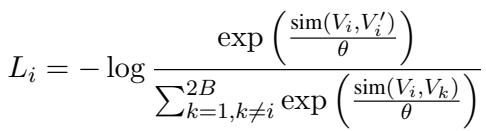
This mathematical pressure forces the video encoder to learn robust representations of the patient’s visual behavior over time.
2. Modality Alignment: Speaking the Same Language
Here lies the biggest technical hurdle: An audio wave and a video frame are mathematically very different from a text token. You cannot simply feed raw video data into a Large Language Model designed for text.
To solve this, the researchers employ Cross-Attention. This mechanism aligns the audio and video features with the text embedding space of the LLM. It essentially translates “visual sadness” or “vocal trembling” into vector formats that the LLM can understand alongside the words.
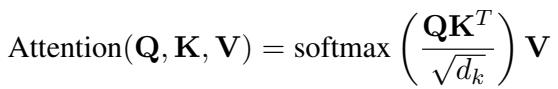
The audio and video features (\(h'_a\) and \(h'_v\)) are aligned with the LLM’s embedding matrix (\(E\)).
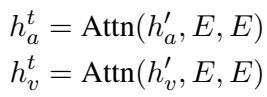
Once aligned, these features are concatenated (joined together) to form a Multimodal Context. This context vector contains the what (text), the how (audio), and the look (video) of the conversation.
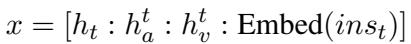
3. The Hierarchical Process
The ZS-CoDR framework doesn’t try to do everything at once. It mimics human cognitive processes through a hierarchical approach:
- Task 1: Detection & Emotion: The multimodal context is fed into the first LLM layer. It predicts:
- Is there a cognitive distortion? (Yes/No)
- What is the emotion? (e.g., Sadness, Fear, Anger)
- Task 2: Reasoning Generation: If a distortion is detected, the system passes the context, the predicted label, and the predicted emotion to a second LLM layer. This layer is prompted to generate the “Why.”
This separation ensures that the reasoning generation is conditioned on accurate detection, improving the logical flow of the output.
The Data: Creating CoDeR
You cannot validate a reasoning model without ground truth. The researchers started with an existing dataset called CoDEC, which had labels for distortions but lacked explanations.
They augmented this to create CoDeR (Cognitive Distortion Detection and Reasoning). They employed expert annotators to write detailed reasons for why specific utterances were distortions.
The complexity of this task is visible in the word clouds generated from the dataset. The reasoning vocabulary (Figure 5) is dense with psychological terms like “belief,” “perception,” “negative,” and “evidence.”

Experiments and Results
Does adding video and audio actually help? Does the hierarchical structure work? The researchers compared ZS-CoDR against several baselines, including standard text-only models and other multimodal systems.
Quantitative Success
The results were compelling. ZS-CoDR outperformed baselines across almost all metrics.
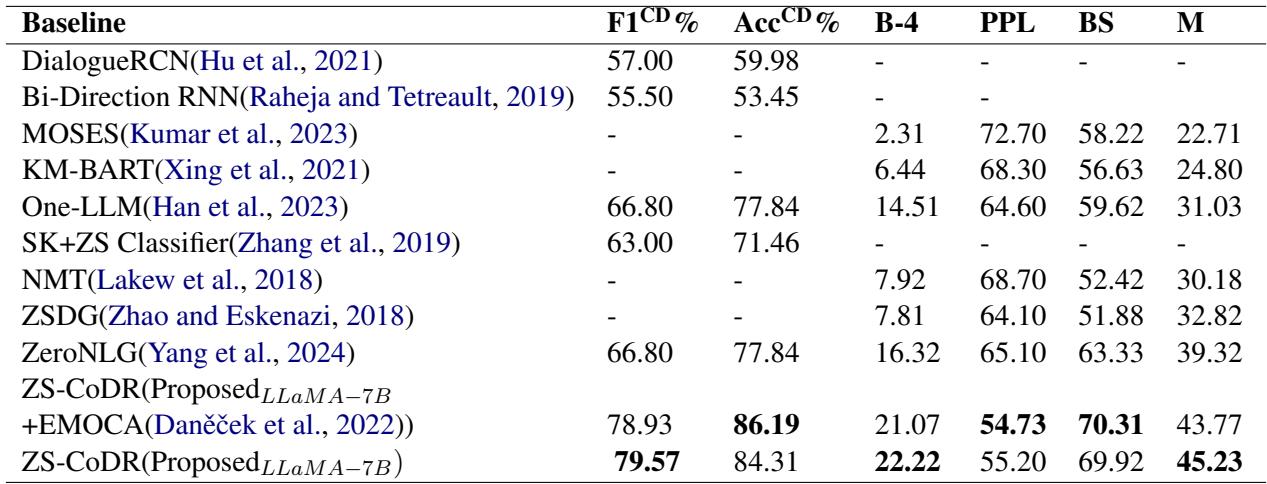
In the table above, look at the F1 score (for detection accuracy) and BLEU-4/BERTScore (for the quality of the generated reasoning). The proposed multimodal approach (bottom rows) significantly beats standard baselines like ZeroNLG.
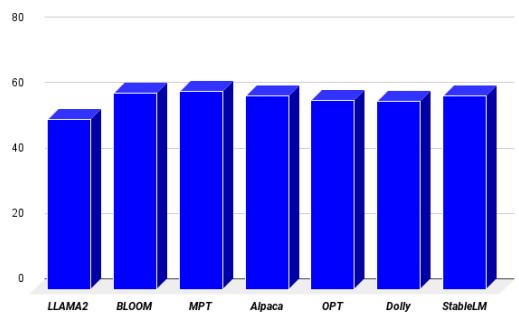
The researchers also tested different LLM backbones (like OPT, Bloom, and Alpaca) to see which “brain” worked best. LLaMA-7B proved to be the superior engine for this task, achieving the lowest perplexity (perplexity measures how “confused” a model is; lower is better).
Qualitative Analysis: The “Human” Touch
Numbers are great, but in mental health, the nuance of the language matters most. Let’s look at a comparison between the ground truth, the ZS-CoDR model, and a baseline (ZeroNLG).
In the example below, the patient makes a leap of logic about letters and people’s desires.
- ZeroNLG gives a vague, generic response.
- ZS-CoDR (Multimodal) generates a specific explanation: “identifies the same utterance as a cognitive distortion due to inaccurate interpretation based solely on letter arrangements.”

The inclusion of video and audio proved crucial. In ablation studies (where researchers remove one modality to see what happens), removing video caused a significant drop in performance. This confirms that facial cues—a furrowed brow, a lack of eye contact—are essential signals for diagnosing distorted thinking.
Context Length Matters
Another interesting finding was the importance of conversation history. How far back does the model need to “remember” to give a good explanation?
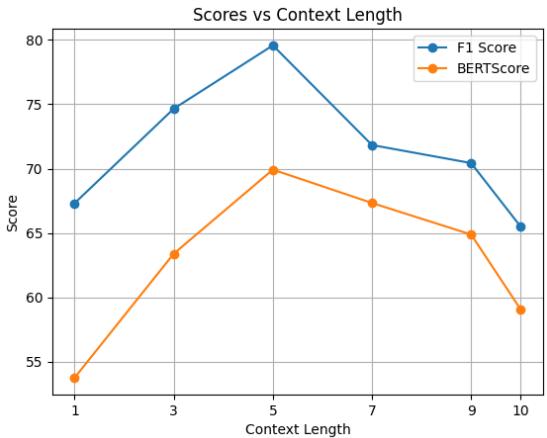
As shown in Figure 7, the performance peaks when the model considers the previous 5 utterances. If the context is too short (1 utterance), the model lacks background. If it’s too long (10 utterances), the model gets distracted by irrelevant noise.
Case Studies in Reasoning
To fully appreciate the system’s capability, we can look at specific examples of the reasoning generated by the model.
In one instance using the OPT backbone, a patient says, “I was just trying to save myself.” The model identifies this as a distortion and explains that the patient is rationalizing their behavior to downplay deeper issues.

In another example using the Alpaca backbone, the model explicitly identifies “emotional reasoning” (a specific type of distortion where one believes that if they feel something, it must be true). The patient says, “I now know it’s the truth,” referring to people making jokes about them. The model correctly identifies that the patient is interpreting jokes as truth based solely on their feelings.

Conclusion
The ZS-CoDR framework represents a significant step forward in Affective Computing. By moving beyond simple text classification and embracing the messy, multimodal nature of human communication, AI can become a more effective support tool for mental health professionals.
Key takeaways from this research:
- Context is Multimodal: You cannot fully understand a patient’s mental state by reading a transcript alone. Video and audio are vital.
- Explainability is Safety: In healthcare, a “black box” AI is dangerous. Systems that explain their reasoning (e.g., “I flagged this because the patient is overgeneralizing based on a single event”) build trust.
- Hierarchical Design Works: Separating detection and reasoning into distinct steps mimics human clinical diagnosis and yields better results.
As Large Language Models continue to evolve, frameworks like ZS-CoDR pave the way for AI assistants that don’t just listen, but actually understand the complex “why” behind our thoughts.