](https://deep-paper.org/en/paper/file-3073/images/cover.png)
Social media platforms are the modern town squares, but they are increasingly polluted by hate speech. While content moderation (banning or deleting) is one approach, it often clashes with free speech principles and can be difficult to scale. A more organic and constructive solution is counterspeech: direct responses that refute hate speech, correct misinformation, and try to de-escalate hostility.
However, writing effective counterspeech is hard. To be persuasive, you can’t just say “you’re wrong.” You need evidence. You need a clear argument. And most importantly, you need to be factually accurate.
Large Language Models (LLMs) like GPT-4 or Llama seem like the perfect tools for automating this, but they suffer from a critical flaw: Hallucination. They might invent statistics to win an argument or lose track of the original point they were trying to make.
In this post, we will dive deep into F2RL, a new framework proposed by researchers from the National University of Defense Technology and the Academy of Military Science in China. This paper introduces a sophisticated method to teach LLMs how to generate counterspeech that is not only persuasive but also factually correct and faithful to the evidence.
The Problem: Hallucinations in Good Intentions
Before understanding the solution, we need to dissect why standard LLMs struggle with this task. When you ask an AI to refute a hate speech post, it tries to predict the most probable next words. It doesn’t inherently “know” facts.
This leads to two specific types of failure:
- Factuality Hallucination: The model invents fake evidence. For example, claiming a specific group donates “100 billion dollars” when the real number is different.
- Faithfulness Hallucination: The model ignores the evidence provided to it, or it writes a response that doesn’t actually address the specific hate speech input.
The researchers illustrate this problem clearly in the image below. Look at the difference between User 2 (who hallucinates a number), User 3 (who gives a history lesson that doesn’t quite fit the context), and User 4 (who provides a clear claim backed by verifiable evidence).
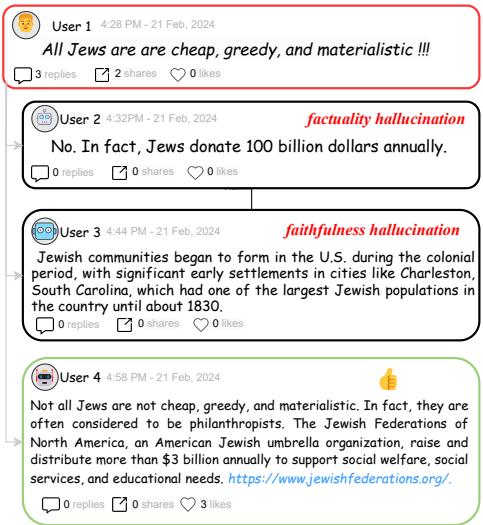
The goal of the F2RL framework is to consistently produce the quality of output seen in User 4: a response guided by a clear claim and supported by real evidence.
The Solution: The F2RL Framework
To solve these issues, the researchers didn’t just tweak a prompt; they re-engineered the entire generation pipeline. F2RL stands for Factuality and Faithfulness Reinforcement Learning.
The framework operates in three distinct stages:
- Self-Evaluation Claim Generation: Deciding what to argue before arguing it.
- Coarse-to-Fine Evidence Retrieval: Finding the right facts to back up that argument.
- Reinforcement Learning (RL): Training the model to stick to the facts using a complex reward system.
Let’s look at the high-level architecture:
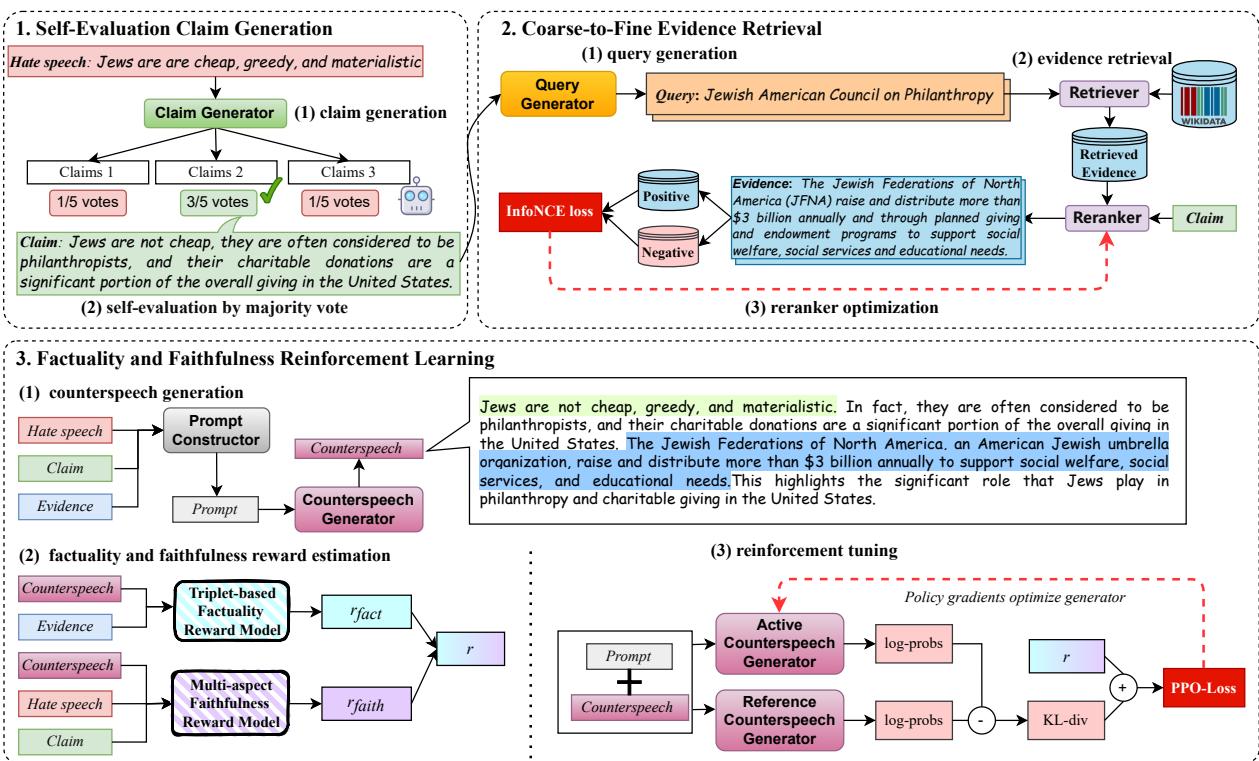
Let’s break down each module to understand the engineering behind this approach.
Module 1: Self-Evaluation Claim Generation
Standard approaches often try to retrieve evidence directly based on the hate speech. The problem is that hate speech is often vague or emotional. Searching for “hate speech keywords” might return irrelevant data.
F2RL adds an intermediate step: The Counter-Claim.
Before looking for facts, the model generates a specific argument strategy. However, LLMs can generate weak arguments. To fix this, the authors implement a Self-Evaluation mechanism.
- Generation: The LLM generates multiple potential claims (e.g., 5 different ways to refute the statement).
- Voting: The LLM acts as a judge, reviewing its own generated claims and voting for the one that most effectively rebuts the hate speech.
This ensures that the foundation of the counterspeech—the core argument—is solid before any evidence is gathered.
Module 2: Coarse-to-Fine Evidence Retrieval
Once the system has a winning claim, it needs proof. A simple Google search (or database lookup) isn’t enough because the gap between a “claim” and “evidence” can be large.
The researchers propose a Coarse-to-Fine strategy:
- Query Generation: The model generates search queries based on the chosen claim.
- Coarse Retrieval (The Broad Net): Using a tool called Contriever, the system pulls a large set of documents from Wikipedia that might be relevant. This ensures diversity.
- Fine Reranking (The Filter): This is where it gets interesting. A second model (BGE M3) looks at the retrieved documents and scores them based on how well they support the specific claim.
Optimizing the Reranker
To make the reranker smart, they train it using Contrastive Learning. They want the model to pull the “Claim” and “Positive Evidence” closer together in vector space, while pushing “Negative Evidence” away.
This is achieved mathematically using the InfoNCE loss function.
First, the total loss function aggregates the error across all claims and evidence pairs:
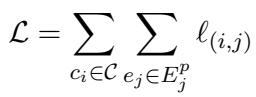
The core mechanism, however, is inside the term \(\ell_{(i,j)}\). This equation essentially calculates a probability. It maximizes the similarity score \(s\) between the claim \(c_i\) and the positive evidence \(e^p_j\), while minimizing the similarity to negative evidence \(e^n\):
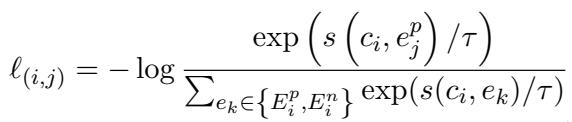
By minimizing this loss, the system learns to filter out irrelevant noise and keep only the evidence that truly backs up the claim.
Module 3: Factuality and Faithfulness Reinforcement Learning
This is the heart of the paper. Even with good evidence, an LLM might ignore it or misuse it during the final text generation. To force the LLM to behave, the authors use Reinforcement Learning (RL), specifically Proximal Policy Optimization (PPO).
In RL, you need a “Reward Model”—a teacher that gives the student a grade. If the grade is high, the model learns to repeat that behavior. F2RL uses two specialized reward models.
1. The Triplet-Based Factuality Reward
How do you automatically check if a sentence is true? The authors break the generated text down into Knowledge Triplets (Subject, Relation, Object).
For example, if the generated text is “Jews donate 100 billion,” the triplet is (Jews, donate, 100 billion).
The system then checks if this triplet is entailed (supported) by the retrieved evidence. If the evidence says “Jews donate 3 billion,” the entailment score is low, and the model gets a low reward.
The formula for the factuality reward (\(r_{fact}\)) calculates the average entailment probability between the evidence (\(e\)) and the triplets (\(t\)) extracted from the counterspeech (\(cs\)):
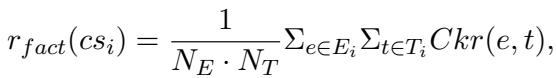
2. The Multi-Aspect Faithfulness Reward
Factuality isn’t enough. You can say something true that is completely irrelevant to the argument. Faithfulness ensures the response stays on track. The authors define faithfulness in three dimensions:
- Faithfulness to Hate Speech: Does the response actually oppose the hate speech? (Measured by a Stance Detection model).
- Faithfulness to Claim: Does the response follow the chosen counter-claim? (Measured by semantic similarity).
- Faithfulness to Evidence: Does the response utilize the provided evidence? (Measured by similarity).
These are combined into a single faithfulness score (\(r_{faith}\)):
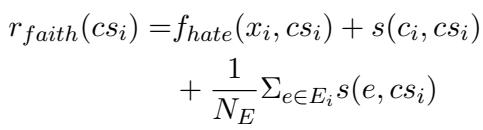
The Final Objective
The system combines the Factuality and Faithfulness scores into a final reward \(r(cs_i)\), where \(\gamma\) is a balancing parameter:
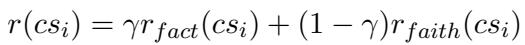
Finally, the generator is trained to maximize this reward while not deviating too far from its original language capabilities (to keep the text fluent). This is the PPO objective function, where \(D\) represents the KL-divergence (a penalty for changing the model too much):
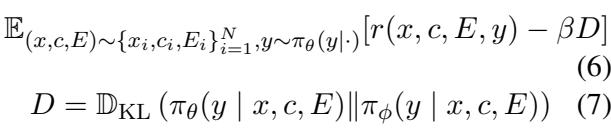
Experiments and Results
Does all this complexity actually work? The researchers tested F2RL on three benchmark datasets (CONAN, MTCONAN, MTKGCONAN) using varied underlying LLMs (GLM4, Qwen1.5, Llama3).
They compared their method against:
- IOP: Simple Input-Output Prompting.
- CoT: Chain of Thought (generate claim -> generate evidence internally -> write response).
- CoTR: Chain of Thought with Retrieval (retrieve evidence -> write response).
The results were impressive. Take a look at Table 1:
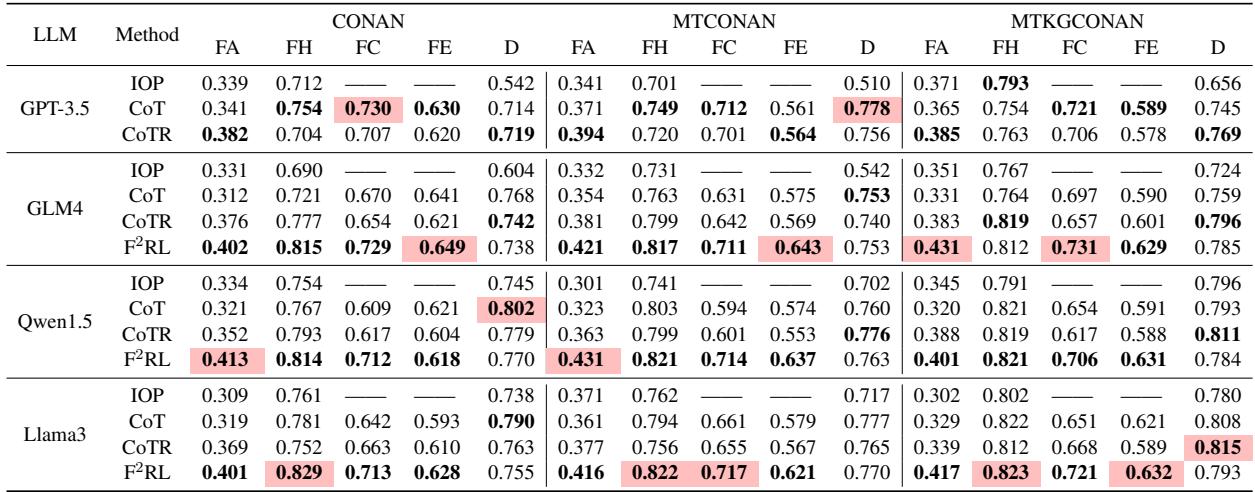
Key Takeaways from the Data:
- Factuality Boost: Across the board, F2RL (the rows with “F2RL”) achieves the highest FA (Factuality) scores. This proves the triplet-based reward works.
- Faithfulness: The model also dominates in Faithfulness to Hate Speech (FH), Claim (FC), and Evidence (FE).
- Consistency: Whether using Llama3 or Qwen, the framework improves performance, showing it’s a generalizable method.
The Diversity Trade-off
There is one fascinating catch. If you look at the D (Diversity) column in the table above, or the charts below, you’ll see that F2RL often has slightly lower diversity than baseline models.
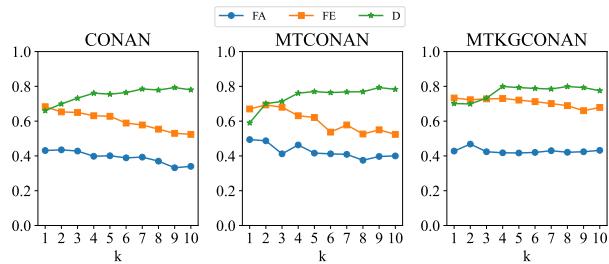
Why does diversity drop?
- Strict Structures: The model learns that certain sentence structures (e.g., “In fact, [Evidence]…”) yield high rewards, so it reuses them.
- Fact-Dependency: Creativity often requires deviating from rigid facts. By forcing the model to stick to the evidence, the “creative writing” aspect is constrained.
However, in the context of fighting misinformation, boring but true is vastly superior to creative but false.
Human Evaluation
Metrics are great, but do humans think the responses are better? The authors recruited volunteers to rate the generated counterspeech.
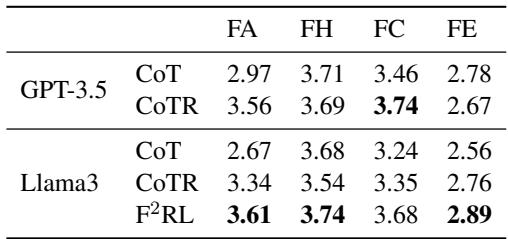
The human evaluation confirms the automated metrics: F2RL generates responses that are perceived as more factual and relevant than standard prompting methods.
Conclusion and Implications
The F2RL framework represents a significant step forward in controlled text generation. It moves beyond simply asking an LLM to “be helpful” and instead engineers a pipeline that enforces rigor.
By explicitly separating the Claim (the argument) from the Evidence (the proof), and then using Reinforcement Learning to penalize hallucinations, the researchers have created a blueprint for safer, more effective automated counterspeech.
This technology has implications beyond just hate speech. The same “Claim-Guided, Evidence-Supported” framework could be applied to:
- Automated customer support (citing specific policy documents).
- Medical advice summaries (citing specific medical journals).
- Educational tutoring (sticking strictly to textbook material).
While no AI is perfect—and the authors note that human review is still necessary before posting counterspeech—F2RL brings us closer to a world where AI helps clean up the information ecosystem rather than polluting it with hallucinations.