](https://deep-paper.org/en/paper/file-3250/images/cover.png)
Large Language Models (LLMs) like GPT-4 and Llama 2 have revolutionized how we interact with technology. They can summarize documents, write code, and answer complex questions. But they have a well-known “kryptonite”: Hallucinations.
An LLM hallucination occurs when the model generates content that sounds plausible but is factually incorrect or unfaithful to the source material. For a student writing a paper or a developer building a chatbot, this is a critical reliability issue.
How do we catch these lies? Traditional methods often check the entire response at once or break it down sentence by sentence. However, a new research paper titled “Knowledge-Centric Hallucination Detection” argues that we are looking at the wrong level of detail. The authors introduce REFCHECKER, a framework that hunts for hallucinations by breaking text down into “Claim-Triplets”—atomic units of knowledge.
In this post, we will tear down this paper, explain why “triplets” are the future of fact-checking, and explore how REFCHECKER outperforms existing state-of-the-art detection methods.
The Granularity Problem
To understand why detecting hallucinations is hard, imagine you are a teacher grading a student’s history essay. The student writes: “The Eiffel Tower was constructed in 1889 by the architect Gustave Eiffel in Berlin.”
If you grade the whole response as “False,” you aren’t being entirely fair. The date is right. The architect is right. The location is wrong.
If you grade it sentence-by-sentence, the result is still a binary “False,” which obscures which part of the sentence is wrong.
Existing research typically checks hallucinations at three levels:
- Response Level: Checking the whole paragraph. (Too broad).
- Sentence Level: Checking period-to-period. (Better, but still misses nuance).
- Sub-sentence Level: Extracting phrases. (Often structurally messy and hard to define).
The authors of REFCHECKER propose a fourth, superior option: Knowledge Triplets.
Why Triplets?
A knowledge triplet follows a specific structure: (Subject, Predicate, Object).
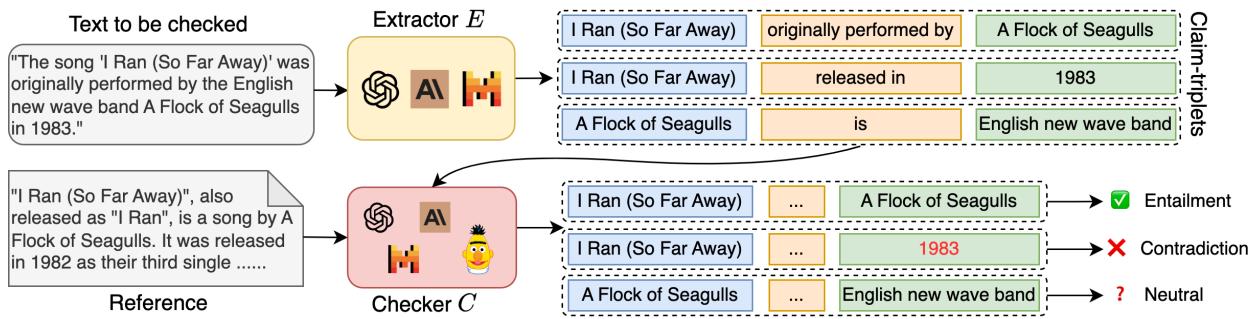
Let’s look at the example provided in the paper regarding the song “I Ran (So Far Away).”

As shown in Figure 1, if we look at the sentence “I Ran (So Far Away) was originally performed by A Flock of Seagulls in 1983,” a sentence-level checker might simply flag it as false.
However, the triplet extractor breaks this into:
- (I Ran, originally performed by, A Flock of Seagulls) -> True
- (I Ran, released in, 1983) -> False (It was 1982)
- (A Flock of Seagulls, is, English new wave band) -> True
By using triplets, we isolate the specific factual error (“1983”) without discarding the correct information. This level of granularity allows for much more precise hallucination detection.
The REFCHECKER Framework
The researchers developed a pipeline called REFCHECKER to automate this process. It doesn’t just rely on proprietary models; it is designed to work with both closed-source (like GPT-4) and open-source models (like Mistral).
The framework consists of two main stages: the Extractor and the Checker.
1. The Extractor (E)
The Extractor’s job is to take the LLM’s response and decompose it into a list of claim-triplets.
- Input: The raw text response.
- Process: The model (e.g., GPT-4 or a fine-tuned Mistral 7B) identifies declarative statements and converts them into the (Subject, Predicate, Object) format.
- Output: A list of triplets.
The authors found that while GPT-4 is a great extractor, they could achieve comparable performance by fine-tuning a smaller, open-source model (Mistral 7B) using knowledge distillation.
2. The Checker (C)
The Checker takes the extracted triplets and verifies them against a Reference (ground truth text).
- Input: A specific triplet and the reference text.
- Process: The Checker determines the relationship between the claim and the reference.
- Output: One of three labels:
- Entailment: The reference confirms the triplet is true.
- Contradiction: The reference proves the triplet is false.
- Neutral: The reference does not contain enough information to verify the triplet.
This “Neutral” category is crucial. Many previous systems only used binary labels (Fact vs. Non-Fact), which confuses direct lies with simply unverifiable information.
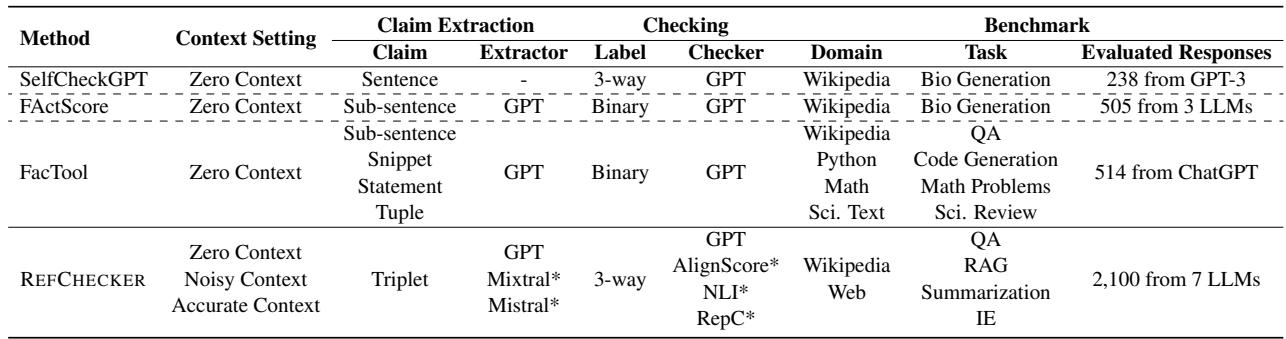
Comparison with Previous Methods
Table 1 below illustrates how REFCHECKER differs from other popular tools like SelfCheckGPT, FActScore, and FacTool. Notice how REFCHECKER covers a broader range of contexts and uses the unique Triplet granularity.
Three Settings for Hallucination
Not all hallucinations happen in the same context. A chatbot making up a fact about history is different from a summarization tool misquoting a document. The authors categorize these into three distinct settings, visualized in Figure 3.
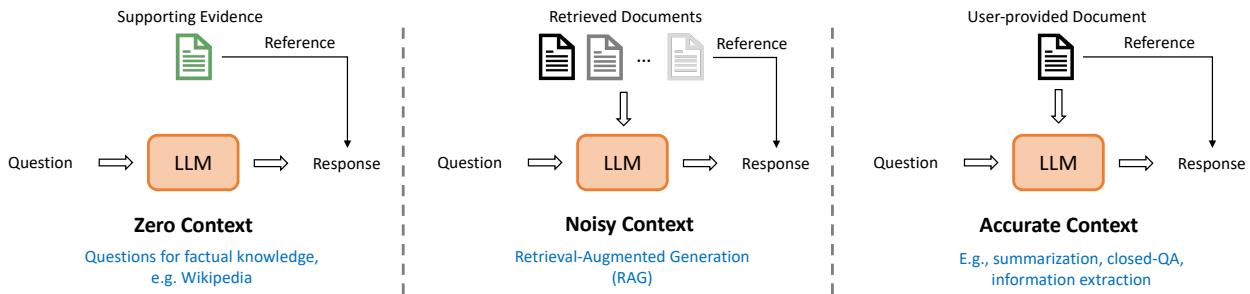
- Zero Context (ZC): The model must rely entirely on its internal memory (e.g., “Who won the World Cup in 2010?”). There is no reference document provided in the prompt.
- Noisy Context (NC): This represents Retrieval-Augmented Generation (RAG) scenarios. The model is given several documents retrieved from a search engine, some of which might be irrelevant, and must answer a question.
- Accurate Context (AC): The model is given a specific, clean document and asked to summarize it or extract information.
Building the Benchmark: KNOWHALBENCH
To test their framework, the researchers couldn’t rely on existing datasets because they were too limited in scope or granularity. They built a new benchmark called KNOWHALBENCH.
They curated 300 “hard” examples (100 for each context setting) and collected responses from 7 different LLMs (including GPT-4, Claude 2, and Llama 2).
Crucially, they performed human evaluation on these responses. Annotators manually reviewed 11,000 claim-triplets generated from 2,100 responses. This created a gold-standard dataset to see if REFCHECKER’s automated verdicts aligned with human judgment.
Experimental Results
So, does the triplet approach actually work better? The results are compelling.
1. Granularity Matters
The researchers compared the performance of checkers when operating at the response, sentence, sub-sentence, and triplet levels.
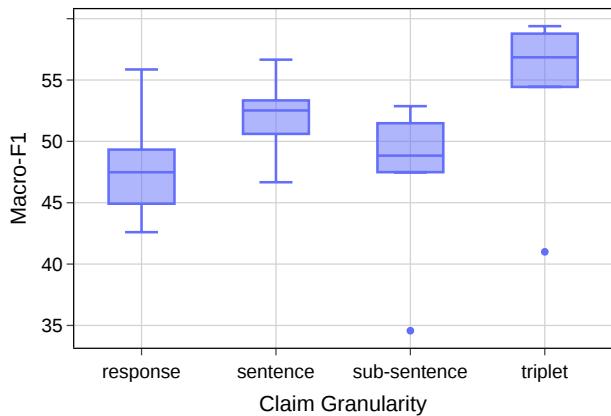
Figure 4 shows the distribution of F1 scores (a measure of accuracy).
- Response-level checking (far left) has a low median score.
- Sentence-level improves slightly.
- Sub-sentence actually sees a performance drop, likely because extracting consistent sub-sentences is difficult.
- Triplet-level (far right) achieves the highest median performance.
This confirms the hypothesis: Triplets are the optimal unit for fact-checking.
2. Beating the Baselines
The authors compared REFCHECKER against the popular SelfCheckGPT method. SelfCheckGPT is a “zero-resource” method that detects hallucinations by sampling multiple responses and checking for consistency.
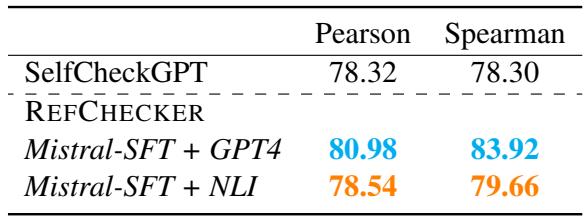
As seen in Table 3, REFCHECKER outperforms SelfCheckGPT in correlation with human judgments. Notably, even the open-source configuration (Mistral-SFT + NLI) beats the standard SelfCheckGPT setup. This suggests that a single logical check against a reference is often more effective than statistically comparing multiple stochastic responses.
3. Open Source vs. Proprietary Models
One of the most encouraging findings for students and developers is that you don’t need GPT-4 to build a good hallucination detector.
The researchers tested various combinations of Extractors and Checkers. They found that a fine-tuned Mistral 7B model (Mistral-SFT) could perform almost as well as GPT-4 at the extraction task.
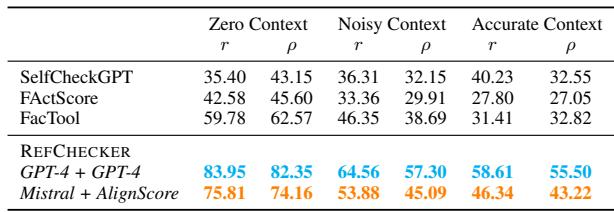
In Table 5, looking at the F1 score, the Mistral-SFT model (86.4) is very close to GPT-4 (89.3) and significantly faster (1.7 seconds per iteration vs 8.7 seconds).
For the Checker component, they experimented with NLI (Natural Language Inference) models and fine-tuned Mistral models.
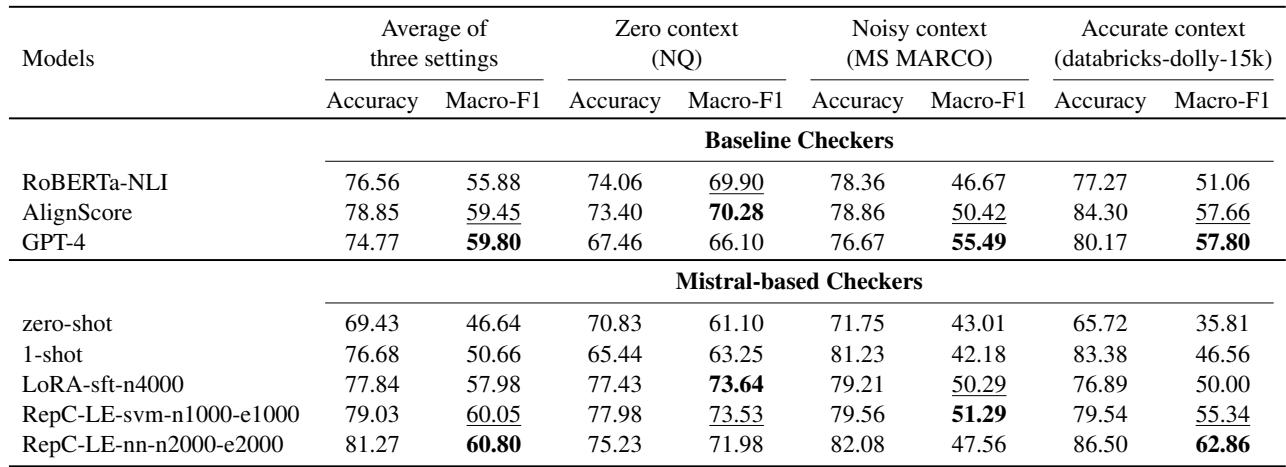
Table 6 reveals that while GPT-4 is a strong checker, specialized smaller models (like AlignScore) and fine-tuned Mistral variants (like RepC-LE-nn) are highly competitive. This paves the way for running high-quality hallucination detection locally on your own hardware.
Why Do Models Hallucinate? Insights from the Data
Beyond the tool itself, the paper offers fascinating insights into why these models fail.
The “Copying” Safety Net
The researchers analyzed the relationship between how much a model “copies” from the source text and its truthfulness.
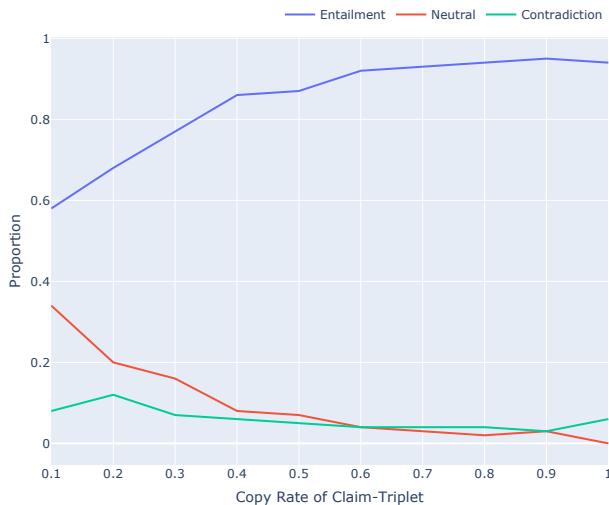
Figure 11 shows a clear trend:
- Blue Line (Entailment/Truth): Goes up as the copy rate increases.
- Green/Red Lines (Contradiction/Neutral): Go down as the copy rate increases.
Essentially, copying is safe. When models try to paraphrase or synthesize information too heavily, the risk of hallucination skyrockets.
Internal Knowledge Bias
The team also discovered a phenomenon they call “Internal Knowledge Bias.” Even when you provide an LLM with a specific document (Accurate Context), the model often ignores it if the document contradicts what the model learned during pre-training.
For example, if you provide a fake news article saying “The Earth is flat” and ask the model to extract facts based on the article, the model might still refuse or hallucinate a correction because its internal weights “know” the Earth is round. While this seems helpful, in a strict fact-extraction or summarization task, it is technically a failure to follow instructions.
Conclusion and Implications
The REFCHECKER paper makes a significant contribution to the field of AI safety. By shifting the focus from sentences to Claim-Triplets, the researchers have found a way to pinpoint hallucinations with much higher precision.
Key Takeaways for Students and Developers:
- Granularity is Key: When building evaluation systems, don’t just look at the whole answer. Break it down.
- Triplets are Powerful: The Subject-Predicate-Object structure is a robust way to represent knowledge for machine verification.
- Open Source is Viable: You can build state-of-the-art detection systems using smaller, fine-tuned models like Mistral 7B, reducing reliance on expensive APIs like GPT-4.
- Context Matters: Hallucination detection strategies must change depending on whether the model is doing closed-book QA, RAG, or summarization.
As we continue to integrate LLMs into critical workflows, tools like REFCHECKER will be essential “spell-checkers” for facts, ensuring that the AI revolution remains grounded in reality.
The images used in this blog post are derived from the paper “Knowledge-Centric Hallucination Detection” by Hu et al.