](https://deep-paper.org/en/paper/file-3326/images/cover.png)
The dream of Artificial General Intelligence (AGI) relies heavily on the ability of machines to process information the way humans do: multimodally. When you look at a picture of a crowded street and answer the question, “Is it safe to cross?”, you are seamlessly blending visual perception with linguistic reasoning. Multimodal Large Language Models (MLLMs) like LLaVA and Flamingo have made massive strides in mimicking this capability.
However, there is a catch. As these models grow into the billions of parameters, adapting them to new tasks becomes prohibitively expensive. Traditional “full fine-tuning”—where we update every single weight in the model—is computationally heavy and storage-intensive.
This brings us to a critical question: Can we adapt these massive multimodal models to new tasks by updating only a tiny fraction of their parameters, without sacrificing performance?
Researchers from the Rochester Institute of Technology, Meta AI, and others propose an emphatic “Yes” in their paper, M\(^2\)PT: Multimodal Prompt Tuning for Zero-shot Instruction Learning. They introduce a method that tunes just 0.09% of the model’s parameters yet achieves results comparable to—and sometimes better than—full fine-tuning.
The Challenge: The Single-Modality Trap
To solve the cost issue of fine-tuning, the field has turned to Parameter-Efficient Finetuning (PEFT). Techniques like LoRA (Low-Rank Adaptation) and Prompt Tuning have become standard. Prompt tuning, specifically, involves freezing the entire pre-trained model and only training a small set of “soft prompts” (vectors) prepended to the input.
While effective, most existing prompt tuning methods suffer from a “single-modality” bias. They tends to either:
- Add prompts only to the language model (ignoring the vision encoder).
- Add prompts only to the visual encoder (ignoring the language model).
This disjointed approach overlooks the complex interaction between vision and text. The researchers behind M\(^2\)PT argue that to truly master zero-shot instruction learning, we need a unified approach that guides both the “eyes” (vision encoder) and the “brain” (LLM) of the model simultaneously.
Enter M\(^2\)PT: Multimodal Prompt Tuning
The core innovation of this paper is a hierarchical architecture that inserts learnable prompts into both the vision and language components of the model, bridging them with a specialized interaction layer.
The Architecture Overview
Let’s break down the architecture. A standard MLLM consists of a Vision Encoder (like CLIP) that processes images and a Large Language Model (like Vicuna/LLaMA) that processes text and generates answers.
M\(^2\)PT introduces three specific tunable components while keeping the rest of the massive model frozen:
- Visual Prompts (\(P_v\)): Learnable vectors inserted into the Vision Encoder.
- Textual Prompts (\(P_t\)): Learnable vectors inserted into the LLM.
- Cross-Modality Interaction: A layer that aligns the visual features with the textual space.
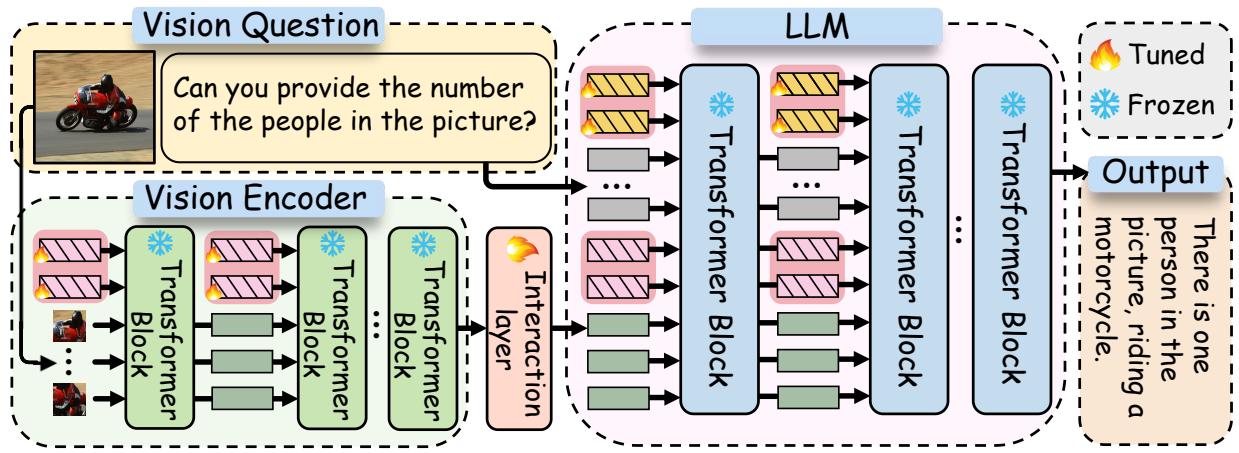
As shown in Figure 2, the workflow is elegant. The visual prompts help the encoder extract task-relevant visual features. These features are then projected via the interaction layer to “talk” to the textual prompts within the LLM. This ensures that the language model isn’t just receiving raw image data; it’s receiving visually prompted data that is already aligned with the textual instructions.
1. Visual Prompts
The researchers insert a set of tunable vectors (\(P_v\)) into the layers of the Vision Encoder (\(f_v\)). These prompts are placed at the beginning of the sequence in each layer.
Mathematically, for the \(i\)-th layer of the vision encoder, the output \(O_v^i\) is calculated by processing the prompts and the output from the previous layer:
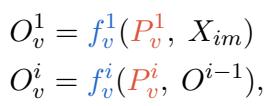
This allows the vision encoder to adapt its feature extraction process specifically for the task at hand without changing its original pre-trained weights.
2. Textual Prompts
Similarly, textual prompts (\(P_t\)) are inserted into the LLM. However, these aren’t just standard NLP prompts. Because they operate in a multimodal context, they need to capture the semantic relationship between the image and the text.
The output of the LLM layers (\(O_m\)) is derived by processing the textual prompts alongside the aligned visual information and the text embedding (\(O_t\)).
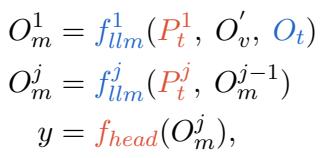
3. The Secret Sauce: Cross-Modality Interaction
The most distinct feature of M\(^2\)PT is how it handles the handover between vision and text. Simply feeding the vision output to the LLM is often insufficient for fine-grained tasks.
The researchers introduce a tunable Interaction Layer (\(f_{in}\)). This layer takes the output from the vision encoder (\(O_v^N\)) and projects it linearly into the textual embedding space.
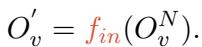
This projection ensures that the “visual thoughts” of the model are translated into a “language” that the LLM’s textual prompts can understand and interact with effectively.
Why This Works: Looking Inside the “Black Box”
You might wonder: does the model actually use these prompts, or are they just noise? The researchers visualized the attention activation maps of the model to see where it was focusing its computational energy.
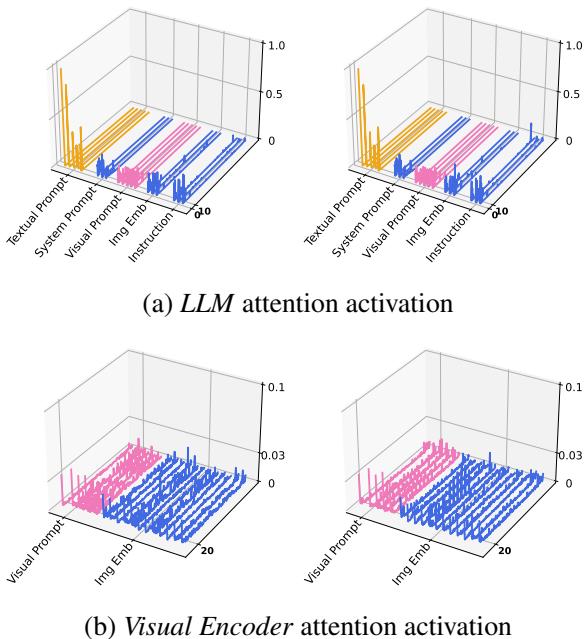
Figure 3 reveals something fascinating:
- In the LLM (Fig 3a): There are high activation spikes corresponding specifically to the textual prompt regions.
- In the Visual Encoder (Fig 3b): The activations for visual prompts are noticeably higher than most other tokens.
This confirms that the frozen backbone models are actively attending to these learned prompts to guide their inference. The prompts act as “beacons,” directing the massive pre-trained networks toward the correct reasoning path for zero-shot tasks.
Experimental Results
The researchers evaluated M\(^2\)PT on a wide variety of benchmarks, including the comprehensive MME benchmark, VSR (Visual Spatial Reasoning), and standard perception tasks like CIFAR-10 and MNIST. They compared their method against state-of-the-art PEFT methods like LoRA (Low-Rank Adaptation) and VPT (Visual Prompt Tuning).
Superior Performance with Minimal Parameters
The results were impressive. M\(^2\)PT consistently outperformed other parameter-efficient methods.
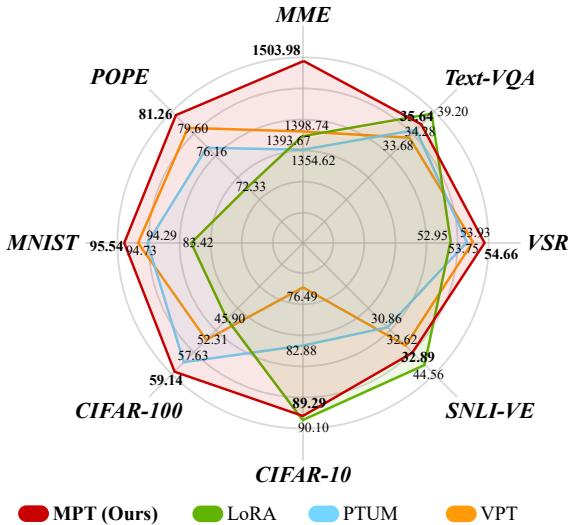
As illustrated in the radar chart above (Figure 1), M\(^2\)PT (represented by the blue line) envelopes the baselines across almost all datasets. It shows particular strength in the MME benchmark, which tests both perception and cognition.
Let’s look at the hard numbers:
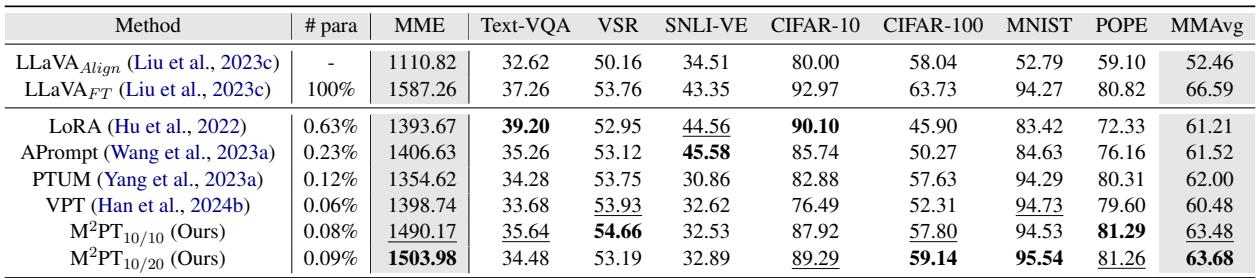
Table 1 highlights the efficiency:
- LoRA tunes 0.63% of parameters.
- M\(^2\)PT tunes only 0.09% of parameters.
Despite using nearly 7x fewer parameters than LoRA, M\(^2\)PT achieves a higher average score (MMAvg) of 63.68 compared to LoRA’s 61.21. In fact, on datasets like VSR, MNIST, and POPE, M\(^2\)PT even outperforms the fully fine-tuned LLaVA model (which updates 100% of the weights). This suggests that for certain zero-shot tasks, full fine-tuning might actually lead to overfitting or catastrophic forgetting, while prompt tuning preserves the model’s general capabilities better.
Component Analysis: Do We Need It All?
Is the complexity of using both visual and textual prompts necessary? Could we get away with just one?
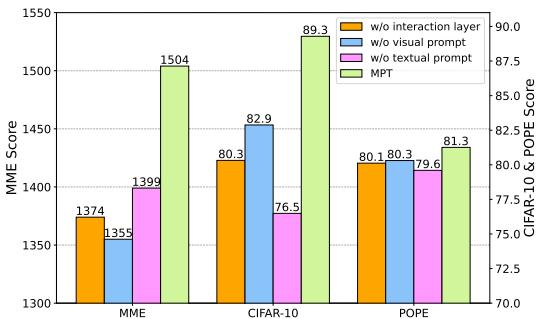
Figure 4 presents an ablation study where researchers removed components one by one.
- w/o Interaction Layer (Orange): Performance drops significantly, proving that simply having prompts isn’t enough; they need to be aligned.
- w/o Visual Prompt (Blue) & w/o Textual Prompt (Pink): Removing either modality’s prompts hurts performance.
Interestingly, the importance varies by task. For MME (a complex multimodal task), the visual prompts are crucial. For CIFAR-10 (a classification task), the textual prompts play a larger role. This validates the design choice of including both to handle a diverse range of tasks.
Qualitative Success
Numbers are great, but how does this translate to actual model behavior?

Figure 8 shows specific examples where M\(^2\)PT succeeds while other methods fail.
- MME Example (Top): The question asks if there is a chair in the image. The image shows people playing chess on the ground with chairs in the background. Baselines like PTUM and VPT answer “No,” likely focusing only on the people or the board. M\(^2\)PT correctly spots the chairs and answers “Yes,” demonstrating superior visual perception.
- CIFAR-10 Example (Bottom): The image is a blurry photo of a cat. Other models hallucinate a “Truck” or “Airplane.” M\(^2\)PT correctly identifies “Cat,” showing robustness even with lower-quality visual inputs.
Conclusion and Future Implications
The M\(^2\)PT paper presents a compelling argument for the future of efficient AI adaptation. By strategically placing learnable prompts in both the vision and language components of a model and ensuring they can communicate via an interaction layer, we can achieve state-of-the-art performance with negligible parameter costs.
Key takeaways for students and practitioners:
- Modality Synergy: Treating vision and language separately during fine-tuning is suboptimal. They must be aligned.
- Efficiency is Key: You don’t need to retrain a 7B or 13B parameter model to teach it new tricks. 0.09% of the parameters is often enough if they are the right parameters.
- Zero-Shot Potential: Properly tuned prompts allow models to generalize to unseen tasks effectively, a crucial capability for real-world AI assistants.
As MLLMs continue to scale, methods like M\(^2\)PT will likely become the standard for deploying specialized models on consumer hardware, democratizing access to powerful multimodal AI.