](https://deep-paper.org/en/paper/file-3702/images/cover.png)
TUNA: Solving the Multimodal Alignment Gap with Retrieval-Augmented Tags
Imagine showing a picture of a rare, exotic fruit to an AI and asking, “What is this?” If the AI has seen millions of pictures of apples and bananas but never this specific fruit during its fine-tuning phase, it might confidently tell you it’s a “pomegranate” or simply hallucinate a description that sounds plausible but is visually incorrect.
This is a pervasive problem in Multimodal Large Language Models (MLLMs). While models like LLaVA have revolutionized how computers understand images, they often struggle with three specific issues when dealing with detailed visual instructions:
- Identifying novel objects (things not in their instruction-tuning data).
- Hallucinating non-existent objects (saying a knife is there when it isn’t).
- Missing specific details (ignoring attributes like color or texture).
In this post, we will dive deep into a research paper titled “Tag-grounded Visual Instruction Tuning with Retrieval Augmentation”. The authors introduce TUNA, a novel framework that bridges the gap between visual understanding and language generation by using a massive external memory of “tags.”
The Problem: The “Alignment Gap”
To understand why TUNA is necessary, we first need to understand where current MLLMs fail.
Take a look at the image below. It shows a photograph of mangosteens.

As you can see in Figure 1, standard models like GPT-4 and LLaVA struggle. GPT-4 identifies the fruit but misses the context of the knife. LLaVA-Wild completely fails, identifying the fruit as a “pomegranate” and hallucinating a “bowl” and a “spoon” that simply aren’t there. The model proposed in this paper (Ours) correctly identifies the mangosteens and the knife.
Why does this happen?
The root cause lies in the architecture of these models. Most MLLMs consist of two main parts:
- A Vision Encoder (like CLIP): This reads the image. It is pre-trained on hundreds of millions of image-text pairs (e.g., 400M). It “knows” what a mangosteen is because it has seen it in that massive dataset.
- A Multimodal Connector & LLM: This part translates the visual features into language. However, this connector is usually fine-tuned on a much smaller dataset (e.g., 1.2M pairs).
There is a mismatch here. The vision encoder sees the “mangosteen” features, but the connector hasn’t learned the “vocabulary” to map those specific visual features to the word “mangosteen” in the language model’s space. The authors call this the alignment gap.
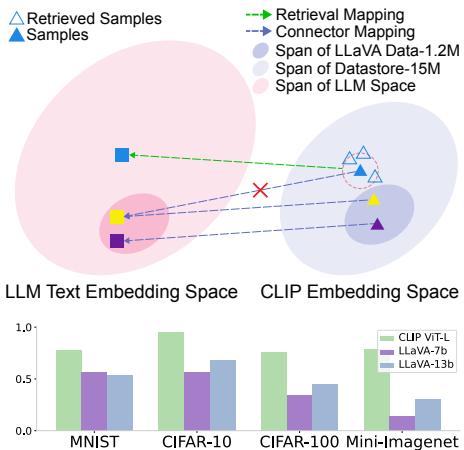
Figure 2 illustrates this beautifully.
- Top: The pink area represents the data the model was fine-tuned on. The blue triangle represents a new, “out-of-distribution” (OOD) object (like the mangosteen). The connector tries to map it but misses the target (the text embedding), landing on the yellow square instead of the green triangle.
- Bottom: The bar chart shows that while the frozen CLIP encoder (green bars) has high accuracy in classifying images, the MLLMs built on top of it (purple and blue bars) actually get worse at classification. The connector acts as a bottleneck, losing information.
The Solution: TUNA
The researchers propose a solution inspired by Retrieval Augmented Generation (RAG). If the model doesn’t “know” the word for an image, why not let it look it up?
TUNA stands for Tag-grounded Visual Instruction tUNing with retrieval Augmentation. Instead of relying solely on the weights learned during training, TUNA retrieves relevant “tags” (keywords) from an external database to help guide the generation process.
Step 1: Building the Datastore (Mining Tags)
Retrieving full captions can be noisy. Captions are often long, conversational, or irrelevant. The authors realized that tags—specific nouns and attributes—are much cleaner anchors for visual grounding.
To build their datastore, they took 15 million image-text pairs from datasets like CC12M and CC3M. They didn’t just use the captions; they processed them using Scene Graph Parsing and Named Entity Recognition (NER). This extracted the core “objects” and “attributes” from the text.

As shown in Figure 3, a caption about a street in Montepulciano is distilled into precise tags: “narrow street,” “colorful facades,” “blue sky,” and “Montepulciano.” This creates a massive index where visual embeddings are keys, and these precise tags are values.
Step 2: The TUNA Architecture
So, how does the model use these tags during training and inference? Let’s break down the architecture shown in Figure 4.
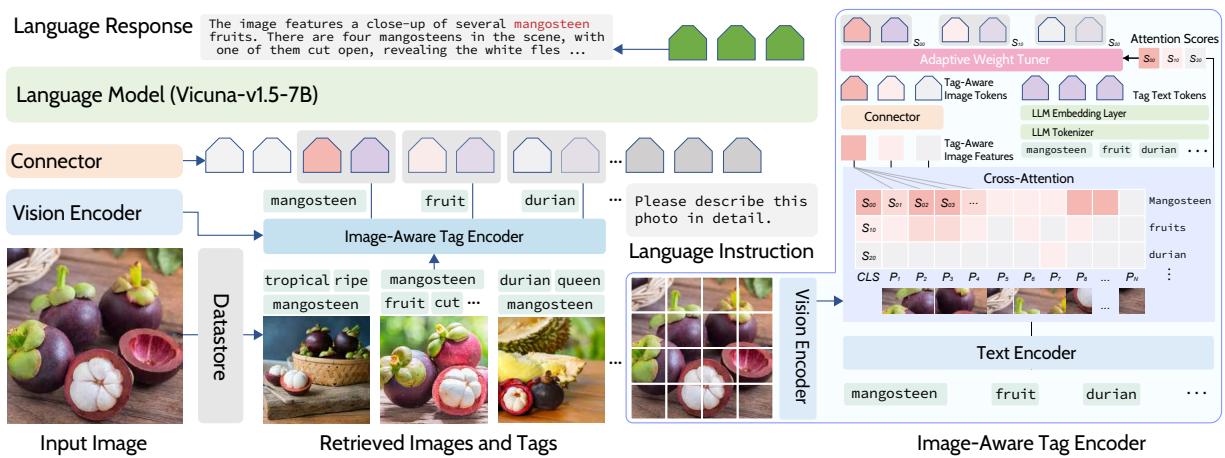
The process works as follows:
- Retrieval: When an input image arrives, the system uses CLIP to find the most similar images in the external datastore.
- Tag Extraction: It pulls the tags associated with those retrieved images.
- The Image-Aware Tag Encoder (The “Secret Sauce”): This is where TUNA shines. It doesn’t just feed the tags as text. It passes the tags through a special encoder that attends to the original input image.
- If the retrieved tag is “cat,” the encoder checks the input image: “Is there actually a cat here? What does this specific cat look like?”
- This produces a tag-aware image token, blending the semantic meaning of the word with the specific visual features of the current image.
- Adaptive Weight Tuner: Not all retrieved tags are good. If you have a picture of a Durian, you might retrieve a picture of a Jackfruit because they look similar. You don’t want the model to output “Jackfruit.” The Adaptive Weight Tuner calculates a score based on how well the tag matches the input image. Low-relevance tags get down-weighted so they don’t confuse the LLM.
Experimental Results
The researchers tested TUNA against state-of-the-art models like LLaVA-1.5, InstructBLIP, and Qwen-VL across 12 different benchmarks.
Quantitative Performance
The results were consistent: TUNA outperformed baselines that used the same underlying Language Model (Vicuna-7B) and training data.
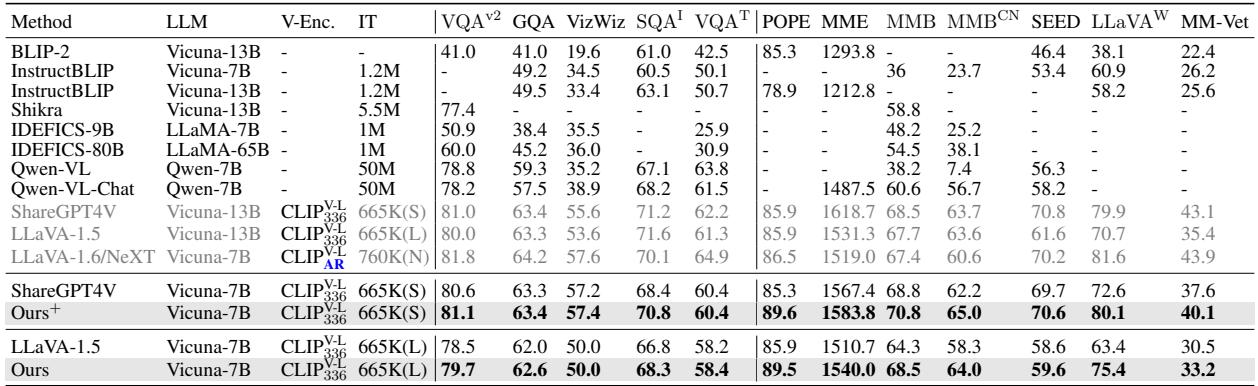
In Table 2, you can see TUNA (Ours) achieving the highest scores across benchmarks like VQA (Visual Question Answering), POPE (Object Hallucination), and MME. It even holds its own against larger 13B models in several categories.
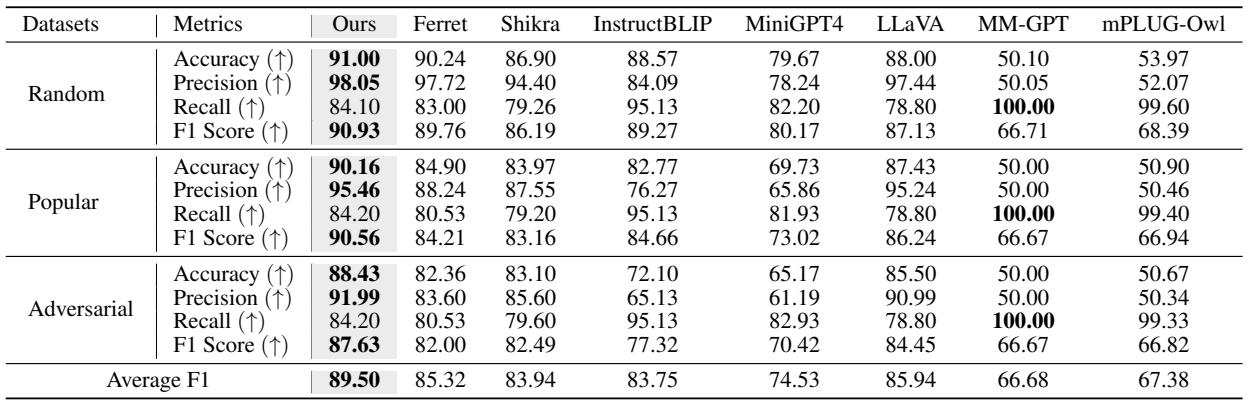
Reducing Hallucinations
One of the most significant improvements was in the POPE benchmark, which measures object hallucination (does the model say an object exists when it doesn’t?).
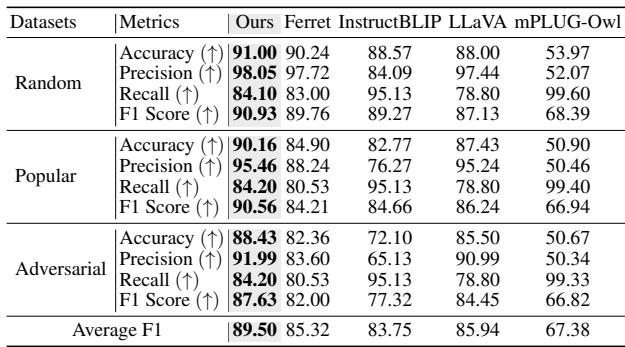
As Table 4 shows, TUNA achieves higher accuracy and precision than standard LLaVA and even models designed for grounding like Ferret. By having explicit tags grounded in the image, the model is less likely to “guess” incorrectly.
Qualitative Examples: Seeing the Difference
Numbers are great, but seeing the model in action explains why it works better.
Identifying Art vs. Reality
In the top example of Figure 5 below, the question asks, “Does this artwork exist in the form of architecture?” (meaning, is this a real building or a painting?). LLaVA gets confused and says “Yes.” TUNA retrieves similar images of paintings and correctly answers “NO.”
Finding Small Details
In the bottom example, the user asks if there is a snowboard. It is very hard to see. TUNA retrieves images of skiing and snowboarding contexts, helping it correctly identify the “YES,” while LLaVA misses it. Note the “heat map” visualization—this shows the Adaptive Weight Tuner working. Bright spots indicate tags the model trusted; dark spots are tags it ignored.

Descriptive Detail
TUNA isn’t just about yes/no answers; it improves detailed descriptions. In the example below regarding Diamond Head crater, LLaVA hallucinates “boats” and “people” to make the scene sound more generic. TUNA sticks to the facts, correctly describing the vegetation and the houses in the background (which are actually there), likely prompted by retrieved tags regarding aerial views and landscapes.

Zero-Shot Capabilities: The Fashion Test
Perhaps the most impressive demonstration of TUNA’s power is its zero-shot capability. The researchers created a “Fashion-Bench” using images from FashionGen. They didn’t fine-tune TUNA on this specific data; they simply swapped the external datastore to include fashion-related images and tags.
Because TUNA learns to use the datastore, it can adapt to new domains instantly just by changing the reference library.
Look at Figure 9. The input is a man in a specific patterned blazer.
- LLaVA-1.5 gives a generic description: “black jacket with white polka dots.” It misses the brand entirely.
- TUNA retrieves similar fashion items. It correctly identifies the “white star pattern” (not polka dots) and even identifies the brand as Neil Barrett.
This is the power of retrieval. The model weights don’t need to memorize every fashion brand in existence; the datastore holds that knowledge, and TUNA knows how to fetch it.
Why Tags Over Captions?
You might wonder: why go through the trouble of extracting tags? Why not just retrieve captions (sentences) like standard RAG?
The authors performed an ablation study to test this.
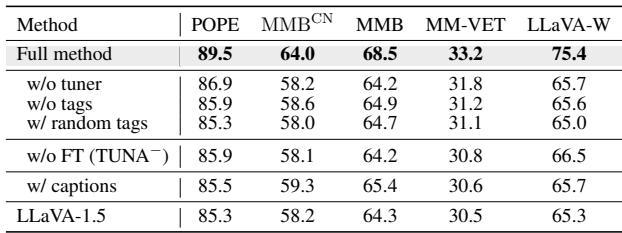
Table 6 shows the results.
- w/ captions: Using full sentences actually resulted in lower performance than using tags. Captions contain noise and linguistic structures that can distract the model.
- w/o tuner: Removing the adaptive weight tuner also hurt performance, proving that you can’t just blindly trust every retrieved tag.
- w/o tags: This is essentially the baseline performance, which is significantly lower.
Conclusion
The TUNA paper presents a compelling argument for moving beyond simple end-to-end training for Multimodal LLMs. By acknowledging the “alignment gap”—the difficulty of mapping every possible visual concept to text using limited training data—the researchers found a way to bridge it using external knowledge.
Key Takeaways:
- Retrieval Augmentation works for Vision: Just as LLMs benefit from looking up facts, MLLMs benefit from looking up visual concepts.
- Tags are better than Captions: Precise, object-oriented tags provide better grounding signals than noisy sentences.
- Adaptive Weighting is Crucial: Retrieval is imperfect; the model must learn to ignore irrelevant retrieved data based on the actual visual input.
TUNA offers a lightweight, effective way to make AI models more precise, less hallucination-prone, and capable of adapting to new domains like fashion without expensive retraining. It is a significant step toward AI that can see and describe the world as it truly is.