](https://deep-paper.org/en/paper/file-3711/images/cover.png)
In the current era of Artificial Intelligence, we are witnessing a “bigger is better” trend. Large Language Models (LLMs) like GPT-4, Claude, and Llama have demonstrated startling reasoning capabilities. They can solve math problems, debug code, and answer complex commonsense questions by generating a “Chain-of-Thought” (CoT)—a step-by-step reasoning path that leads to the final answer.
However, running these massive models is expensive and computationally heavy. This has led to a surge of interest in Small Language Models (SLMs). The goal is simple: can we take the reasoning power of a giant model and compress it into a smaller, faster, and cheaper model?
The standard approach is CoT Distillation. You take a large teacher model, have it generate reasoning steps for thousands of questions, and then train a small student model to mimic those steps. While this works to an extent, it has a fatal flaw: small models often cheat. Instead of learning how to reason, they memorize surface-level patterns and keywords—known as spurious correlations.
In this post, we will deep dive into a fascinating paper titled “Teaching Small Language Models Reasoning through Counterfactual Distillation.” The researchers propose a novel framework that forces small models to stop memorizing and start understanding causal relationships. They achieve this by generating counterfactual data (what if scenarios) and employing Multi-View Chain-of-Thought (arguing for the right answer and against the wrong ones).
Let’s unpack how this works, step by step.
The Core Problem: Spurious Correlations
To understand why standard distillation fails, we first need to understand how small models “think” compared to large models.
When an LLM answers a question, it typically utilizes a vast amount of world knowledge to deduce the answer. When an SLM is trained to mimic this, it often lacks that depth of knowledge. To minimize its training error, the SLM looks for shortcuts. It notices that certain words appear together frequently and assumes they are causally linked.
The authors of the paper illustrate this problem perfectly with a commonsense reasoning example involving a weasel and chicken eggs.
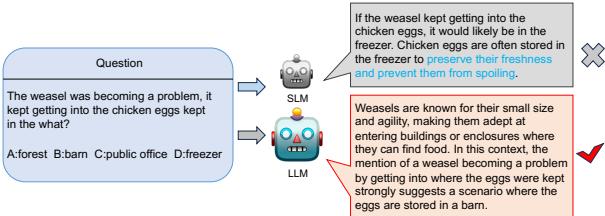
As shown in Figure 1, the question asks: “The weasel was becoming a problem, it kept getting into the chicken eggs kept in the what?”
- The LLM (Teacher) correctly reasons that weasels get into enclosures and eggs are kept in barns. It selects Barn.
- The SLM (Student), trained via standard CoT distillation, sees the words “chicken eggs” and “kept.” In its training data, “eggs” and “kept” are frequently associated with “freezer” (for preservation). It ignores the context of the “weasel” entirely and hallucinates a reasoning path to justify Freezer.
This is a spurious correlation. The model learned that \(A \rightarrow B\) usually happens, so it applied it blindly, ignoring the causal context (the weasel). To fix this, we need to teach the model to distinguish between correlation (eggs are often in freezers) and causation (the weasel implies the eggs are not in a freezer).
The Solution: Counterfactual Distillation Framework
The researchers propose a method that improves standard CoT distillation in two distinct ways:
- Counterfactual Data Augmentation: Creating “what if” versions of training examples to break spurious correlations.
- Multi-View CoT: Teaching the model to not just explain why the right answer is right, but why the wrong answers are wrong.
The overall architecture of their approach is visualized below.
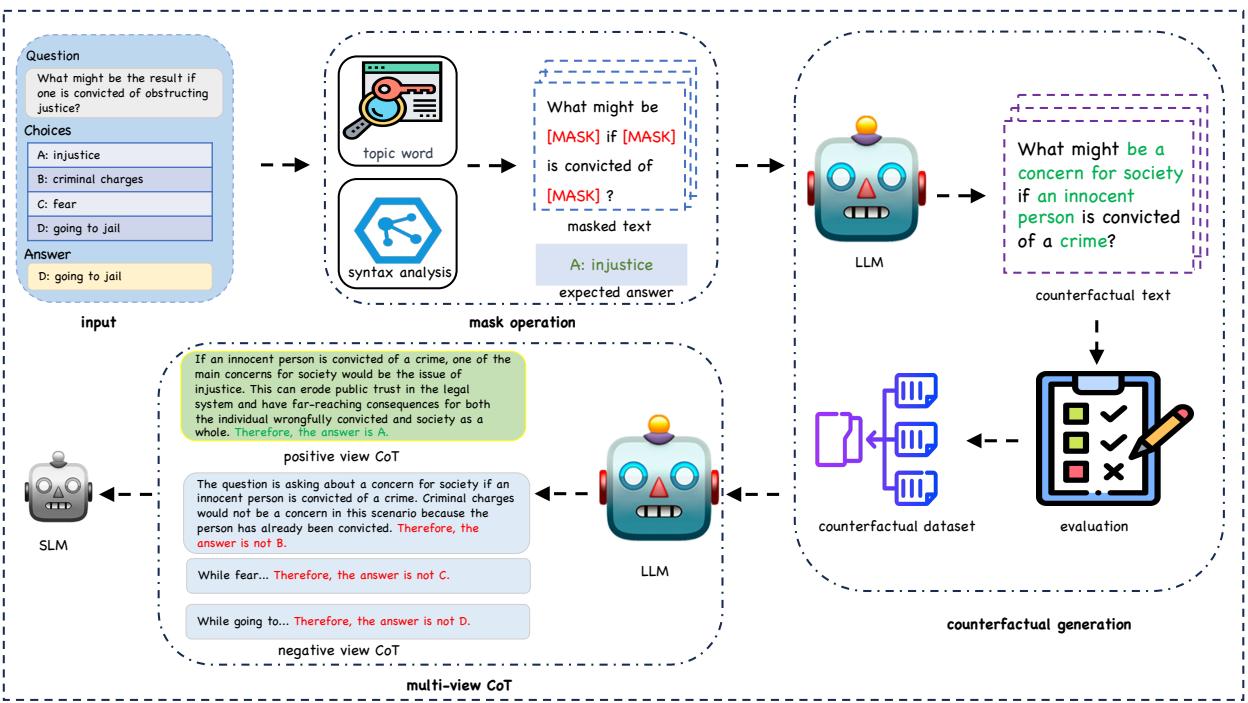
As we can see in Figure 2, the process flows from the input data through a “Mask Operation” to generate counterfactuals, and finally into a “Multi-View CoT” generation module. Let’s break down these stages.
1. Disrupting Causal Relationships (The Mask Operation)
To teach a model causal reasoning, you need to show it examples where changing a small detail leads to a completely different outcome. The researchers automate this using LLMs.
First, they need to identify the “topic words” or “noun phrases” that drive the causal logic of the sentence. If we change these words, the answer should change. If the model ignores this change and gives the old answer, we know it’s not reasoning.

In Figure 3, we see the mechanism for identifying these key phrases. The system prompts an LLM to identify the “topic word.” For example, in the sentence “James was looking for a good place to buy farmland,” the topic word is farmland.
Once these causal keywords and noun phrases are identified, the system masks them out (replaces them with [MASK]). This disrupts the original causal link.
2. Counterfactual Generation
Now that we have a sentence with holes in it, the next step is to fill those holes to create a Counterfactual Example.
A counterfactual example is a variation of the original input that is similar in structure but has a different ground-truth answer. The goal is to force the SLM to pay attention to the specific words that differentiate the original from the counterfactual.

Figure 4 demonstrates the prompt engineering used here. The researchers provide an LLM with the masked question and a new, target answer. The LLM must fill in the blanks so that the sentence makes sense for that new answer.
- Original: “What might be the result if one is convicted of obstructing justice?” \(\rightarrow\) Answer: Going to jail.
- Counterfactual: “What might be a concern for society if an innocent person is convicted of a crime?” \(\rightarrow\) Answer: Injustice.
By training the SLM on both the original and the counterfactual, the model learns that it cannot just blindly associate “convicted” with “jail.” It must read the specific context (“obstructing justice” vs. “innocent person”) to determine the correct outcome.
To ensure quality, the researchers use a filtering strategy: they generate multiple reasoning paths for the new counterfactual. If the LLM consistently arrives at the new target answer, the data is kept. If the LLM is confused, the data is discarded.
3. Multi-View Chain-of-Thought (CoT)
Standard distillation usually asks the model: “Why is Option A correct?” However, human reasoning often works by elimination: “Option B is definitely wrong because X, and Option C is impossible because Y, so it must be Option A.”
The researchers introduce Multi-View CoT to replicate this. They generate two types of reasoning paths for the SLM to learn:
- Positive View CoT (PVC): The standard explanation supporting the correct answer.
- Negative View CoT (NVC): Refutational rationales for the incorrect options.
Referring back to the workflow in Figure 2, you can see the model is fed both views. This provides “dense” supervision. The model learns distinct knowledge:
- From PVC, it learns to find supporting evidence.
- From NVC, it learns to identify contradictions and perform elimination.
Training the Model
The training process combines the original data and the generated counterfactual data. The SLM is fine-tuned to generate the rationale (reasoning) and the final label.
To distinguish between the positive and negative reasoning strategies, the researchers append special control tokens to the input:
[Direct election]signals the model to generate a Positive View (supporting the answer).[Elimination method]signals the model to generate a Negative View (refuting an incorrect option).
The loss function used is the standard language modeling loss, which calculates the probability of generating the correct reasoning tokens (\(t_i\)) given the question (\(q\)), options (\(o\)), and the strategy token (\(st\)).
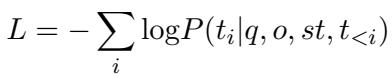
This equation essentially says: we train the model to maximize the likelihood of producing the correct explanation and answer step-by-step.
Experimental Results
The researchers tested their method on four major reasoning benchmarks: CommonsenseQA (CSQA), QuaRel, QASC, and ARC. They used various SLM architectures, including GPT-2, OPT, and GPT-Neo, ranging from 120M to 770M parameters.
1. Does it beat standard fine-tuning?
The results are highly impressive. The table below compares the proposed method against standard Fine-Tuning (FT) and standard CoT Distillation (FT-CoT).
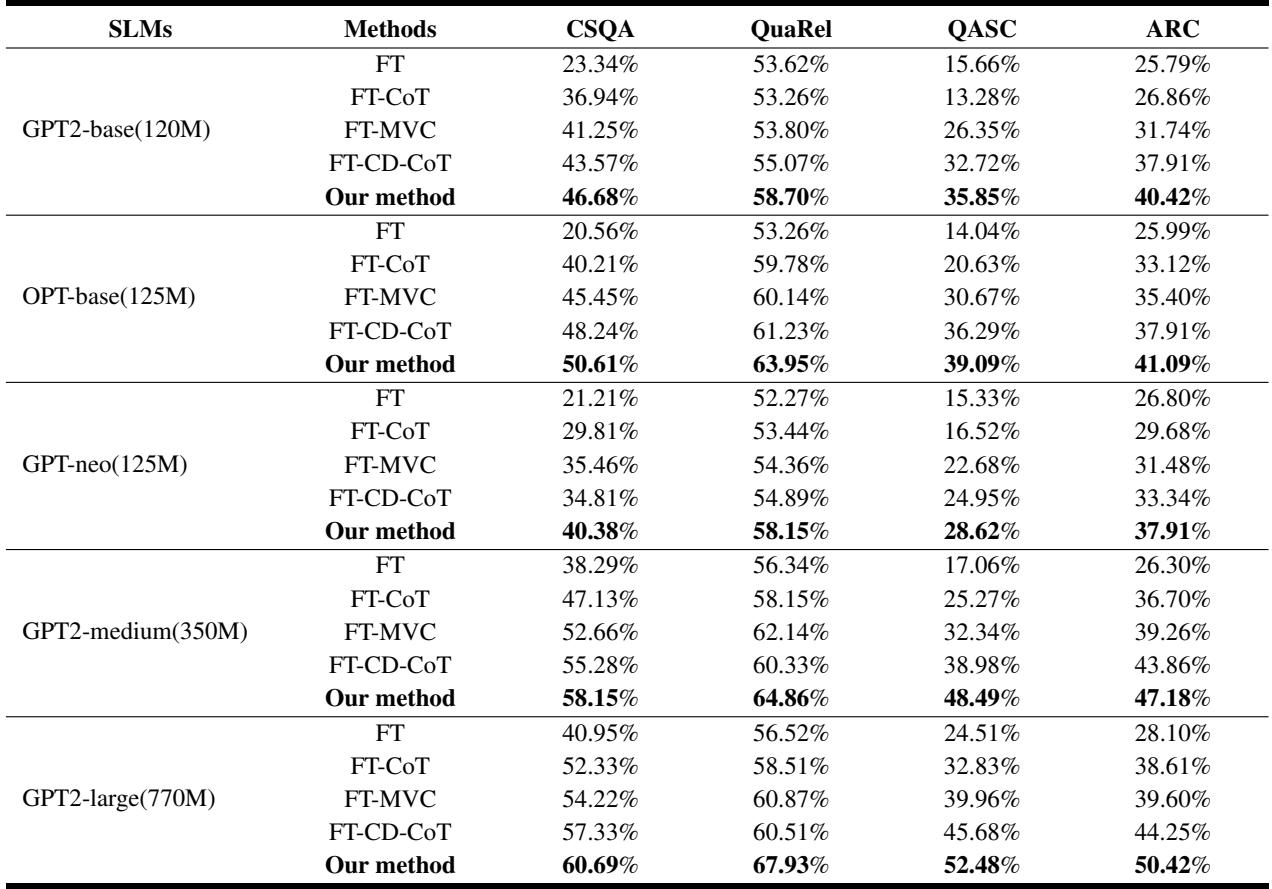
Looking at Table 1, the column “Our method” consistently shows the highest accuracy across all datasets and model sizes.
- Magnitude of Improvement: On average, the method improves upon standard CoT distillation by 11.43%.
- Efficiency: A very small model (GPT2-base, 120M parameters) trained with this method often outperforms a much larger model (GPT2-medium, 350M parameters) trained with standard methods. For example, on the ARC dataset, GPT2-base with Counterfactual Distillation scores 40.42%, beating the larger GPT2-medium’s score of 36.70%.
2. Generalization to Out-of-Distribution (OOD) Data
The ultimate test of reasoning is whether the model can apply what it learned to new, unseen scenarios (Out-of-Distribution). If a model is relying on spurious correlations (memorizing specific word pairs), it will fail when the data distribution changes.
The researchers tested this by training on one dataset and testing on the other three.
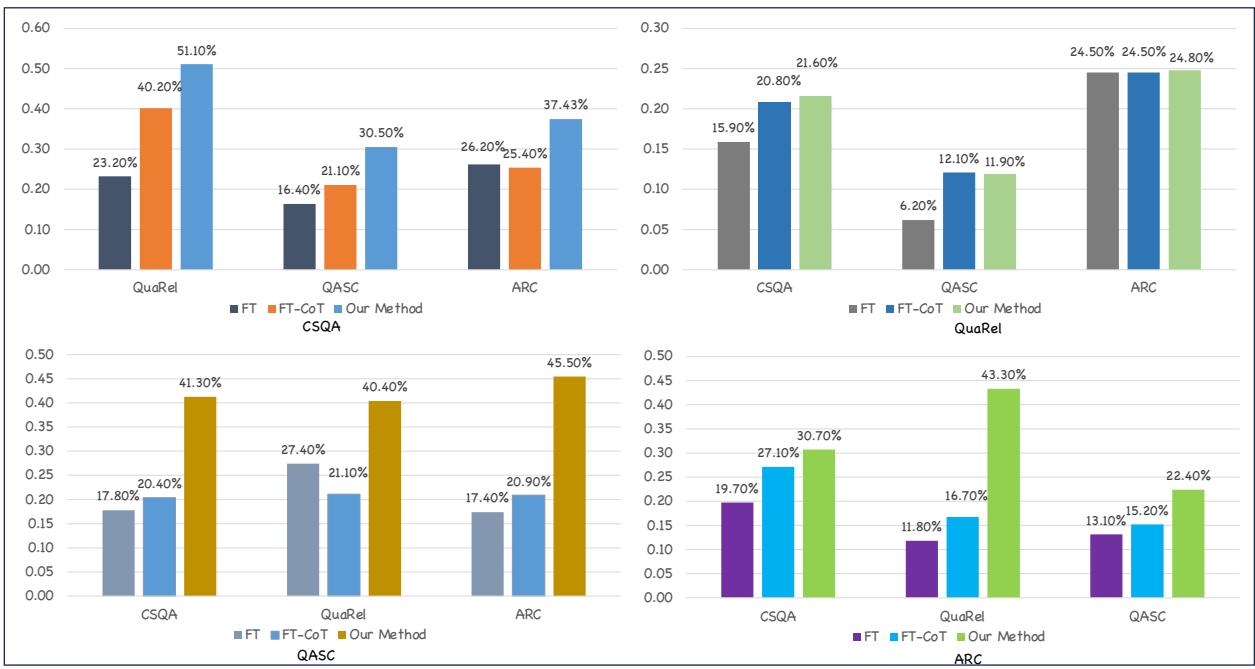
Figure 5 clearly shows the robustness of the proposed method (represented by the third bar in each cluster). When trained on CSQA, QASC, or ARC, the counterfactual method significantly outperforms the baseline (FT-CoT). This confirms that the model isn’t just memorizing; it is learning transferable reasoning structures.
(Note: The performance gain is smaller when training on QuaRel, likely because QuaRel is a smaller dataset with a different binary-choice format, making transfer harder for all methods.)
3. Versatility Across Architectures
Is this method specific to GPT-style models? To find out, the researchers applied it to Encoder-Decoder models like BART and T5.
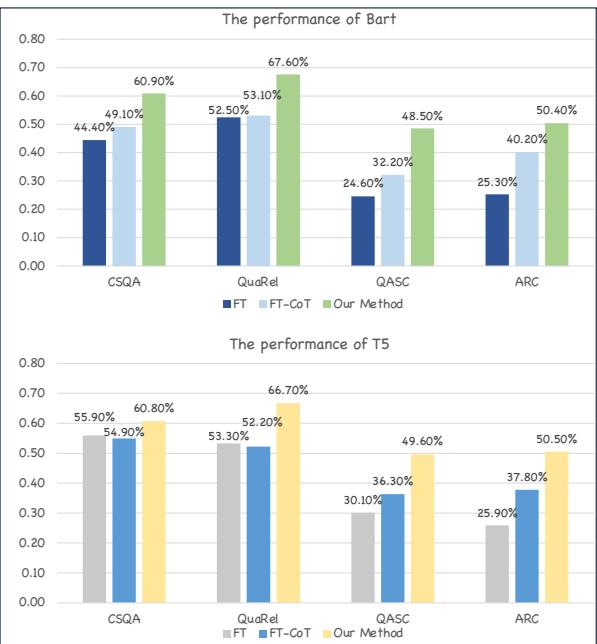
Figure 6 shows that the gains are consistent. Whether using BART or T5, the “Our Method” bar (green) is significantly higher than the standard CoT baseline (orange). This suggests the framework is a universal enhancer for small language models.
Why Does It Work? A Qualitative Look
To really drive home why this works, let’s look at a qualitative comparison of the reasoning generated by the new method versus the old method.
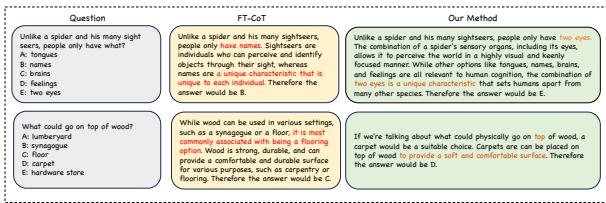
Figure 7 provides two illuminating examples:
- The “Human vs. Spider” Question:
- FT-CoT (Baseline): The model focuses on the phrase “two eyes” and selects it. While the answer is technically correct, the reasoning is shallow.
- Our Method: The model generates a much richer explanation: “Humans perceive the world through senses… including vision… having two eyes.” It connects the concept of “sighters” to “vision” and “eyes.”
- The “Wood on Wood” Question:
- The question asks where wood goes on top of wood.
- FT-CoT picks “floor” because wood and floor are frequent collocations.
- Our Method explains why: “Flooring provides a comfortable surface… often placed on top of other wooden surfaces.”
By training on counterfactuals, the model learns that the relationship between words is governed by the rules of the world (causality), not just how often they appear next to each other in a sentence.
Conclusion and Implications
This research highlights a critical limitation in how we have been training small AI models. Simply “distilling” the answers or even the reasoning from large models isn’t enough if the student model is just memorizing the teacher’s words without understanding the logic.
By introducing Counterfactual Distillation, the researchers have found a way to “stress test” the student model during training.
- Counterfactuals force the model to look for causal triggers rather than surface patterns.
- Multi-View CoT equips the model with the ability to verify answers via elimination, mimicking human critical thinking.
For students and practitioners in NLP, this paper offers a valuable lesson: Data quality and diversity (specifically causal diversity) matter more than just data volume. You don’t always need a larger model to get better reasoning; sometimes, you just need to teach the small model to ask “What if?” and “Why not?”