](https://deep-paper.org/en/paper/11875_gmail_generative_modalit-1762/images/cover.png)
引言
我们正处于生成式 AI 的“黄金时代”。像 Stable Diffusion 和 DALL-E 3 这样的模型能够在几秒钟内根据简单的文本描述变幻出照片般逼真的图像。对于机器学习研究人员和学生来说,这创造了一个诱人的可能性: 无限的训练数据。
想象一下,你想要训练一个视觉系统来识别稀有物体或复杂场景。与其花费数月时间收集和标注现实世界的照片,为什么不直接生成数百万张合成图像呢?这听起来像是解决数据稀缺问题的完美方案。
然而,这里有一个陷阱。最近的研究表明,在训练过程中不加区分地混合生成的图像和真实图像,往往会导致模式崩溃 (mode collapse) 和性能下降。模型开始“过拟合”合成数据的特定伪影 (artifacts) 和统计怪癖,导致其在真实世界的输入上测试时失败。
这就引出了一篇令人着迷的新论文: 《GMAIL: Generative Modality Alignment for generated Image Learning》 (GMAIL: 用于生成图像学习的生成模态对齐) 。
在这篇文章中,我们将深入探讨 GMAIL 如何提出这一问题的解决方案。作者引入了一个巧妙的框架,不再将生成的图像视为“假的真实图像”,而是将其视为一种与真实图像截然不同的独立模态 (modality) ——就像我们在 CLIP 等模型中将“文本”和“图像”视为不同模态一样——并在共享的潜在空间中对它们进行数学上的对齐。
问题: 数据的恐怖谷
要理解 GMAIL,我们首先需要了解当前方法的失败模式。
当你混合真实数据和合成数据来训练模型 (如视觉-语言模型或 VLM) 时,你本质上是在要求它同时学习两种不同的分布。尽管“垫子上的猫”的生成图像在视觉上看起来与真实照片相似,但底层的像素统计数据、纹理模式和频率分布是不同的。
如果模型盲目地在这两者上进行训练,它将难以泛化。它从合成数据中获得的“知识”无法干净地迁移到现实世界的任务中。这通常被称为模态差异 (modality gap) 。
GMAIL 的作者认为,我们应该停止假装合成图像是真实的。相反,我们应该将“生成图像”和“真实图像”视为两种不同的模态。
GMAIL 框架
GMAIL 的核心思想是生成模态对齐 (Generative Modality Alignment) 。 其目标是确保生成图像 (由神经网络产生) 的特征表示与描述相同概念的真实图像的特征表示完美对齐。
让我们分解一下这个架构。
1. 双路径架构
该框架依赖于包含两个并行流的教师-学生 (teacher-student) 设置。
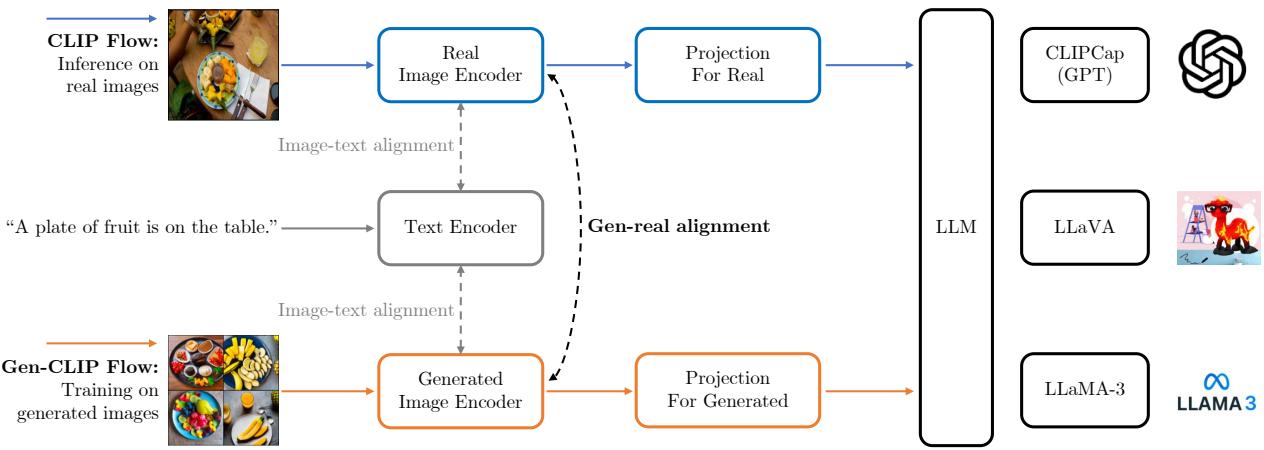
如图 1 所示,该架构分为两条不同的路径:
- CLIP 流 (教师) : 此路径处理真实图像 。 它使用一个预训练的 CLIP 图像编码器,该编码器保持冻结状态 (其权重不更新) 。此编码器代表了现实世界的视觉概念应如何映射到潜在空间的“基准真值 (ground truth) ”。
- Gen-CLIP 流 (学生) : 此路径处理生成的图像 。 它使用一个单独的编码器 (从 CLIP 初始化) ,该编码器会进行微调。此编码器的目标是学习如何处理合成图像,使其嵌入 (embeddings) 与教师的真实图像嵌入相匹配。
通过分离这些流,模型不会被真实像素和合成像素之间的统计差异所困扰。它拥有一个专门用于生成数据的“眼睛” (编码器) 。
2. 使用 LoRA 进行高效微调
从头开始重新训练一个庞大的编码器既昂贵又有“灾难性遗忘” (忘记原始预训练知识) 的风险。为了解决这个问题,作者采用了低秩适应 (Low-Rank Adaptation, LoRA) 。
LoRA 冻结预训练模型的权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层中。这使得 GMAIL 能够通过仅更新极小部分的参数来使模型适应“生成模态”,从而使该过程在计算上非常高效。
3. 对齐的数学原理
我们实际上如何强制生成的图像嵌入与真实的图像嵌入对齐呢?这是通过跨模态对齐损失 (Cross-Modality Alignment Loss) 来完成的。
目标是最小化生成图像 (\(x_g\)) 的嵌入与共享相同语义含义 (例如,相同的标题) 的真实图像 (\(x_r\)) 的嵌入之间的距离。
其数学公式是一个对比损失函数:
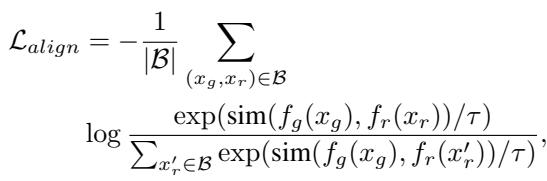
让我们解读一下这个方程:
- \(f_g(x_g)\) : 来自学生编码器的生成图像嵌入。
- \(f_r(x_r)\) : 来自冻结教师编码器的真实图像嵌入。
- \(\text{sim}(\cdot)\) : 余弦相似度 (衡量两个向量的接近程度) 。
- \(\tau\) : 温度参数,用于缩放 logits。
分子部分鼓励模型拉近正样本对 (生成的图像及其对应的真实图像) 。分母部分将生成的图像推离批次中的其他真实图像 (负样本) 。
这迫使学生编码器学习一种转换,以“纠正”合成伪影,将生成的图像映射到向量空间中真实图像所在的完全相同的位置。
可视化潜在空间
为了真正理解为什么这种对齐是必要的,我们可以看一个 t-SNE 图。t-SNE 是一种将高维数据可视化的技术。
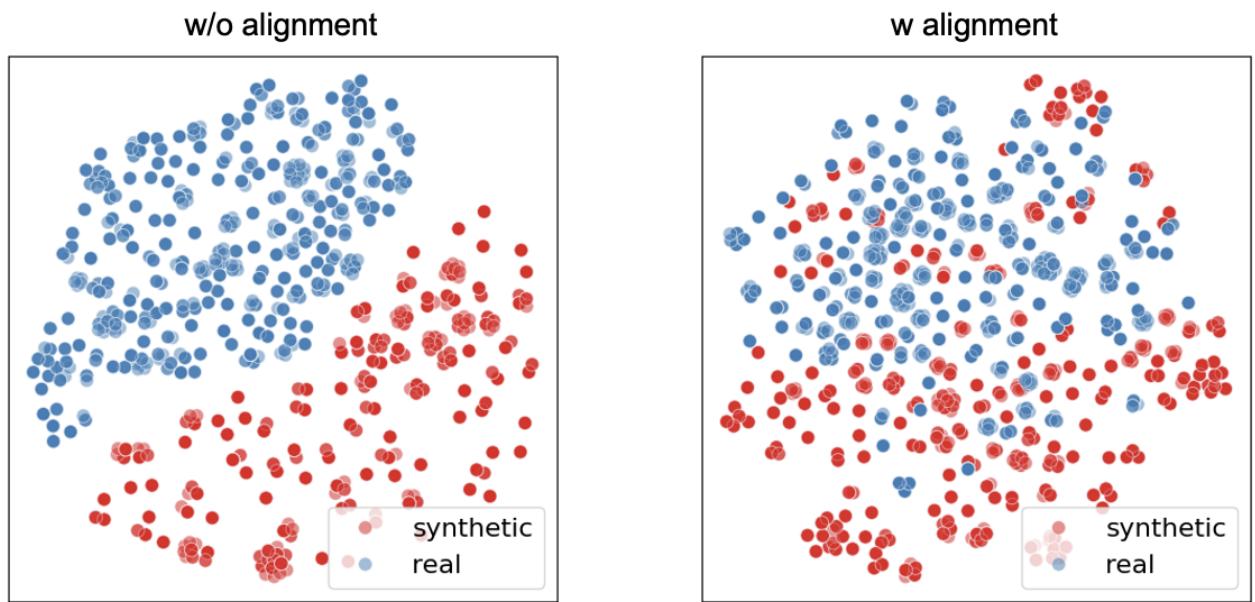
在图 3 (左) 中,我们看到了没有对齐时的世界状态。蓝点 (真实图像) 和红点 (合成图像) 形成了两个截然不同、相互分离的簇。这可视化了“模态差异”。在这个红色簇上训练的分类器会在蓝色簇上失败,因为它们在数学空间中本质上位于不同的区域。
在图 3 (右) 中,我们看到了 GMAIL 的结果。红点和蓝点完美地混合在一起。对齐损失成功地迫使合成表示与真实表示重叠。这意味着在该对齐的合成特征上训练的模型将天然地泛化到真实数据。
实验与结果
这种理论上的对齐实际上能否提高下游任务的性能?作者在几个主要的计算机视觉基准上测试了 GMAIL。
图像描述 (Image Captioning)
第一个测试是 COCO 数据集上的图像描述。模型使用生成的图像进行训练,然后要求其为真实图像编写描述。
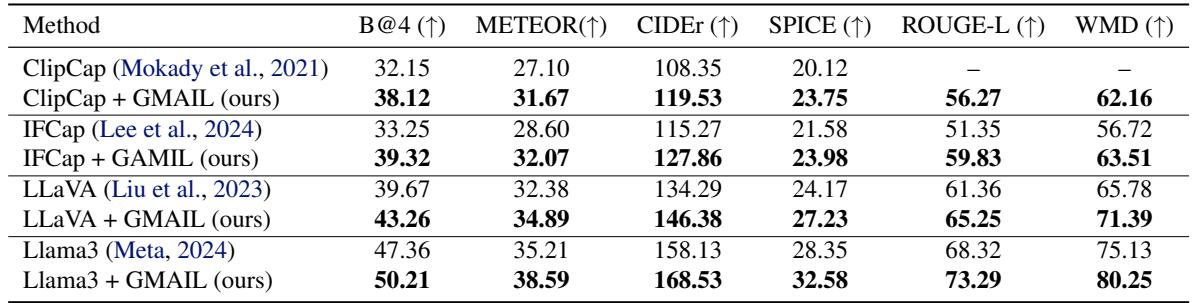
如表 1 所示,GMAIL 显著优于基线。
- B@4 (BLEU 分数) 和 CIDEr 是描述质量的标准指标 (越高越好) 。
- ClipCap + GMAIL 取得了 119.53 的 CIDEr 分数,大幅击败了标准 ClipCap (108.35)。
- 该框架还提升了像 LLaVA 和 LLaMA-3 这样的大型模型的性能,证明了这种对齐技术与模型无关。
零样本检索 (Zero-Shot Retrieval)
接下来,他们研究了零样本图像检索——为文本查询找到正确的图像 (文生图) 或为图像查询找到正确的文本 (图生文) 。

在表 2 中,我们看到了持续的改进。例如,在文生图检索 (R@1) 中,GMAIL 将基线 CLIP 从 32.7 提升到了 37.5 。 这表明对齐过程帮助模型比标准预训练更好地理解了文本和视觉概念之间的语义联系。
它具有扩展性吗?
合成数据的一个承诺是可扩展性。如果我们生成更多的图像,模型会变得更好吗?
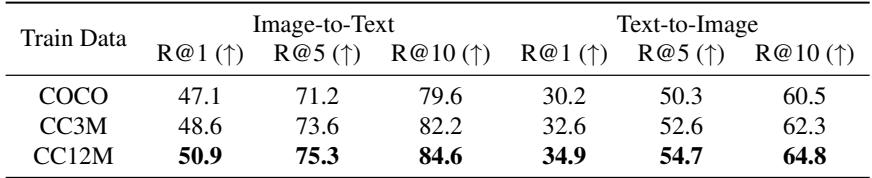
表 7 给出了答案: 是的。 当作者将合成训练数据从 COCO 规模 (大约 56 万张图像) 增加到 CC12M 规模 (1200 万张图像) 时,检索性能显著跃升 (例如,图生文 R@1 从 47.1 升至 50.9) 。
这是一个至关重要的发现。它表明 GMAIL 有效地释放了大规模合成数据的潜力。只要你正确地对齐数据,你就可以通过生成更多数据来改进你的模型。
审视数据
值得注意的是,这项研究中使用的生成图像 (由 Stable Diffusion v2 创建) 质量很高。

图 2 展示了并排比较。生成的图像 (第 2-6 列) 非常好地捕捉了真实图像 (第 1 列) 的高级语义。然而,它们并不是像素级的完美复制。它们包含扩散模型特定的“指纹”。
如果没有 GMAIL,模型可能会锁定这些特定的扩散伪影 (例如,模型如何渲染光照或纹理) 。GMAIL 迫使模型忽略这些伪影,只关注与真实图像一致的语义内容。
结论
GMAIL 论文为我们如何处理即将到来的合成数据洪流提出了一个令人信服的论点。它告诉我们, 更多的数据并不总是更好——除非它是经过对齐的。
通过将生成的图像视为一种独立的模态,并在数学上强制它们与现实世界的分布对齐,GMAIL 为训练下一代视觉-语言模型提供了一个稳健的框架。
给学生的关键要点:
- 模态差异: 合成数据遵循与真实数据不同的分布;忽略这一点会导致模式崩溃。
- 教师-学生对齐: 你可以使用在真实数据上训练的冻结模型 (教师) 来指导在合成数据上训练的模型 (学生) 。
- 潜在空间: 胜负取决于潜在空间。像 t-SNE 这样的可视化是验证你的模型是否真的学到了你认为它学到的东西的强大工具。
- 效率: 像 LoRA 这样的技术对于现代深度学习研究至关重要,使我们能够在有限的计算资源下调整巨大的模型。
随着生成模型不断改进,像 GMAIL 这样的框架可能会成为标准实践,成为连接 AI 生成的创造力与 AI 理解的实际需求之间的桥梁。