](https://deep-paper.org/en/paper/13000_not_all_wrong_is_bad_usi-1611/images/cover.png)
在 GDPR、加州消费者隐私法案 (CCPA) 以及数字监控日益加强的时代,“被遗忘权”已经从哲学概念转变为技术必需品。当用户删除服务账户时,他们期望自己的数据不仅从数据库中消失,也能从接受过这些数据训练的 AI 模型的“大脑”中消失。
这一过程被称为机器遗忘 (Machine Unlearning) 。
理想情况下,当数据被移除时,我们会简单地在该数据缺失的情况下从头开始重新训练 AI 模型。这被称为“精确遗忘” (exact unlearning)。它效果完美,但在成本和时间上却是天文数字。试想一下,每当有一位用户提交删除请求,就要重新训练一个庞大的大语言模型或 ImageNet 分类器。这在计算上是不可行的。
这促使研究人员寻找“近似”解决方案——即无需繁重的重新训练,通过微调现有模型使其表现得像从未见过该数据一样的方法。然而,这些捷径往往伴随着代价: 它们要么降低模型的整体准确性,要么无法真正删除信息,使模型容易受到隐私攻击。
在这篇文章中,我们将深入探讨论文 “Not All Wrong is Bad: Using Adversarial Examples for Unlearning” 中提出的一种新方法。这项技术被称为 AMUN (Adversarial Machine UNlearning,对抗性机器遗忘),它采用了一种反直觉的方法: 在“错误”数据——具体来说是对抗样本——上微调模型,从而在保留模型整体智能的同时,通过外科手术般的方式移除记忆。
黄金标准: “遗忘”看起来是什么样的?
在设计让模型遗忘的方法之前,我们需要了解模型在未曾见过某数据时的表现。
在机器学习中,我们通常将数据分为训练集 (模型会记住的) 和测试集 (模型从未见过的) 。
- 训练数据: 模型通常对这些样本非常有信心。
- 测试数据: 模型可以正确分类这些数据,但其预测置信度 (概率得分) 通常低于训练数据。
因此,如果我们成功地“遗忘”了一个特定的数据子集 (我们称之为遗忘集 , 或 \(\mathcal{D}_F\)) ,模型对待这些样本的方式应该就像对待未见过的测试集 (\(\mathcal{D}_T\)) 一样。它不一定非要将它们分类错误,但它不应该对它们过度自信。
研究人员分析了从头开始重新训练的模型 (即“黄金标准”) 来可视化这种行为。

如上图直方图所示,在重新训练的模型中,“遗忘集” (绿色柱状) 的置信度分布与“测试集” (橙色线) 完美重叠。模型对待它本应遗忘的数据,就像对待它从未见过的数据一样。
核心洞察: 大多数先前的遗忘方法试图强迫模型做出随机预测或最大化遗忘集上的误差。这是不自然的。目标不应是让模型在被删除数据上变得“愚蠢”;目标是让模型变得漠不关心且置信度降低,使其行为与未见数据的自然分布保持一致。
解决方案: 对抗性机器遗忘 (AMUN)
研究人员提出了一种名为 AMUN 的方法。其核心思想依赖于对抗样本 (Adversarial Examples) 。
什么是对抗样本?
通常,对抗样本被视为安全威胁。它们是经过轻微修改 (通常人类无法察觉) 的输入 (如图像) ,旨在欺骗神经网络以高置信度做出错误的分类。例如,改变熊猫图片中的几个像素可能会让模型认为它是一只长臂猿。
这些样本的存在是因为深度学习模型学习的决策边界对训练数据高度特异。对抗样本恰好位于决策边界的另一侧。
变武器为工具
AMUN 反转了剧本。它不是利用对抗样本来攻击模型,而是用它们来“治愈”模型的特定记忆。
逻辑如下:
- 模型已经“记住”了遗忘集 (\(\mathcal{D}_F\)) 并且对其非常有信心。
- 我们希望降低这种置信度,但不破坏模型在其余数据上的表现。
- 我们为遗忘集生成对抗样本。这些输入 (\(x_{adv}\)) 看起来与原始数据 (\(x\)) 非常相似,但被预测为不同的类别 (\(y_{adv}\))。
- 我们使用这些错误的标签在对抗样本上对模型进行微调 。
这听起来很危险。为什么在错误标签上训练会有帮助?
当模型在带有标签 (\(y_{adv}\)) 的对抗样本 (\(x_{adv}\)) 上进行微调时,它被告知: “这个看起来像原始数据 \(x\) 的输入,属于类别 \(y_{adv}\)。” 然而,原始模型知道 \(x\) 属于类别 \(y\)。 由于 \(x\) 和 \(x_{adv}\) 在数学输入空间中非常接近,模型被拉向两个方向。它试图适应新信息 (对抗性标签) ,同时也想保留其现有的知识 (原始标签) 。
结果是决策边界的“平滑化”。模型并没有灾难性地遗忘概念;它只是对输入空间的那个特定区域变得不那么自信了。这恰好模仿了我们在“黄金标准”重训练模型中看到的现象: 对遗忘集的置信度降低。
算法 1: 构建对抗集
AMUN 的第一步是生成这些特定的对抗样本。该算法为我们要遗忘的每张图像搜索“最近”的可能对抗样本。

工作原理:
- 从遗忘集中取出一个样本 \((x, y)\)。
- 从一个非常小的扰动半径 (\(\epsilon\)) 开始。
- 使用攻击方法 (如 PGD) 尝试在该半径内找到一个对抗样本。
- 如果模型仍然预测正确的标签,则将半径 (\(\epsilon\)) 加倍并重试。
- 一旦找到对抗样本 \((x_{adv}, y_{adv})\),将其添加到数据集 \(\mathcal{D}_A\) 中。
通过找到最近的可能对抗样本,该方法确保了对模型的更改是局部化的。我们只想影响模型在我们想要删除的数据周围微小邻域内的行为,而保持模型其余的知识完好无损。
为什么“并非所有错误都是坏的”
人们可能会认为在带有错误标签的数据上训练模型会破坏其准确性。作者进行了一项消融研究来证明情况并非如此,前提是“错误”数据选择得当。
他们比较了在以下数据上进行微调:
- Adv (\(\mathcal{D}_A\)): AMUN 生成的对抗样本。
- 随机标签 (Random Labels): 带有随机错误标签的原始图像。
- 随机噪声 (Random Noise): 带有对抗性标签的随机噪声图像。
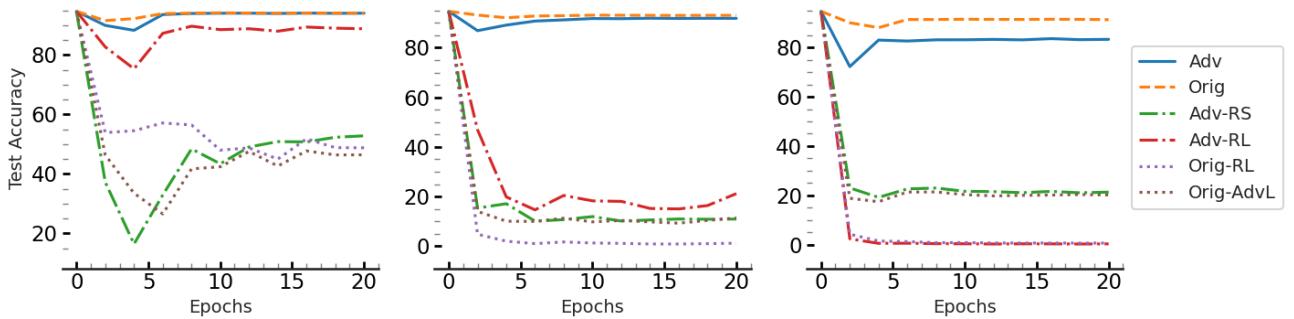
图 1 中的结果令人震惊。
- 蓝线 (Adv) 代表在 AMUN 的对抗样本上微调的模型。请注意,测试准确率 (Test Accuracy) (Y 轴) 保持稳定且处于高位。
- 橙色虚线 (Orig) 是基准性能。
- 其他线条 (绿色、红色、紫色) 代表在随机标签或其他“错误”数据变体上微调的模型。它们遭受了灾难性遗忘 (Catastrophic Forgetting)——准确率直线下降。
结论: 对抗样本天然属于模型“学到”的分布 (即使该分布略有缺陷) 。在它们之上进行微调比在随机垃圾数据上微调要安全得多,因为它在纠正模型对特定样本的过度自信的同时,尊重了模型的内部逻辑。
理论保证
作者用理论界限支持了这一经验性的成功。他们推导了已遗忘模型 (我们从 AMUN 得到的) 与重新训练模型 (黄金标准) 之间差异的上限。
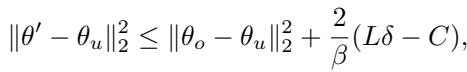
这个等式可能看起来很复杂,但其中的组成部分讲述了一个清晰的故事:
- \(\delta\) (delta): 这代表原始图像与对抗样本之间的距离 (\(||x - x_{adv}||\))。
- 界限 (The Bound): 我们的模型与完美的重新训练模型之间的差异与 \(\delta\) 成正比。
翻译一下: 对抗样本越接近原始图像 (\(\delta\) 越小) ,AMUN 就越接近遗忘的完美“黄金标准”。这从数学上证明了算法 1 搜索最近可能对抗样本的策略是合理的。
实验与结果
研究人员将 AMUN 与几种最先进 (SOTA) 的遗忘方法进行了对比测试,包括“精确重新训练” (RETRAIN)、“微调” (FT) 以及像“SalUn”和“稀疏性 (Sparsity)”这样的新方法。
他们使用成员推断攻击 (Membership Inference Attacks, MIA) 来评估这些方法。
- 目标: 攻击者试图猜测特定图像是否在训练集中。
- 指标: 我们希望攻击失败。理想情况下,攻击的成功率 (AUC) 应为 50% (相当于随机抛硬币) 。如果 MIA 得分很高,说明模型并没有真正遗忘数据。
设置 1: 可访问剩余数据
在理想情况下,遗忘算法可以访问保留集 (\(\mathcal{D}_R\))——即应保留在模型中的数据。这允许该方法在擦除遗忘集的同时,“提醒”模型应该保留什么。
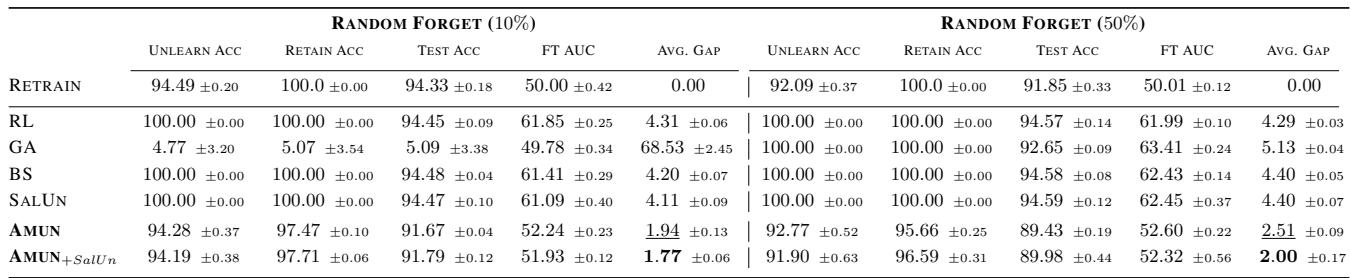
如表 1 所示, AMUN 实现了最佳性能 (最低的平均差距) 。
- 遗忘准确率 (Unlearn Acc): 遗忘集上的准确率略有下降,与重新训练的模型相匹配。
- 测试准确率 (Test Acc): 未见数据的准确率保持在高位 (93.45%)。
- MIA 差距 (MIA Gap): 成员推断攻击的表现几乎等同于随机猜测 (FT AUC \(\approx\) 50%),证明隐私风险已被消除。
设置 2: 无法访问剩余数据 (困难模式)
这才是 AMUN 真正大放异彩的地方。在许多现实世界的隐私场景中,由于存储、隐私或法规孤岛,每次遗忘请求都访问完整的训练数据集 (\(\mathcal{D}_R\)) 是不可能的。
大多数现有方法在此处都会崩溃。没有保留集作为锚点,它们往往会导致模型遗忘一切 (灾难性遗忘) 。
然而,AMUN 只需要遗忘集 (\(\mathcal{D}_F\)) 和生成的对抗样本 (\(\mathcal{D}_A\))。由于对抗样本保留了数据的自然分布,它们天生就能防止模型崩溃。论文证明,即使没有保留集,AMUN 也显著优于竞争对手,在有效清除遗忘集的同时保持了较高的测试准确率。
可视化成功效果
置信度得分真的发生变化了吗?

图 5 可视化了 AMUN 的成功。
- 左图 (遗忘前) : 遗忘集 (绿色) 看起来与保留集 (蓝色) 完全一样——置信度很高。
- 右图 (AMUN 之后) : 遗忘集 (绿色) 向左移动,与测试集 (橙色) 完美对齐。模型已成功“遗忘”了已删除数据与未见数据之间的区别。
持续遗忘
现实世界的请求不会一次性发生。用户会随着时间的推移陆续删除帐户。一个稳健的遗忘系统必须能够处理多波删除请求而不退化。
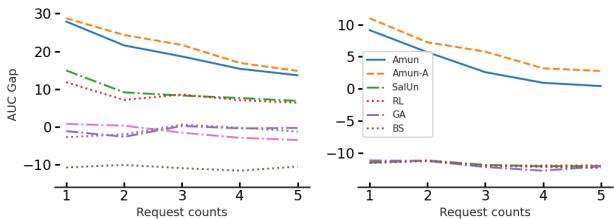
图 2 展示了 AMUN 的持久性。即使在 5 次连续的遗忘请求 (每次删除 2% 的数据) 之后,AMUN 仍保持较低的 AUC 差距。这表明,即使模型经历了反复修改,样本依然持续表现得更像测试数据而不是训练数据。
结论
AMUN 代表了隐私保护 AI 向前迈出的重要一步。通过认识到 “并非所有错误都是坏的” , 研究人员解锁了对抗样本的强大效用。
AMUN 不是去对抗模型容易被对抗性扰动欺骗的倾向,而是利用这一漏洞对神经网络进行精确的“脑科手术”。通过在这些特定的、错误标签的样本上进行微调,它迫使模型局部降低其置信度。
关键要点:
- 效率: AMUN 避免了从头开始重新训练的巨大成本。
- 准确性: 与注入随机噪声不同,使用对抗样本保留了模型正确分类未见数据的能力。
- 独立性: 即使在原始训练数据不可用的情况下,AMUN 也能表现得非常出色,解决了数据隐私合规中的一个主要后勤障碍。
随着隐私法规的收紧,像 AMUN 这样的技术对于维持强大的 AI 与用户删除其数字足迹的权利之间的微妙平衡将至关重要。