](https://deep-paper.org/en/paper/13597_swe_lancer_can_frontier_-1885/images/cover.png)
在快速发展的大型语言模型 (LLM) 世界中,我们已经看到 AI 系统从解决简单的教科书式编程问题,发展到在国际编程竞赛中赢得奖牌。然而,在解决一个封闭的算法难题与驾驭专业软件工程这一混乱、复杂的现实之间,仍然存在着巨大的鸿沟。
当 OpenAI 宣布 SWE-Bench Verified 时,模型开始显示出希望,但批评者认为,即使是这些基准测试也过于依赖孤立的任务和可能被“博弈”的单元测试。问题依然存在: 如果我们把这些模型部署到现实世界的自由职业市场中,它们真的能拿到报酬吗?
这就是 SWE-Lancer 的登场时刻。
在这篇文章中,我们将剖析 OpenAI 研究人员的一篇引人入胜的新论文,该论文介绍了一个不基于分数或准确率百分比,而是基于 美元 的基准测试。通过策划来自 Upwork 的 1,400 多个真实任务,总支付价值达 100 万美元,SWE-Lancer 试图回答一个挑衅性的经济问题: 前沿 LLM 能否胜任工作并赚取薪水?
当前基准测试的问题
要理解为什么 SWE-Lancer 是必要的,我们需要先看看现有代码评估方法的局限性。
历史上,像 HumanEval 这样的基准测试侧重于程序合成——要求模型编写单个 Python 函数来解决特定的逻辑问题。虽然这对早期的 LLM 很有用,但对于像 GPT-4o 这样的模型来说,这些任务现在已经微不足道了。
接下来的演变是 SWE-Bench , 它引入了代码仓库级的上下文。它要求模型解决流行的开源库中的 GitHub 问题。然而,这些基准测试通常依赖 单元测试——即验证特定函数是否返回特定值的小型、孤立的代码检查。
在现实世界中,软件工程很少仅仅是关于通过单元测试。它是关于“端到端” (E2E) 功能的。网页上的按钮真的能打开模态框吗?当用户提交表单时,数据库是否正确更新?修复是否在移动端和 Web 端都能正常工作?此外,真正的工程涉及管理决策: 根据权衡、依赖关系和技术债务在不同的架构提案之间进行选择。
当前的基准测试很大程度上忽略了这些“全栈”和“管理”层面的复杂性。SWE-Lancer 旨在填补这一空白。
介绍 SWE-Lancer
SWE-Lancer 由 1,488 个真实的自由职业任务构建而成,这些任务来自上市公司 Expensify 的开源仓库。这些任务最初是在 Upwork 上发布的,这意味着真正的人类自由职业者通过解决这些任务赚取了真金白银。
该基准测试通过两项重大创新脱颖而出:
- 经济基础: 每个任务都有特定的美元价值,从 50 美元的错误修复到 32,000 美元的功能实现不等。
- 角色分工: 基准测试将任务分为两个不同的类别: 独立贡献者 (IC) 任务和 软件工程 (SWE) 经理 任务。
1. 独立贡献者 (IC) 任务
基准测试的 IC 部分模拟了开发人员的日常工作。模型会收到一个代码库、一个问题描述,以及修复错误或实现功能的请求。
与其以前使用单元测试 (通常脆弱或容易“过拟合”) 检查代码的基准测试不同,SWE-Lancer 使用 端到端 (E2E) 测试 。 这些测试由专业软件工程师创建并经过三重验证。它们使用浏览器自动化 (通过 Playwright) 来实际与应用程序交互——点击按钮、在字段中输入内容,并验证视觉和逻辑结果。
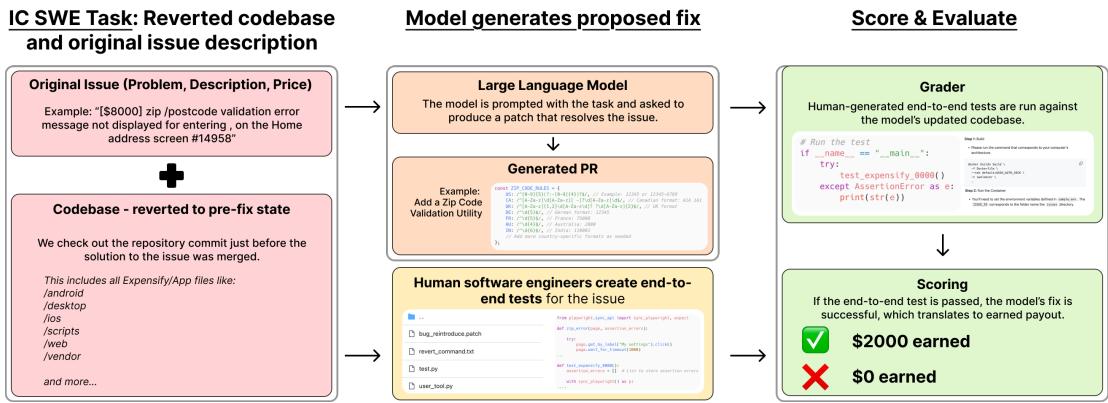
如 图 1 所示,工作流程非常严谨:
- 输入: 模型接收问题描述 (例如,“未显示验证错误”) 和修复前的代码库。
- 行动: 模型生成一个补丁 (一个“拉取请求/Pull Request”) 。
- 评估: 系统针对修补后的代码运行人工生成的 E2E 测试。
- 支付: 如果——且仅当——测试通过,模型将“赚取”相关的奖金 (例如 2,000 美元) 。如果测试失败,它将赚取 0 美元。
这种方法可以防止模型编写在语法上看起来正确,但无法在浏览器中正确渲染或破坏用户流程的代码。
2. SWE 经理任务
软件工程不仅仅是编写代码;还在于决定写 什么 代码。在 Expensify/Upwork 的工作流程中,自由职业者提交关于他们打算如何解决问题的提案。然后经理会审查这些提案并选择最好的一个。
SWE-Lancer 通过要求 LLM 充当经理的角色来捕捉这一动态。
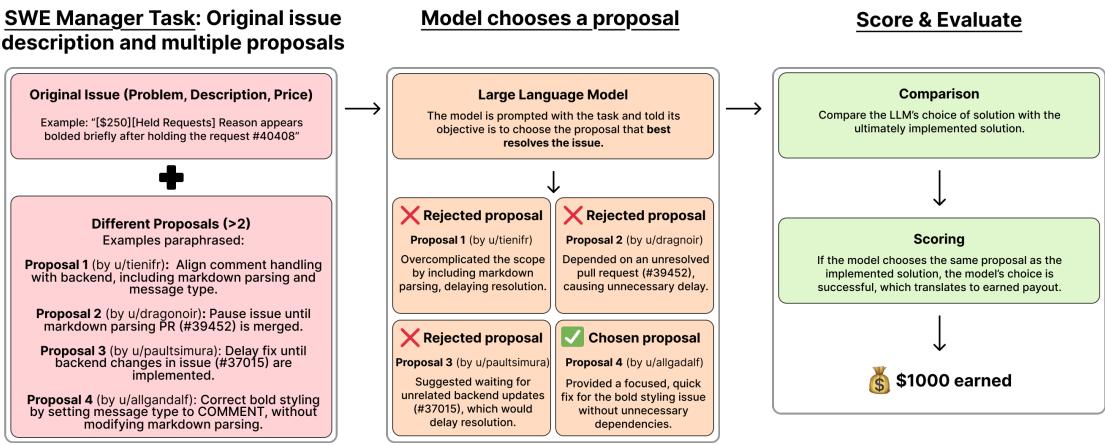
图 2 展示了这个决策过程:
- 上下文: 模型获得问题描述、价格以及人类提交的一组真实提案 (例如,“u/tienifr 的提案 1”,“u/dragonir 的提案 2”) 。
- 推理: 模型可以浏览代码库以验证提案中提出的技术主张。它必须识别哪个提案在技术上是合理的,能最大限度地减少技术债务,并切实解决根本原因。
- 选择: 模型选择一个获胜者。
- 评分: 模型的选择将与负责该项目的人类工程经理所做的实际决定进行比较。如果模型选择了相同的获胜者,它就赚取奖金。
这是该领域的一个重要补充,因为它测试的是 LLM 对代码架构和权衡进行“推理”的能力,而不仅仅是生成语法。
3. 动态定价和难度
SWE-Lancer 最有趣的一个方面是难度源自市场。在标准基准测试中,任务通常被视为同等单位。在 SWE-Lancer 中,50 美元的任务通常比 8,000 美元的任务更简单。
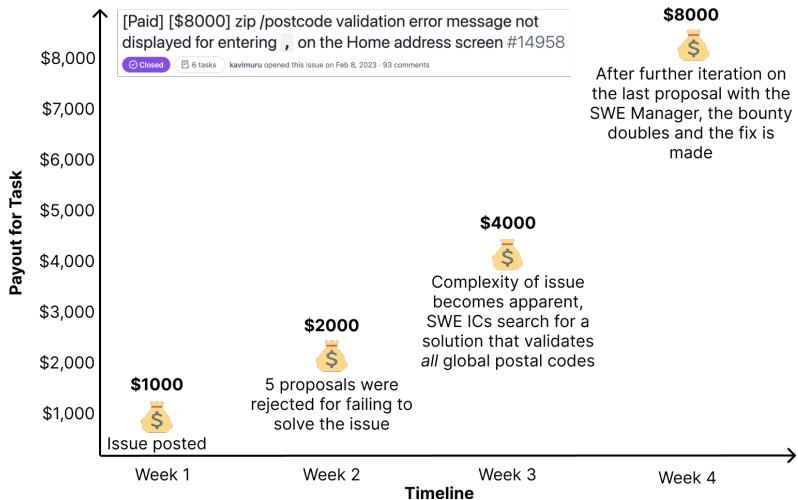
图 4 展示了这种定价在实践中是如何运作的。一个关于邮政编码验证错误的任务最初悬赏 1,000 美元。然而,随着自由职业者提交的提案未能考虑到边缘情况 (如全球邮政编码) ,复杂性变得显而易见。赏金在四周内多次提高,最终定格在 8,000 美元 。
这种动态定价创造了一个自然的难度梯度。通过基于 收入 来评估模型,我们将更多的权重赋予那些真正推动经济影响的复杂、高价值问题,而不是简单的拼写错误或单行修复。
SWE-Lancer 与现状的比较
要真正理解 SWE-Lancer 所代表的飞跃,有助于将其与现有基准测试直接比较。
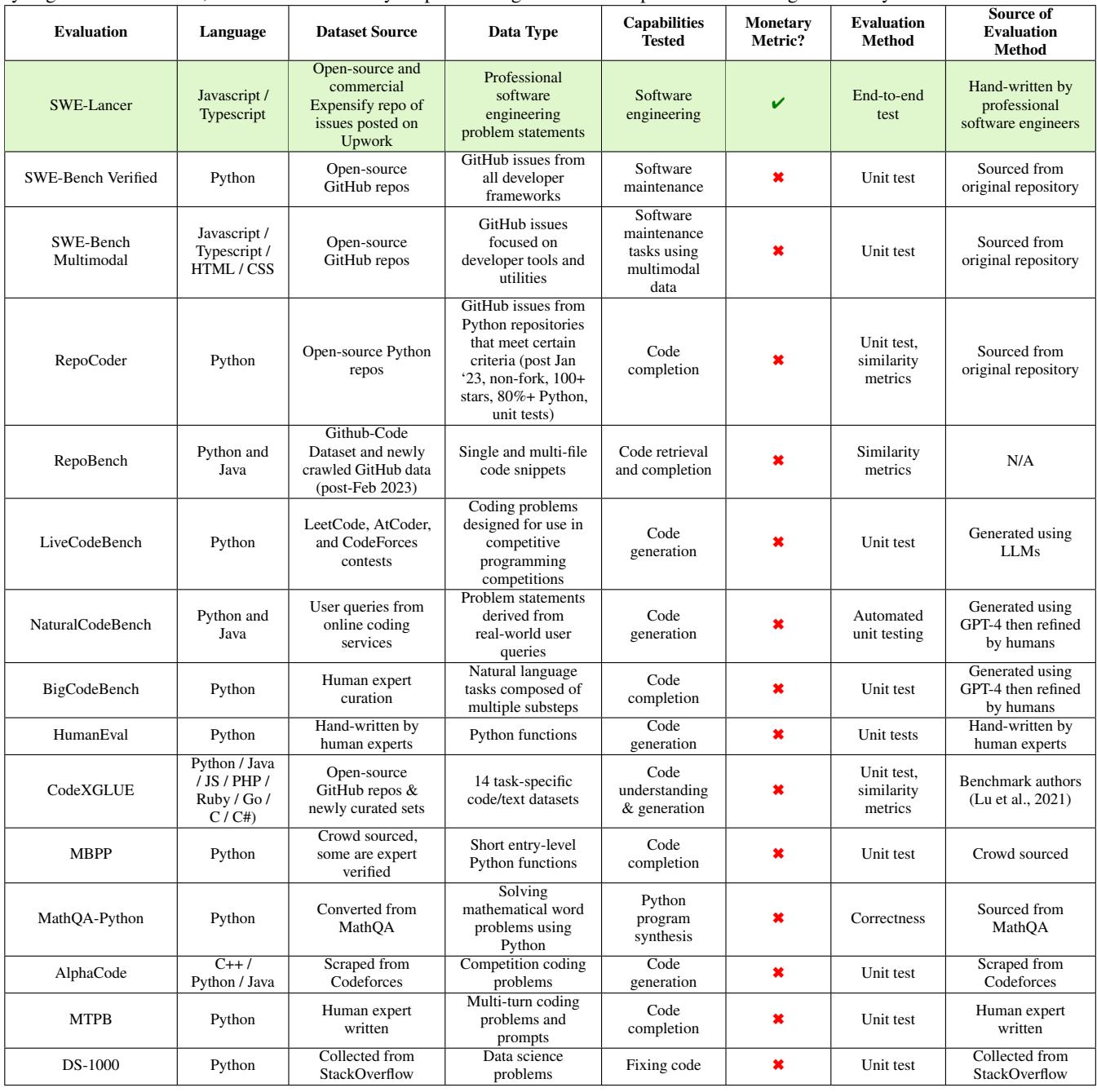
如 表 5 详述,大多数基准测试 (如 SWE-Bench Verified 或 RepoBench) 依赖于源自代码仓库的单元测试。SWE-Lancer 的独特之处在于使用工程师手工制作的 端到端测试 , 并将性能映射到 货币指标 。 它也是唯一一个包含专门的“管理”评估轨道的主要基准测试。
实验设置
研究人员评估了三个前沿模型:
- GPT-4o (OpenAI)
- o1 (OpenAI,以前称为 Strawberry/Q*,使用高推理算力)
- Claude 3.5 Sonnet (Anthropic)
为了确保公平和真实:
- 环境: 代理在一个安全的 Docker 容器中运行,无法访问互联网 (防止它们在线查找解决方案) 。
- 工具: 模型被赋予了一个基本的脚手架,允许它们浏览代码库、搜索文件和运行终端命令。至关重要的是,它们获得了一个 “用户工具” ——一个在浏览器中运行应用程序的模拟器,以便模型在提交之前验证自己的修复。
- 数据分割: 研究人员发布了一个公共的“钻石集 (Diamond set)” (价值 50 万美元) ,但保留了一个私有的保留集 (holdout set),以防止未来的模型在测试数据上进行训练。
结果: 收益如何
那么,当今的 AI 到底能赚多少钱?
简短的回答是: 数额可观,但远未达到 100 万美元的全部潜力。
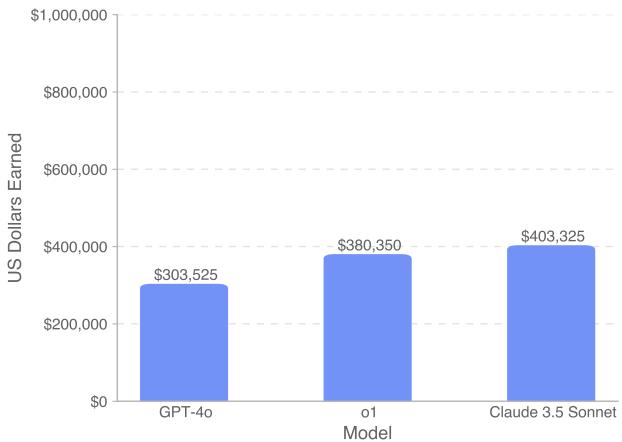
图 5 显示了完整数据集的总收入。 Claude 3.5 Sonnet 成为收入最高的模型,获得了超过 400,000 美元 。 OpenAI 的推理模型 o1 紧随其后,约为 380,000 美元,而 GPT-4o 则落后,约为 300,000 美元。
虽然赚取 40 万美元听起来很诱人,但请记住,总奖金池是 1,000,000 美元。这意味着即使是最好的模型也错失了近 60% 的资金,表明 AI 尚未准备好完全自动化自由职业软件工程。
细分: 编码 vs. 管理
总数据掩盖了模型在 编写 代码能力与 管理 代码能力之间的巨大差异。
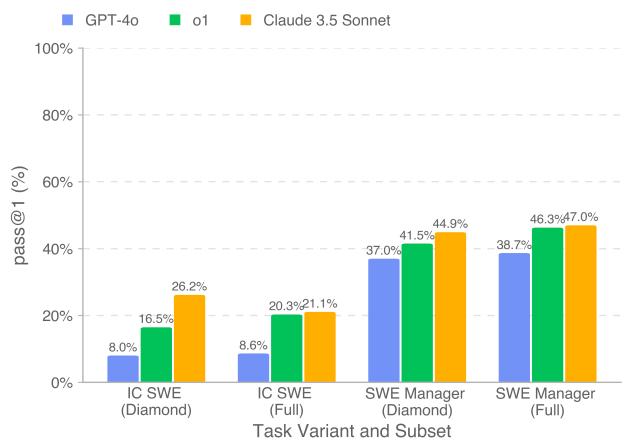
图 6 提供了成功率 (Pass@1) 的细分视图:
- IC SWE 任务 (编码) : 这对模型来说仍然非常困难。表现最好的模型 Claude 3.5 Sonnet 仅解决了 Diamond 集中 26.2% 的任务。GPT-4o 表现非常吃力,仅解决了 8%。
- SWE 经理任务 (决策) : 模型在这里表现得更好。Claude 3.5 Sonnet 达到了近 45% 的准确率,o1 紧随其后。
这表明,当前的前沿模型在评估技术提案方面出奇地好——也许比它们自己实现细节要好。它们可以识别正确的路径,但在尝试行走时会绊倒。
“推理”和多次尝试的价值
研究人员还调查了哪些因素可以让模型赚得更多。确定了两个关键杠杆: 尝试次数 和 推理算力 。
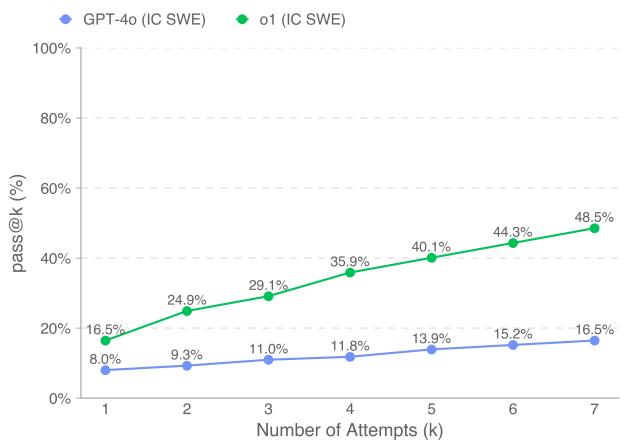
图 7 (由于编号原因,在图像组中标记为图 6) 展示了给予模型多次尝试机会 (pass@k) 的影响。
- o1 (绿线) : 第一次尝试的成功率为 16.5%,但如果允许 7 次尝试,成功率将飙升至 48.5% 。
- GPT-4o (蓝线) : 改进曲线要平缓得多。
这凸显了像 o1 这样模型中“推理”能力的价值。当 o1 失败时,它往往是因为不同的、可解决的原因失败,重试可以修复这些问题。而 GPT-4o 经常陷入相同的故障模式。
同样,增加 测试时计算 (test-time compute) (模型在回答前“思考”的时间) 显示出与收入的明显相关性,特别是对于更昂贵、更复杂的任务。
经济论点: AI 作为成本节约者
对于该行业来说,最实际的结论可能不是 AI 是否能 取代 工程师,而是它是否能让工程师 更便宜。
研究人员模拟了一个混合工作流: 如果我们让 AI 先尝试解决任务,只有在 AI 失败时才将其移交给人类自由职业者,会怎么样?
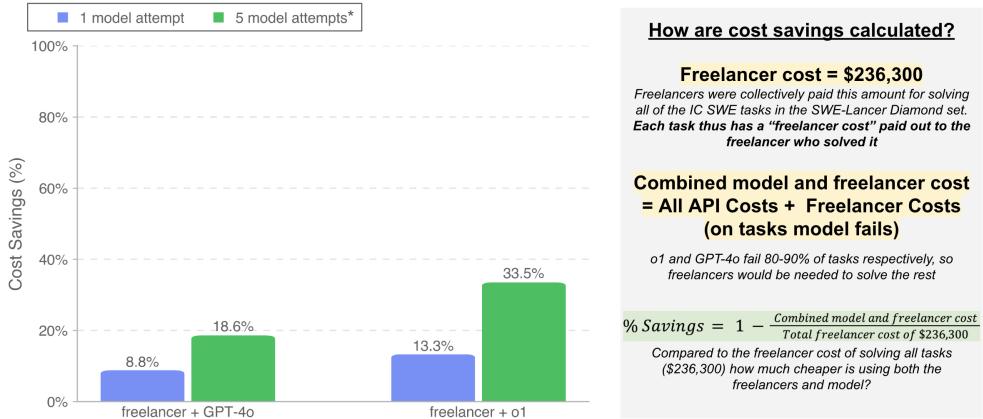
图 10 展示了这种成本效益分析。
- 场景: 模型尝试完成任务。如果成功,成本仅仅是 API 费用 (几美分或几美元) 。如果失败,你需要支付全额的自由职业者费用。
- 结果: 通过允许 o1 模型在回退给人类之前进行 5 次尝试,公司可以在 Diamond 数据集上降低 33.5% 的总成本。
这是一个巨大的潜在效率收益。即使成功率低于 30%,与人工相比,AI 推理的低成本意味着自动尝试在经济上是可行的“彩票”。
挑战与未来工作
尽管数字看起来很有希望,但论文也强调了重大局限性:
- 根本原因分析: 模型擅长找到错误 哪里 (定位) ,但往往无法理解 为什么 会在多个文件中发生这种情况。它们倾向于应用“创可贴式的修复/权宜之计”,而不是系统性的解决方案。
- 工具使用: 虽然强大的模型使用提供的用户工具 (浏览器模拟器) 进行调试,但在较弱的模型往往会放弃使用它或无法有效地解析输出。
- 数据污染风险: 由于这些任务来自公共 GitHub 仓库,始终存在模型在训练期间见过这些代码的风险。研究人员通过私有保留集来减轻这种风险,但这仍然是该领域的一个挑战。
结论
SWE-Lancer 代表了 AI 评估的一个成熟度里程碑。通过从抽象的分数转向现实世界的美元,它为我们的现状提供了更清晰的图景。
结论是什么? AI 尚未准备好成为高级软件工程师。 仅解决约 26% 的编码任务表明,人类的专业知识对于执行仍然至关重要。然而,模型在“经理”任务中的出色表现以及在混合工作流中节省 33% 成本的潜力表明,AI 已经准备好成为一名高效的 初级工程师 或 技术助理 。
随着像 Claude 3.5 Sonnet 和 OpenAI 的 o1 这样的模型继续提高其推理和工具使用能力,我们可以预期“错失的资金”比例将会缩小。目前,自由职业市场是安全的——但驾驭它的工具每天都在变得更加锋利。