](https://deep-paper.org/en/paper/14278_policy_labeled_preferenc-1750/images/cover.png)
引言
基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) 无疑改变了人工智能的格局。它是 GPT-4 和 Llama 2 等现代大型语言模型 (LLM) 背后的引擎,使它们能够与人类意图保持一致。RLHF 的标准配方通常包括训练一个奖励模型来模仿人类偏好,然后优化一个策略以最大化该奖励。
然而,以直接偏好优化 (Direct Preference Optimization, DPO) 等方法为首的一波新研究简化了这一过程。DPO 完全跳过了显式的奖励建模步骤,直接从偏好数据中优化策略。它优雅、稳定且有效——至少在数据表现良好的情况下是这样。
但是,当我们走出文本生成的舒适区,进入机器人技术或复杂控制系统的混乱世界时会发生什么呢?在这些领域,环境是随机的 (stochastic) ,数据通常来自熟练和不熟练操作员的混合。
这就触及了当前方法中一个隐藏的陷阱: 似然不匹配 (Likelihood Mismatch) 。 标准的 DPO 类算法通常隐含地假设数据集中的轨迹是由最优 (或接近最优) 策略生成的。当一个糟糕的策略因为环境噪声而“走运”时,现有的方法可能会将其误解为技能,从而导致次优的学习效果。
在这篇文章中,我们将深入探讨一篇名为 “Policy-labeled Preference Learning: Is Preference Enough for RLHF?” (带策略标签的偏好学习: RLHF 仅有偏好就够了吗?) 的论文。研究人员提出了一种名为 带策略标签的偏好学习 (Policy-labeled Preference Learning, PPL) 的新颖框架。PPL 认为仅有偏好标签是不够的;为了真正从离线数据中学习,我们还必须考虑是谁生成了该数据——即行为策略 (behavior policy) 。
背景: 向直接偏好法的转变
要理解 PPL,我们需要先看看我们从何而来。
传统 RLHF 与 DPO
在传统的 RLHF (如 PEBBLE) 中,过程分为两个阶段:
- 奖励学习: 收集轨迹对 \((\zeta^+, \zeta^-)\),其中人类更偏好 \(\zeta^+\)。训练一个神经网络来预测标量奖励 \(r(s,a)\) 以解释这些偏好。
- 策略优化: 使用标准的 RL 算法 (如 PPO 或 SAC) 来最大化这个学习到的奖励。
直接偏好优化 (DPO) 及其变体 (如 CPL) 意识到,对于每一个奖励函数,都存在一个对应的最优策略。利用这种数学上的对偶性,它们制定了一个损失函数,直接从偏好中优化策略,消除了对独立奖励模型的需求。
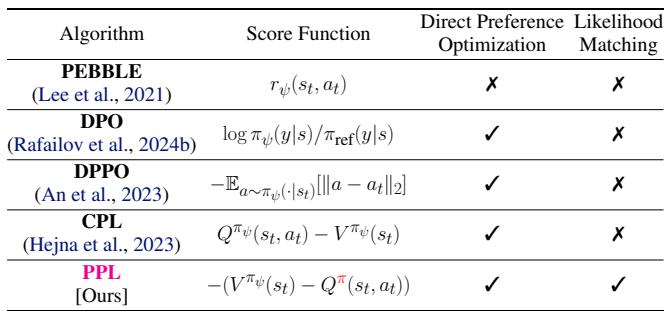
下表 1 总结了不同算法如何处理这个问题。请注意,PPL 的独特之处在于它结合了 似然匹配 (Likelihood Matching) , 我们稍后将探讨这一概念。
“回报”的问题
在强化学习中,我们通常关心累积回报 (奖励之和) 。然而,在稀疏奖励环境中 (比如机器人试图抓取物体) ,回报在很长一段时间内通常是缺乏信息的。
作者认为,在从偏好中学习时, 遗憾值 (Regret) 是比原始奖励好得多的指标。遗憾值衡量的是最优动作的价值与实际采取动作的价值之间的差异。
如下面的图 1 所示,奖励 (左) 可能非常稀疏——除非你成功,否则一无所获。然而,遗憾值 (右) 在每个时间步都提供密集的信号,确切地告诉你某个特定动作有多么次优。
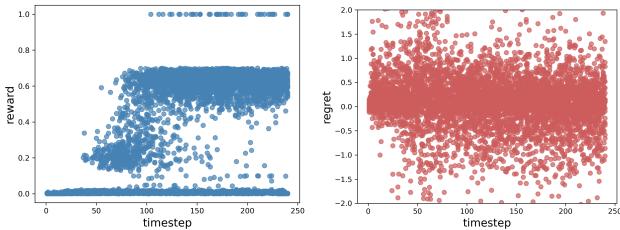
虽然对比偏好学习 (CPL) 试图使用最优优势 (遗憾值的近亲) ,但它遗漏了拼图中至关重要的一块: 行为策略。
核心问题: 似然不匹配
这篇论文的核心论点是: 忽略数据来源会导致学习错误。
在许多离线 RL 数据集中,数据是异构的 (heterogeneous) 。 它来自不同的来源: 随机探索者、脚本机器人、新手人类和专家人类。
- 环境随机性: 有时,一个糟糕的策略走了一步臭棋,但环境随机跳转到了一个好的状态。
- 策略次优性: 有时,一个好的策略走了一步好棋,但环境跳转到了一个坏的状态。
如果你的算法假设所有数据都来自“最优”分布 (正如 DPO 类方法通常隐含所做的那样) ,它就无法区分“运气好”和“技术好”。
可视化不匹配
考虑图 3 中的图表。
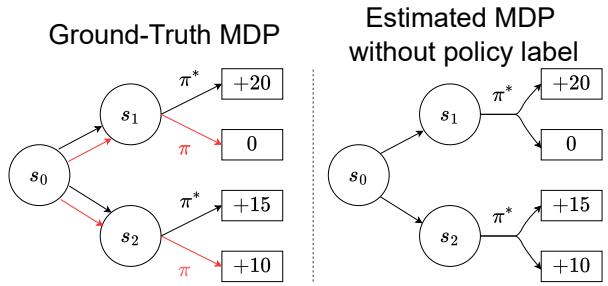
在左侧( 基准真实 MDP ),我们看到了现实:
- 策略 \(\pi^*\) (最优) 采取了一个导致 \(s_1\) 的动作,获得高奖励 (+20) 。
- 策略 \(\pi\) (次优) 采取了一个导致 \(s_2\) 的动作,获得较低奖励 (+10) 。
显然,\(s_1\) 更受偏好。
然而,看右侧( 无策略标签的估计 MDP )。如果我们不知道哪条路径是由哪个策略生成的,仅仅看结果,学习算法可能会被转移概率搞混。如果数据集中包含许多次优策略 \(\pi\) 意外到达好状态的轨迹,或者最优策略 \(\pi^*\) 运气不好的轨迹,算法可能会错误地推断导致 \(s_2\) 的动作实际上是更好的选择。
这就是 似然不匹配 (Likelihood Mismatch) 。 算法将结果归因于世界的动态变化,而不是行动策略的质量。
解决方案: 带策略标签的偏好学习 (PPL)
研究人员提出 PPL 来解决这个问题。核心思想简单而深刻: 用生成轨迹的策略来标记该轨迹。
通过显式地建模行为策略 (\(\pi\)),PPL 可以在数学上将环境噪声与策略技能分离开来。
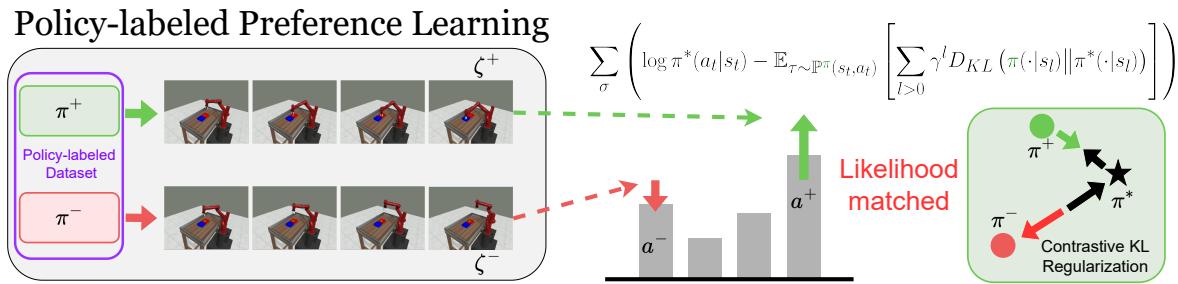
如图 2 所示,PPL 使用了一个对比学习框架。它不仅仅问“哪条路径更好?”,而是问“鉴于策略 A 产生了路径 A,策略 B 产生了路径 B,哪种策略偏差解释了这种偏好?”
理论基础: 定义遗憾值
作者将他们的方法建立在 最大熵 (MaxEnt) 框架之上。在 MaxEnt RL 中,最优策略不仅最大化奖励,还最大化策略的熵 (随机性) ,这鼓励了探索和鲁棒性。
该框架下的最优策略 \(\pi^*\) 定义为:
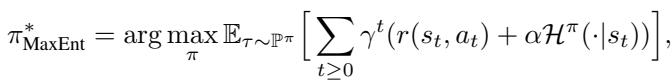
论文引入了 负遗憾值 (Negative Regret) 的严格定义。遗憾值本质上是你期望在最优策略下获得的价值 (\(V\)) 与你实际采取动作的 Q 值 (\(Q\)) 之间的差值。
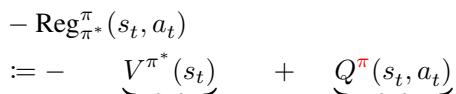
这是关键的理论贡献。作者推导出了 策略偏差定理 (Policy Deviation Theorem) (定理 3.4) 。他们证明了这个差值 (遗憾值) 与行为策略和最优策略之间的 Kullback-Leibler (KL) 散度直接相关。
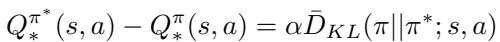
其中 \(\bar{D}_{KL}\) 是 序列前向 KL 散度 (sequential forward KL divergence) :
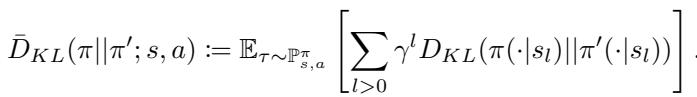
这用通俗的话怎么说? 这意味着“遗憾值”不仅仅是一个“错失良机”的模糊概念。在数学上,它等同于随时间推移你的策略与最优策略之间的距离 (KL 散度) 。如果你最小化遗憾值,你就是在最小化与最优策略的距离。
PPL 目标函数
利用这个定理,作者将遗憾值分解为两部分:
- 似然 (Likelihood) : 在最优策略下,这个动作的可能性有多大?
- 序列 KL (Sequential KL) : 轨迹在未来与最优路径的偏差有多大?
这引出了 PPL 损失函数。PPL 不仅仅是提高受偏好轨迹的概率,而是优化这个目标:
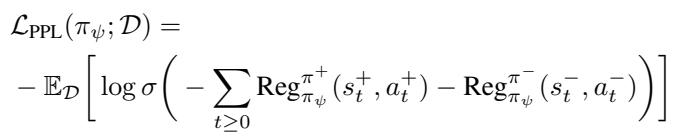
具体来说,观察损失函数内部的评分函数,我们看到它在即时动作似然与未来偏差之间取得了平衡:
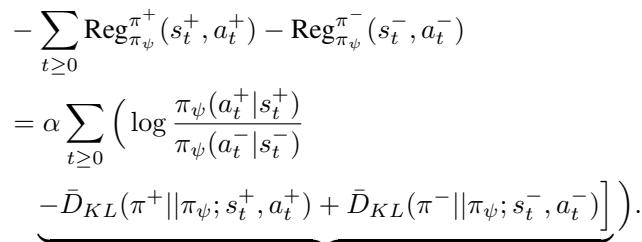
该方程告诉模型要:
- 增加受偏好片段 (\(\zeta^+\)) 中动作的似然。
- 减少非受偏好片段 (\(\zeta^-\)) 中动作的似然。
- 关键点: 最小化赢家的未来偏差 (KL),并最大化输家的未来偏差。
对比 KL 正则化
包含 \(\bar{D}_{KL}\) 的项就是作者所说的 对比 KL 正则化 (Contrastive KL Regularization) 。
在标准的 DPO 中,你通常只看数据集中特定的状态-动作对。PPL 更进一步,向未来“展开 (rolling out) ” (模拟) 几步 (或使用记录的未来步骤) ,看看策略将导向何方。
实际实现中,用前瞻视界 \(L\) 来近似这个无限和:
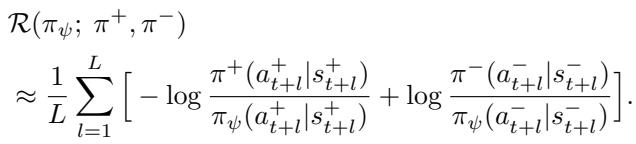
这种正则化确保了学习到的策略在序列上与受偏好的轨迹保持一致,而不仅仅是在瞬间保持一致。它迫使模型理解动作的长期后果,从而解决似然不匹配问题。
实验与结果
作者在 MetaWorld 基准测试上测试了 PPL,这是一个机器人操作任务的标准测试平台。
他们专注于离线学习,即智能体必须从固定数据集中学习,而不与世界交互。他们创建了两种类型的数据集:
- 同构 (Homogeneous) : 数据主要从一种类型的策略收集。
- 异构 (Heterogeneous) : 策略的混乱混合 (例如,有些成功率为 20%,有些为 50%) 。
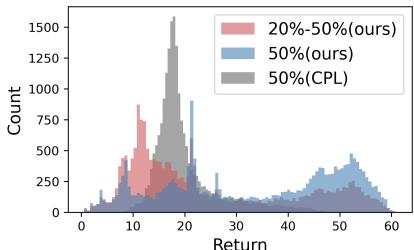
异构数据集尤其具有挑战性,因为它模仿了现实世界中数据混乱的情况。图 4 显示了这些数据集中回报的分布。请注意,与之前工作中使用的标准数据集 (灰色) 相比,异构数据 (红色) 具有奇怪的多峰分布。
主要结果
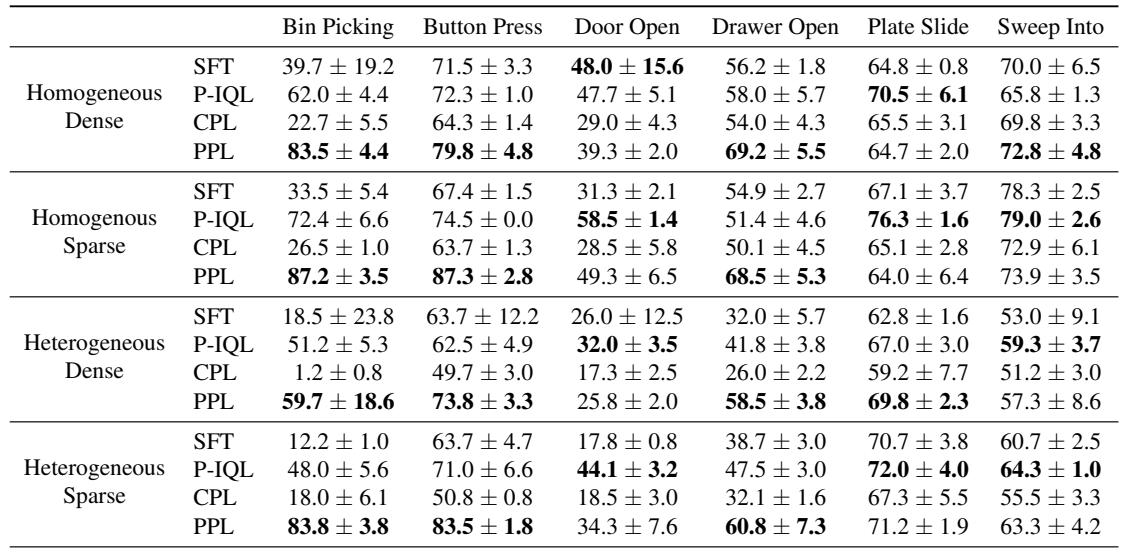
表 2 总结的结果相当惊人。PPL 始终优于基线,尤其是 对比偏好学习 (CPL) 和 基于偏好的 IQL (P-IQL) 。
结果的关键要点:
- 在稀疏/异构设置中的主导地位: 看“Heterogeneous” (异构) 行。在像 Bin Picking (捡垃圾箱) 和 Door Open (开门) 这样的任务中,标准的 CPL 几乎完全失败 (成功率为 1.2% 和 17.3%) 。PPL 保持了高性能 (59.7% 和 25.8%) 。
- 效率: P-IQL (一种基于奖励的方法) 表现不错,但需要训练单独的奖励模型和评论家 (critic) ,使用的参数量几乎是 PPL 的 10 倍。PPL 以一小部分的计算成本实现了类似或更好的结果。
标签真的重要吗?
你可能会想: “这是数学的原因,还是仅仅因为你告诉了模型是哪个策略在行动?”
为了回答这个问题,作者进行了一项消融研究,比较了 PPL 与 PPL-deterministic (PPL-确定性) 。 在确定性版本中,他们假设一个通用的策略,而不是使用真实的行为策略标签。
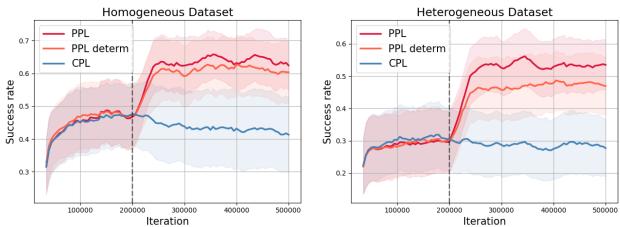
如图 5 所示,知道策略 (红线) 比猜测策略 (橙线) 具有明显的优势,特别是在像 Bin Picking 这样的复杂任务中。这从经验上证明了“似然不匹配”是一个真实存在的问题,而显式的策略标签是解决方案。
在线学习
最后,作者询问 PPL 是否适用于 在线 (Online) 设置,即智能体与环境交互并动态生成新数据。
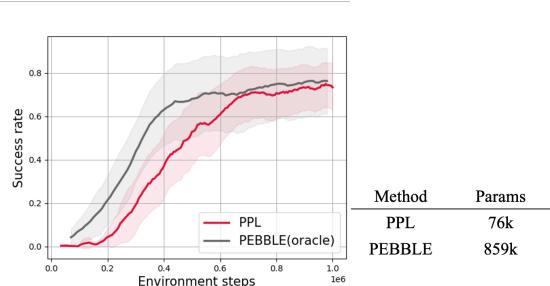
图 6 显示 PPL (红色) 与 PEBBLE (灰色) 的表现相当,后者是一个使用无监督预训练的强大基线。PPL 是 从头开始 实现这一点的,进一步突显了其数据效率。
结论与启示
论文 “Policy-labeled Preference Learning” 强调了我们处理 RLHF 方式中一个微妙但关键的缺陷: 假设偏好意味着最优性。通过忽略数据来源,我们要么会混淆环境的运气与智能体的技能。
PPL 通过以下方式提供了一个强大的解决方案:
- 使用遗憾值: 比稀疏奖励更密集、信息量更大的信号。
- 策略标签: 显式地考虑行为策略以修正似然不匹配。
- 对比 KL 正则化: 确保学习到的策略在长期内与受偏好的轨迹保持一致。
对于 RL 的学生和研究人员来说,这项工作强调了 数据生成过程 的重要性。在大数据时代,很容易将数据集视为状态-动作对的静态集合。PPL 提醒我们,每个数据点都讲述了一个特定策略与特定环境交互的故事,理解这个故事是学习最优行为的关键。
随着我们迈向在现实世界中部署机器人,处理混乱、异构的人类数据将不可避免。像 PPL 这样的框架为智能体铺平了道路,使它们能够筛选这些噪声,不仅学习我们偏好什么,而且学习 如何 可靠地实现它。