](https://deep-paper.org/en/paper/1439_what_limits_virtual_agent-1798/images/cover.png)
引言
我们正见证着多模态大语言模型 (MLLM) 的黄金时代。从 GPT-4o 到 Claude 3.5,这些模型不再仅仅是文本处理器;它们正在进化为“虚拟智能体 (Virtual Agents) ”,能够看懂屏幕、点击按钮并浏览网页。我们的梦想是拥有一个能够处理复杂工作流的数字助手——比如“从邮件下载销售报告,在 Excel 中可视化数据,然后通过 Slack 将图表发送给经理。”
然而,炒作与现实之间存在着差距。虽然智能体在简单、线性的任务上表现良好,但当面对现实世界计算机工作中混乱、非线性的本质时,它们往往会崩溃。
部分问题在于我们测试它们的方式。现有的基准测试通常依赖于僵化、线性的路径,或者基于结果的指标,这些都无法告诉我们智能体为什么会失败。由于依赖昂贵的人工标注,这些测试也很难扩展。
OmniBench 应运而生。在最近的一篇论文中,研究人员介绍了一个可扩展的、多维度的基准测试,旨在利用图结构任务严格测试虚拟智能体。通过摒弃线性指令并拥抱有向无环图 (DAG) 的复杂性,OmniBench 揭示了当前顶尖模型的脆弱性,并为构建真正稳健的数字智能体提供了路线图。
当前基准测试的问题
要理解为什么需要 OmniBench,我们首先需要看看当前评估方法的局限性。大多数现有的虚拟智能体基准测试分为两类:
- 基于轨迹 (Trajectory-based) : 这些测试将智能体的点击路径与人类演示进行逐步比较。如果智能体采取了人类没有使用的有效捷径,它就会被判定失败。
- 基于结果 (Result-based) : 这些测试检查环境的最终状态 (例如,“文件在文件夹里吗?”) 。虽然这种方法更好,但它忽略了过程中的细微差别。如果一个智能体完成了 90% 的复杂工作流,但在最后一次点击时失败,它得到的分数就是零。
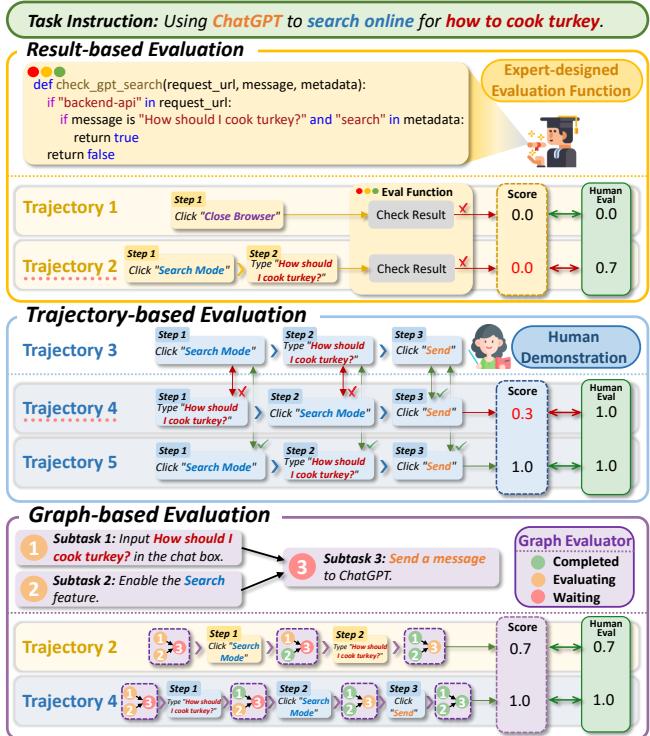
如图 4 所示,当前的策略存在缺陷。基于轨迹的评估会惩罚创造性的解决方案 (轨迹 4 虽然成功了但被判定失败) ,而基于结果的评估则忽略了进度 (轨迹 2 比轨迹 1 更好,但两者得分都为 0) 。
此外,现实世界的任务并不总是线性的链条 (A \(\rightarrow\) B \(\rightarrow\) C) ,它们通常是图结构。你可能需要打开一个应用程序 (A) 并下载一个文件 (B) ,同时检查一封电子邮件 (C) ,然后再将它们合并成一份报告 (D) 。如果一个智能体只理解线性序列,它就无法有效地进行规划或确定优先级。
OmniBench: 一种新的架构
OmniBench 通过将任务建模为图来解决这些问题。具体来说,它使用有向无环图 (DAG) ,其中节点代表子任务,边代表依赖关系。这允许并行执行分支和复杂的依赖关系管理。
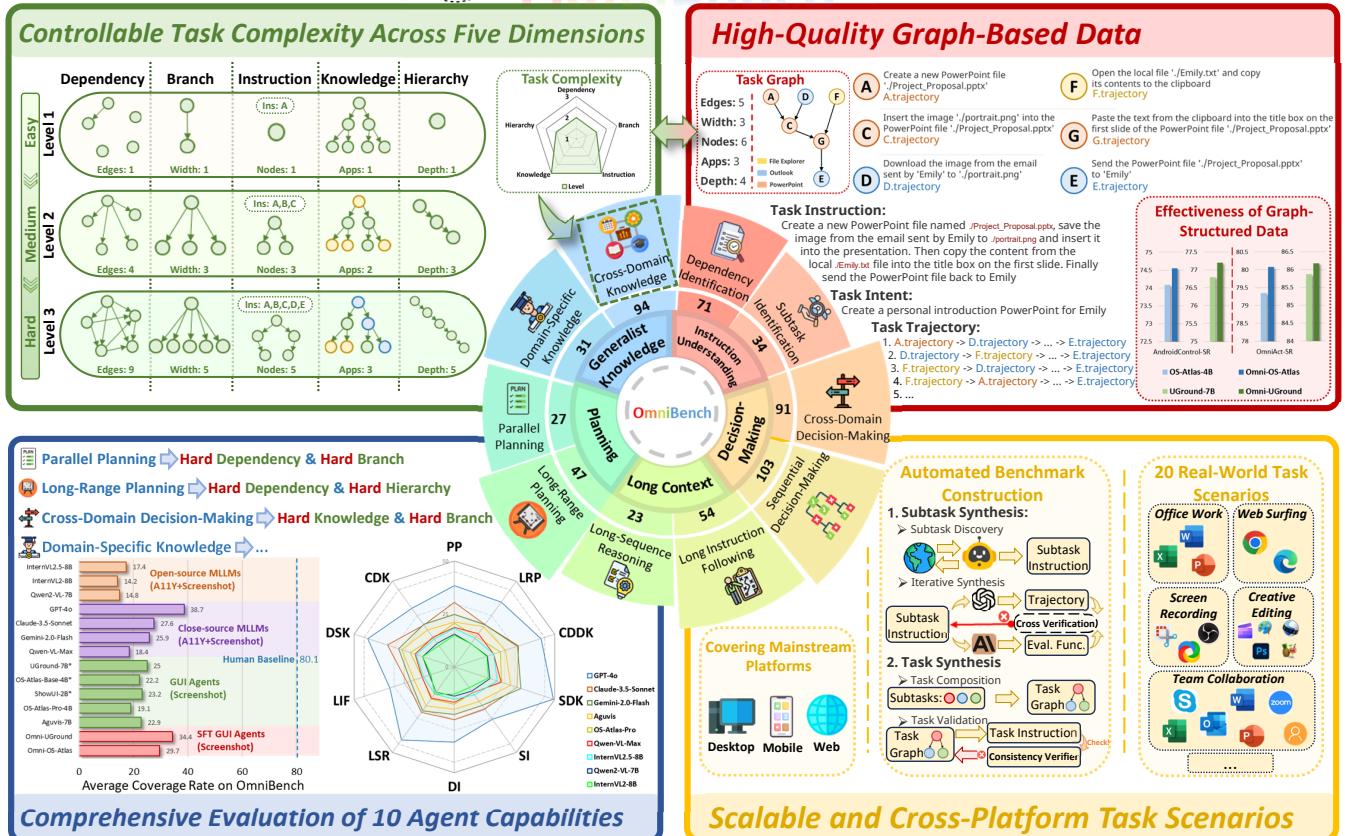
如图 1 所示,OmniBench 围绕任务复杂性的五个特定维度进行设计:
- 依赖复杂度 (Dependency Complexity) : 图中边的数量 (子任务之间有多大的依赖性?) 。
- 指令复杂度 (Instruction Complexity) : 节点的数量 (指令中有多少个步骤?) 。
- 知识复杂度 (Knowledge Complexity) : 所需应用程序的多样性 (例如,在 Photoshop、Outlook 和 Excel 之间切换) 。
- 层级复杂度 (Hierarchy Complexity) : 图的深度 (存在多少个先决条件层?) 。
- 分支复杂度 (Branch Complexity) : 图的宽度 (有多少任务可以并行完成?) 。
通过调整这些维度,研究人员可以生成从“简单”到“困难”的任务,以测试特定的智能体能力。
可视化图任务
为了更具体地说明这一点,让我们看看基准测试中的“任务图”实际上是什么样子的。
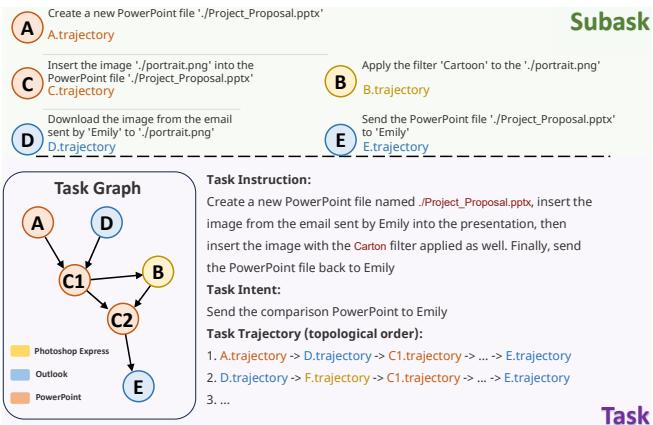
在图 12 中,用户想要处理一个演示文稿。智能体必须:
- 创建一个 PowerPoint (节点 A) 。
- 同时从 Outlook 下载附件 (节点 B) 。
- 插入图片 (节点 D) 并应用滤镜 (节点 C1) 。
- 最后,通过电子邮件将结果发回 (节点 E) 。
一个线性智能体可能会尝试在下载附件之前发送电子邮件。一个具备图意识的智能体能理解依赖关系: 节点 B 必须在节点 C2 之前发生,但节点 A 可以独立于节点 B 发生。
构建方法: 自底向上的流水线
基准测试的最大挑战之一是规模。手工创建 36,000 个像上面那样复杂的任务需要数年时间。OmniBench 通过自动化的自底向上合成流水线解决了这个问题。

如图 2 详述,该过程就像一条装配线:
1. 子任务发现 (Subtask Discovery)
系统让一个高级 MLLM 探索包含 49 个不同应用程序 (如 Photoshop Express、VS Code、Slack 等) 的环境。它识别“原子”动作或子任务——简单的工作单元,如“裁剪图像”或“发送电子邮件”。它定义了每个子任务的输入 (所需资源) 和输出 (创建的资源) 。
2. 迭代合成与验证 (Iterative Synthesis & Verification)
仅仅生成任务是不够的;它们必须是可验证的。系统使用代码大模型 (Code LLMs) 为每个子任务编写 Python 评估脚本。然后它运行一个“交叉验证”循环: 智能体尝试解决子任务,代码尝试对其评分。如果它们不一致或失败,系统会改进指令或代码,直到它们对齐。
3. 任务组合 (“乐高”阶段)
一旦有了一个经过验证的子任务池,系统就会将它们组合起来。与之前可能随机链接动作的方法不同,OmniBench 使用意图提取 (Intent Extraction) 。 它寻找具有共同逻辑目标的子任务 (例如,“准备会议”) ,并根据资源依赖关系将它们连接起来 (A 的输出变为 B 的输入) 。
这确保了生成的任务不是无意义的 (如“打开计算器然后关闭浏览器”) ,而是具有可控复杂度的有意义的工作流。
OmniEval: 全新的评分标准
由于任务是图结构的,将其简单地评分为“通过/失败”是不够的。研究人员引入了 OmniEval , 这是一个包含两个新颖指标的框架:
- 覆盖率 (Coverage Rate, CR) : 这衡量进度。它根据子任务在图中的深度对其进行加权。完成一个“根”任务 (如打开应用程序) 的价值低于完成一个“叶”任务 (如发送最终电子邮件) ,因为后者需要前面的所有步骤都正确无误。
- 逻辑一致性 (Logical Consistency, LC) : 这衡量智能体是如何思考的。为了节省时间,人类通常会在切换到另一个应用程序之前完成一个应用程序中的所有任务。LC 会惩罚那些没有逻辑理由就在应用程序之间不规律切换的智能体。
实验与结果
研究人员评估了 12 个虚拟智能体,包括像 GPT-4o 和 Claude-3.5-Sonnet 这样的专有巨头,以及像 Qwen2-VL 这样的开源模型。结果发人深省。
1. “图”差距 (The “Graph Gap”)
最引人注目的发现是,现代智能体在处理非线性任务时是多么吃力。
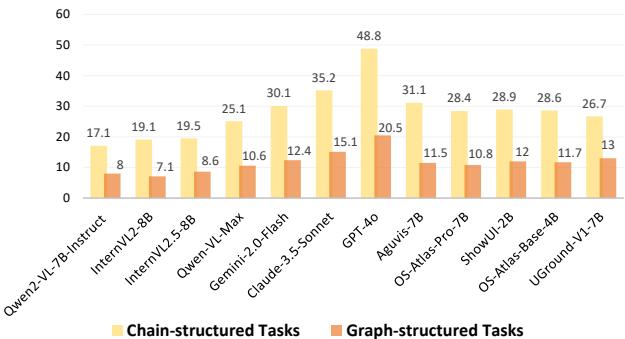
图 7 显示了巨大的性能下降。看看 GPT-4o : 它在链式结构 (线性) 任务上达到了近 49% 的成功率,但在图结构任务上暴跌至 20.5% 。
这表明,虽然大语言模型 (LLM) 擅长遵循要点列表,但它们难以维护依赖关系的心理模型。它们将图视为线,经常在满足先决条件之前就尝试执行步骤。
2. 具体能力缺陷
该基准测试将性能细分为 10 项能力。有两个领域成为了主要的瓶颈: 子任务识别 (Subtask Identification, SI) 和 长指令遵循 (Long Instruction Following, LIF) 。
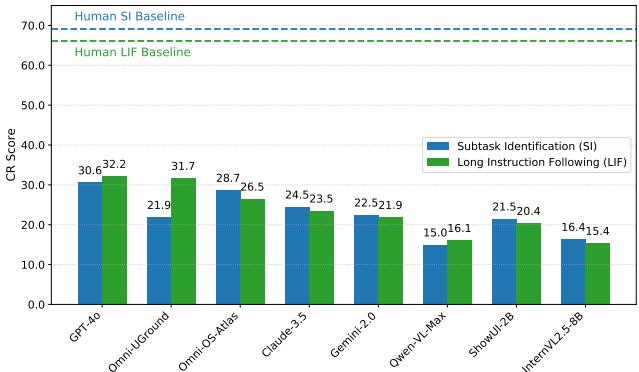
如图 6 所示,即使是最好的模型 (GPT-4o 和微调后的 Omni-UGround) 也大大低于人类基准。人类在子任务识别上的得分约为 70%;GPT-4o 仅为 30.6%。这表明智能体难以将长而复杂的提示分解为可执行的原子步骤。
3. 它们为何失败?
研究人员分析了 100 个失败案例以诊断根本原因。
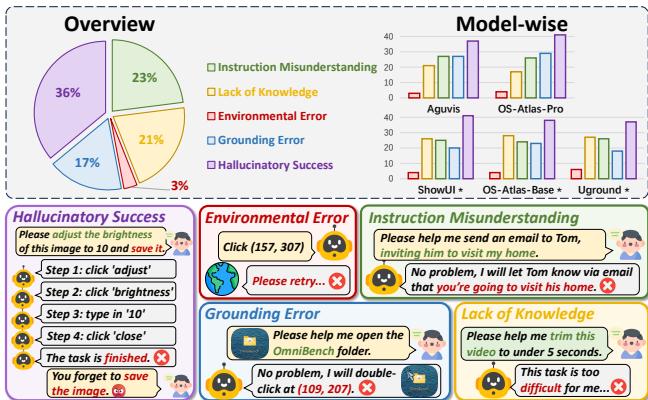
图 8 突出了错误分布。
- 幻觉式成功 (36%) : 智能体以为它完成了任务,但实际上没有。这是一个记忆和验证问题。
- 指令误解 (23%) : 智能体根本没有理解被要求做什么。
- 知识匮乏 (21%) : 智能体不知道如何使用特定的应用程序 (例如,如何在 Zotero 中创建参考文献列表) 。
4. 一线希望: 在图上训练是有效的
这篇论文不仅仅是批评;它还是一个解决方案。研究人员使用 OmniBench 数据集对开源模型 (具体为 OS-Atlas 和 UGround) 进行了微调。
结果如何?在图数据上微调后的智能体 (标记为 Omni-OS-Atlas 和 Omni-UGround )在 AndroidControl 和 OmniAct 等其他基准测试上的表现优于其基础版本。这证明了训练智能体尊重图依赖关系能使其成为更好的通才,即使是在线性任务上。它教会模型去推理先决条件和后果,而不仅仅是预测下一个 token。
结论与启示
OmniBench 代表了虚拟智能体成熟的重要一步。我们正在从“看,AI 能打开浏览器!”的阶段迈向“AI 能做我的工作吗?”的阶段。
研究结果表明,目前这一代智能体虽然令人印象深刻,但在非线性世界中仍是“线性思维者”。它们难以规划、确定优先级和管理依赖关系。然而,OmniBench 提出的方法——自动化创建复杂的、基于图的训练数据——提供了一条清晰的前进道路。通过教导智能体将世界视为依赖关系图而不是步骤列表,我们可以弥合聊天机器人与真正的数字助手之间的差距。
对于进入这一领域的学生和研究人员来说,结论很明确: 不要仅仅为了下一次点击而优化。 要为工作流优化。智能体的未来在于它们规划、验证和理解其正在执行的工作结构的能力。