](https://deep-paper.org/en/paper/1490_leveraging_diffusion_mode-1695/images/cover.png)
引言: 寻找不存在之物的悖论
想象一下,你是一名保安,任务是抓捕商店扒手。然而,你这辈子从未见过扒手,你只观察过诚实的顾客。这就是图级异常检测 (Graph-Level Anomaly Detection, GLAD) 面临的根本问题。
在生物化学 (检测有毒分子) 或社交网络分析 (识别机器人网络) 等领域,异常往往非常罕见、标注成本高昂,甚至完全未知。传统的人工智能在这里举步维艰,因为标准的监督学习既需要“好”数据的样本,也需要“坏”数据的样本。当你只有“好”数据 (正常图) 时,如何教会机器识别“坏”数据呢?
多年来,研究人员一直依赖基于重构的方法: 教会模型完美地绘制正常图;如果它难以绘制某个新图,那这个图一定是异常的。但这种方法很脆弱。有时,异常图实际上比复杂的正常图更容易重构,从而导致检测失败。
在最近的一篇论文中,研究人员提出了一种范式转变。与其仅仅盯着正常数据,如果我们利用生成式 AI 来自行构想我们自己的异常会怎样?
AGDiff (异常图扩散) 应运而生。该框架利用潜在扩散模型 (Latent Diffusion Models) ——这正是 Midjourney 等图像生成器背后的技术——其目的不是为了生成完美的图像,而是生成“伪异常”图。通过让检测器对抗这些自我生成的伪造数据进行训练,AGDiff 达到了最先进的性能,有效地通过对自己想象出来的对手进行演练,教会了自己如何识别异常。
现有方法的问题
在深入了解 AGDiff 之前,我们需要理解为什么现有方法遇到了瓶颈。
- 无监督方法 (重构) : 这些模型压缩图数据并尝试重建它。其假设是异常会有很高的重构误差。然而,这假设了异常在结构上非常复杂或截然不同。细微的异常往往会被遗漏。
- 半监督方法: 这些方法使用一小部分已标注的异常。虽然有效,但它们受限于所提供的特定异常。如果模型学会了识别“A 类”异常,它可能会完全错过新的“B 类”异常。
研究人员发现了一个巨大的机会: 数据增强 。 如果我们没有足够的异常,我们就应该制造它们。但这不能只是随机噪声;我们需要的是“困难”负样本——那些看起来几乎正常,但包含细微结构扰动的图。
AGDiff 框架
AGDiff 的核心创新在于利用潜在扩散模型作为伪异常生成器。
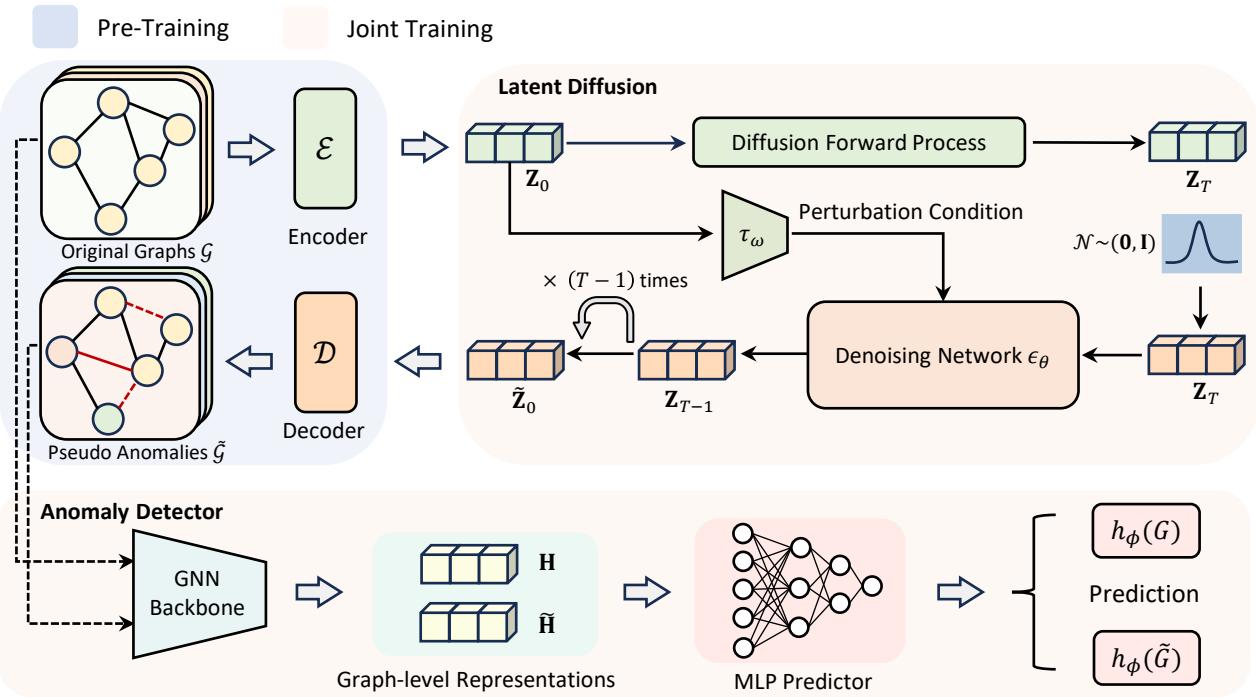
如图 1 所示,该架构分为三个明显的阶段。让我们逐一拆解。
第一阶段: 预训练 (学习常态)
在你能够有效地打破规则之前,你需要先理解规则。同样,AGDiff 首先需要理解什么样的图是“正常”的。
作者使用一个变分框架 (类似于 VAE) 将图数据 (邻接矩阵 \(\mathbf{A}\) 和节点特征 \(\mathbf{X}\)) 压缩到一个低维的潜在空间 (\(\mathbf{Z}\)) 中。
\[ \begin{array} { r l } & { \mathcal { L } _ { \mathrm { p r e t r a i n } } = \displaystyle \ell _ { \mathrm { r } } ^ { \mathrm { a t t r } } + \ell _ { \mathrm { r } } ^ { \mathrm { e d g e } } + \ell _ { \mathrm { K L } } } \\ & { \quad \quad \quad \quad = \displaystyle \sum _ { i = 1 } ^ { N } ( \| \mathbf { X } _ { i } - \hat { \mathbf { X } } _ { i } \| _ { F } ^ { 2 } + \mathcal { H } ( \mathbf { A } _ { i } , \hat { \mathbf { A } } _ { i } ) } \\ & { \quad \quad \quad \quad - \mathrm { K L } ( q ( \mathbf { Z } _ { i } | \mathbf { X } _ { i } , \mathbf { A } _ { i } ) | \mathcal { P } ( \mathbf { Z } ) ) ) , } \end{array} \]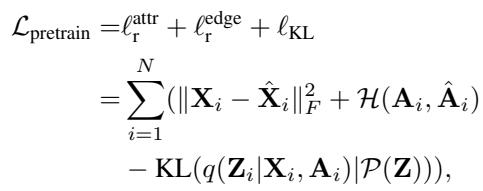
预训练损失 (如上图) 确保潜在嵌入 \(\mathbf{Z}\) 能够捕捉到正常图的关键结构和属性信息。这个潜在空间将成为扩散模型的游乐场。
第二阶段: 通过潜在扩散生成异常
这是 AGDiff 与标准扩散应用分道扬镳的地方。通常,训练扩散模型是为了去除噪声以生成高保真数据。AGDiff 则利用扩散来引入受控扰动 。
该过程发生在潜在空间 \(\mathbf{Z}\) 中,而不是图空间中。这在计算上更高效,并允许对图结构进行更平滑的操作。
前向过程
模型在 \(T\) 个时间步内逐步向正常图的潜在表示中添加高斯噪声。
\[ \begin{array} { r } { \mathbf { z } _ { t } = \sqrt { \bar { \alpha } _ { t } } \mathbf { z } _ { 0 } + \sqrt { 1 - \bar { \alpha } _ { t } } \epsilon _ { t } , \quad \epsilon _ { t } \sim \mathcal { N } ( \mathbf { 0 } , \mathbf { I } ) , } \end{array} \]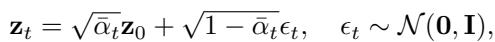
条件反向过程
这是秘诀所在。作者引入了一个扰动条件 (\(\mathbf{c}\))。他们并没有让模型完美地重建原始的正常图,而是基于一个扰动向量对去噪过程进行条件化。
条件向量 \(\mathbf{c}\) 源自原始潜在代码 \(\mathbf{z}_0\) 加上一些可学习的噪声 \(\eta\):
\[ \mathbf { c } = \tau _ { \omega } ( \mathbf { z } _ { 0 } ) = \sigma ( \mathbf { W } _ { \mathbf { c } } ( \mathbf { z } _ { 0 } + \boldsymbol { \eta } ) + \mathbf { b } _ { \mathbf { c } } ) , \]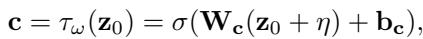
这个向量 \(\mathbf{c}\) 就像一个向导。当模型试图对数据进行“去噪”时,\(\mathbf{c}\) 会强迫它稍微偏离航线,阻止其完全回到正常的起点。反向扩散步骤如下所示:
\[ \mathbf { z } _ { t - 1 } = \frac { 1 } { \sqrt { \alpha } } \left( \mathbf { z } _ { t } - \frac { 1 - \alpha _ { t } } { \sqrt { 1 - \bar { \alpha } _ { t } } } \epsilon _ { \theta } ( \mathbf { z } _ { t } , t , \mathbf { c } ) \right) + \tilde { \beta } \mathbf { v } , \]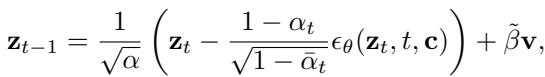
结果是什么?一个伪异常图 。 它保留了正常图的总体结构 (因为它起始于正常图) ,但包含了由条件扩散引入的细微扭曲。
第三阶段: 联合训练与检测
现在系统拥有一组正常图 (真实的) 和一组伪异常图 (生成的) 。
最后的组件是一个异常检测器——一个构建在图同构网络 (GIN) 之上的二分类器。该检测器被训练用来区分真实的正常图和生成的伪异常图。
\[ \mathcal { L } = \mathcal { L } _ { \mathrm { c l s } } + \lambda \mathcal { L } _ { \mathrm { d i f f } } \]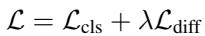
训练是一个联合过程 (如上图公式 14) 。模型同时优化扩散过程 (以制造逼真但独特的伪异常) 和分类器 (以区分它们) 。这产生了一个反馈循环:
- 生成器试图创造位于常态边界附近的“困难”异常。
- 检测器努力收紧该边界。
- 结果是一个紧密包裹正常数据的高辨别力决策边界。
为什么“生成”优于重构
你可能会问: 为什么对抗假数据训练比仅仅测量重构误差更好?
作者通过比较两种算法提供了令人信服的经验分析:
- \(\mathcal{A}_1\): 基于重构的检测。
- \(\mathcal{A}_2\): 使用生成的伪异常进行判别式检测 (AGDiff)。
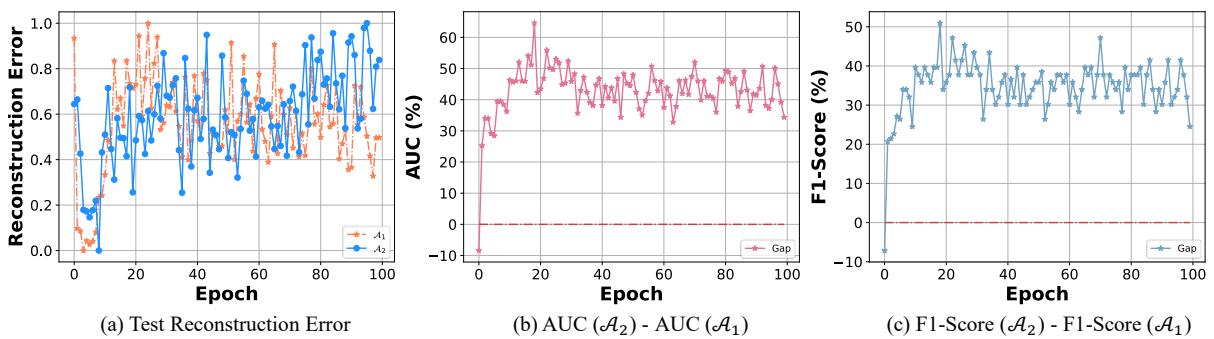
图 4 完美地阐释了这种动态。
- 图 (a): 随着训练的进行,\(\mathcal{A}_1\) (橙色) 降低了正常数据的重构误差。它在压缩方面变得非常出色。
- 图 (b): 然而,请看 AUC 的差距。随着 epoch 增加,\(\mathcal{A}_2\) (蓝线) 开始显著优于 \(\mathcal{A}_1\)。
虽然 \(\mathcal{A}_1\) 专注于压缩,但它往往会过度拟合,以至于它可以重构任何东西,甚至是异常。而 \(\mathcal{A}_2\) 通过明确地学习对伪异常说“不”,学会了对“正常”意味着什么的一个更稳健的定义。
实验结果
研究人员将 AGDiff 与包括图核 (如 Weisfeiler-Lehman) 和现代基于 GNN 的方法 (如 SIGNET、MUSE 和 iGAD) 在内的综合基准进行了测试。他们使用了两类数据集:
- 中等规模: 分子图 (MUTAG, COX2 等) 。
- 大规模不平衡: 异常罕见的现实世界数据集 (例如 SW-620,其中只有 5.95% 的图是活性化合物) 。
标准基准上的表现
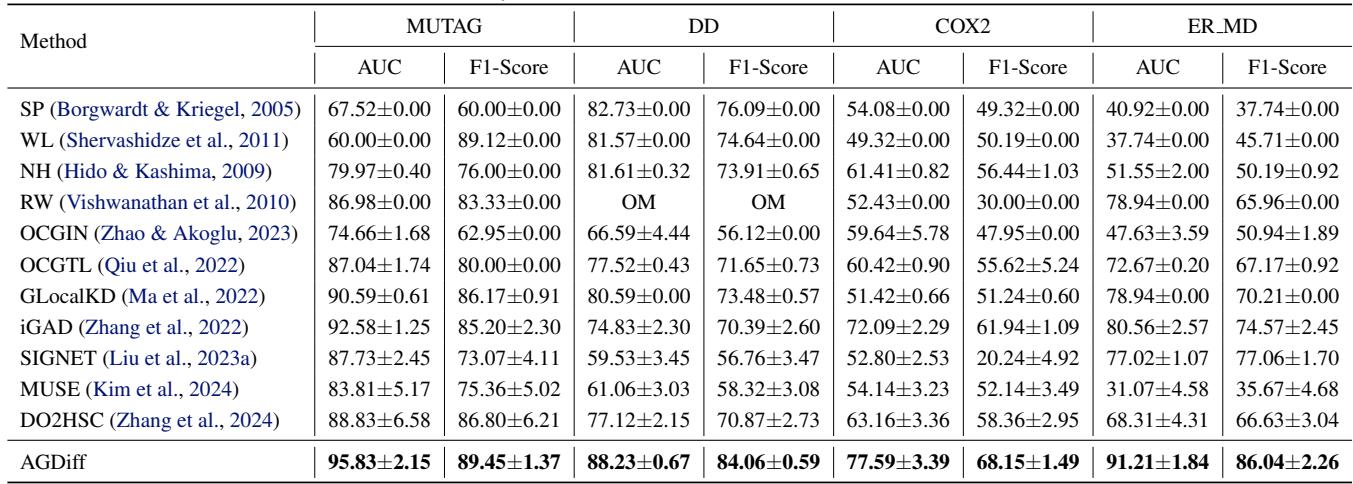
表 1 显示了其全面的优势。在 DD 数据集上,AGDiff 达到了 88.23% 的 AUC,以近 18 个百分点的优势击败了第二名 SIGNET (70.67%)。即使与半监督方法如 iGAD (实际上使用了真实的已标注异常) 相比,AGDiff (作为无监督方法) 也经常获胜或表现出很强的竞争力。
不平衡数据上的表现
异常检测器的真正考验是“大海捞针”般的场景。
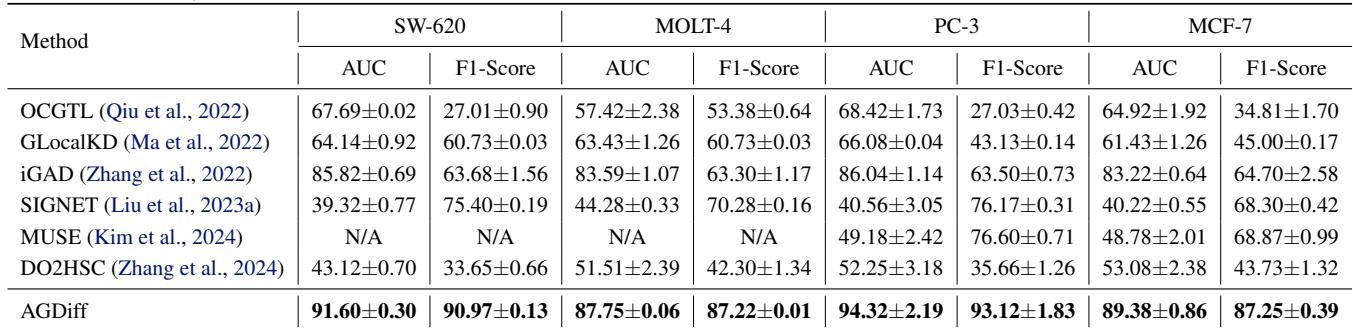
在表 2 中,差距进一步拉大。在 PC-3 上,AGDiff 达到了 94.32% AUC , 而最好的无监督基准 (MUSE) 仅达到 49.18%。这证明了当数据稀缺且不平衡时,生成多样化的伪监督信号比依赖数据集本身不均匀的统计数据要有效得多。
潜在空间可视化
为了证明模型不仅仅是在死记硬背数据,作者使用 t-SNE 可视化了潜在嵌入。
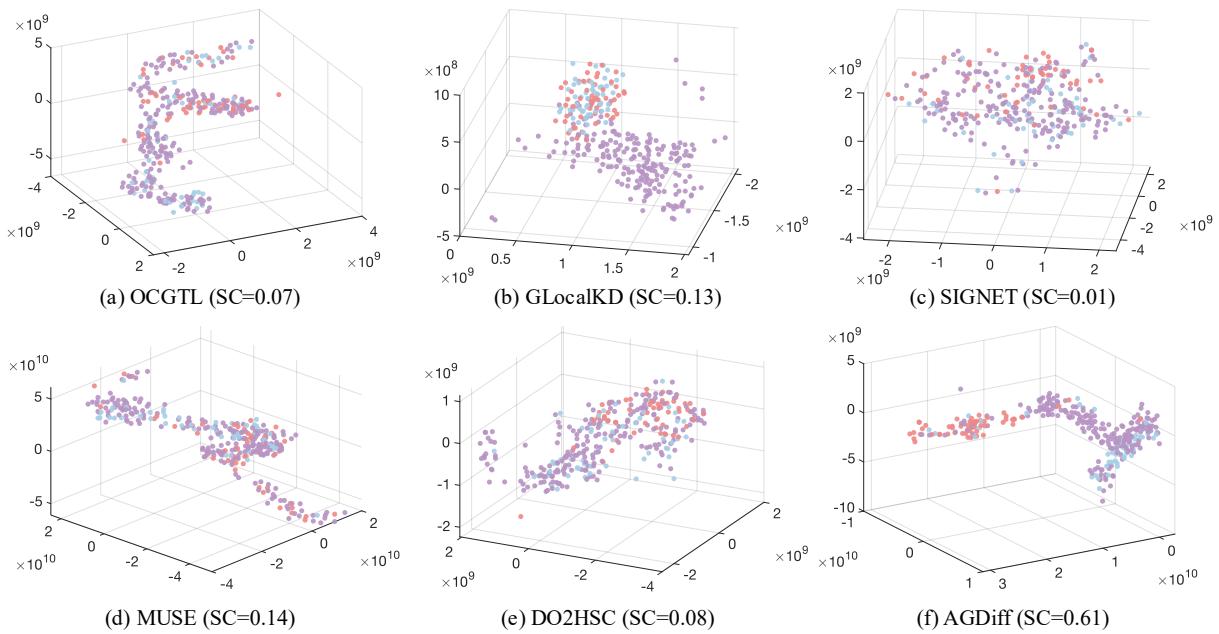
在图 5 中,请看 (f) AGDiff 与其他方法的区别。
- 在图 (a) 到 (e) 中,红点 (异常) 被埋在紫色/蓝色簇 (正常数据) 中。模型感到困惑。
- 在 (f) 中,AGDiff 将红点推到了一个明显的区域。 轮廓系数 (Silhouette Coefficient, SC) 跃升至 0.61 , 远高于第二好的结果 (0.14)。这种分离正是分类步骤如此准确的原因。
“伪异常”长什么样?
验证生成的图不仅仅是随机静噪非常重要。它们看起来需要像合理的图。
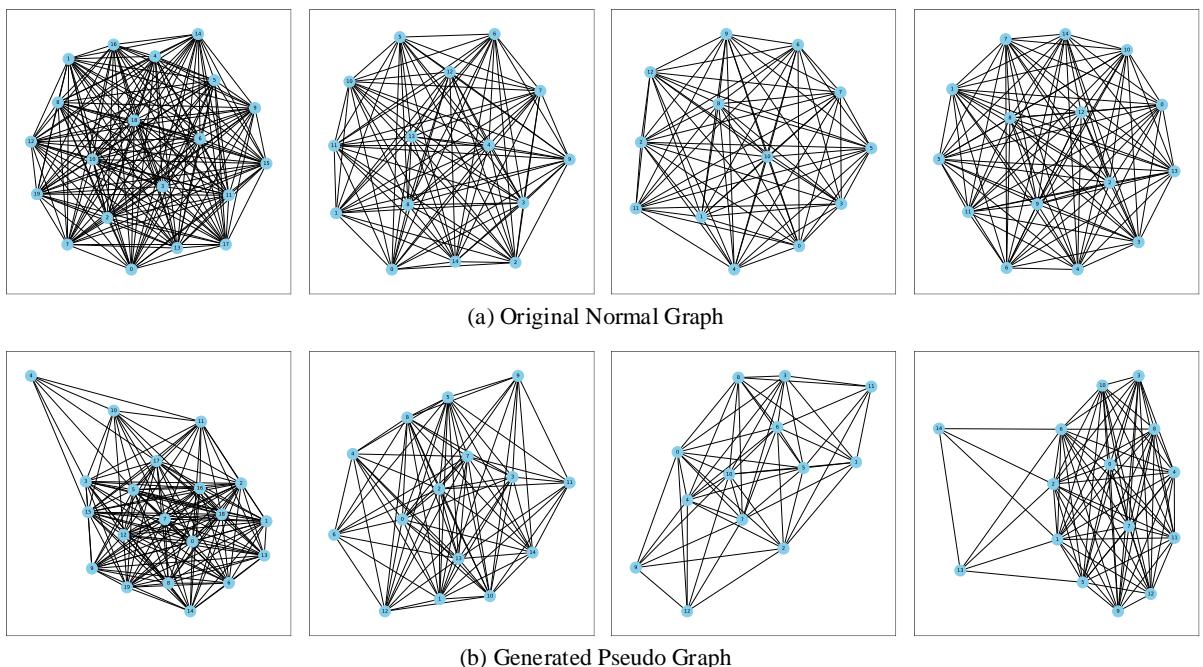
图 6 将原始正常图 (上排) 与其生成的伪异常对应图 (下排) 进行了比较。
- 结构保留: 伪图清楚地与其父图相似。它们不是随机噪声;它们看起来像分子。
- 细微偏差: 注意连接性的变化。有些簇更稀疏;有些边被改道了。这些正是作者想要达到的“细微扰动”——小到难以察觉的变化,迫使模型学习细粒度的特征。
超参数的影响
该模型有多敏感?作者分析了参数 \(\lambda\) (lambda),它控制分类损失和扩散损失之间的平衡。
\[ \mathcal { L } = \mathcal { L } _ { \mathrm { c l s } } + \lambda \mathcal { L } _ { \mathrm { d i f f } } \]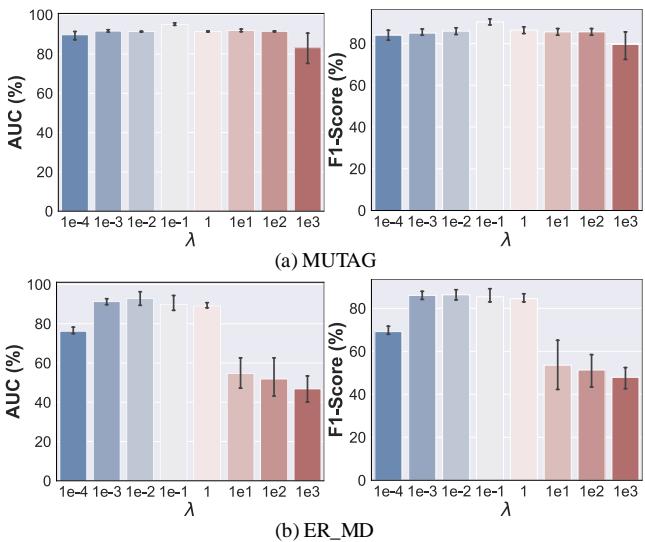
图 3 显示了一个“最佳平衡点 (Sweet Spot) ”效应。
- 低 \(\lambda\): 模型忽略了扩散质量。生成的异常不够多样化。
- 高 \(\lambda\): 模型过于关注扩散。伪异常可能会变得与正常图过于相似 (过度去噪) ,从而混淆分类器。
- 中间地带: 峰值性能出现在两个任务平衡的地方。
结论
AGDiff 论文展示了标准异常检测逻辑的巧妙反转。AGDiff 不是被动地观察正常数据并希望异常能突显出来,而是主动想象“可能会出什么问题”。
通过利用潜在扩散模型的生成能力,该框架创建了一个自监督学习环境。它生成多样化、具有挑战性的伪异常,作为我们很少见到的真实异常的代理。
关键要点:
- 转向生成: 从基于重构的检测转向基于生成的检测,可以实现更稳健的决策边界。
- 潜在力量: 在潜在空间中操作使得扩散过程高效且在结构上连贯。
- 扰动是关键: 条件噪声注入确保生成的图是有用的“近似样本”,而不是容易识别的垃圾数据。
对于图学习领域的学生和研究人员来说,这突显了扩散模型除了制作漂亮图片之外日益增长的效用——它们正成为复杂科学领域中数据增强和稳健表示学习的重要工具。