](https://deep-paper.org/en/paper/1812.07172/images/cover.png)
想象一下,你是一位才华横溢的学徒,正在向一位大师学习多种截然不同的技能。今天你画着精致的水彩画,明天又在锻造钢铁。一位好的导师不会用完全相同的基础原则教授这两种技艺。对于水彩画,你会从轻柔的笔触和色彩融合开始;对于锻造,你会从力量与热量控制入手。初始心态——即“先验”——必须与当前的任务相匹配。
在人工智能领域,这种“学会学习”的理念被称为元学习 。 其中一种领先的方法是模型无关元学习 (MAML) , 它旨在找到一个通用的起点——一组初始模型权重——使得 AI 能仅用少量样本便能快速适应新的任务。这就如同找到一个中央火车站,从那里可以迅速抵达城市的任何一个区域。
但如果这座“城市”拥有几个彼此分离的市中心呢?当任务差异极大——例如识别颜色与估算温度——一个单一的起点将无法兼顾所有情况。这正是多模态任务分布所带来的挑战: 这些任务往往自然形成不同的簇或“模态”。
来自南加州大学和 SK T-Brain 的研究团队在论文 《迈向多模态模型无关元学习》 中直接面对这一问题。他们提出的算法 MuMoMAML 结合了两大元学习范式的优点,创建了一个系统: 它首先识别所面临的任务类型,然后在学习开始前智能地调整其起点。这种混合设计同时具备灵活性与专业性,使得模型能快速而高效地学习各类不同的问题。
元学习的双重故事
要理解 MuMoMAML 的创新,我们先要了解它融合的两种方法: 基于梯度的元学习与基于模型的元学习。
1. 基于梯度的元学习: 寻找完美的起跑线
以 MAML 为代表的基于梯度方法,旨在寻找一组最优的初始参数,记作 \(\theta\)。这些参数虽不适用于任何单一任务,但它们经过调整后具备极强的适应性。只需几步梯度更新,模型便能快速针对新任务进行特化。
直观上,\(\theta\) 位于参数空间的中心点,周围环绕着不同任务的邻近最优点。这种灵活性使 MAML 具有模型无关性: 它几乎可应用于任何依靠梯度下降训练的架构——从卷积网络到强化学习智能体。
然而,它的局限在于依赖单一的 \(\theta\)。当任务模态相距较远时,这种通用初始化将变得无效。
2. 基于模型的元学习: 任务识别器
基于模型的方法选择了另一条路径。它们不去寻找共享初始化,而是学习从少量样本中直接推断任务身份。一个由若干样本对 \((x_k, y_k)\) 组成的支持集被编码成一个任务嵌入——一个总结了任务关键特征的向量。此嵌入随后会调节基础模型的行为。
可以把它比作一个“双脑系统”: 第一个“大脑”分析数据后说,“啊,这个任务是拟合正弦波!”;第二个“大脑”立即重构其内部结构,表现得像一个正弦波专家。这类方法在识别与适应特定任务方面表现出色,但通常需要精心设计的架构,因此通用性较差。
混合英雄: MuMoMAML
MuMoMAML (多模态模型无关元学习) 优雅地结合了这两种理念。它使用一个基于模型的组件来确定任务属于哪个模态,然后根据该信息生成一个定制化的起始点用于后续的基于梯度适应。
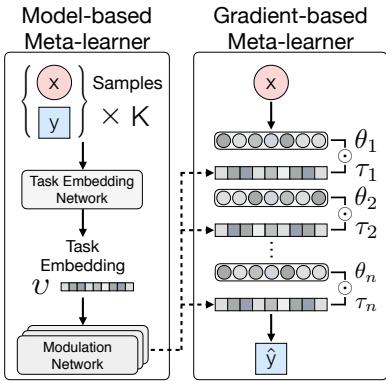
图 1: MuMoMAML 的架构。一个基于模型的“任务嵌入网络”识别任务,而一个基于梯度的学习器从一个经过调制的、特定于任务的起点开始适应。
整个过程分为两部分,并以端到端方式联合训练。
- 基于模型的识别器:
- 任务嵌入网络 — 将支持集样本 \(\{x_k, y_k\}_{k=1}^K\) 编码为稠密的任务嵌入向量 \(v\)。
- 调制网络 — 接收 \(v\),输出调制参数 \(\tau\),用于塑造基础模型在此任务上的行为。
- 基于梯度的适应器: 主模型由参数 \(\theta\) 表示,通过梯度更新来优化其预测。
神奇时刻: 调制
关键创新出现在这两者的结合中。调制参数 \(\tau\) 将通用参数 \(\theta\) 转换为任务专用参数 \(\phi\)。这一基于模型的适应步骤形式化为:
\[ \phi_i = \theta_i \odot \tau_i \]其中 \(\odot\) 表示在每层应用的调制操作。
作者们尝试了多种调制机制,包括注意力机制和逐特征线性调制 (FiLM) 。 结果显示 FiLM 最为有效。对于每一层,调制网络生成缩放与平移因子,分别记为 \(\tau_\gamma\) 和 \(\tau_\beta\),得到:
\[ \text{New Output} = (\text{Original Output} \otimes \tau_\gamma) + \tau_\beta \]这种逐层调制允许对网络进行细粒度调整,从而得到适合任务的新初始化 \(\phi\)。随后模型从该定制化起点出发,执行常规的基于梯度的适应 , 以实现高性能。
实验与结果: 它真的有效吗?
研究团队在三个领域——回归、强化学习和小样本图像分类——测试了 MuMoMAML,并发现其始终优于基线模型。
多模态回归: 拟合不同族的函数曲线
在此实验中,元学习器面对混合的回归任务: 拟合正弦函数、线性函数与二次函数 。 传统的 MAML 只有一个共享初始化,难以同时兼顾三者。
为了形成强有力的基线,作者提出了 Multi-MAML , 即为每个模式独立训练一个 MAML 模型。在评估时,Multi-MAML 被告知每个函数属于哪个模态——这相当于具备先知式的优势。
结果却令人清晰:
| 方法 | 调制 | 双模态 (MSE) | 三模态 (MSE) |
|---|---|---|---|
| MAML | – | 1.0852 | 1.1633 |
| Multi-MAML | 真实模态 (GT) | 0.4330 | 0.7791 |
| MuMoMAML (FiLM) | 学习得到 | 0.3125 | 0.4048 |
MuMoMAML 的性能甚至超过了使用真实模态先验的 Multi-MAML。这表明它能够自主推断任务模态并有效利用模态间的共享知识——不仅仅是孤立地学习专业技能,而是实现洞见迁移。
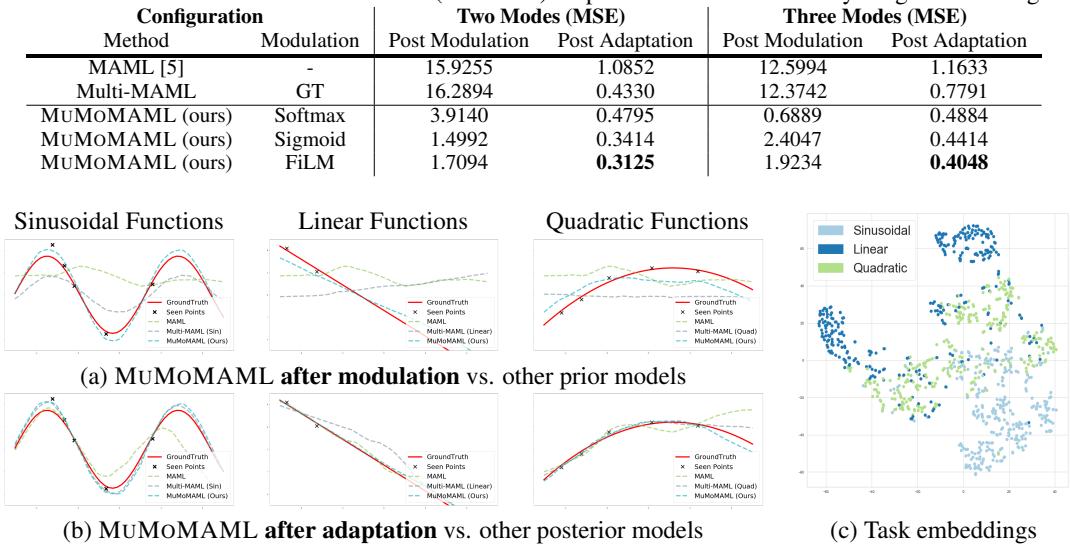
图 2: (a) 未进行梯度更新时,MuMoMAML 调制后的先验 (蓝色) 已比 MAML 更能逼近目标函数。(b) 经过适应后,它超越了所有基线模型。(c) t-SNE 图显示不同函数类型形成清晰聚类,验证了模态识别的成功。
图 2(c) 所示的任务嵌入按函数类型整齐聚类,证明 MuMoMAML 成功学习到了每种模态的内部表示。
强化学习: 在双模态世界中导航
MuMoMAML 也在强化学习环境中进行了评估,智能体需从多模态目标分布中学习。
在 2D 导航任务中,智能体要到达来自两个不同簇的目标点。而在更复杂的 Mujoco 模拟中,一个半猎豹 (Half-Cheetah) 机器人学习在不同位置间移动或维持不同目标速度。
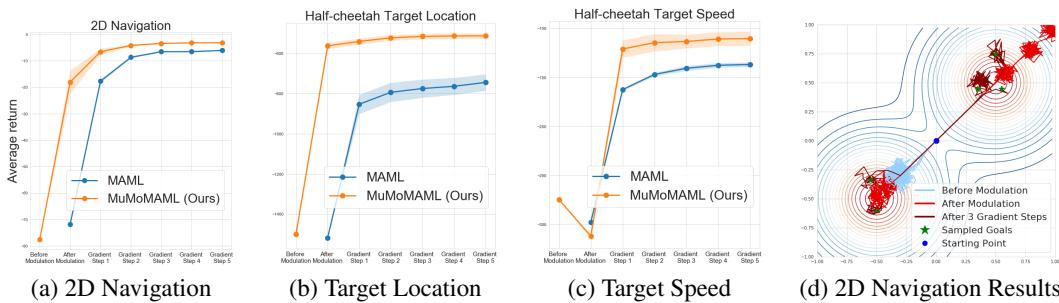
图 3: (a–c) 在各个适应阶段,MuMoMAML (橙色) 均获得比 MAML (蓝色) 更高的奖励。(d) 在 2D 导航任务中,调制后的策略 (橙色) 已能朝正确目标移动;经过几步梯度下降 (绿色) 后,它进一步微调轨迹。
即便在梯度更新之前,调制策略已带来更高的初始奖励。仅靠调制步骤便赋予智能体情境感知能力——引导其进入正确的行为模式。
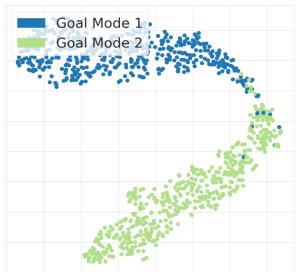
图 4: 在半猎豹目标位置环境中,任务嵌入形成了两个清晰的聚类,表明模型能够从有限的交互数据中识别任务模态。
在所有强化学习任务中,从第一次适应到最终收敛,MuMoMAML 始终保持对 MAML 的优势。
小样本图像分类: 通用测试
最后,研究团队在经典的 Omniglot 基准上评估了 MuMoMAML。任务要求模型在每类仅看到一个或五个样本后识别新的手写字符。
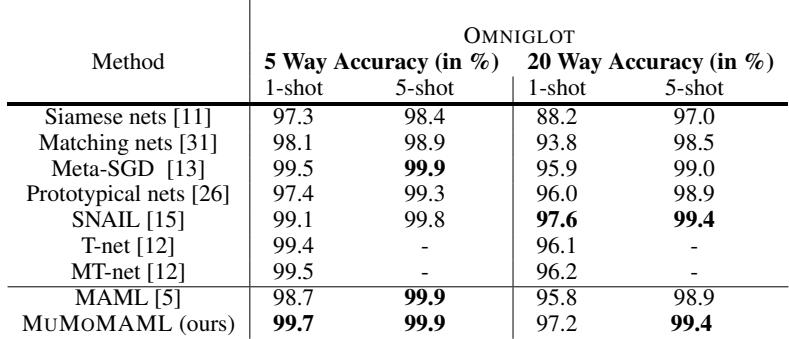
表 2: MuMoMAML 的性能达到或超过当前最优水平,表明其多模态适应机制即便在没有明确模态的任务中也能良好泛化。
MuMoMAML 的表现与顶尖算法相当,有时甚至更好。值得注意的是,它的混合设计并未削弱标准任务上的表现——实现了流畅的泛化能力。
结论: 两全其美的元学习
论文 《迈向多模态模型无关元学习》 提出了一个引人深思的理念: 当面对高度多样化的任务时,不必执着于寻找一个单一的起点,而应适应“先验”本身 。
通过结合基于模型的任务识别能力与基于梯度的快速适应效率,MuMoMAML 构建了一个灵活的基础,使其能够识别任务性质并立即调整策略。经调制后,它再通过梯度下降不断精化理解——兼具直觉与理性。
这种混合式方法标志着朝更加具备情境感知的人工智能迈出了重要一步。正如一位匠人从水彩画切换到钢铁锻造时会转换思维方式,MuMoMAML 也让机器能够根据挑战类型来定制其学习过程——让真正的通用智能更近一步。