](https://deep-paper.org/en/paper/2010.02500/images/cover.png)
人类是卓越的学习者。在我们的一生中,我们不断获取新技能,适应不断变化的环境,并在过去的经验基础上持续成长。当你学会骑自行车时,你不会忘记如何走路;当你学习一门新语言时,你仍然记得自己的母语。这种在不抹去已有知识的前提下积累新知识的能力,是人类智慧的一个重要标志。
对于现代人工智能系统而言,这个对人类来说轻而易举的能力却是一个重大挑战。当今最先进的模型——如 BERT 和 GPT——在狭窄的任务上表现出色,但当它们在新数据上重新训练时,却常常会忘记之前掌握的知识。这个问题被称为灾难性遗忘 , 就像一个学生在历史考试中取得优异成绩后,却把所有数学知识都忘了。这严重限制了人工智能在任务与数据不断变化的真实世界场景中的实用性。
研究人员长期以来一直追求终身学习的终极目标——设计能够按照时间顺序学习不断出现的任务而不抹去已有知识的模型。许多此类方法依赖于“情景记忆”系统来存储和回放过去的样本。然而,这些方法往往存在明显的实践缺陷: 巨大的内存需求、负迁移 (即先前学习损害了新学习) ,以及缓慢的推理速度。
卡内基梅隆大学的一支团队在他们的论文《内存受限的高效元终身学习》中尝试解决这一问题。他们提出的模型 Meta-MbPA , 在显著降低内存占用的同时提升了准确率和速度。它仅使用以往方法所需内存的 1% , 就实现了最先进的结果,并且运行速度提高了 22 倍 。 让我们看看这项突破是如何实现的。
终身学习的三大支柱
在深入理解 Meta-MbPA 之前,先了解终身学习的核心理念会很有帮助。其目标是在一个任务序列 \( \mathcal{D}_1, \mathcal{D}_2, \ldots, \mathcal{D}_N \) 上训练单个模型 \( f_{\theta} \),这些任务依次到来。模型并不知道每个样本属于哪个任务,但必须在所有任务上保持良好的平均表现。
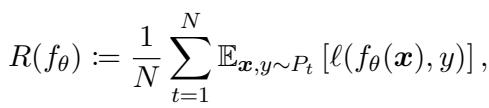
“模型持续学习,以最小化所有已观察任务的平均期望风险,从而平衡新旧知识。”
多数终身学习系统遵循三项关键原则:
1. 通用表示 (Generic Representation) : 从广泛的知识基础开始。像 BERT 这样的模型在海量文本语料上预训练,捕捉了通用语言理解能力。终身学习者在此基础上逐步更新知识,通常采用正则化来防止出现可能导致旧知识被抹去的剧烈参数变化。
2. 经验回放 (Experience Rehearsal) : 受人类记忆巩固的启发,这一原则要求将极少量的过往样本存入情景记忆模块。当学习新任务时,模型通过回放这些旧样本进行“排练”,以强化旧知识。
3. 任务特定微调 (局部适应) (Task-specific Finetuning / Local Adaptation) : 在推理阶段,模型快速微调最接近查询输入的样本——即内存中的 K 个最近邻——通过少量轻量更新适应特定任务的细微差别,同时保留通用知识。
这三大支柱非常强大,但如何有效结合它们才是挑战所在。在 Meta-MbPA 出现之前的最新方法虽然尝试实现这一目标,却陷入了效率瓶颈。
先进方法及其局限性: MbPA++
此前最好的方法是 基于模型的参数适应 (MbPA++) , 它整合了三大原则,但并未以统一的方式实现。其核心过程如下:
- 通用表示: 从一个预训练的 BERT 编码器开始,并针对每个新的训练样本更新参数,以最小化标准任务损失。
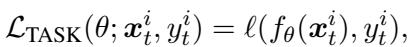
“公式 (2): 任务损失——衡量模型在每个训练样本上的误差。”
- 经验回放: 模型定期从内存中采样一批存储样本进行回放,以巩固旧技能。
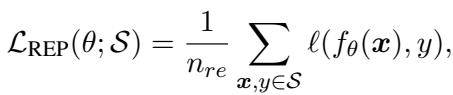
“公式 (3): 经验回放帮助模型刷新先前任务的知识。”
- 任务特定微调: 在测试阶段,MbPA++ 会为每一个测试查询检索 \(K\) 个最近邻样本,然后执行多次梯度下降更新进行局部适应,再生成预测结果。
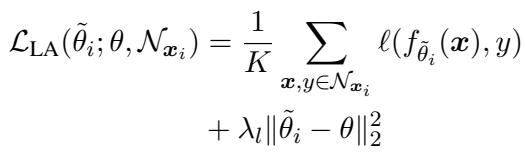
“公式 (4): 局部适应通过内存中的邻近样本微调预测。”
尽管 MbPA++ 效果不错,但研究人员发现了三大缺陷:
- 内存过大: 需要几乎存储所有训练样本才能达到最佳表现。
- 负迁移: 在新任务上的表现有时甚至不如基线模型。
- 推理缓慢: 每个测试样本都要重新适应,推理可能耗时数小时。
问题的根源在于训练与测试的不匹配 : MbPA++ 只在训练中最小化直接任务损失 (公式2) ,而评估时是在局部适应 (公式4) 之后。换句话说,它从未学会如何高效地适应。
协同解决方案: Meta-MbPA 框架
Meta-MbPA 通过巧妙的元学习策略解决了这一训练-测试不匹配问题。它不再只是训练模型完成任务,而是训练模型成为一个能高效进行未来适应的良好初始化器 。 也就是说,模型不仅是在学习,还在学习如何学习。
1. 元学习更优的通用表示
为了获得适应性更强的表示,训练的每一步都模拟一个内部“局部适应”循环,然后根据适应后的表现更新模型参数。
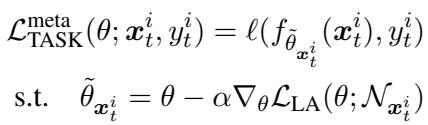
“公式 (5): 元损失鼓励模型在模拟适应后仍表现良好,从而弥合训练与测试之间的差距。”
这将学习转化为一个“学习去适应”的过程,外部优化使模型更具弹性与灵活性。像 PyTorch 这样的现代框架可以无缝处理所需的“梯度的梯度”计算。
2. 更智能的经验回放
Meta-MbPA 也依据相同的元学习原则重构了记忆回放,确保模型以能够提升未来适应能力的方式从过去样本中学习。
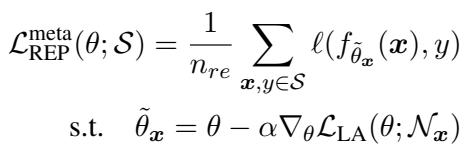
“公式 (6): 元回放让模型从过去样本中学习适应能力。”
此外,Meta-MbPA 不再随机填充内存,而是采用基于多样性的记忆选择规则 。 在决定是否存储新样本时,会计算它与当前内存中样本的差异:
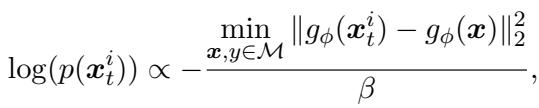
“公式 (7): 差异性越大的样本越可能被存储,以捕捉更广泛的数据分布。”
该方法选择能扩展内存覆盖范围的样本,同时将内存大小控制在极小规模——仅占数据总量的 1%。
3. 高效且稳健的微调
最后,Meta-MbPA 通过引入粗粒度局部适应显著加快推理。它不再为每个测试样本单独适应,而是使用全局内存中随机抽样的一批实例为整个批次执行一次性适应。
这种设计的两大优点:
- 稳健性: 广泛采样可避免因少数不相关样本造成过拟合。
- 高效性: 一次适应可同时优化数千个预测,推理速度提升高达 22× 。
Meta-MbPA 的实证验证
该框架在文本分类和问答任务上进行了评估,使用了 AGNews、Yelp、Amazon、DBPedia、SQuAD 和 TriviaQA 等标准数据集。
整体性能
与 MbPA++、Replay、A-GEM 和 Online EWC 等强基线方法相比,Meta-MbPA 即使在极小的内存条件下,仍取得明显优于对手的结果。
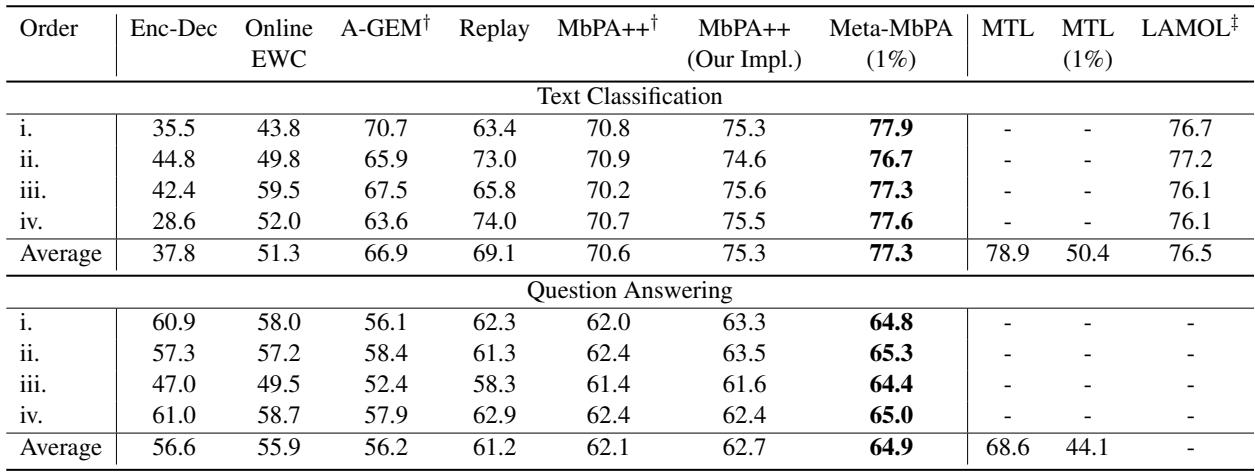
“Meta-MbPA 使用仅 1% 内存,即达到了最高的平均准确率和 F1 分数。”
内存效率
为了直接比较效率,研究者在相同的小内存预算下评估 MbPA++ 与 Meta-MbPA。结果清晰: Meta-MbPA 表现稳定,而 MbPA++ 性能大幅下降。
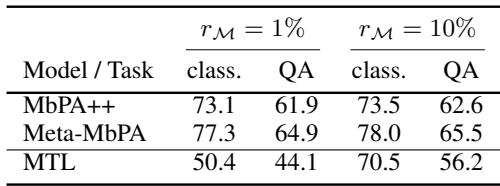
“即使内存极小,Meta-MbPA 仍保持强劲表现,突出了其高效的内存利用率。”
“不确定”记忆的问题
研究者还探索了不同的样本存储策略。随机选择与基于多样性的选择效果良好,而“基于不确定性”的选择——选取模型最不确定的样本——却表现异常糟糕。
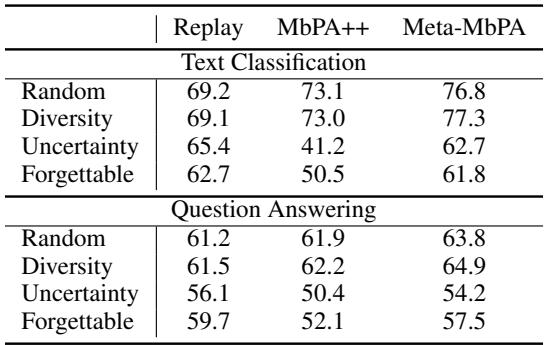
“由于数据覆盖不足,基于不确定性的记忆选择始终表现欠佳。”
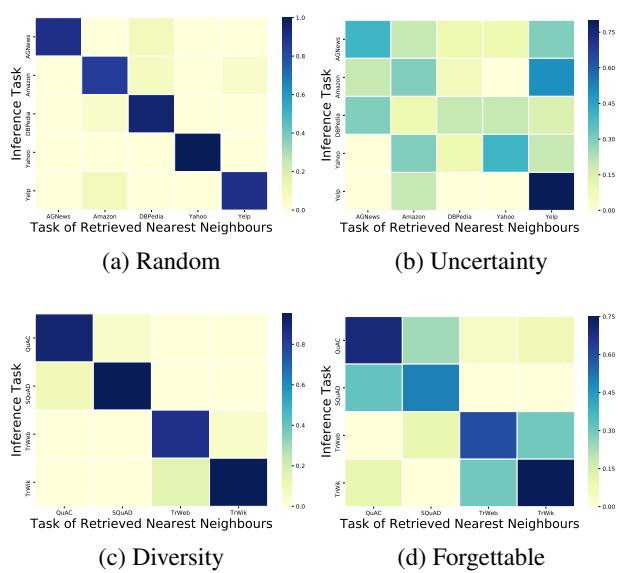
“图1: 基于多样性的记忆确保任务对齐邻居检索,减少跨任务干扰。”
当不确定性记忆被模糊或异常样本填充时,模型在不同任务间检索到错误邻居,导致负迁移——即旧任务学习干扰新任务。
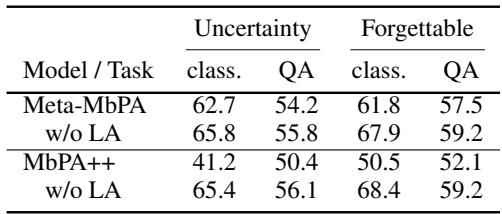
“在不确定性记忆条件下跳过局部适应能提升准确率——这是负迁移效应的证据。”
平衡遗忘与负迁移
终身学习不仅要防止灾难性遗忘,过度纠正还可能造成负迁移——旧知识反而阻碍新学习。Meta-MbPA 是第一个明确权衡这种取舍的框架。
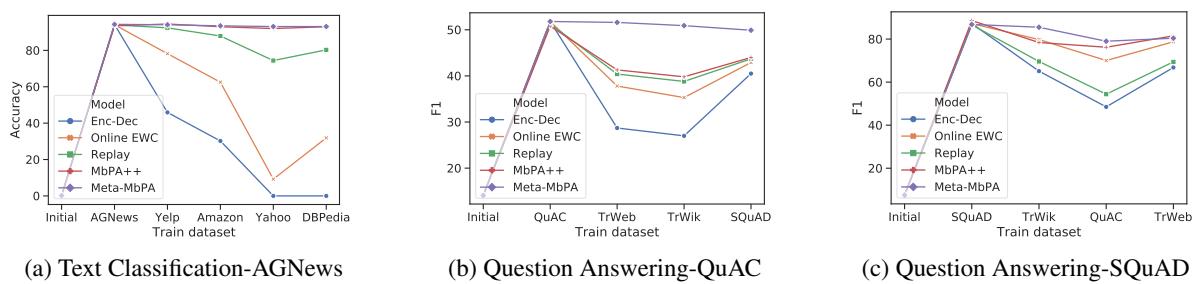
“Meta-MbPA 能在持续学习新任务的过程中保持对首个任务的最佳表现。”
那么,它在学习新任务方面的表现如何?最后任务的结果揭示了另一面。
“Meta-MbPA 避免了 MbPA++ 的负迁移问题,在最新任务上保持强劲性能。”
Meta-MbPA 成功实现了在掌握新技能的同时保留旧技能——这是终身学习领域极为罕见的成果。
结论: 迈向真正的自适应 AI
高效元终身学习框架标志着人工智能持续学习的重大进步。通过将表示学习、记忆回放与适应统一为一个协同的元学习过程,它实现了前所未有的效率与稳定性。
核心总结:
- 协同作用至关重要: 训练模型学会高效适应胜于分散优化各组件。
- 小而精的记忆: 覆盖多样样本的记忆库可媲美规模庞大的存储。
- 平衡是关键: 终身学习的成功取决于同时控制遗忘与负迁移。
凭借 Meta-MbPA,我们向着能够在复杂动态的现实环境中持续可靠学习的 AI 系统又迈进了一步——高效、自适应,更加接近人类。