](https://deep-paper.org/en/paper/2206.05625/images/cover.png)
人工智能已在众多专业任务中取得了超越人类的表现。AI 可以在国际象棋中击败特级大师,以惊人的准确度转录音频,并在图像识别方面超过人类。然而,尽管现代 AI 功能强大,却存在一个关键弱点: 它很“脆弱”。多数 AI 模型就像一个为了单场考试而拼命的优秀学生——能完美掌握一门学科,却在面对新主题时一无所知。相比之下,孩子能够持续学习,适应新信息,精进技能,并在旧知识的基础上不断拓展,而不会将过去的学习清空。
这一根本差距揭示了 AI 发展中的两大障碍。首先是灾难性遗忘现象——神经网络在学习新任务时,会覆盖掉对旧任务的知识。其次是神经网络的设计过程 , 它至今仍是一门缓慢且依赖直觉的艺术,而非系统化、可扩展的科学。
若我们能构建出能克服这两大障碍的 AI 呢?如果 AI 不仅能持续学习,还能不断重塑自身架构,提升学习能力,会发生什么?这正是研究论文 《探索神经架构搜索与持续学习的交叉点》 所探讨的愿景。作者提出了一种新范式——持续自适应神经网络 (Continually-Adaptive Neural Networks, CANNs) , 将持续学习 (Continual Learning, CL) 和神经架构搜索 (Neural Architecture Search, NAS) 两个前沿领域结合,旨在创造能够自主适应与演化的智能体。
本文将解析这一愿景的核心思想。我们将探讨 CL 与 NAS 如何应对终身学习和自我设计的挑战,并深入了解它们融合后如何催生 CANNs——那些为学习而生的 AI 系统。
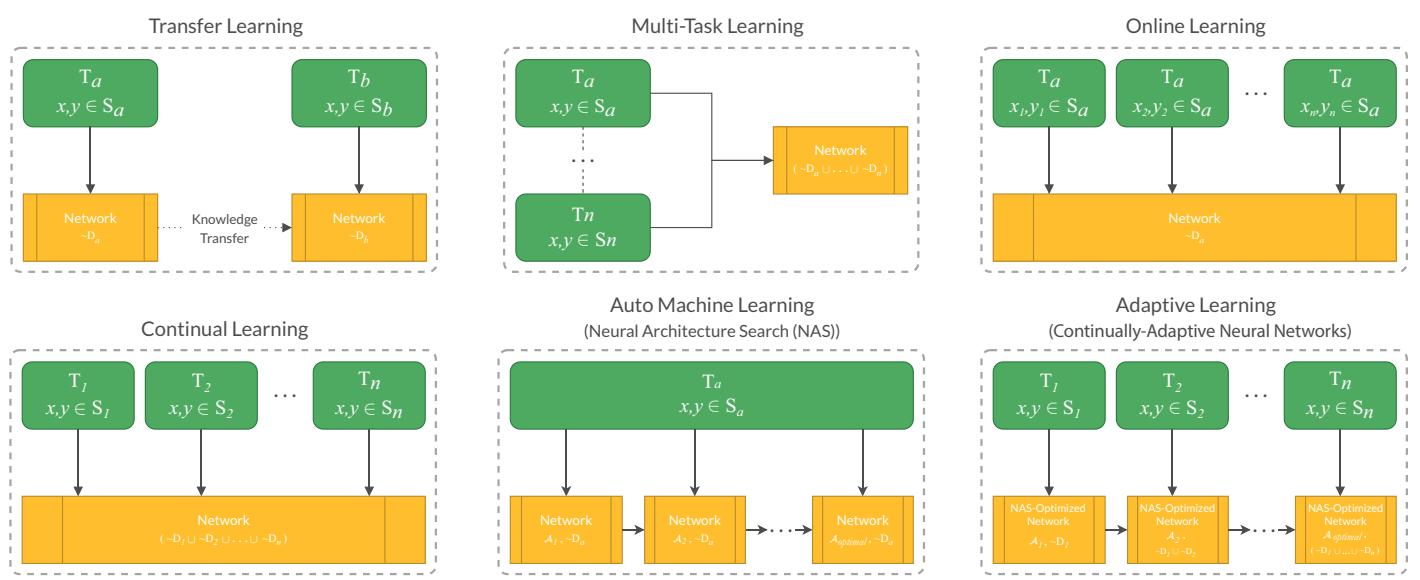
自适应学习及其相邻机器学习范式的比较图示。
稳定性–可塑性困境: 理解持续学习
设想你训练了一个世界级的 AI 来识别鸟类。然后,你希望它学会识别鱼类。当用鱼的图像训练同一网络时,其内部参数会发生剧烈变化,结果它忘记了如何识别鸟——这就是灾难性遗忘的一个例子。
持续学习 (CL) 的目标是使模型能够从连续的数据流中学习,而不会丢失先前知识。其核心在于平衡两种相互对立的力量:
- 可塑性 (Plasticity): 学习新信息并快速适应的能力。
- 稳定性 (Stability): 在学习新任务时仍能保留旧知识的能力。
这种平衡被称为稳定性–可塑性困境——学得太灵活容易遗忘,学得太僵化则无法进步。CL 研究提出了两大类策略来解决这一问题,如下图所示。
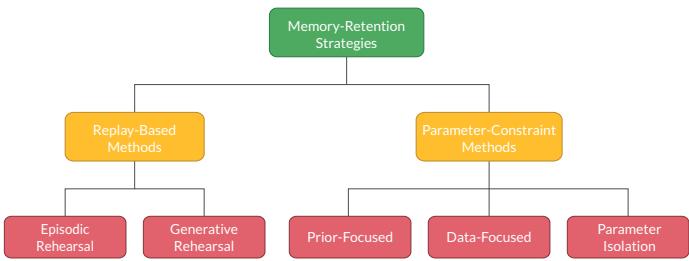
持续学习中的记忆保留策略。
1. 基于重放的方法: 温故而知新
受人脑巩固记忆机制的启发,基于重放的方法通过储存过去任务的信息来进行“复习”。
- 情景重放 (Episodic Rehearsal): 网络保存一小部分先前任务的原始数据。在训练新数据时混入这些旧样本,帮助模型回忆已有知识。该方法简单但内存占用大,难以扩展。
- 生成式重放 (Generative Rehearsal): 不保存原始数据,而是用生成模型 (如 GAN) 学习数据分布并生成合成样本进行复习。更高效,但复杂度更高。
这两种方法都借鉴了生物学记忆重放的机制,是强大而资源密集的终身学习途径。
2. 基于参数约束的方法: 保护知识
此方法不依赖旧数据,而是通过保护关键参数来保持知识。
- 正则化方法 (Prior-Focused): 增加惩罚项,防止关键权重发生大幅变化。弹性权重巩固 (Elastic Weight Consolidation, EWC) 是著名案例。
- 参数隔离 (Parameter Isolation): 冻结旧任务的参数,为新任务分配新的参数,可完美保存旧知识但容易导致模型无限膨胀。
- 知识蒸馏 (Data-Focused): 让旧模型充当“教师”,引导新模型模仿其输出,既能传递知识又避免重放。
混合方法,如梯度情景记忆 (Gradient Episodic Memory, GEM) , 结合重放与约束——在保护关键参数的同时重放代表样本,以平衡记忆保持与适应性。
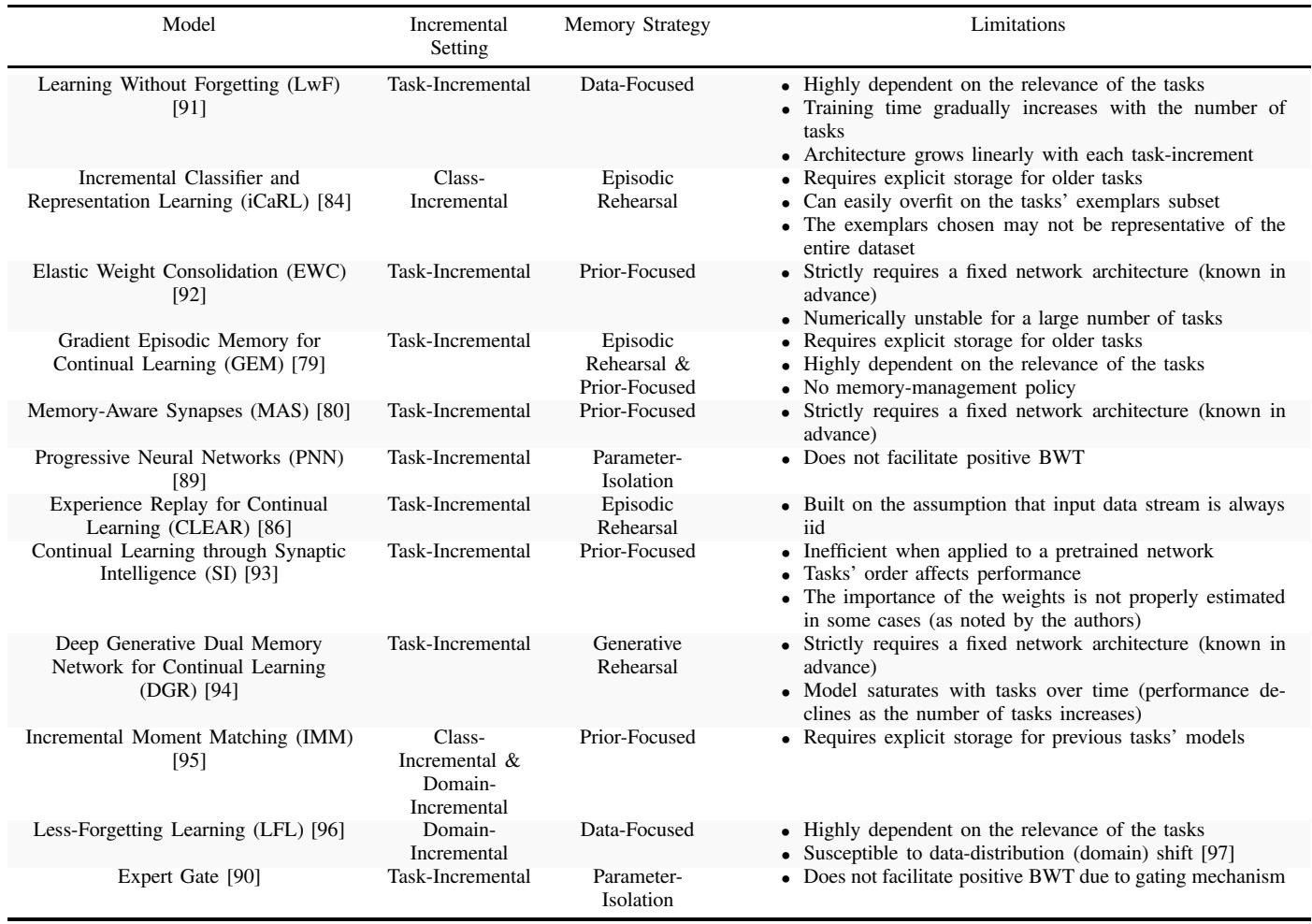
从适应性角度比较关键持续学习模型。
自动架构师: 揭示神经架构搜索的机理
当 CL 研究聚焦于让模型持续学习时,NAS 则解决了另一个问题: 谁来设计这些模型?
设计神经网络架构——即层、操作与连接的组合——传统上需要大量人工与经验。 神经架构搜索 (NAS) 通过算法自动探索最优架构来解决这一问题。
一个典型的 NAS 系统 (如下图所示) 包括三大部分: 搜索空间 (Search Space)、搜索算法 (Search Algorithm) 与评估策略 (Evaluation Strategy) 。
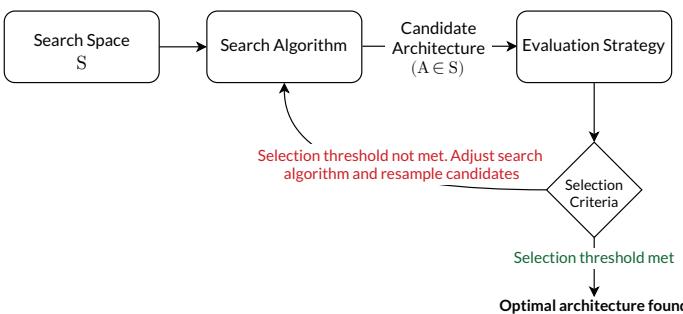
通用的神经架构搜索框架。
1. 搜索空间: 可能性的宇宙
搜索空间定义了可探索的架构类型:
- 层级空间 (Layer-Wise Space): 每一层都从一组操作 (如卷积、池化) 中采样。灵活但计算量巨大。
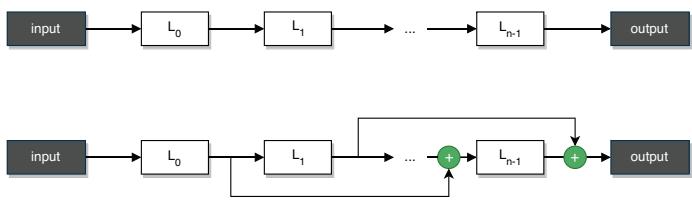
层级搜索空间: 顺序架构 (上) 与带跳跃连接的架构 (下) 。
- 基于单元的空间 (Cell-Based Space): 由可复用的“小单元”在固定宏观结构中堆叠构建。高效且广泛应用,如 NASNet 等顶尖模型即采用此方法。
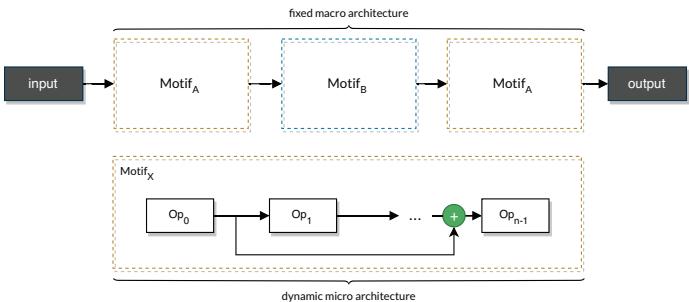
基于单元的 NAS 架构示例。
2. 搜索算法: 构建的逻辑
用于探索搜索空间的算法包括:
- 强化学习 (Reinforcement Learning): 智能体逐步设计架构,并根据性能获得奖励。
- 神经进化 (Neuroevolution): 架构种群通过选择、变异与交叉进化,模仿自然选择。
- 梯度优化 (Gradient Optimization): 将搜索空间转换为可微形式,以梯度下降同时优化架构与权重,这奠定了可微 NAS (如 DARTS) 的基础。
3. 评估策略: 性能检验官
系统需要评估各候选架构的表现:
- 完整训练 (Full Training): 每个架构都从零训练,精确但耗时。
- 低保真估计 (Lower Fidelity Estimation): 用部分数据或低分辨率快速预测性能。
- 权重继承 (Weight Inheritance): 从父架构传递权重给子架构,减少训练成本。
- 一次性模型 (One-Shot Models): 训练一个包含所有子架构的“超网”(supernet),子图共享权重,将搜索时间从数周缩短到数小时。
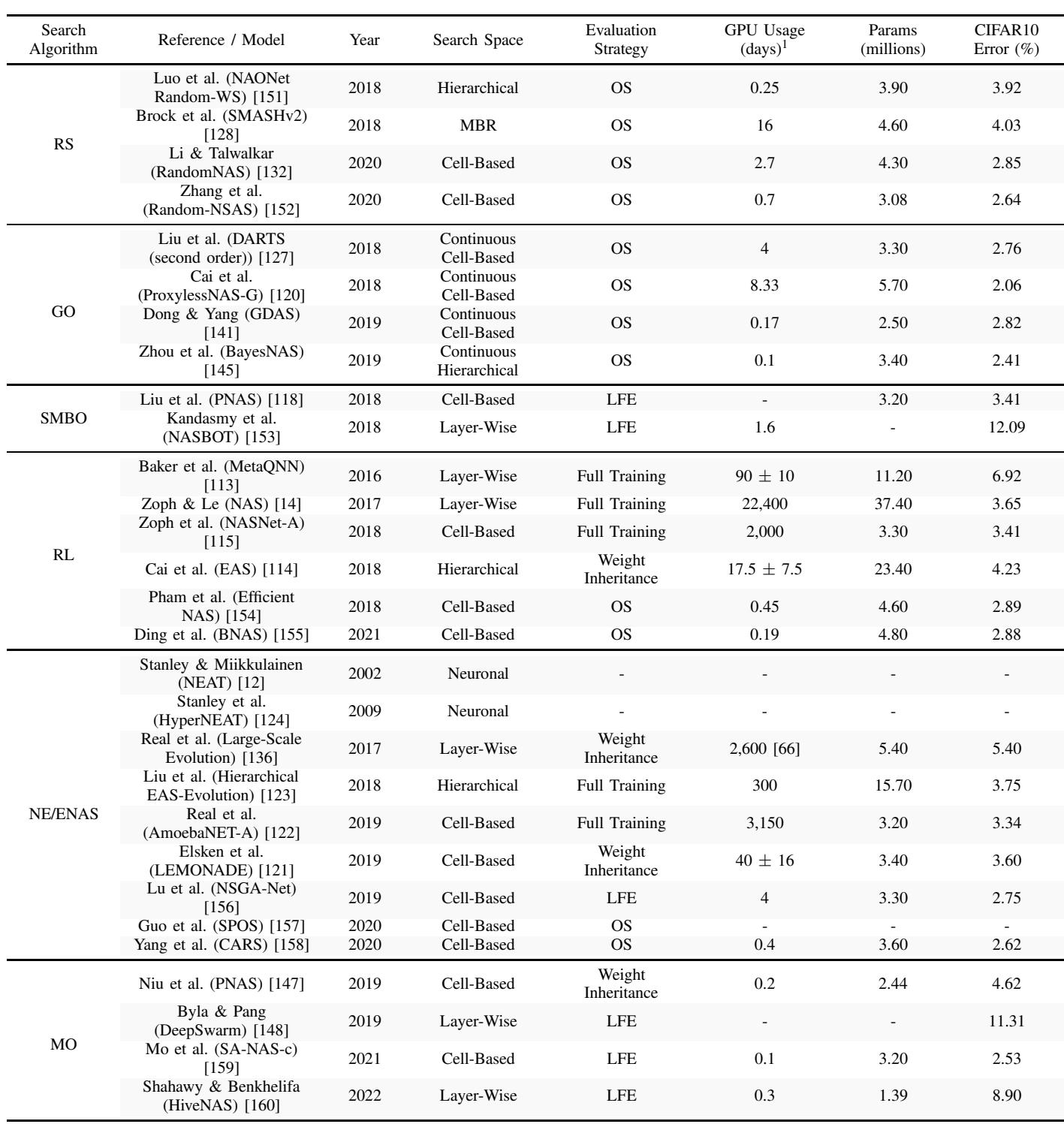
NAS 模型性能比较。
NAS 实现了模型设计的自动化飞跃,但多数 NAS 框架假设任务是静态的——一次性学习一个固定任务。当环境变化时,架构不会随之演化。这种静态性与持续适应形成鲜明对比,也因此催生了 CANN 的理念。
综合: 持续自适应神经网络 (CANNs)
持续自适应神经网络融合了 CL 的终身学习与 NAS 的自我设计。传统 CL 模型只调整权重,传统 NAS 模型每个任务生成一个架构。而 CANN 能在跨任务学习的过程中同时演化架构。
作者指出,CANN 应具备以下特征:
- 生命周期内完全自主。
- 本质上持续学习, 可防止灾难性遗忘。
- 能够处理无限输入流, 随时间平滑自适应。
为实现这一目标,CANN 必须融合学习与自我管理,兼顾模型与数据的双重适应。
提出的持续自适应神经网络分类法。
CANN 的主要组成
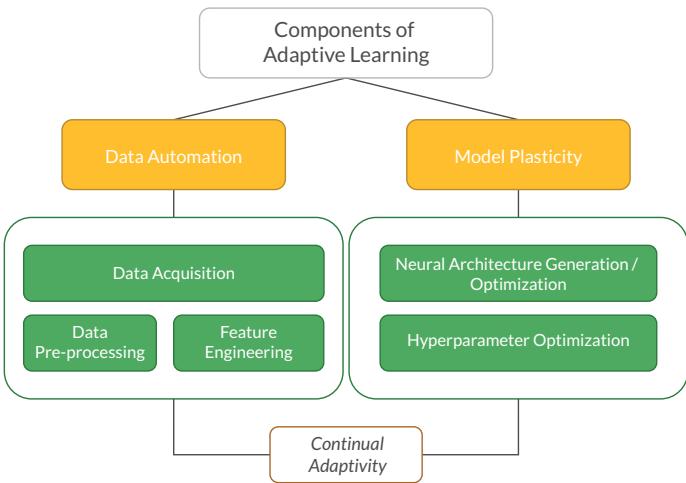
CANN 框架基于两大支柱: 模型可塑性 (Model Plasticity) 和数据自动化 (Data Automation) 。
- 模型可塑性: 连接 NAS 与 CL 的核心引擎。架构可增减规模以应对复杂性变化,修剪冗余连接,为新领域重映射模块,并动态优化超参数。
- 数据自动化: 系统可自主管理数据流——无需人工干预即可完成收集、清洗与特征构建。
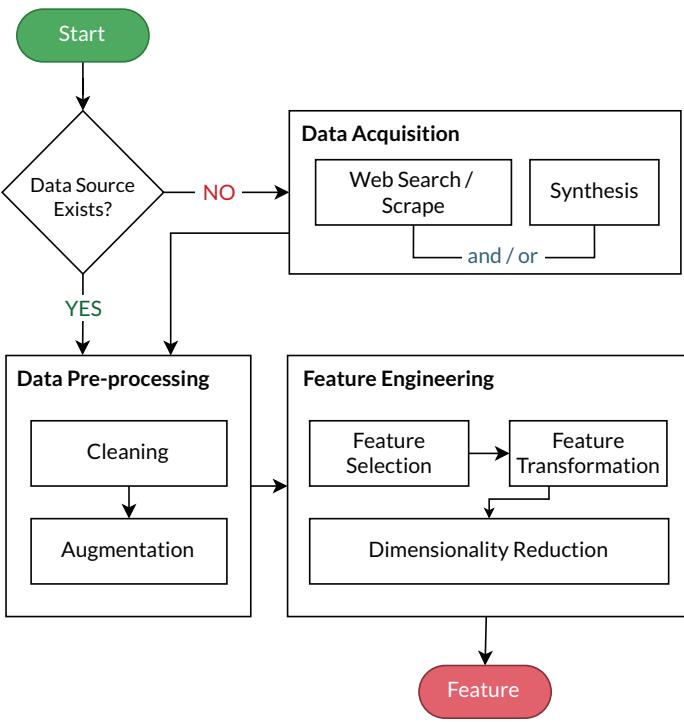
持续数据自动化流程图。
该流程包括:
- 数据采集 (Data Acquisition): 通过网络爬取或使用 GAN、模拟器生成新样本。
- 数据预处理 (Data Pre-processing): 清理噪声、修复缺失值,并进行数据增强以提升多样性。
- 特征工程 (Feature Engineering): 自动选择相关特征,优化表示并降低维度。
早期模型与其挑战
研究者已尝试将 CL 与 NAS 结合,虽有成效但仍不完善。
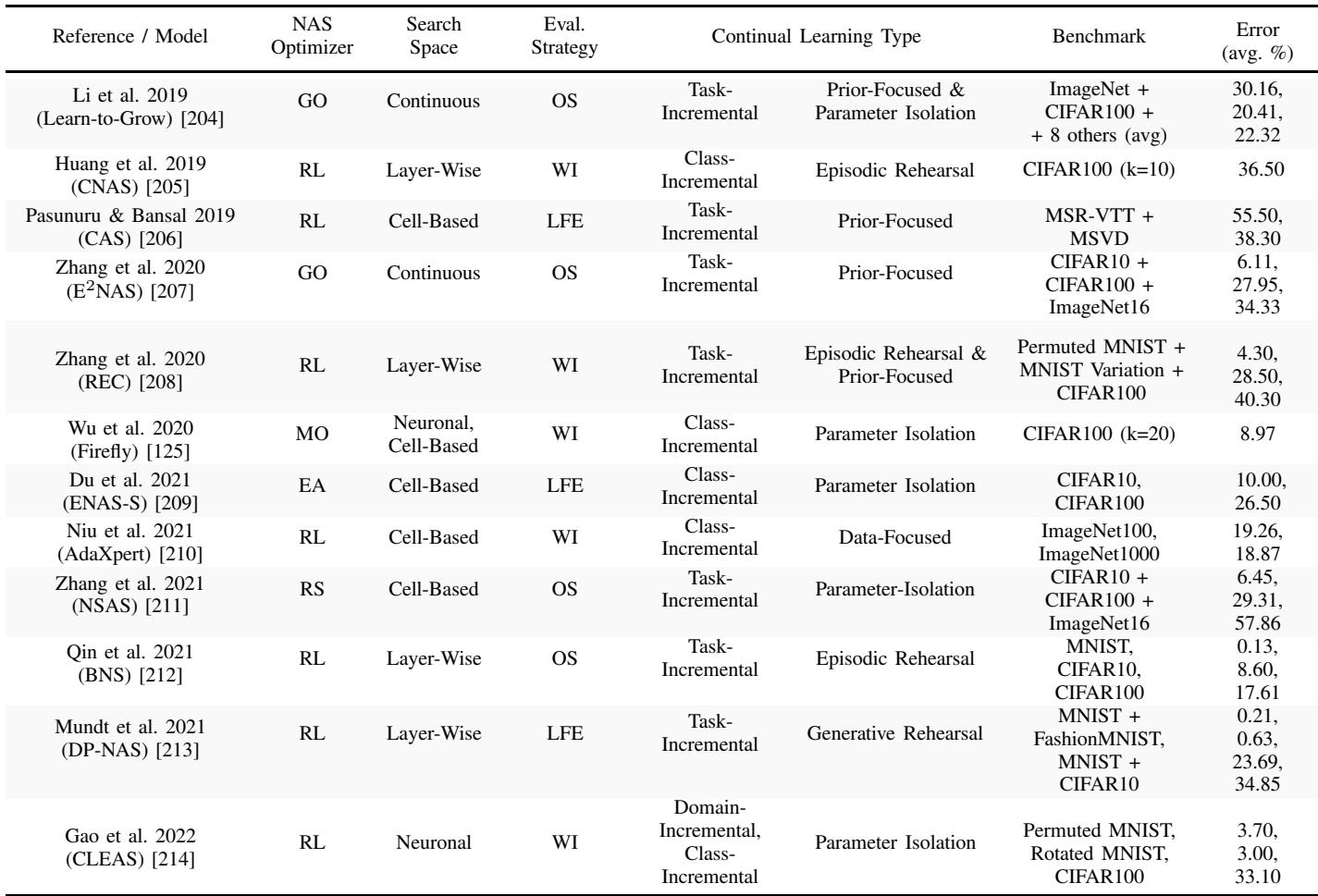
现有持续自适应神经网络模型的比较。
诸如 Learn-to-Grow 和 ENAS-S 的模型会在每次学习新任务时扩展架构,从而避免遗忘,但规模会无限膨胀。重放型方法如 CNAS 与 BNS 需要庞大的外部存储。与此同时,AdaXpert 仅在数据分布显著变化时触发新架构搜索——更智能,却仍假设任务间分界明确。
愿望清单: 适应性智能的特征要求
基于这些原型,作者提出了未来 CANN 的“理想特性”:
- 有界容量的动态架构: 模型可按需扩展或收缩,但需保持可部署性。
- 优雅的遗忘: 遗忘应渐进、选择性,而非彻底丧失。
- 小样本学习能力: 利用先前经验快速学习极少样本任务 (正向迁移) 。
- 无显式数据存储: 通过参数约束替代原始数据保存,以符合隐私与可扩展目标。
- 领域无关学习: 无需人为定义任务边界即可持续学习。
- 动态搜索空间推断: 可根据数据流自动调整架构候选池。
这些特性描绘了真正自适应智能的蓝图——能够自主构建、学习、重塑自身的持续进化系统。
前路展望: 挑战与未来方向
CANN 的愿景令人振奋,却也充满挑战。结合 NAS 与 CL 意味着叠加两个计算资源密集型过程。未来研究需聚焦于提升自主效率——通过更智能的搜索、评估与学习融合来降低成本。
关键研究方向包括:
- 基准测试 (Benchmarking): 建立持续适应的新评估指标,超越单纯准确率。
- 未探索的算法 (Unexplored Algorithms): 探索群体智能或蚁群优化等元启发式算法,提高并行性与探索性。
- 真正的自主性 (True Autonomy): 模型终将学会定义自己的目标——迈向通用人工智能 (AGI) 的关键一步。
- 安全与可靠性 (Safety and Reliability): 自主系统必须确保数据完整性,并防止在关键领域发生不稳定的自我修改。
结论: 从静态工具到有机学习者
数十年来,AI 一直以狭窄的专精定义——一个模型只解决一个任务。然而,现实世界是动态的,充满持续变化。
持续自适应神经网络为突破这一限制提供了新路径,将 CL 的终身学习与 NAS 的自我设计相结合。这类系统或将开启 AI 进化的新阶段——从僵化算法迈向像生命体般学习与演化的动态智能。
“为学习而生”的 AI 才刚刚起步。尽管挑战巨大,但前景非凡: 机器不仅会执行,还能进化——以智能所特有的创造力与灵活性,应对世界的无限变化。