](https://deep-paper.org/en/paper/2209.00840/images/cover.png)
引言
在大语言模型 (LLM) 时代,我们已经习惯了见证 AI 创造看似奇迹般的壮举。从通过律师资格考试到编写复杂的 Python 脚本,像 GPT-4 这样的模型似乎对世界有着深刻的理解。但在人工智能社区中,始终存在一个挥之不去的问题: 这些模型究竟是在进行推理,还是仅仅在做复杂的模式匹配?
当一个 LLM 回答问题时,它是遵循逻辑思维链——即从前提 \(A\) 和 \(B\) 推导出结论 \(C\)——还是仅仅在检索统计学上最可能出现的单词序列?
这种区别至关重要。如果我们要让 AI 在法律、医学或工程等高风险领域获得信任,它必须具备严谨的一阶逻辑 (First-Order Logic, FOL) 推理能力。它不能仅仅“感觉”答案是正确的;它必须能够演绎地证明这一点。
FOLIO 应运而生,这是一篇开创性的研究论文和数据集,旨在专门测试这一能力。与以往测试“模糊”推理或依赖简单合成数据的基准测试不同,FOLIO 引入了一个逻辑严密、由专家标注的数据集,旨在揭露现代 LLM 推理能力的短板。
在这篇文章中,我们将拆解 FOLIO 论文,探讨该数据集是如何构建的,并分析为什么即使是世界上最强大的模型也难以解开它的谜题。
现有基准测试的问题
要理解为什么需要 FOLIO,我们首先需要审视 AI 评估的现状。虽然有许多旨在测试“推理”的数据集,但它们通常会陷入两个陷阱:
- 缺乏自然性: 像 RuleTaker or ProofWriter 这样的数据集专注于演绎逻辑,但它们是人工合成生成的。它们使用的词汇量极小 (有时仅 100 个单词) 且句式重复。它们看起来像是披着文本外衣的数学题,这使得模型很容易在不理解真实语言的情况下“投机取巧”。
- 缺乏逻辑纯粹性: 像 ReClor 或 LogiQA 这样的数据集取自 LSAT 等考试。虽然语言自然,但其推理通常是“归纳性”的,或者依赖于外部常识知识。这使得很难分离出模型进行纯粹逻辑演绎的能力。
FOLIO 的作者清楚地强调了这些缺陷。他们希望创建一个既具语言多样性 (使用真实、复杂的英语) 又具逻辑严密性 (遵循严格的一阶逻辑) 的数据集。
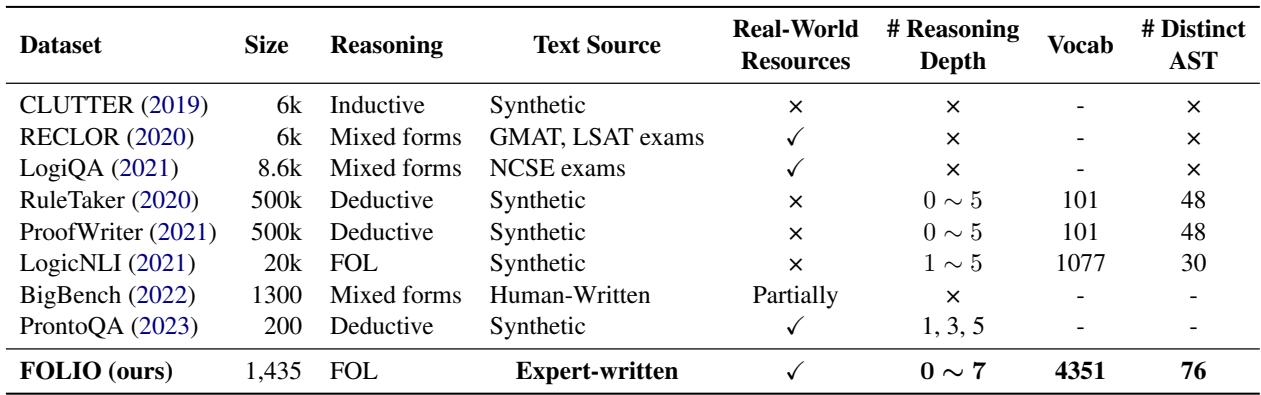
如表 1 所示,FOLIO 脱颖而出,它是第一个由专家编写的、结合了一阶逻辑 (FOL) 与大词汇量 (4,351 个单词) 及深度推理链 (高达 7 步) 的数据集。与其前身通常依赖简单的“如果 A 则 B”链条不同,FOLIO 引入了复杂的逻辑结构,涉及全称量词 (“所有”) 、存在量词 (“有些”) 、否定和析取 (“或”) 。
FOLIO 方法: 连接语言与逻辑
这篇论文的核心贡献是创建了 FOLIO 语料库本身。其目标是创建一组问题,模型在这些问题中会得到一个“故事” (一组前提) ,并必须确定结论是 True (真) 、False (假) 还是 Unknown (未知) 。
为了确保基本事实 (ground truth) 无可争议,研究人员不仅仅让路人标记数据。他们实施了一个并行标注系统,每一句自然语言句子都配有一个正式的一阶逻辑公式。
示例结构
让我们看一个数据集中的具体例子,来理解模型面临的挑战。
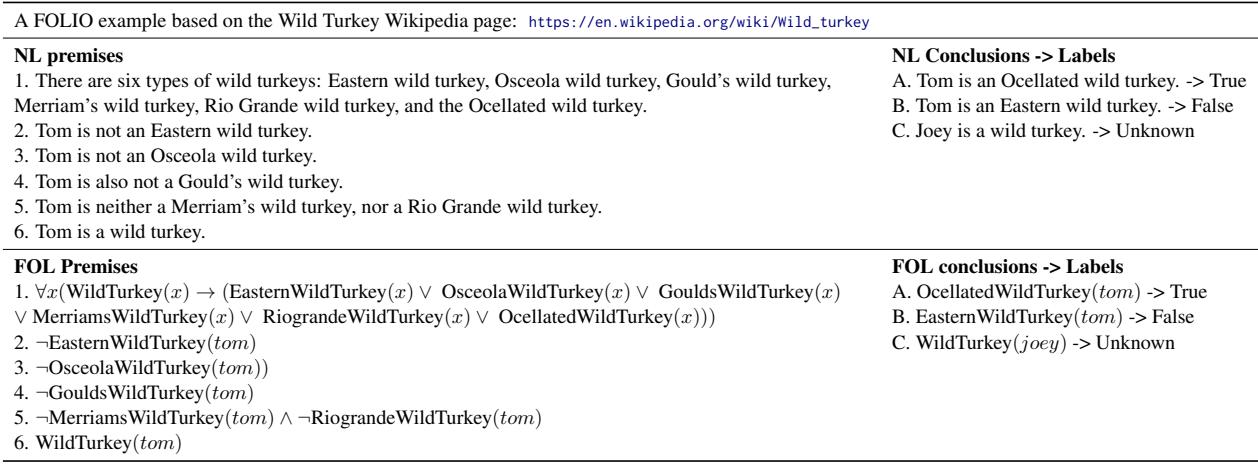
在表 2 中,我们看到一个关于野生火鸡的故事。
- 前提 (Premises) : 文本定义了这个世界。有六种特定类型的野生火鸡。我们被告知一只名叫 Tom 的火鸡。我们被明确告知 Tom 不是什么 (他不是 Eastern, Osceola, Gould’s 等) 。
- 逻辑 (Logic) : 这是一个经典的排除法过程 (析取三段论) 。如果 \(x\) 必须是 \(\{A, B, C, D, E, F\}\) 中的一个,而我们知道 \(\neg A, \neg B, \neg C, \neg D, \neg E\),那么逻辑上,\(x\) 必须是 \(F\)。
- 结论 (Conclusion) : “Tom is an Ocellated wild turkey.” (Tom 是一只眼斑火鸡。)
- 标签 (Label) : True (真) 。
关键在于注意 FOL Premises (FOL 前提) 这一列。研究人员将英语句子“Tom is not an Eastern wild turkey”映射为逻辑公式 \(\neg EasternWildTurkey(tom)\)。这种双重结构使得数据集可以通过数学方法进行验证。如果逻辑引擎表明结论可以从前提推导出来,那么标签在数学上就保证是正确的。
构建数据集: WikiLogic 和 HybLogic
创建这个数据集并非通过网络爬虫抓取就能完成。它需要高技能的劳动力——具体来说,是受过正规逻辑训练的计算机科学学生。团队花费了近 1,000 个工时,采用两种截然不同的策略来创建数据:
- WikiLogic: 标注者选取随机的维基百科文章,并根据现实世界的事实编写逻辑故事。这确保了语言的自然性并涵盖了多样化的主题。
- HybLogic (混合) : 这种方法从复杂的逻辑模板 (例如特定的三段论) 开始,然后用自然语言概念“填空”。这种方法被用来强行注入高度复杂的推理模式,这些模式在随机的维基百科文章中可能不会频繁出现。
深度的复杂性
FOLIO 的一个定义性特征是推理深度 。 这是指从前提推导到结论所需的逻辑步骤数量。
大多数以前的数据集在深度达到 5 时就止步了。FOLIO 将其推得更远。
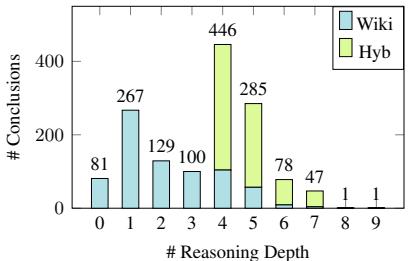
图 1 展示了这些深度的分布。虽然 WikiLogic 示例 (蓝色) 倾向于较短 (1-5 步) ,但 HybLogic 示例 (绿色) 引入了深层、曲折的推理链,达到 7 或 8 步。这种复杂性的“长尾”正是大语言模型往往会崩溃的地方。
实验
研究人员提出了两个主要任务来评估现代 AI:
- 逻辑推理: 给定自然语言前提,模型能否预测正确的标签 (真/假/未知) ?
- NL-FOL 翻译: 模型能否将英语文本翻译成有效的一阶逻辑代码?
他们测试了多种模型,范围从经过微调的“小”模型 (如 BERT 和 RoBERTa) 到庞大的 Logic-LM 系统,当然还有 GPT-3.5 和 GPT-4。
任务 1: 逻辑推理结果
结果发人深省。在一个我们期望 AI 具有超人能力的世界里,FOLIO 揭示了一个巨大的差距。

表 4 展示了主要的排行榜。以下是关键结论:
- 微调对小语境效果良好: 令人惊讶的是,微调后的 Flan-T5-Large (比 GPT-4 小得多的模型) 达到了 65.9% 的准确率。这表明如果你专门针对此类逻辑训练模型,它是可以学习这些模式的。
- GPT-4 不是完美的推理者: 开箱即用 (标准提示) ,GPT-4 得分为 61.3% 。 即使使用了像“思维链” (CoT) 这样的高级提示技术,它的得分也只在 68-70% 左右达到顶峰。
- 差距: 结合了 LLM 与外部代码求解器的专门神经符号方法 (如 Logic-LM) 将得分推高至 78.1% 。 然而,简单地要求 LLM 自己“想”通问题仍然容易出错。
推理深度的影响
为什么 GPT-4 的得分只有 60-70%?答案在于链条的复杂性。研究人员按推理深度分解了模型性能。
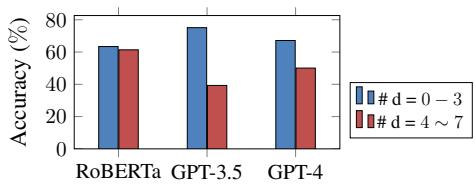
图 2 显示了一个清晰的趋势。当推理较浅 (\(d=0-3\)) 时,GPT-4 表现尚可 (超过 75%) 。但当问题要求在上下文中同时保持 4 到 7 个逻辑步骤时,性能骤降至接近 50%——几乎不比抛硬币好多少。这证实了虽然 LLM 能捕捉到表层逻辑,但它们难以在长演绎链中保持连贯性。
任务 2: NL-FOL 翻译
第二个任务要求模型充当翻译员: 将英语前提转换为 FOL 公式。如果模型能完美做到这一点,我们可以直接将公式输入逻辑求解器并获得 100% 的准确率。
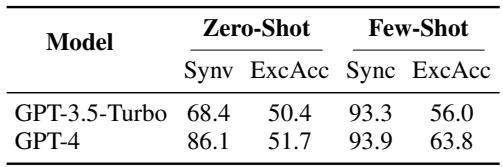
表 5 揭示了一个迷人的二分法:
- 句法有效性 (SynV) : GPT-4 非常擅长编写看起来正确的代码。它达到了 93.9% 的句法有效性。公式具有正确的括号、符号和语法。
- 执行准确率 (ExcAcc) : 然而,代码在语义上通常是错误的。当生成的公式通过逻辑引擎运行时,它们仅在 63.8% 的情况下得出正确答案。
这意味着模型理解逻辑的语法,但往往无法捕捉它正在翻译的英语句子的精确含义。
错误分析: LLM 错在哪里?
为了理解模型是如何失败的,作者对 GPT-4 的错误答案进行了人工评估。他们将错误分为四类。
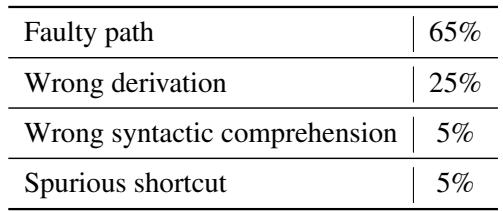
如表 7 所示,绝大多数错误 (65%) 被归类为 “Faulty Path” (路径错误) 。 这意味着模型开始推理时是正确的,但在链条中间的某个地方转错了弯。它失败不是因为它不懂单词 (句法理解错误仅占 5%) ;它失败是因为它无法维持演绎过程。
“真”的偏见
另一个有趣的发现是模型预测中的偏见。
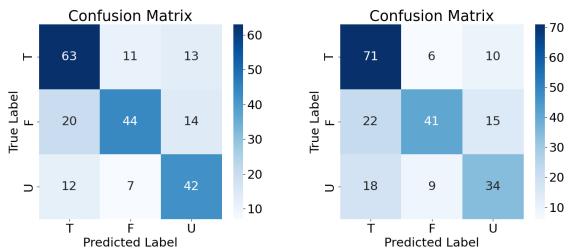
图 4 展示了混淆矩阵。你可以看到模型 (RoBERTa 和 GPT-4) 在识别 True (真) 结论方面比识别 False (假) 或 Unknown (未知) 结论要好得多。
这凸显了 LLM 的一个根本问题: 它们倾向于确认上下文中存在的信息。验证某事是 False (矛盾) 或 Unknown (缺乏信息) 需要对前提定义的“世界状态”进行更严格的检查,这对于 Transformer 的注意力机制来说似乎更难处理。
真实的失败案例
论文提供了案例研究来说明这些失败。

在 表 9 中,我们看到一个关于飞蛾和蝴蝶的 WikiLogic 例子。
- 逻辑: “飞蛾不是蝴蝶。” “Cerura vinula 是一种飞蛾。”
- 结论 A: “Cerura vinula 从茧中破壳而出。” (前提 3 说飞蛾从茧中破壳而出,而 CV 是飞蛾。所以, True )。
- 结论 B: “Cerura vinula 没有细触角。” (前提 2 说蝴蝶有细触角。我们知道 CV 不是蝴蝶。这是否意味着它没有细触角?不。非蝴蝶生物也可能有细触角。这是一个经典的逻辑谬误: 否定前件。答案应该是 Unknown )。
- 结果: GPT-4 错误地预测 B 为 True 。 它陷入了谬误,假设因为蝴蝶有特征 X,非蝴蝶一定没有特征 X。

表 10 展示了一个包含更复杂量化逻辑 (“所有员工都……”,“有些员工……”) 的混合示例。在这里,GPT-4 完全迷失了方向,预测结论 (B) 为“Unknown”,而根据前提,该结论明显是 False 。
结论
FOLIO 论文为 AI 行业提供了一次至关重要的现实检验。它证明了虽然大语言模型在人类语言方面表现流利,但它们还不是可靠的逻辑引擎。
这项研究的关键要点是:
- 语言 \(\neq\) 逻辑: 一个模型可以写出完美的英语 (或 Python) ,但在基本的演绎推理上仍然会失败。
- 复杂性至关重要: 模型在浅层推理 (1-3 步) 上表现良好,但随着逻辑链变长,性能迅速下降。
- 神经符号是未来: 最好的结果并非来自纯 LLM,而是来自结合了 LLM 与形式逻辑求解器的系统。这表明未来的路径可能涉及“混合”AI 系统,其中 LLM 处理翻译,而形式引擎处理推理。
FOLIO 提供了一个基准,确保我们不会将流利误认为是智能。在模型能够在没有外部帮助的情况下掌握“野生火鸡”问题或“Cerura Vinula”谬误之前,我们还没有真正解决推理问题。