](https://deep-paper.org/en/paper/2212.10618/images/cover.png)
如果你玩过像《上古卷轴: 天际》、《巫师》或《天外世界》这样的大型开放世界角色扮演游戏 (RPG) ,你就会知道,游戏的沉浸感很大程度上取决于你遇到的人。非玩家角色 (NPC) 是这些世界的生命线。他们给你发布任务,解释这片土地的历史,并对你的决定做出反应。
但是,创造这些互动极其昂贵。一款 3A 大作可能有数千个 NPC,每个 NPC 都需要独特的对话树,且这些对话必须与游戏传说 (Lore) 以及玩家当前的任务状态保持一致。这是一场后勤噩梦,需要耗费数百万美元和数年的写作时间。
这就引出了一个迷人的问题: 我们能否使用大型语言模型 (LLMs) 来自动化,或者至少辅助编写这些复杂的对话树?
在研究论文 “Ontologically Faithful Generation of Non-Player Character Dialogues” (非玩家角色对话的本体忠实生成) 中,来自约翰霍普金斯大学和微软的研究人员探索了这一前沿领域。他们介绍了一个新的数据集和一个建模框架,旨在生成的 NPC 对话不仅语法正确,而且是“本体忠实”的——这意味着它严格遵守游戏世界的事实。
程序化对话的问题
我们在游戏中应用程序化文本生成已经很久了,但历史上它一直很浅显。像 GPT-3 或 GPT-4 这样的现代 LLM 虽然流畅,但容易产生“幻觉”。在游戏语境下,幻觉是一个破坏游戏体验的恶性 Bug。如果一个 NPC 让你去一个不存在的城镇,或者声称自己是国王而实际上是个乞丐,玩家的沉浸感就会破碎。
为了在游戏开发中发挥作用,AI 模型必须处理三个特定的复杂性:
- 分支树: RPG 对话不是线性的对话;它们是具有多种玩家选择和结果的树状结构。
- 传说忠实度: NPC 必须体现特定的人设 (Persona) ,并了解世界的历史 (即本体,Ontology) 。
- 任务功能性: 对话有其职能——它必须向玩家传达具体的目标 (例如,“去琥珀高地找我的儿子”) 。
如下图所示,真实游戏中的信息流非常复杂。对话位于任务数据、特定游戏传说和玩家选择的交汇点。
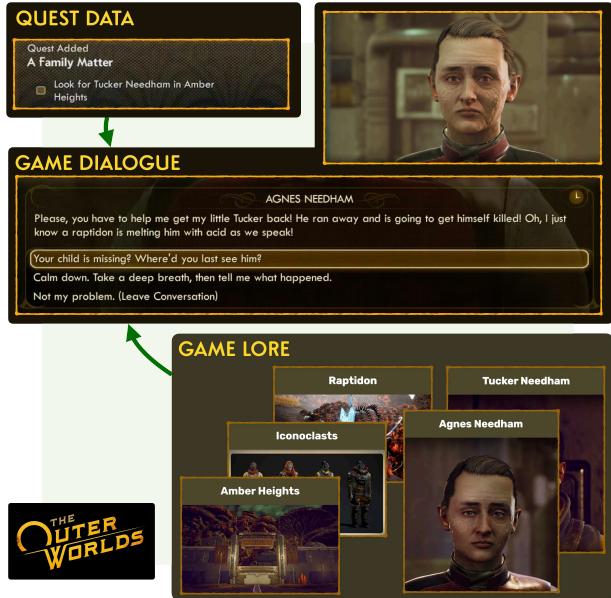
介绍 KNUDGE
这项研究的第一个主要贡献是一个名为 KNUDGE (KNowledge Constrained User-NPC Dialogue GEneration,知识约束下的用户-NPC 对话生成) 的数据集。
为了构建一个反映现实世界复杂性的数据集,研究人员没有模拟一个游戏;他们直接从源头取材。他们直接从黑曜石娱乐 (Obsidian Entertainment) 的热门 RPG 游戏《天外世界》 (The Outer Worlds) 中提取了对话树。这款游戏以其剧本写作、黑色幽默和复杂的分支叙事而闻名,是完美的测试平台。
任务剖析
KNUDGE 包含来自 45 个支线任务的 159 个对话树。但光有对话是不够的。研究人员将这些树与细粒度的本体约束配对。
对于每一个对话,数据集包括:
- 任务信息 (Q): 一个梗概、当前活跃的目标,以及描述对话中需要发生什么的“攻略段落”。
- 生平信息 (B): 关于涉及的角色、地点和团体的详细维基和传说条目。
这种结构模仿了人类编剧所拥有的资源: 一本游戏世界的“设定集”和针对特定任务的设计文档。
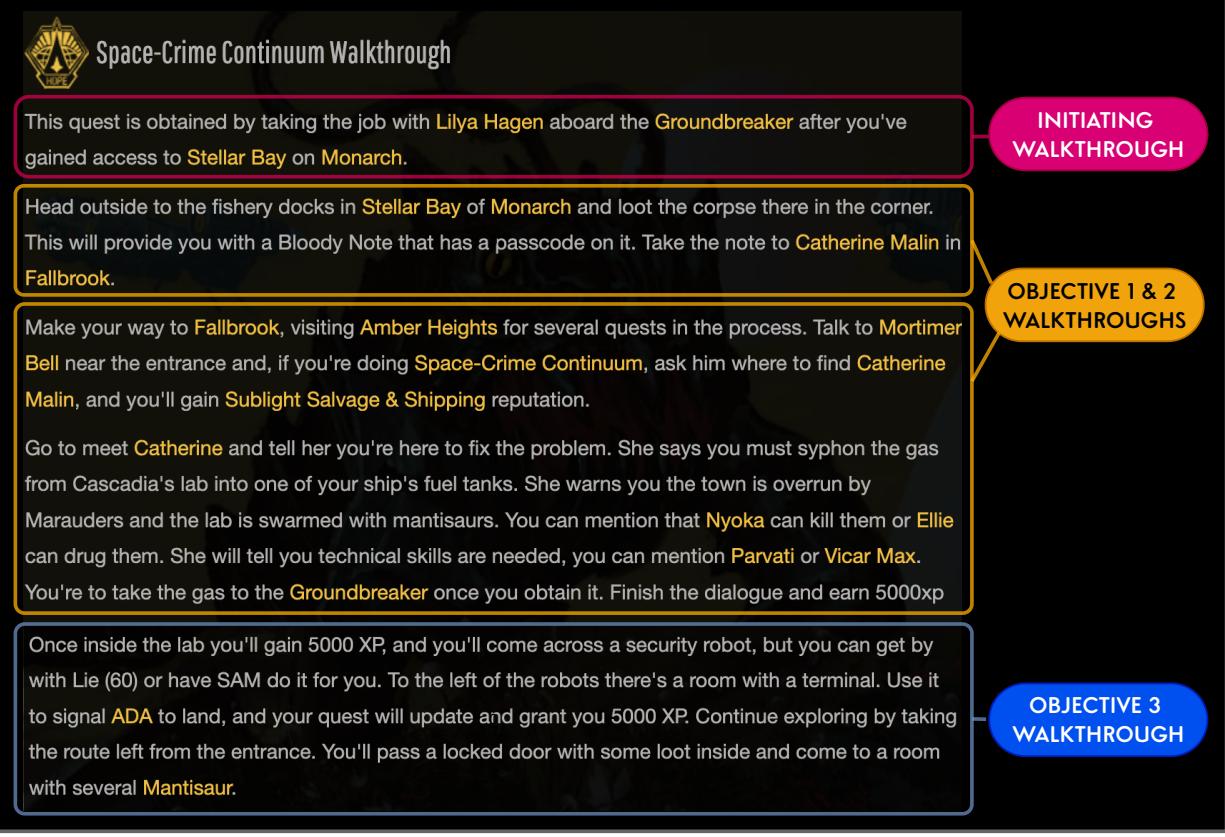
如上图 6 所示,约束非常详细。模型不仅仅被告知“写一个关于失踪人口的任务”。它被赋予了必须在最终文本中体现的具体日志条目和攻略步骤。
标注对话树
研究人员更进一步,对对话树的单个节点进行了标注。他们使用了一种基于反事实的启发式方法: 如果某条特定的传说不存在,这句对话还有意义吗?
这使得数据集能够将对话中的特定句子映射回支持它们的具体传说事实。
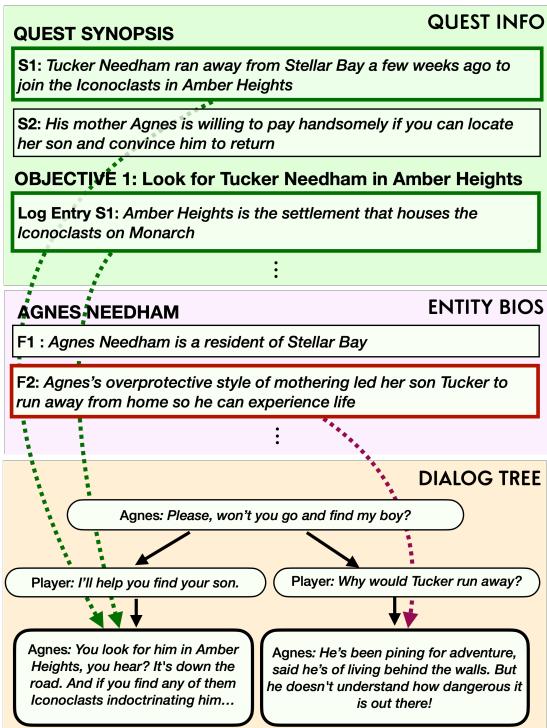
在图 3 中,请注意对话选项 (底部的树) 是如何直接链接到“实体生平”和“任务梗概”中的具体事实的。这种映射对于训练模型准确使用信息而不是编造事实至关重要。
方法: DialogueWriters
有了手头的数据,研究人员开发了一套神经方法,称之为 DialogueWriters 。 DialogueWriter 的目标是获取游戏状态 (任务数据 Q、生平数据 B 和参与者列表 P) 以及当前的对话历史,并为 NPC 生成下一个潜在的回复。
非线性的挑战
标准语言模型是从左到右阅读文本的。它们期望线性的序列。然而,对话树是分支图 (有时包含循环/回路) 。
为了解决这个问题,研究人员使用了树线性化技术。当训练模型预测特定节点时,他们通过追踪从对话开始到当前点的路径来“压平”历史记录。这将一个复杂的图问题转化为 Transformer 可以处理的序列到序列问题。
两种方法: 监督学习 vs. 上下文学习
论文比较了训练这些编写器的两种主要方法:
- 监督学习 (SL): 微调一个 T5-large 模型。这涉及在 KNUDGE 数据集上专门更新神经网络的权重。
- 上下文学习 (ICL): 使用 GPT-3 。 研究人员不重新训练模型,而是将任务
Q和生平B数据以及一些对话应有的样貌示例放入一个巨大的提示词 (Prompt) 中。
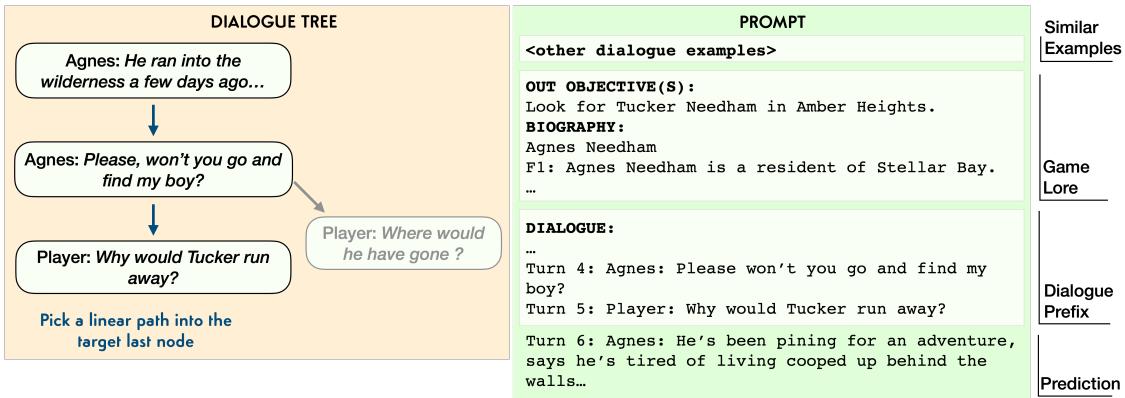
图 5 展示了提示策略。提示词创建了一个包含类似示例、相关游戏传说和对话前缀 (历史) 的“上下文”。然后要求模型预测下一行。
知识选择 (KS)
这里的一个关键创新是知识选择 (KS) 。
在一个朴素的方法中,你可能会把所有的传说都丢进模型里,然后祈祷它能表现好。然而,这通常会混淆模型或导致它忽略约束条件。
KS 模型被设计为执行两步过程:
- 选择: 首先,准确识别传记或任务描述中的哪一事实与当前回合相关。
- 生成: 然后,专门以该选定事实为条件编写对话行。
这迫使模型“展示其工作依据”,并确保生成的对话是基于具体游戏数据的。
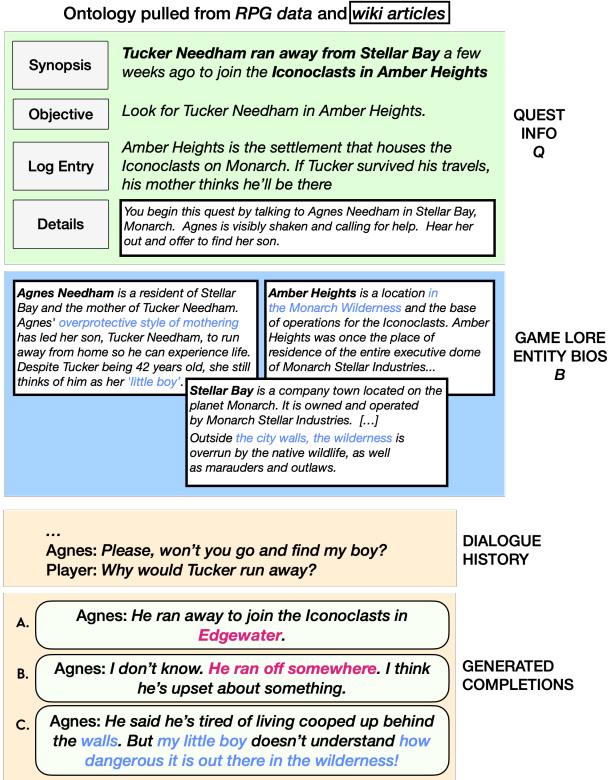
图 2 演示了为什么这是必要的。“补全 A”与传说相矛盾 (地点错误) 。“补全 B”通用且乏味。“补全 C”是目标: 它推进了任务,并且引用了关于“Iconoclasts” (偶像破坏者/无政府主义者) 和“wilderness” (荒野) 的具体传说。
实验与结果
那么,AI 能像专业游戏设计师一样写作吗?研究人员使用自动化指标 (如 BLEU 分数,衡量与人类参考文本的词重叠度) 和严格的人工评估对此进行了测试。
定量分析
自动化指标突显了创造性生成的一个难点: “黄金”参考 (人类编剧实际写的内容) 只是表达某事的一种有效方式。模型经常写出有效的句子,只是与人类编剧的具体用词不匹配,导致分数较低。
然而,数据显示 上下文学习 (GPT-3) 总体上优于微调后的 T5 模型。
人工评估
由于自动化指标在创意写作方面不可靠,研究人员聘请了人工评估员根据四个标准对生成的对话进行评分:
- 连贯性 (Coherence): 对话流程自然吗?
- 违规 (Violation): 它是否与传说相矛盾?
- 生平使用 (Biography Usage): 它是否使用了角色的背景故事?
- 任务使用 (Quest Usage): 它实际上推进了任务吗?
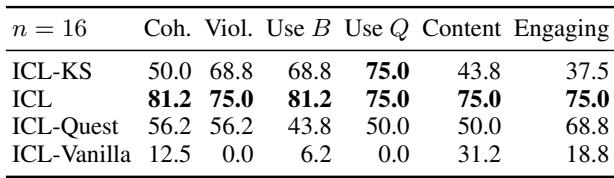
表 5 显示了成对比较 (头对头胜率) 。结果很有启发性:
- ICL (GPT-3) 占据主导地位: 在连贯性和内容建议方面,它优于其他方法。
- 知识选择 (KS) vs. 矛盾: 有趣的是,强制进行知识选择 (直接复制事实) 的模型在“无违规”方面的评分有时略低。为什么?因为有时强行将复杂的事实塞进句子里,会导致相比标准 ICL 模型更流畅、自由的生成来说,产生笨拙或略显不准确的陈述。
“灵魂”差距
最定性的发现是“人设” (persona) 上的差距。
虽然 AI 模型可以生成连贯、事实正确的对话,但它们往往难以捕捉角色独特的“声音”。在《天外世界》中,一个 NPC 可能是一个受惊的、过度保护的母亲,或者是一个愤世嫉俗、憎恨公司的叛军。
- 黄金 (人类) : “几天前他跑进了荒野。我警告过他关于龙形兽、螳螂兽和掠夺者的事……但他就是不听!” (情绪高昂,列举具体的怪物) 。
- AI 模型: “他几周前离开了。说是要去琥珀高地……我就知道他如果不小心会害死自己的。” (功能性强,准确,但较平淡) 。
案例研究: 生成完整的对话树
为了观察模型如何处理终极挑战,研究人员让它们仅根据约束条件从头开始生成一个完整的 10 轮对话树。
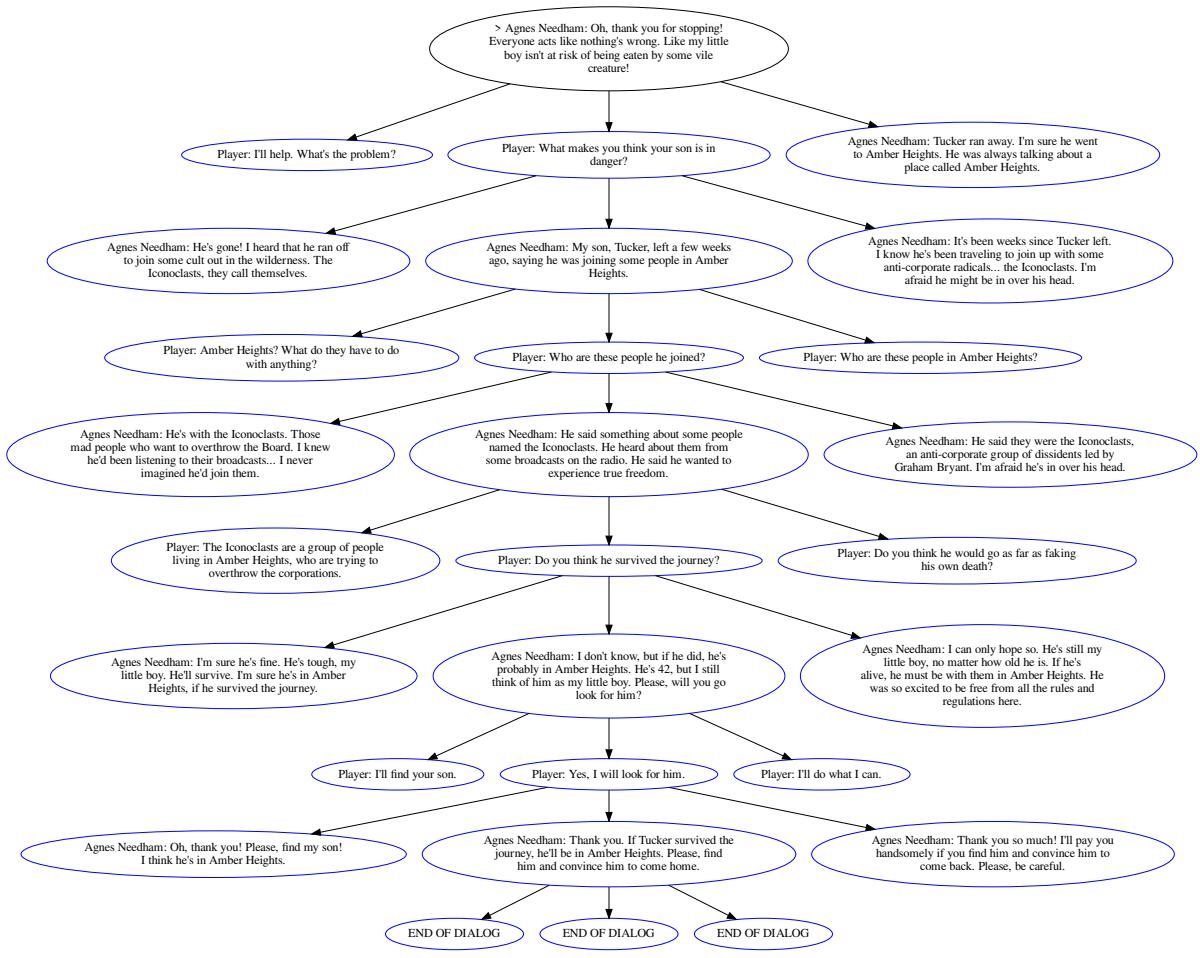
图 16 显示了一个 AI 生成的树的示例。它成功地根据玩家的输入进行分支,并保持了任务的上下文 (Agnes 寻找她的儿子 Tucker) 。它达成了一个合乎逻辑的结局,即玩家接受了任务。
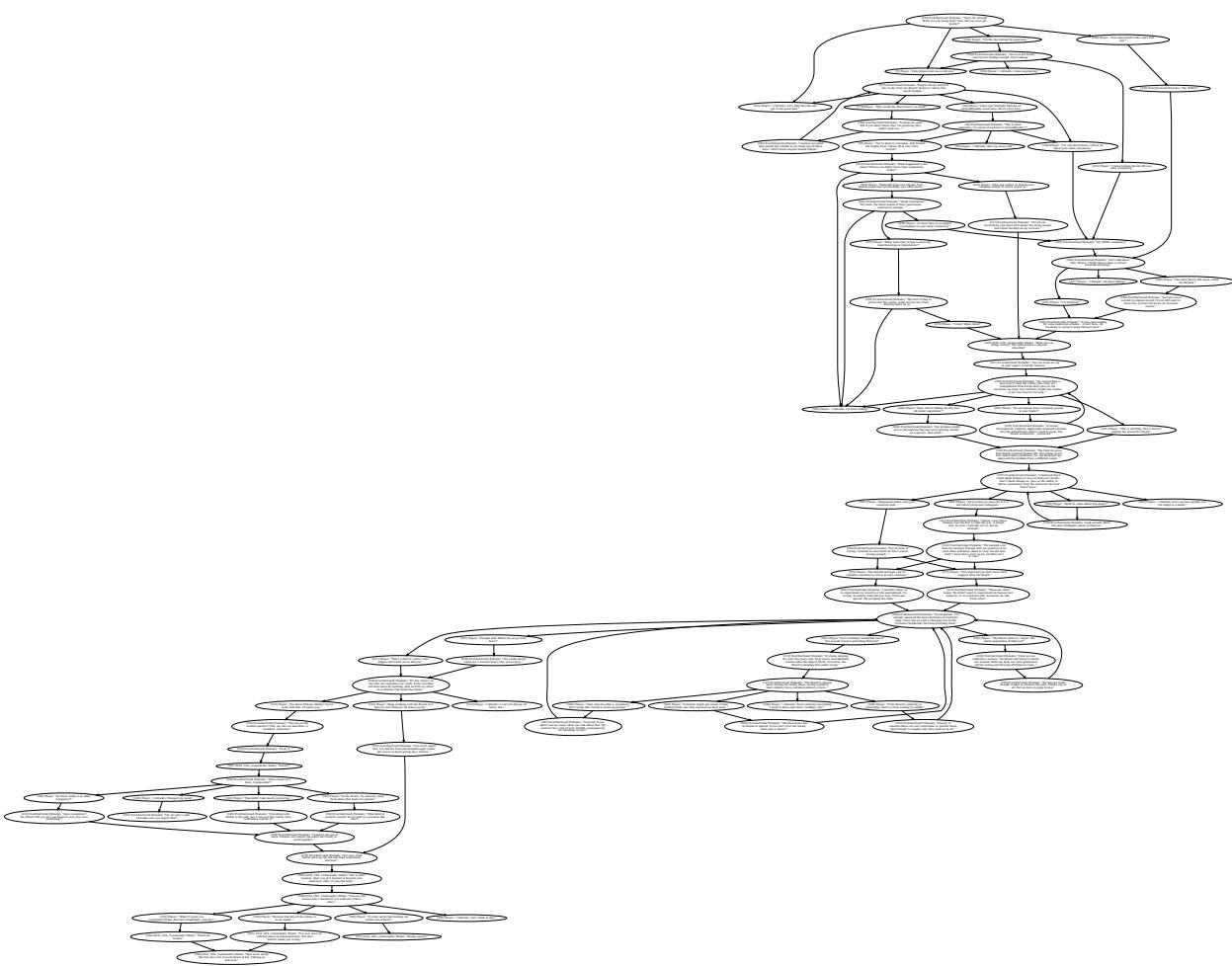
虽然令人印象深刻,但其结构仍然比实际游戏中手工制作的错综复杂的网络 (见下图 12) 要简单。真实的游戏树具有复杂的循环、技能检定 (例如,“需要工程学 50”) 和独特的由情绪转变,这些是当前模型尚未完全掌握的。
结论与未来启示
KNUDGE 数据集是对游戏领域 AI 的一次现实检验。它将目标从“AI 能写一个句子吗?”转移到了“AI 能在复杂的分支叙事中保持一致的现实吗?”。
研究结果表明,我们还没有达到按下一个按钮就能生成年度最佳游戏 (GOTY) 级别剧本的地步。AI 缺乏专业作家的文体天赋和情感深度。然而, DialogueWriter 模型证明了 AI 可以成为一个强大的副驾驶 。
想象这样一个工具: 游戏设计师勾勒出任务的“节拍” (本体) ,AI 建议十几种对话树的变体,处理分支逻辑并确保不与传说相矛盾。然后,编剧对对话进行润色,注入必要的个性。这种“人在回路”的工作流程可以大大降低开发成本,从而允许创造比以往更大、更丰富、反应更灵敏的世界。
对于自然语言处理 (NLP) 和游戏设计的学生来说,这篇论文强调了未来不仅仅在于更大的模型;而在于将这些模型锚定在结构化知识 (本体) 中,以确保它们遵守它们正在协助构建的世界的规则。