](https://deep-paper.org/en/paper/2305.14341/images/cover.png)
科学界存在沟通难题。虽然研究人员正以前所未有的速度取得突破,但由此产生的论文往往晦涩难懂、充满术语,令普通大众望而却步。这种鸿沟催生了平实语言摘要 (Plain Language Summarization, PLS) 的任务——将复杂的科学摘要重写为非专业人士也能理解的清晰、易懂的语言。
随着大型语言模型 (LLMs) 的兴起,自动化这一过程似乎触手可及。但这里有一个陷阱: 我们如何知道一份摘要是否真的“平实”?
自然语言处理 (NLP) 中使用的标准指标 (如 ROUGE 或 BLEU) 旨在匹配单词重叠,而不是衡量文本的易读性或是否正确解释了技术术语。为了解决这个问题,来自伊利诺伊大学厄巴纳-香槟分校、亚利桑那大学、华盛顿大学和艾伦人工智能研究所的研究团队开发了 APPLS 。
在这篇文章中,我们将深入探讨他们的论文,了解他们如何构建一个“元评估”测试平台来给评分者打分,以及他们的发现对 AI 文本评估的未来有何启示。
问题所在: 当指标抓不住重点时
要理解为什么我们需要 APPLS,我们首先需要看看目前是如何对 AI 摘要进行评分的。
传统上,如果你想看看一个 AI 模型是否擅长总结,你会将其输出与人类编写的“金标准”进行比较。像 ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 这样的指标只是简单地计算 AI 文本和人类文本之间有多少 n-gram (单词序列) 重叠。
然而,平实语言摘要是多层面的。它涉及:
- 简化 (Simplification) : 用简单的词语替换复杂的词语。
- 解释 (Explanation) : 添加背景信息 (如定义) 。
- 去除术语 (Jargon Removal) : 删减不必要的技术细节。
AI 可能会写出一个完全准确且非常简单的摘要,但如果它使用的词语与人类参考文本不同,ROUGE 就会给它打低分。反之,AI 可能会逐字逐句地复制复杂的摘要。ROUGE 可能会因为重叠度高而给它高分,即使 AI 根本没有进行任何简化。
研究人员意识到,要推动该领域的发展,我们需要对 PLS 的特定细微差别敏感的指标。
APPLS 方法论: 指标的测试平台
研究人员推出了 APPLS , 这是一个细粒度的元评估测试平台。其目标不是评估摘要模型,而是评估评估指标本身 。
为此,他们确定了优秀的 PLS 指标必须捕捉的四个关键标准:
- 信息量 (Informativeness) : 摘要是否涵盖了主要发现和方法?
- 简化度 (Simplification) : 语言是否通俗易懂?
- 连贯性 (Coherence) : 文本是否逻辑通顺?
- 忠实度 (Faithfulness) : 与源文本相比,摘要在事实层面是否准确?
构建“Apples”
如果你不知道正在测量的文本的真实质量基准,你就无法测试一个指标。研究人员需要一个受控环境,在这里他们确切地知道摘要哪里出了问题,以观察指标是否能捕捉到这些问题。
他们从 CELLS 数据集开始,这是一个包含科学论文及其对应平实语言摘要的集合。
为了创建测试平台,他们遵循了下图所示的一个巧妙流程:
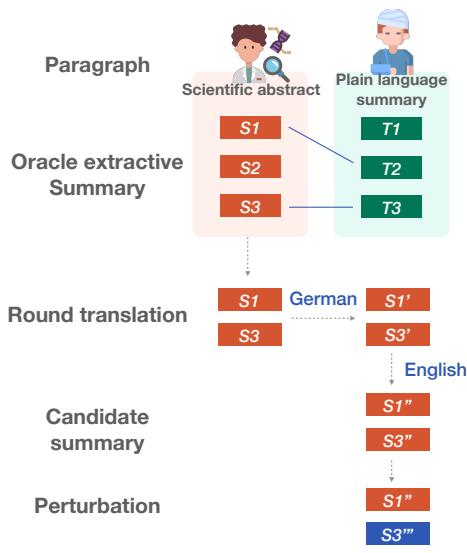
- 抽取 (Extraction) : 他们从科学摘要中提取最相关的句子。
- 回译 (Round-Trip Translation, RTT) : 为了创建一个听起来自然但不仅仅是直接复制的“候选摘要”,他们将英文文本翻译成德文,然后再翻译回英文。这在保持含义不变的同时引入了词汇变化。
- 扰动 (Perturbation) : 这是核心创新点。他们系统地利用 11 种不同类型的错误 (扰动) 在四个标准维度上“破坏”这些候选摘要。
扰动方式
研究人员对文本应用了特定的更改 (扰动) ,并检查指标是否做出了适当的反应。如果一个指标擅长衡量连贯性 , 当你打乱句子顺序时,它的分数应该下降。如果它衡量的是忠实度 , 当你替换数字时,分数应该大幅下跌。
以下是他们破坏文本的方式:
- 信息量: 他们删除句子或从其他领域添加不相关的句子 (幻觉) 。
- 简化度: 他们使用 GPT-4 来简化文本。一个对简化敏感的指标应该随着文本变得更简单而出现分数变化。
- 连贯性: 他们随机重新排序句子。
- 忠实度: 他们引入了细微但危险的错误:
- *数字替换: * 将“5900 万”改为“6400 万”。
- *实体替换: * 将特定的病毒名称替换为另一个。
- *动词替换: * 将“感染 (infected) ”改为“拯救 (saved) ” (反义词替换) 。
结果: 指标表现如何?
研究人员测试了 14 种指标,包括标准重叠指标 (ROUGE, BLEU) 、基于模型的指标 (BERTScore) 、文本简化指标 (SARI) ,甚至包括基于 LLM 的评估 (让 GPT-4 对文本评分) 。
如下图所示,结果揭示了一个混乱的局面,没有单一指标能在所有方面胜出。
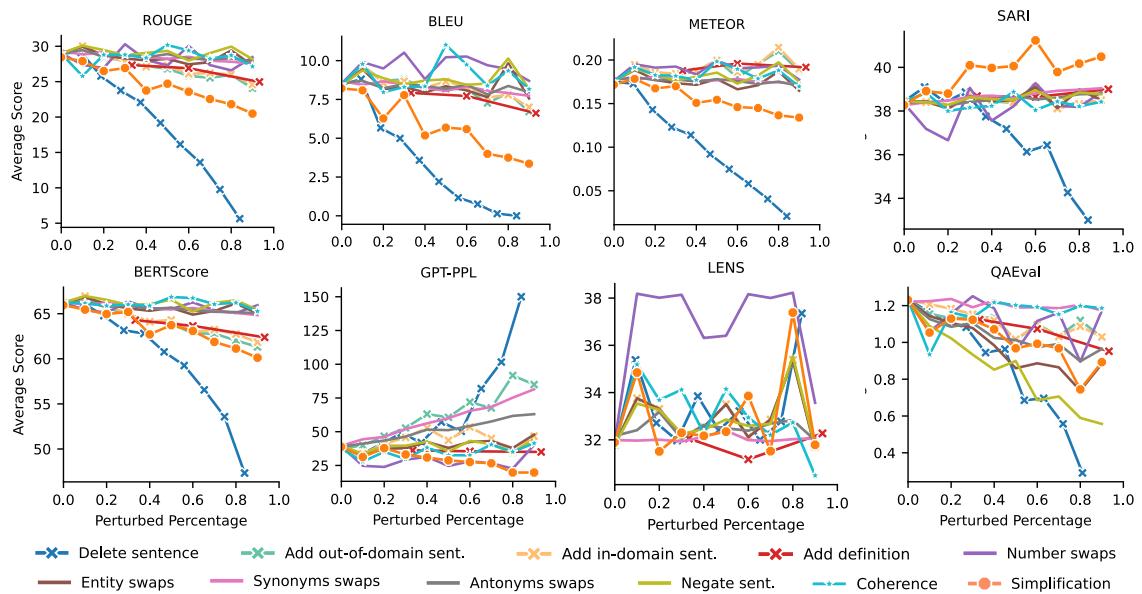
1. 简化的盲区
最惊人的发现是标准指标在处理简化方面的表现有多差。
看上图中的 SARI 曲线 (唯一在简化类别中呈上升趋势的线) 。SARI 是专门为文本简化设计的指标。它奖励模型保留好的词、删除坏的词并添加新的简单词。随着文本变得更简单,它是唯一一个分数持续提高的自动指标。
相比之下,看看 ROUGE、BLEU 和 BERTScore。随着文本变得更加简化 (客观上更适合外行读者) ,这些分数反而下降了。因为简化后的文本看起来不太像原始的复杂参考文本,这些指标就对其进行惩罚。
研究人员通过“交换”实验证明了这一点。他们分别计算了从复杂到简单和从简单到复杂的得分。一个好的简化指标应该对这两个方向有不同的反应。
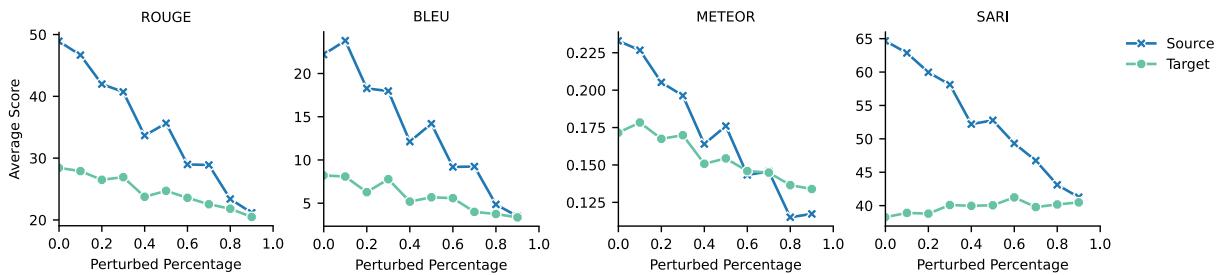
如图 13 所示,无论方向如何,ROUGE 和 BLEU 都会下降。它们只是测量相似度,而不是简单度。这证实了标准摘要指标从根本上不适合衡量摘要的“平实”程度。
2. 词汇特征: 可靠的信号
如果复杂的指标失效了,简单的统计数据呢?研究人员查看了词汇特征——计算动词、名词、句子长度和单词稀有度。
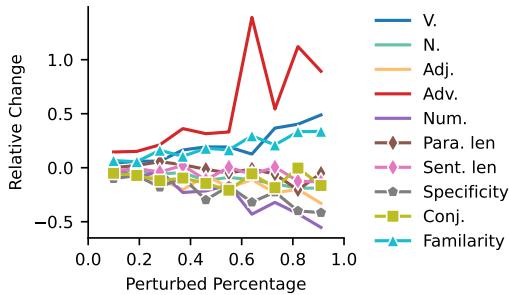
结果与语言学理论一致:
- 随着简化程度增加, 句子长度 (Sent.len) 减少。
- 副词 (Adv.) 和 动词 (V.) 增加。
- 名词 (N.) 和 特异性 (Specificity) 减少。
有趣的是, 连词 (Conjunctions) (如“因此”或“然而”) 减少了。虽然一些文献认为连词有助于流畅性,但在 PLS 中,较短的句子通常意味着切断复杂的复合句,从而导致连词减少。这些简单的特征被证明是衡量简单度的稳健指标。
3. LLM 能给自己打分吗?
最后,团队调查了“LLM 即裁判 (LLM-as-a-Judge) ”。他们将摘要输入给 GPT-4,并附上定义四个标准的提示,要求其对文本进行 0 到 100 的评分。
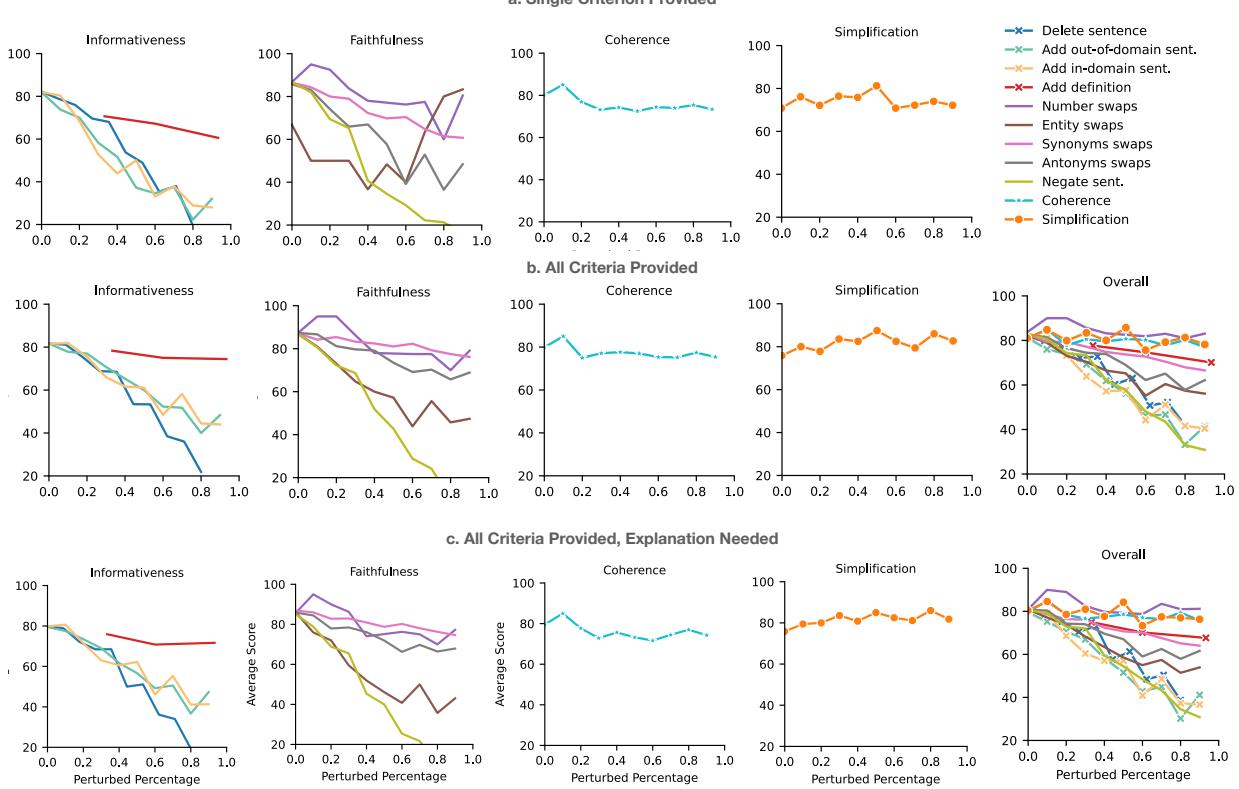
结果 (图 4) 很有希望但喜忧参半:
- 优势: GPT-4 对信息量 (检测删除的句子) 和忠实度 (注意幻觉) 很敏感。它也能相当好地跟踪简化度 。
- 劣势: 它在连贯性方面很吃力。即使句子被大幅打乱,LLM 的评分也没有像预期那样急剧下降。
研究人员还发现,要求 LLM 在评分的同时提供解释并没有显着提高相关性。然而,在一个提示中提供所有标准 (图表中的设置 ‘b’) 通常比逐个询问更高效、更有效。
结论与建议
APPLS 的创建为 PLS 评估提供了首个全面的“压力测试”。对于学生和研究人员来说,启示很明确: 不要依赖单一的分数。
如果你正在构建一个向公众总结科学内容的系统:
- 使用 SARI 来衡量简单度。它是唯一真正理解这项任务的自动指标。
- 使用 QAEval 或基于 LLM 的评分来检查忠实度。你不能让医疗摘要出现幻觉。
- 使用词汇特征 (如句子长度和常用词百分比) 作为可读性的合理性检查。
- 避免使用 ROUGE/BLEU 来衡量简化质量。它们用于检查内容重叠还可以,但它们会因为你的模型使用了更简单的词汇而惩罚它。
APPLS 框架表明,评估生成内容与生成本身一样困难。通过使用受控扰动——故意破坏事物——我们可以更好地理解我们的指标实际看到了什么,确保当我们说一个摘要是“平实语言”时,它是名副其实的。