](https://deep-paper.org/en/paper/2309.08600/images/cover.png)
像 GPT-4 这样的大语言模型 (LLM) 展现了惊人的能力,但一个根本性问题依然存在——它们究竟是如何工作的? 我们可以看到它们的输入和输出,但其预测背后的内部推理过程却深埋在数十亿个参数之中。这种不透明性是构建安全、公平和可信系统的主要障碍。如果我们不理解模型为什么会做出某个决定,又如何纠正或防止有害行为呢?
打开这个“黑箱”的一个关键难题是一种被称为多义性 (polysemanticity) 的现象。即一个神经元可能会对多个不相关的概念产生激活。例如,同一个神经元可能同时响应“国王”这个词、一张狮子的图片以及一段 Python 代码。试图通过单个神经元来解释模型,就像试图通过查看构成数千个不同单词的单个字母来理解一部小说一样——令人困惑。
研究人员认为,多义性源于叠加 (superposition) ——即神经网络表示的独立特征数量多于它拥有的神经元数量。为了解决这个矛盾,模型会将多个特征编码到高维激活空间中的方向上,而不是每个神经元只对应一个特征。一个概念可能被表示为分布在多个神经元上的特定激活模式。
这正是最近的论文 《稀疏自动编码器在语言模型中发现高度可解释的特征》 取得突破的地方。作者提出了一种无监督方法来解开这些叠加的特征。通过使用稀疏自动编码器 , 他们学习了一个底层特征的“字典”,从神经元视角进一步出发,揭示出模型理解的真实构建模块。结果是: 这些特征的可解释性显著提升,并且与模型的行为紧密对应——为实现真正的透明度开辟了新的途径。
从纠缠的神经元之网到特征字典
为了理解复杂系统,我们必须将其分解为基本组成部分。在 LLM 中,这些组成通常是神经元——但神经元受制于多义性问题。本研究的目标是找到更好的分析单元: 一个由单义性特征 (monosemantic features) 组成的字典,其中每个特征对应一个单一、可被人理解的概念。
其方法的基础是稀疏字典学习 (sparse dictionary learning) , 这是信号处理和神经科学中的经典思想。它假设任何复杂信号——这里指语言模型的内部激活——都可以由字典中极少数元素的组合重构而成。
例如,描述颜色“赭色 (burnt sienna) ”时,你可以给出 RGB 数值 (精确但对人难以直观理解) ,或者说“主要是红色,带一点黄色和黑色”。稀疏字典学习采用的是第二种方式: 用少量简单元素组合出复杂整体。
团队将这一原则直接应用于语言模型的激活。他们利用稀疏自动编码器学习出一个高层次特征字典,如下图所示。
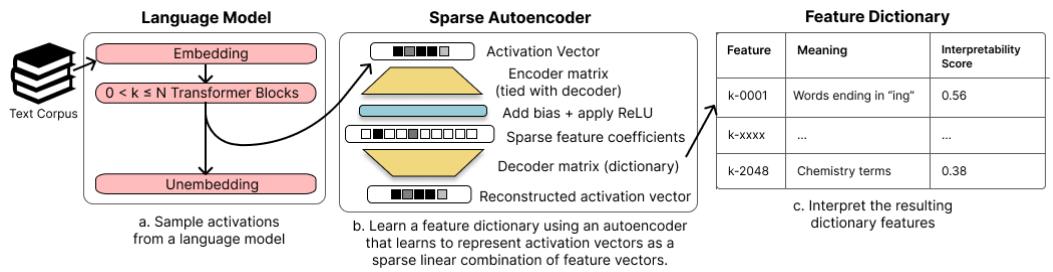
图 1: 作者从语言模型中采样激活值,训练稀疏自动编码器以学习特征字典,并借助自动化方法解释得到的特征。
核心机制: 用稀疏自动编码器学习特征
自动编码器 (autoencoder) 是一种神经网络,由两部分组成——一个用于压缩输入数据的编码器和一个用于重构数据的解码器。关键在于训练过程中稀疏性如何被约束。
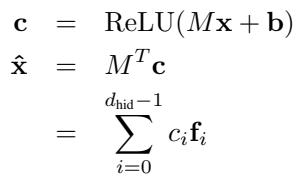
图 2: 稀疏自动编码器将激活值编码为稀疏的特征系数,并将其重构为所学字典特征的加权和。
直观解释如下:
- 输入向量 \( \mathbf{x} \): 来自 Transformer 层的激活样本。
- 编码器矩阵 \( M \): 其每一行充当一个特定特征的检测器。
- 偏置 \( \mathbf{b} \): 在激活前增加偏移项。
- 系数 \( \mathbf{c} = \operatorname{ReLU}(M\mathbf{x} + \mathbf{b}) \): 特征激活的稀疏向量——大多数值为零。
- 解码器 \( M^T \): 编码器的转置。每一列 \( \mathbf{f}_i \) 是一个学习到的字典特征。
- 重构 \( \hat{\mathbf{x}} = M^T\mathbf{c} \): 字典特征的稀疏线性组合,用以逼近原始激活。
训练过程需同时优化两个相互竞争的目标:
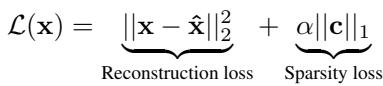
图 3: 自动编码器的损失函数结合了确保保真度的重构项和促进简洁性的稀疏项。
- 重构损失 \( \|{\mathbf{x}} - \hat{{\mathbf{x}}}\|_{2}^{2} \): 鼓励网络准确重建输入。
- 稀疏损失 \( \alpha \|{\mathbf{c}}\|_{1} \): 惩罚活跃特征数量。超参数 \( \alpha \) 平衡精度与简单性。
这种机制促使解码器特征成为有意义且相互独立的方向——一组能够解释数据的最小构建单元。
这些特征是否可用且可解释?
为了评估可解释性,作者需要一个可扩展、客观的度量标准。他们采用了 OpenAI 的自动解释 (auto‑interpretation) 协议 (Bills 等,2023) ,该方法借助 LLM 自身来判断一个特征的行为是否易于理解。
具体流程如下:
- 找出特征强烈激活的文本片段;
- 让 GPT‑4 描述该特征的检测模式;
- 让 GPT‑3.5 根据该描述在新文本上模拟该特征激活;
- 测量预测激活与实际激活的相关度——即可解释性分数 。
示例特征描述和得分如下图所示。

表 1: Pythia‑70M 模型残差流中的字典特征样本及 GPT‑4 生成的描述与自动可解释性得分。
与 PCA、ICA 或原始神经元基等其他分解技术相比,稀疏自动编码器取得了显著优势。
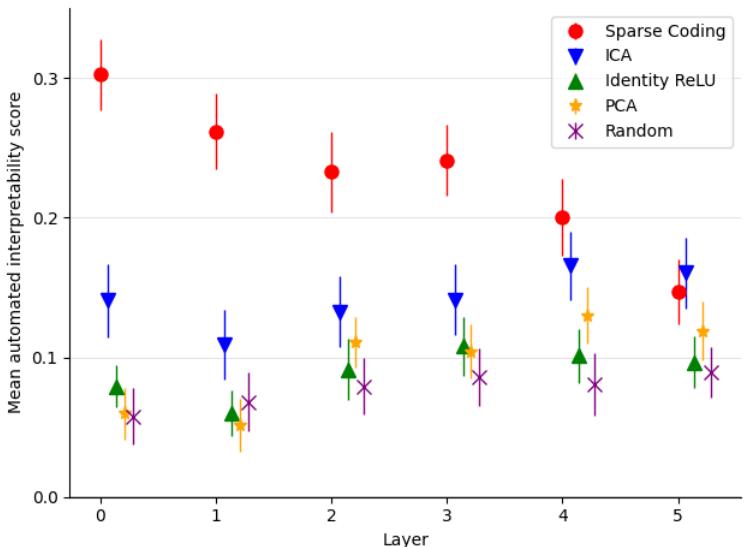
图 4: 各层平均自动可解释性得分。稀疏编码在几乎每一层都达到最高可解释性。
结果显示: 稀疏特征的可解释性显著高于标准方法发现的特征,表明它们捕捉到了模型内部更真实的语义结构。
精确定位模型计算中的因果行为
可解释性是一回事, 因果性 (causality) 则是另一回事。这些特征是否真的驱动了模型的行为?
作者使用一个经典任务进行验证: 间接宾语识别 (Indirect Object Identification,IOI) 。 给定句子: “Then, Alice and Bob went to the store. Alice gave a snack to ____,” 模型应预测“Bob”。
他们采用激活修补 (activation patching) 这一因果干预方法,研究如何沿着这些学习到的特征方向修改内部激活,从而影响输出预测。
- 基础运行 (Base run) : 模型预测“Bob”。
- 目标运行 (Target run) : 将“Bob”替换为“Vanessa”。
- 修补运行 (Patching run) : 在基础输入上重新执行,但在选定层,将部分激活替换为目标运行对应特征的激活值。
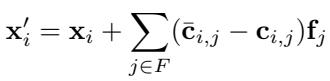
方程: 修补后的激活 \( \mathbf{x}' = \mathbf{x} + \sum_{j \in F} (\hat{\mathbf{c}}_j - \mathbf{c}_j)\mathbf{f}_j \) 沿着选定特征方向修改了内部表示。
修补效果通过模型在修补版与目标句子上的输出分布之间的 KL 散度 (KL divergence) 来衡量。
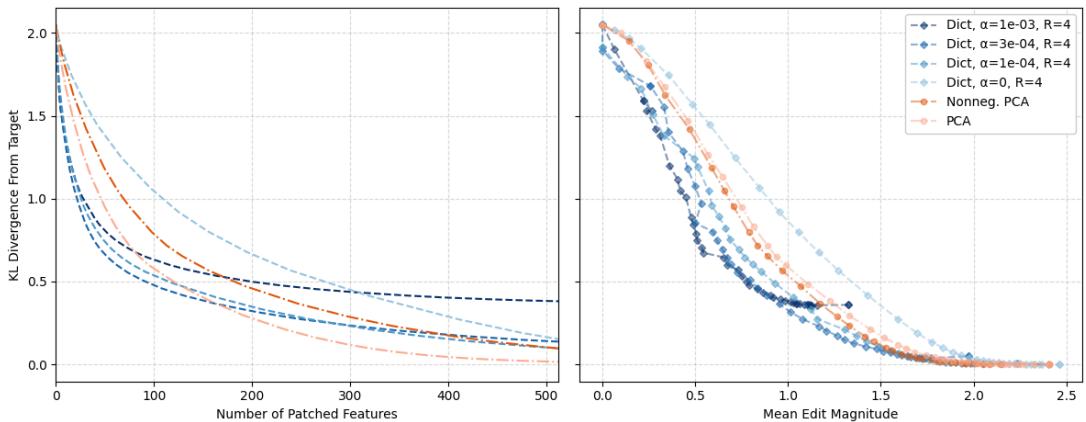
图 5: 稀疏字典相比 PCA,在实现等效因果编辑时所需修补的特征更少,编辑幅度也更小。
稀疏特征让干预更为精确——以更少的特征和更小的调整就能实现相同的行为变化。它们清晰地隔离出驱动特定任务的特征方向,证明了这些方向在模型内部具有真实的因果意义。
探秘内部: 单个特征的案例研究
除了总体指标外,论文还展示了若干单个字典特征,以说明其单义性 (monosemanticity) ——每个特征代表一个清晰且可理解的概念。
一个“撇号”特征
一个有趣的例子是几乎只在撇号处激活的特征。
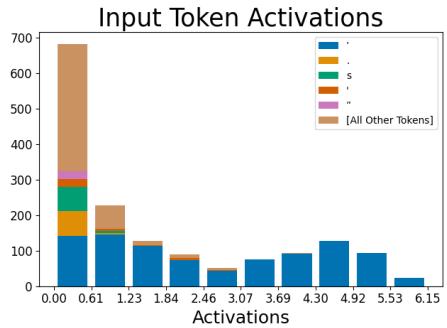
图 6: 左图——激活几乎完全集中在撇号 token 上。右图——消融此特征后,模型对紧随其后的 “s” token 的预测显著下降。
当研究者移除此特征时,模型生成“’s”的概率降低——这完全符合它在所有格和缩略词中的语言作用。这证明了内部表示与输出行为之间存在清晰、可理解的因果对应关系。
自动发现电路
论文最令人激动的部分之一是稀疏特征可用于揭示电路 (circuits) ——跨层交互的特征链。
研究团队锁定了一个会预测右括号“) ”的特征。通过系统地对前一层特征进行消融并测量对目标激活的影响,他们构建出因果依赖图。
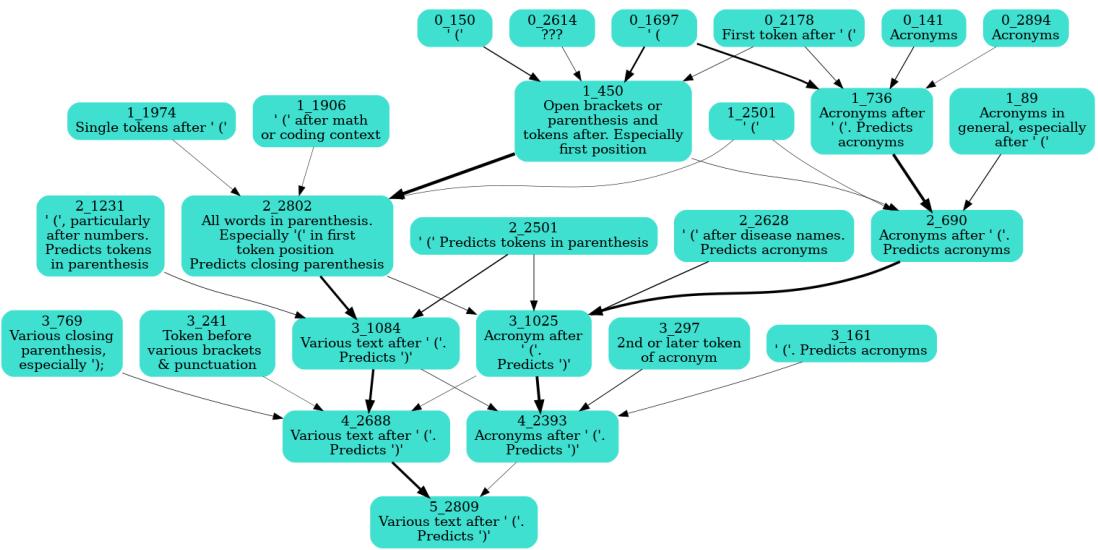
图 7: 自动发现的“右括号”特征电路。早期层检测左括号或缩略词,后期层整合信号以预测右括号。
这一电路与人类推理如出一辙: 第 0 层识别“(”,中间层分析括号内的文本,最后一层预测“)”。稀疏自动编码器由此为逐特征追踪模型的计算提供了清晰路径。
研究意义: 迈向透明的语言模型
这项研究为机制可解释性 (mechanistic interpretability) 迈出了重要一步——让我们能够以具有明确语义的计算单元来理解模型。
关键结论
- 叠加问题可被解决。 稀疏自动编码器将重叠特征解耦为独立、稀疏的方向。
- 特征比神经元更易解释。 自动评估一致显示更高的可解释性分数。
- 特征具有因果关联。 它们能精确控制类似 IOI 任务,实现细粒度的行为调节。
尽管激活重构尚不完美,且该方法目前在残差流上表现最佳,而非于更深的 MLP 层,但这些局限也为未来研究指明方向。提升重构精度或将稀疏特征扩展至其他组件,或能进一步揭示模型的内部工作机制。
机制可解释性的长期目标——即所谓的*枚举式安全 (enumerative safety) *——是为模型使用的每一项特征建立人类可理解的目录,从而确保模型无法执行有害或欺诈性行为。稀疏自动编码器为这一愿景提供了一条可扩展、无监督的实现路径。
通过用可解释的特征取代神经元,这项工作让我们能更清晰地洞察模型内部——为构建可观测、可理解、可引导的 AI 系统铺平了道路。