](https://deep-paper.org/en/paper/2310.08731/images/cover.png)
想象一下,你训练了一个机器人在迷宫中导航。它在数百万次的模拟步骤中学会了“红色瓷砖意味着熔岩”和“绿色瓷砖意味着目标”。它表现得完美无缺。然后,你将它部署到现实世界中。突然,光线发生了变化,或者一扇原本总是开着的门现在锁上了,又或者地面变得湿滑。
在强化学习 (RL) 中,这被称为新奇性 (Novelty) ——即环境的动力学或视觉效果发生了意料之外的、永久性的转变,而这在训练期间从未被智能体预见到。
通常,当 RL 智能体遇到它从未见过的情况时,它会发生灾难性的失败。它可能会原地打转、撞毁,或者自信地采取危险行动,因为它的内部策略已不再有效。为了防止这种情况,我们需要新奇性检测 (Novelty Detection) : 一个充当“检查引擎”指示灯的系统,警告智能体世界已经改变,它应该停止行动或进行适应。
今天,我们将深入探讨一篇名为 “Novelty Detection in Reinforcement Learning with World Models” (基于世界模型的强化学习新奇性检测) 的研究论文。这项工作提出了一种迷人且具有数学依据的方法,可以在不依赖困扰传统方法的繁琐、手动“阈值”的情况下检测这些变化。
“惊奇”的问题
在介绍解决方案之前,我们必须理解为什么这很难。在标准的机器学习中,异常检测通常被视为“分布偏移”。你观察输入的数据,如果它看起来在统计上与你的训练数据不同,你就标记它。
然而,在 RL 中,数据不是静态的。智能体在移动,“摄像机”在平移,状态根据动作不断变化。一种标准方法是测量预测误差 。 如果智能体预测下一个状态并出错了,这是新奇性吗?
不一定。这可能只是随机噪声 (偶然不确定性,aleatoric uncertainty) 。或者也许智能体处于地图的一个它很少访问的角落 (认知不确定性,epistemic uncertainty) 。
大多数现有的方法,如 RIQN (循环隐式分位数网络) ,通过设置一个手动阈值来解决这个问题。你选择一个数字,比如 \(0.5\)。如果误差分数高于 \(0.5\),那就是新奇性。但是你如何选择这个数字?这需要你在新奇性发生之前就知道它长什么样,这与“意料之外”的新奇性定义相矛盾。
这篇论文的作者提出了一个更好的问题: 我们能否利用智能体自身对世界的理解来定义一个动态的新奇性边界,而无需人工调整?
核心概念: 世界模型
要理解这个方法,我们首先需要理解它所基于的架构: 世界模型 (World Model) 。 具体来说,这篇论文使用的是 DreamerV2 。
在传统的 RL 中,智能体观察图像 (\(x_t\)) 并输出动作 (\(a_t\)) 。世界模型更进一步。它试图学习世界的紧凑内部表示。它由以下部分组成:
- 编码器 (Encoder) : 将高维图像 \(x_t\) 转换为紧凑的潜在状态 \(z_t\)。
- 循环模型 (Recurrent Model) : 基于过去的状态和动作维护“历史” \(h_t\)。
- 预测器 (Predictor) : 猜测接下来会发生什么。
关键在于,DreamerV2 使用了变分自编码器 (VAE) 设置。它平衡了两个分布:
- 后验 (Posterior) : \(p(z_t | h_t, x_t)\)。这是智能体在看到实际图像 \(x_t\) 之后对状态的理解。
- 先验 (Prior) : \(p(z_t | h_t)\)。这是智能体仅根据其历史 \(h_t\),在看到图像之前对状态的预测。
在训练期间,智能体最小化先验和后验之间的差异 (KL 散度) 。它试图使其预测 (先验) 与其观察 (后验) 一样好。
训练的损失函数如下所示:
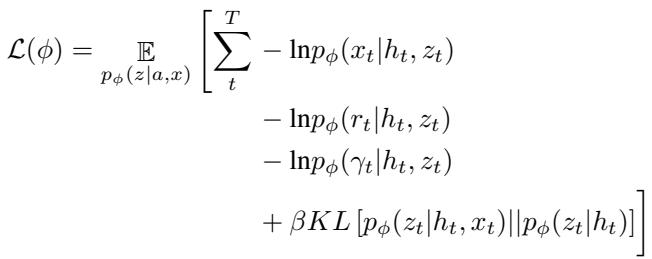
该方程中的最后一项——后验与先验之间的 KL 散度——是关键。它代表“惊奇 (Surprise) ”。如果先验 (预测) 与后验 (现实) 非常不同,KL 散度就会很高。
模型崩溃现象
当新奇性发生时,这个世界模型会发生什么?
让我们看一个具体的例子。在下表中,研究人员引入了巨大的变化: 类人行走模拟中的“噪声”、Atari 游戏“Freeway”中的隐形汽车,以及 MiniGrid 环境中的熔岩。
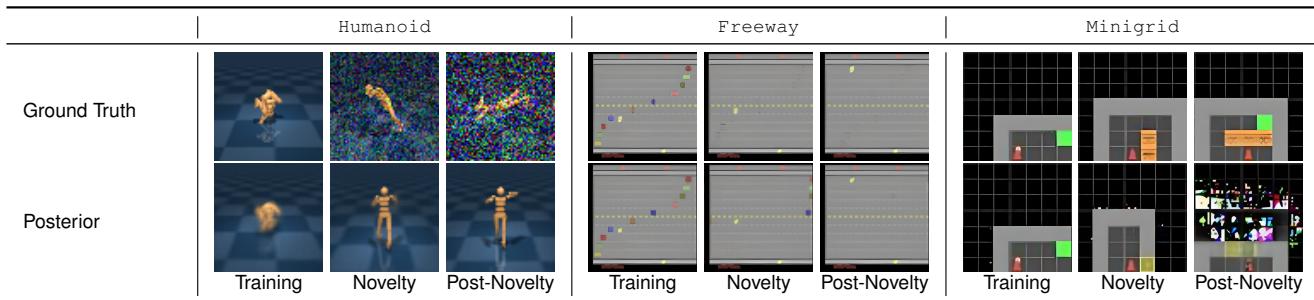
看一看 Posterior (后验) 这一行。
- Training (训练中) : 模型完美地重建了图像。
- Novelty Introduced (引入新奇性) : 模型开始失效。在“Freeway”示例 (中间列) 中,汽车对智能体来说变得不可见,但模型——被这种变化搞糊涂了——产生了一个混乱、模糊的重建幻觉。
- Post-Novelty (新奇性后) : 模型已经完全崩溃。它不再理解世界的因果物理规律。
这种崩溃正是我们想要检测的。但我们希望通过数学方式检测它,而不仅仅是看模糊的图像。
方法: 新奇性检测界限
研究人员提出了一种方法,利用世界模型产生的幻觉状态与真实观察状态之间的错位 。
他们引入了一个涉及“历史丢弃 (history dropout) ”的概念。他们问: 与历史 \(h_t\) 相比,当前图像 \(x_t\) 对我们的理解有多大贡献?
为此,他们定义了一个“虚拟”历史,\(h_0\)。这就像一个患有失忆症的智能体——它没有过去的记忆。
他们建议使用交叉熵 (\(H\)) 比较两个量:
- 如果我们在目标中忽略图像,当前观察 (\(x_t\)) 对预测潜在状态有多大帮助?
- 如果我们保留目标中的图像,它有多大帮助?
这导致了分数的比较:

这看起来很抽象,但它简化为一个包含 KL 散度的强大不等式。研究人员推导出了一个新奇性阈值界限 (Novelty Threshold Bound) 。
黄金方程
这是论文的核心贡献。新奇性不是通过手动阈值检测的,而是当违反以下界限时检测到的:
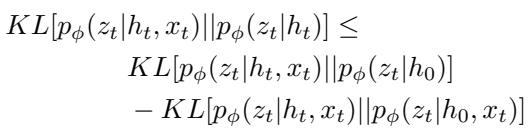
让我们用通俗的语言来分解它。
左侧 (LHS) : \(KL[p(z_t | h_t, x_t) || p(z_t | h_t)]\)。
这就是标准的贝叶斯惊奇 (Bayesian Surprise) 。 它衡量现实 (后验) 与预测 (先验) 有多大不同。
通常,我们会为此设置一个阈值: “如果 LHS > 10,报警!”但我们不想那样做。
右侧 (RHS) : \(KL[p(z_t | h_t, x_t) || p(z_t | h_0)] - KL[p(z_t | h_t, x_t) || p(z_t | h_0, x_t)]\)。
这一侧充当动态阈值 。
第一项检查当前状态与“盲”猜 (\(h_0\)) 相距多远。
第二项检查图像本身提供的信息增益。
直觉: 在正常情况下,你的历史 (\(h_t\)) 使你的预测准确。因此,左侧的散度 (标准惊奇) 应该很小。右侧代表了基于当前观察的复杂性所允许的不确定性“预算”。
当新奇性发生时 (如隐形汽车或上锁的门) ,模型无法调和历史与新的观察结果。关系发生了翻转。标准惊奇 (LHS) 飙升,而模型对观察的置信度 (RHS) 下降或偏移。
如果 LHS > RHS , 我们就遇到了新奇性。不需要手动数字。
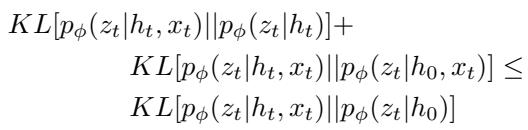
可视化界限
为了证明这一点行之有效,作者在数百万个训练步骤中跟踪了这些值。
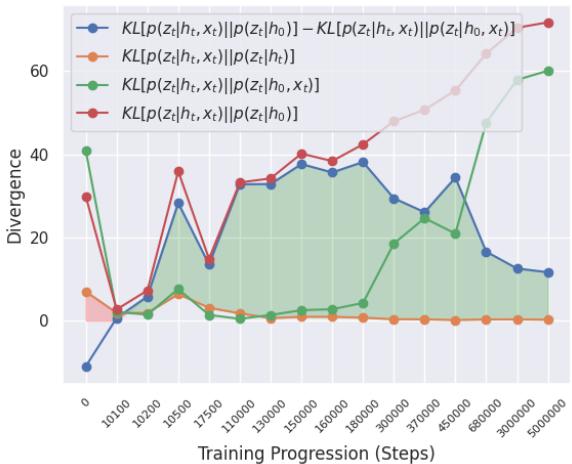
在图 1中,看那条蓝线 。 这代表了界限中计算出的差值。
- 橙线是标准惊奇 (LHS) 。
- 在正常训练期间, 橙线始终保持在蓝线 下方 (绿色阴影区域) 。这意味着界限成立: 无新奇性。
- 如果橙线穿过蓝线之上,那将触发检测。
这张图表明,在平稳环境中,该界限自然得到满足,这意味着假阳性率应该非常低。
实验: 它有效吗?
研究人员在三个不同的领域对此进行了测试:
- MiniGrid: 简单的 2D 导航 (例如,出现熔岩,门锁上) 。
- Atari: 复杂的视觉游戏 (例如,Boxing、Freeway、Seaquest) 。
- DeepMind Control (DMC): 基于物理的机器人控制 (例如,Walker、Cheetah) 。
他们将他们的“KL Bound” (KL 界限) 方法与以下方法进行了比较:
- RIQN: RL 新奇性检测的最先进集成方法。
- PP-Mare: 他们创建的一个基线,用于检查像素重建误差 (即,“图像看起来模糊吗?”) 。
基线: PP-Mare
作为背景,PP-Mare 基线是一种更简单的方法,它检查重建的像素是否错误。
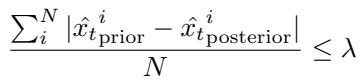
虽然简单,但像素误差往往具有误导性。摄像机角度的微小偏移会导致巨大的像素误差,但这不一定是“新奇性”,而微小的敌人消失可能像素误差很低,但这在概念上是一个巨大的新奇性。

结果 1: 假阳性 (狼来了的故事)
异常检测中最大的问题之一是假阳性率 (FPR) 。 如果你的机器人每 5 秒钟就因为以为看到了鬼而停下来,那它就毫无用处。
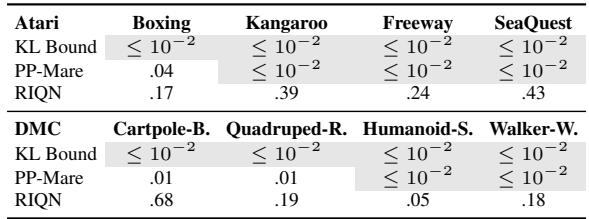
表 2 令人震惊。
- RIQN: 具有很高的假阳性率 (在 Atari 中为 17% 到 43%!) 。它过于敏感。
- KL Bound (我们的) : 始终 \(\leq 10^{-2}\) (低于 1%) 。
因为 KL Bound 源自模型自身的训练动力学,所以它在正常环境中非常稳定。它不会“喊狼来了”。
结果 2: 检测速度和准确性
当新奇性确实发生时,我们能多快捕捉到它?我们测量平均延迟误差 (ADE) ——即从新奇性出现到警报响起之间经过了多少步。越低越好。
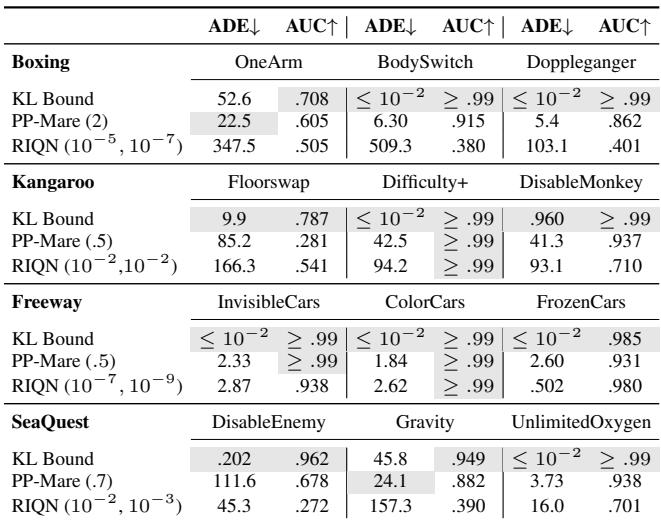
在 Atari (表 3) 中,看“Freeway”环境 (汽车变得隐形或冻结) :
- KL Bound: ADE 为 \(\leq 10^{-2}\)。它几乎瞬间检测到了它。
- PP-Mare: 较慢。
- RIQN: 有竞争力,但请记住它的高假阳性率。
在 DeepMind Control (表 4) 中,结果类似。
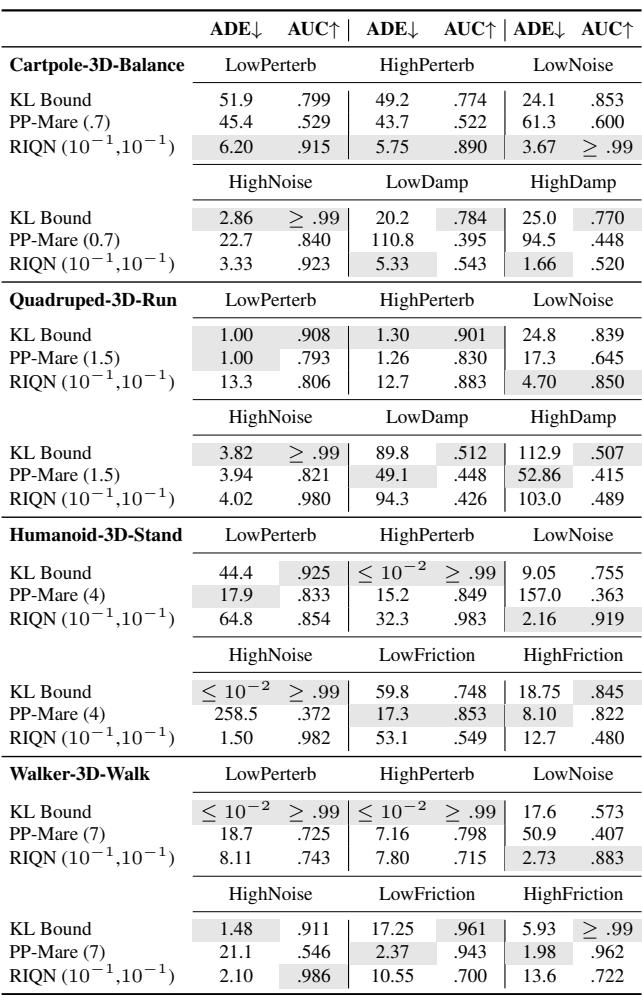
KL Bound 通常无需 RIQN 所需的参数调整即可实现完美或接近完美的检测 (AUC \(\approx 0.99\)) 。
结果 3: 计算速度
这是一篇关于应用研究的博客,所以我们必须问: 运行速度快吗?
RIQN 使用集成 (多个模型) 和复杂的统计累积 (CUSUM) 。KL Bound 只是重新利用世界模型已经在计算的值。
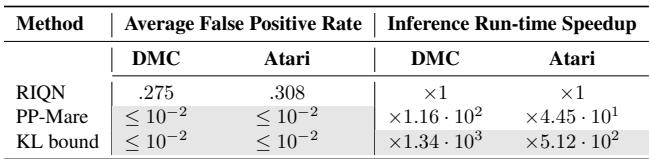
表 6 显示了“推理运行时加速”。KL Bound 方法在 DMC 环境中比 RIQN 快 1340 倍 , 在 Atari 中 快 512 倍 。 这是在机器人上实时运行与需要超级计算机之间的区别。
深入探讨: “假目标”异常
作者进行了一项有趣的消融研究,以展示策略 (智能体的行为) 如何影响检测。
他们在 MiniGrid 中创建了一个“假目标”环境。智能体被训练去往一个目标。在新奇性设置中,目标是假的或无法到达的。
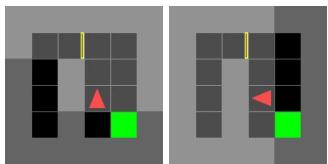
他们发现了一些有趣的事情: 如果智能体训练得很高效,它从不看门的“后面”,因为它不需要。在那个新奇的环境中,它可能会转身。世界模型从未见过门的“背面”,因此将其标记为新奇性。
看到门的背面是新奇性吗?从技术上讲,是的——这是模型尚未学习的过渡。但这突显了一个局限性: 新奇性检测依赖于探索。 如果你的智能体在训练期间盲目地遵循狭窄的路径,那么该路径之外的任何事物看起来都像新奇性。
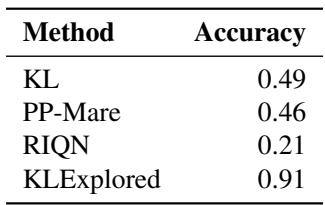
如表 8 所示,明确探索环境 (KLExplored) 极大地提高了标记“真实”新奇性与仅仅是“我以前没看过那里”之间区别的准确性。
推广到其他架构
主要结果使用的是 DreamerV2 (基于 RNN) 。但是现代的基于 Transformer 或基于 Diffusion 的世界模型呢?
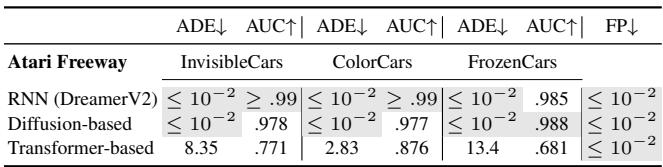
表 7 表明该逻辑仍然成立。无论你使用的是 Transformer (如 IRIS) 还是 Diffusion 模型 (如 Diamond) ,KL Bound 方法都能有效地检测新奇性,尽管 Transformer (因为对数据需求量大) 在 Freeway 环境中的反应稍慢。
结论和主要收获
论文 “Novelty Detection in Reinforcement Learning with World Models” 为 AI 安全中的一个关键问题提供了一个强有力的解决方案。
以下是这项工作为何重要的总结:
- 没有魔法数字: 它消除了对手动阈值 (\(\lambda\)) 的需求。该界限源自模型自身的不确定性动力学。
- 利用“惊奇缺口”: 它通过检查模型是否过于依赖当前图像来检测新奇性,因为其历史 (上下文) 不再有意义。
- 高精度: 与 RIQN 等最先进的方法相比,它大幅降低了假阳性。
- 效率: 计算速度快几个数量级,使其在实时部署中切实可行。
通过重新利用世界模型——智能体本来就用它来规划——进行异常检测,我们几乎“免费”获得了一个安全系统。随着我们将 RL 从视频游戏转移到现实世界,像这样的技术将成为防止机器人在世界不可避免地发生变化时发生故障的安全网。