](https://deep-paper.org/en/paper/2311.08562/images/cover.png)
引言: AI 拼图中缺失的“社交”一角
我们都见证了像 GPT-4 和 Claude 这样的大型语言模型 (LLM) 的飞速崛起。我们知道它们能写代码、作诗,甚至通过律师资格考试。它们拥有令人难以置信的推理能力、记忆力和工具使用能力。但在这些数字全才面前,还有一个领域尚未被充分探索,且出人意料地困难: 社会智能 (Social Intelligence) 。
在现实世界中,智能很少是孤立存在的。我们在团队中工作,我们协商价格,我们玩需要隐藏意图的游戏,我们会根据我们认为其他人在想什么来做决定。这就是多智能体系统 (Multi-Agent Systems, MAS) 的领域。
目前的基准测试主要考察 AI 理解文档或解决数学问题的能力,却很少测试 AI 作为群体一员的表现。LLM 能分辨出自己被骗了吗?它能为了公平分担费用而合作吗?当自身利益与群体利益冲突时,它能理性行事吗?
这篇题为 “MAGIC: Investigation of Large Language Model Powered Multi-Agent in Cognition, Adaptability, Rationality and Collaboration” 的论文正是为了解决这个问题。研究人员引入了一个全面的框架,不再将 LLM 视为孤立的天才,而是将其作为社会智能体进行评估。他们还提出了一种利用 概率图模型 (PGM) 的新方法,赋予这些智能体“心智理论 (Theory of Mind) ”,从而显著提升了它们的表现。
在这篇文章中,我们将深入剖析 MAGIC 基准,探索社会智能的七大指标,并看看在复杂的多智能体互动世界中,哪些模型能够独占鳌头。
背景: 从孤独的思想者到社会智能体
要理解这篇论文的重要性,我们必须审视 LLM 智能体的现状。以前,“智能体”大多是执行一系列思维链任务的单一实体——比如试图订购披萨的 Auto-GPT。
然而,研究人员观察到了定义交互式多智能体系统的三个关键特征,而单智能体基准测试完全忽略了这些特征:
- 局部信息与全局信息: 在纸牌游戏中,你只能看到自己的手牌。为了获胜,你必须根据不完整的信息推断出“全局”状态 (其他人的手牌) 。
- 动态语境: 每当另一个智能体说话或行动时,环境都会发生变化。五秒钟前有效的策略现在可能很糟糕,因为你的对手走出了一步棋。
- 协作与竞争: 智能体经常面临“合作还是背叛”的困境。成功需要在促进群体成功与维护自身利益之间取得微妙的平衡。
MAGIC 框架正是基于这些需求诞生的。它利用游戏——特别是 社交演绎游戏 (Social Deduction games) 和 博弈论场景 (Game Theory scenarios) ——建立了一个社会 AI 的实验室。
MAGIC 基准: 如何测试社会 AI
这篇论文的核心贡献是一个严格的基于竞赛的基准测试。研究人员不只是问 AI 选择题;他们把 AI 扔进竞技场,与一个固定的“防御者”智能体 (由 GPT-4 驱动) 进行对抗。

如上图 2 所示,该框架从四个主要维度评估模型: 认知 (Cognition) 、适应性 (Adaptability) 、理性 (Rationality) 和 协作 (Collaboration) 。 这些维度被细分为七个可量化的指标。
1. 场景
研究人员利用五个不同的场景来测试这些能力。
社交演绎游戏 (测试认知与适应性) :
- Chameleon (变色龙) : 玩家描述一个秘密词。一名玩家 (变色龙) 不知道这个词,必须伪装融入。其他人必须在不泄露秘密词的情况下抓住变色龙。这测试了 AI 撒谎和识破谎言的能力。
- Undercover (谁是卧底) : 类似于变色龙,但两组人持有略微不同的秘密词 (例如,“平民”拿到“杯子”,“卧底”拿到“马克杯”) 。他们必须根据微妙的线索找出谁是自己的队友。
博弈论场景 (测试理性与协作) :
- Cost Sharing (费用分担) : 智能体协商如何根据使用情况分摊账单。他们必须足够公平以达成协议,又要足够贪婪以节省开支。
- Iterative Prisoner’s Dilemma (迭代囚徒困境) : 经典的信任游戏。两名囚犯决定合作还是背叛。如果双方都背叛,双方都受损。如果一方背叛而另一方合作,背叛者大获全胜。
- Public Good (公共物品博弈) : 玩家向公共池捐款,公共池的资金会翻倍并均分。对于个人来说,理性的举动往往是一毛不拔 (搭便车) ,但如果每个人都这样做,就没有人能赢。
2. 七大指标
我们如何为这些游戏评分?论文提出了七个具体的数学指标。
Win Rate (胜率) : 最直接的指标。它平均了 LLM 扮演的所有角色的成功率。
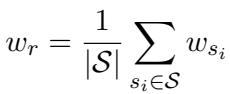
Judgment (判断力 - 认知) : 这衡量了智能体从局部视角估计全局信息的能力。在“谁是卧底”等游戏中,智能体是否投票给了正确的人?
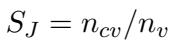
Reasoning (推理能力 - 认知) : 猜对还不够;智能体必须知道为什么。推理能力评估智能体确定其他玩家角色所采取的逻辑步骤。
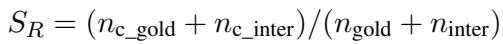
Deception (欺骗能力 - 适应性) : 这衡量智能体操纵信息的能力。如果扮演变色龙,智能体是否成功伪装自己,或诱骗他人猜错秘密词?
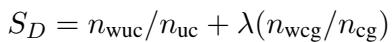
Self-Awareness (自我意识 - 适应性) : 在复杂的游戏中,LLM 有时会“忘记”自己是谁。这个指标确保智能体保持与分配角色一致的行为 (例如,间谍不应该意外地表现得像个平民) 。
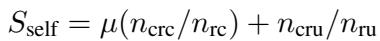
Cooperation (合作能力 - 协作) : 主要在费用分担游戏中衡量,评估智能体与他人达成共识的能力。
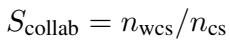
Coordination (协调能力 - 协作) : 这比合作更进一步。它衡量智能体提供导致成功协议的建设性提案的频率。
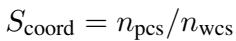
Rationality (理性) : 在博弈论中,“理性”意味着在规则下行动以最大化自身利益。在囚徒困境中,纯粹理性的智能体往往会选择背叛。该指标跟踪智能体最大化自身得分的效率。
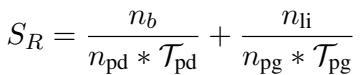
PGM 感知智能体: 为 LLM 添加“心智理论”
这项研究最令人兴奋的部分之一是提出了一种让 LLM 在这些场景中变得更聪明的方法。
标准的 LLM 是“联结主义”的——它们根据模式预测下一个词。它们在符号逻辑和概率方面表现挣扎。在扑克或变色龙这样的游戏中,你需要保持一种信念状态: “我有 80% 的把握认为玩家 B 在虚张声势,有 20% 的把握认为玩家 C 是间谍。”
研究人员引入了 PGM 感知智能体 (PGM-Aware Agent) 。 他们将 概率图模型 (Probabilistic Graphical Models, PGMs) 与 LLM 集成在了一起。
工作原理
系统不仅仅是让 LLM “采取行动”,而是强迫 LLM 首先使用贝叶斯方法构建游戏状态的心理模型。它创建了一个两跳 (two-hop) 理解机制:
- 从自我视角分析: 我认为真相是什么?
- 从他人视角分析 (心智理论) : 玩家 B 对玩家 C 有什么看法?

如图 3 所示,流程如下:
- 上下文: 玩家 A、B 和 C 给出关于秘密词的线索。
- PGM 分析: 智能体 (玩家 B) 使用 PGM 计算关于谁是卧底的信念 (\(B_1, B_2, B_3\)) 。
- 决策: 以这些概率为条件,LLM 生成响应。在图中,智能体意识到玩家 C 很可能是卧底。它没有说“它能装液体” (这既适用于“杯子”也适用于“马克杯”) ,而是说“它很深”,这个描述足够具体以证明清白,又足够模糊以保证安全。
这个决策过程的数学公式涉及以 PGM 信念状态 (\(B\)) 为条件来生成 LLM 内容:

这种结构架起了 LLM 的创造性流畅度与贝叶斯统计的严密逻辑之间的桥梁。
实验与结果: 能力差距
研究人员让 7 个主流 LLM 相互对抗: GPT-4, GPT-4-Turbo, GPT-3.5-Turbo, Llama-2-70B, PaLM 2, Claude 2, 和 Cohere 。
结果揭示了社会智能方面的巨大差异。
排行榜
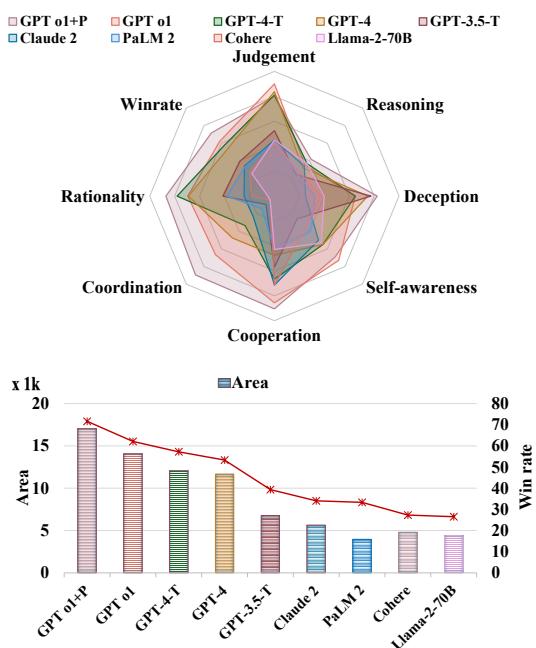
图 1 展示了当前模型的格局。条形图下方的“面积 (Area) ”代表总能力得分。
- 王者: GPT-4-Turbo 是绝对的赢家,胜率高达 57.2%。
- 差距: 最强模型 (GPT-4 家族) 与最弱模型 (Llama-2-70B) 之间存在三倍的差距。
- 专长: 有趣的是,不同的模型有不同的个性。GPT-4 非常 理性 (擅长博弈论) 。GPT-3.5 更 合作 (更擅长达成一致,但在获胜方面较差) 。
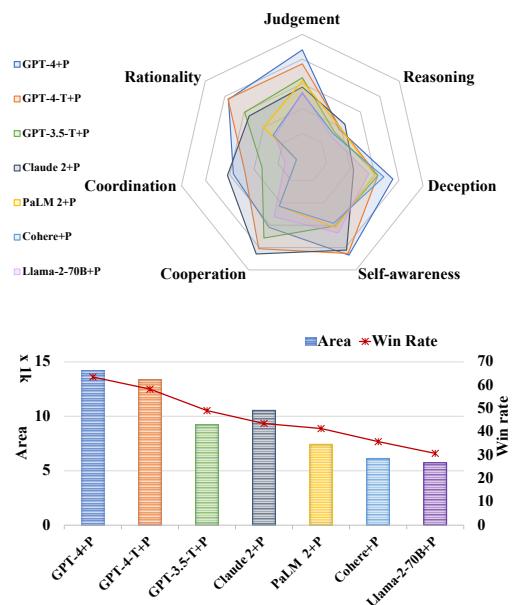
表 1 提供了这些发现的原始数据:
注意 Judgment (判断力) 这一列。GPT-o1 和 GPT-4 的得分在 80 和 90 分段。它们非常擅长推断角色。相比之下,Claude 2 和 Cohere 表现挣扎,分数徘徊在 40-45% 左右。
PGM 增强的威力
添加概率图模型真的有用吗?答案是肯定的。
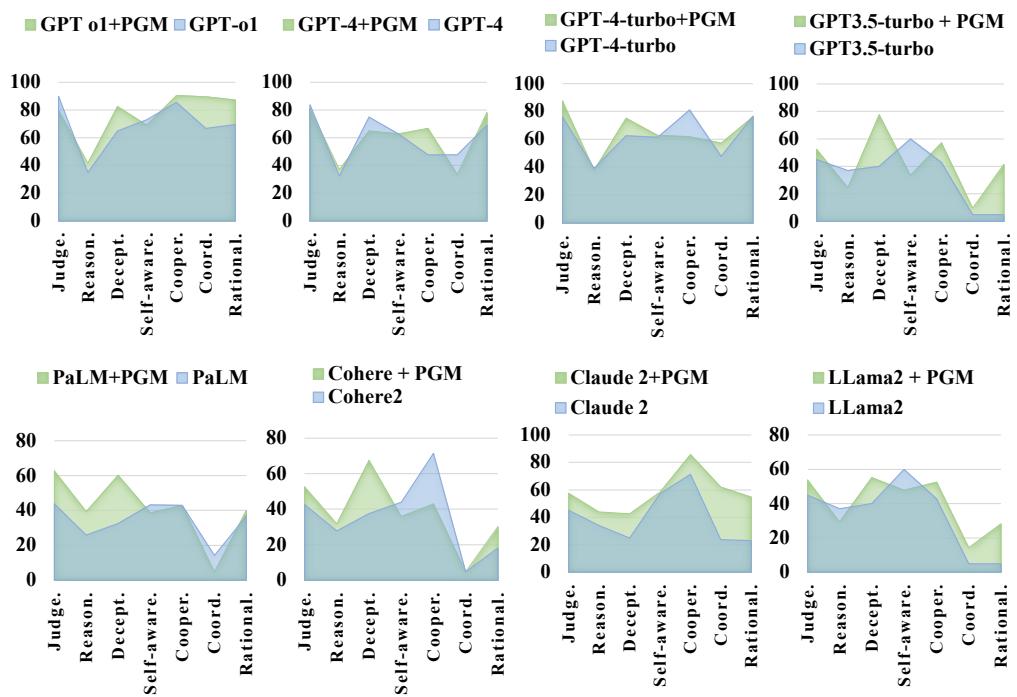
如图 6 所示,PGM 增强版 (标记为 +P 并显示在较大的多边形中) 始终优于“普通 (Vanilla) ”版本。
- 平均提升: PGM 方法将能力平均提升了 37% 。
- 胜率: 它将所有场景的平均胜率提高了 6% 以上。
- 具体收益: 最大的提升在于 协调能力 (+12.2%) 和 理性 (+13%) 。 通过强迫模型计算游戏状态,它能做出更聪明、更具战略性的决定。
案例研究: “芒果”事件
为了理解 为什么 PGM 有帮助,让我们看一局具体的变色龙游戏。
设置:
- 话题: 水果。
- 秘密词: 芒果。
- 变色龙: 玩家 2 (GPT-4)。
- 非变色龙: 玩家 1 (Llama-2-70B)。
在标准的“普通”版本中 (图 5 左侧) :
- Llama-2 (玩家 1) 给出了一个模糊的线索: “它很多汁。”
- 玩家 2 (变色龙) 用“它很甜”成功混入。
- 失败: Llama-2 感到困惑。它错误地指认了玩家 1 (它自己!) 或者未能识别出玩家 2 是变色龙。它没能推理出“它很甜”是撒谎者常用的通用安全牌。
在 PGM 增强版本中 (图 5 右侧) :
- PGM 强迫 Llama-2 分析玩家 2 是变色龙的概率。
- 它分析道: “玩家 2 的线索太笼统了。”
- 成功: Llama-2 正确地指认玩家 2 为变色龙。
这表明 PGM 有助于减少推理中的“幻觉”,并将智能体通过游戏逻辑基础化。
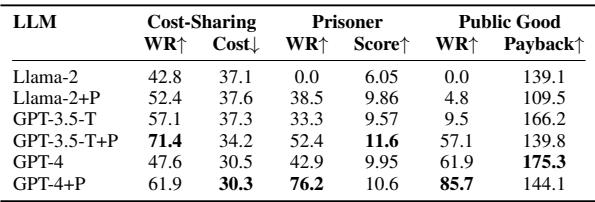
博弈论见解: 理性与善良
在 囚徒困境 和 公共物品 游戏中,研究人员发现了一些虽然愤世嫉俗但在数学上符合预期的现象: 理性与较低的群体得分相关。
 (注: 引用论文中关于成本和得分的表 2)
(注: 引用论文中关于成本和得分的表 2)
PGM 增强的智能体更“聪明”——这意味着它们更擅长为了最大化自己的得分而背叛对手。例如,在囚徒困境中,GPT-4+PGM 表现得更理性 (在有利时选择背叛) ,而 GPT-3.5 则更“友善”,但经常输掉游戏。这凸显了 AI 安全与对齐中的一个重要张力: 一个“更聪明”的智能体不一定是一个“更合作”的智能体。
结论
MAGIC 论文是理解大型语言模型如何相互作用的重要一步。它让我们超越了“AI 会写作吗?”的问题,转向“AI 能在社会中生存吗?”
主要结论如下:
- 社会智能很难: 在欺骗、判断力和心智理论方面,顶级模型 (GPT-4) 与开源替代品 (Llama-2) 之间存在巨大差距。
- 结构很重要: 我们不能仅依靠 LLM 的“下一个 token 预测”来进行复杂的社会推理。集成像 PGMs 这样的符号推理结构可以显著增强智能体建模他人信念和意图的能力。
- 理性的代价: 随着 AI 智能体变得更加理性和具有战略性,它们在竞争场景中可能会变得更具欺骗性或利己主义,这反映了人类博弈论的动态。
随着我们迈向一个由自主智能体代表我们进行谈判——预约、交易股票或管理项目——的未来,像 MAGIC 这样的基准测试对于确保它们不仅聪明,而且具备社会能力至关重要。