](https://deep-paper.org/en/paper/2311.09580/images/cover.png)
引言
想象一下,你正在浏览社交媒体,看到一张房间乱七八糟、一片狼藉的照片,配文却是: “过着我最好的生活 (Living my best life) ”。作为人类,你立刻就能识别出其中的讽刺意味。图像 (混乱) 和文本 (“最好的生活”) 相互矛盾,而这种矛盾创造了意义。
现在,考虑一下标准的多模态 AI 如何看待这个问题。它处理图像,处理文本,并试图将它们对齐。它可能会看到“混乱”和“最好的生活”,然后因为语义内容不重叠而感到困惑。这凸显了当前视觉-语言模型 (VLMs) 的一个关键局限性: 它们非常擅长识别图像和文本何时表达相同的事物 (冗余性) ,但当意义源于两者之间的交互 (协同性) 时——比如讽刺或幽默——它们就显得力不从心了。
在论文 “MMOE: Enhancing Multimodal Models with Mixtures of Multimodal Interaction Experts” 中,来自卡内基梅隆大学和麻省理工学院的研究人员提出了一种新的框架来解决这个问题。他们不再强迫一个模型处理所有类型的图像-文本关系,而是引入了混合专家 (Mixture of Experts, MoE) 方法。通过针对不同的交互类型训练专门的“专家”,他们在讽刺和幽默检测方面取得了最先进的结果。
在这篇文章中,我们将详细拆解为什么标准模型在复杂交互中会失败,以及 MMOE 架构如何将数据智能路由到专门的专家那里,从而“听懂笑话”。
问题: 并非所有交互都是平等的
当前最先进的模型 (如 ALBEF 或 BLIP2) 主要是在依赖冗余性 (redundancy) 的任务上进行训练的。例如,在图像-文本匹配中,模型学习到一只狗的照片对应单词“狗”。视觉信号和文本信号提供了相同的信息。
然而,现实世界的交流很少如此简单。研究人员认为,多模态交互通常分为三类:
- 冗余性 (Redundancy) : 图像和文本都传达相同的情感或信息。
- 独特性 (Uniqueness) : 一种模态承载主要信息。例如,演讲者可能在讲一个无聊的故事,但他们的面部表情清楚地表明他们在开玩笑。
- 协同性 (Synergy) : 最困难的类别。情感既不单独存在于图像中,也不单独存在于文本中;只有当两者融合时才会产生情感。
研究人员根据经验发现,标准模型在处理协同性问题时性能会大幅下降。
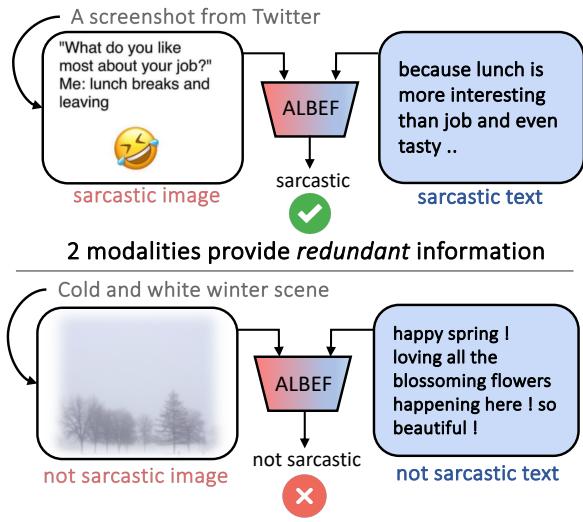
如 图 1 所示,模型 ALBEF 在文本和图像是冗余的 (两者都是讽刺的) 情况下表现良好 (F1 分数约为 89%) 。但是看看底部的例子: 一个寒冷的冬天场景,配文却是“快乐的春天!爱死这些盛开的花朵了。”图像本身不是讽刺的。文本本身看起来也是积极的。讽刺存在于两者之间的冲突中。在这些“协同性”例子上,ALBEF 的性能骤降至约 24%。
协同性案例研究
为了进一步说明为什么这很难,让我们看一个研究中的具体失败案例。

在 图 7 中,图像显示人们在鼓掌,文本说: “they think they should not leave (他们认为自己不该离开) ”。两者本身都不是讽刺。然而,两者的结合暗示了观众被困住或被迫鼓掌,从而产生了讽刺的含义。一个单一的单体模型很难捕捉到这种细微差别,因为它试图寻找一致性,而不是分析交互动态。
解决方案: 多模态交互专家混合模型 (MMOE)
MMOE 的核心洞察是: 不同的交互需要不同的建模范式。 你不应该用解决冗余问题 (匹配) 的数学方法来解决协同问题 (推理) 。
MMOE 框架分三个不同的步骤运作:
- 分类: 按交互类型标记训练数据。
- 专家训练: 为每种类型训练特定的模型。
- 推理: 使用融合机制组合专家对新数据的输出。
让我们逐步了解这些步骤。
第一步: 多模态交互分类
我们如何教计算机区分冗余性、独特性和协同性?研究人员设计了一种巧妙的统计方法,使用“单模态预测”。
他们获取一个数据点 (图像 + 文本) 并生成三个预测:
- \(y_1\) : 仅基于图像的预测。
- \(y_2\) : 仅基于文本的预测。
- \(y_m\) : 真实标签 (该多模态对的实际含义) 。
通过比较这三个值,他们对数据点进行分类。

如 图 2 所示,逻辑流程如下:
- 冗余性 (R) : 图像预测、文本预测和真实标签都一致 (\(y_1 = y_2 = y_m\)) 。
- 独特性 (U) : 模态之间不一致,但其中之一与真实标签匹配。
- 协同性 (S) : 图像和文本预测都不匹配真实标签。正确的标签只能通过结合两者找到。
研究人员使用“预测差异函数”将其形式化,表示为 \(\delta\)。
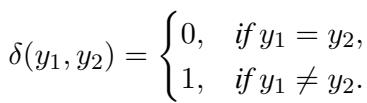
使用这个函数,他们计算总交互差异 \(\Delta_{1,2}\):
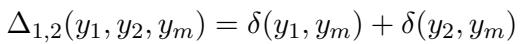
如果 \(\Delta_{1,2} = 0\),则是冗余性。如果是 1,则是独特性。如果是 2 (意味着两个单模态预测器都失败了) ,则是协同性。这个自动化过程允许他们在无需人工手动标记的情况下,将整个训练数据集分类到三个桶中。
第二步: 训练专家
一旦数据分类完成,训练过程就很简单了。研究人员不再在一个巨大的模型上训练所有数据,而是训练三个独立的“专家”模型 (\(f_r\), \(f_u\), \(f_s\)) 。
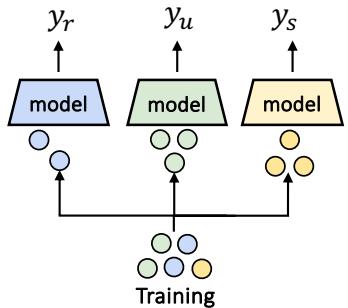
- 冗余专家 (\(f_r\)) : 在模态一致的数据子集上训练。
- 独特性专家 (\(f_u\)) : 在一种模态占主导地位的数据上训练。
- 协同专家 (\(f_s\)) : 在困难的“协同性”子集上训练。
这使得协同专家 (以它为例) 能够专门专注于学习冲突模态之间复杂的非线性关系,而不会被简单的、冗余的例子所“稀释”或干扰。
第三步: 推理与融合
挑战在于: 当一个新的数据点在测试期间到达时,我们不知道真实标签,所以我们不能使用第一步中的方法对其进行分类。我们不知道它是需要协同专家还是冗余专家。
为了解决这个问题,MMOE 使用了一个融合模型 (Fusion Model) (或路由器) 。这是一个经过训练的模型,用于根据输入预测专家的概率权重 (\(w_r, w_u, w_s\)) 。
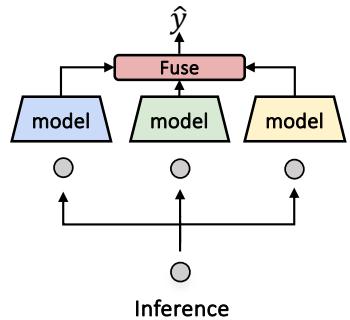
最终预测 \(\hat{y}\) 是专家的加权和:
\[ \hat{y} = w_r f_r(x) + w_u f_u(x) + w_s f_s(x) \]这使得系统能够动态调整。如果输入看起来像标准的图像说明,冗余专家会获得高权重。如果它看起来像一个讽刺的梗图,协同专家就会接管。
通用适用性
MMOE 最强大的方面之一是它是模型无关的。它不是特定的神经网络架构;它是一种训练策略。

如 图 5 所示,MMOE 可以应用于:
- 基于融合的 VLM , 如 ALBEF (视觉和文本在网络深处混合) 。
- 多模态扩展的 LLM , 如 BLIP2 (视觉特征作为 LLM 的提示) 。
- 图像转文字的 LLM (图像被转换为文本描述并输入到像 Qwen 这样的标准 LLM 中) 。
实验与结果
研究人员在两个具有挑战性的任务上测试了 MMOE: 讽刺检测 (MUStARD 数据集) 和幽默检测 (URFunny 数据集) 。
它击败了基线模型吗?
结果令人印象深刻。MMOE 在不同的基础模型 (ALBEF, BLIP2, Qwen2) 上均持续提升了性能。
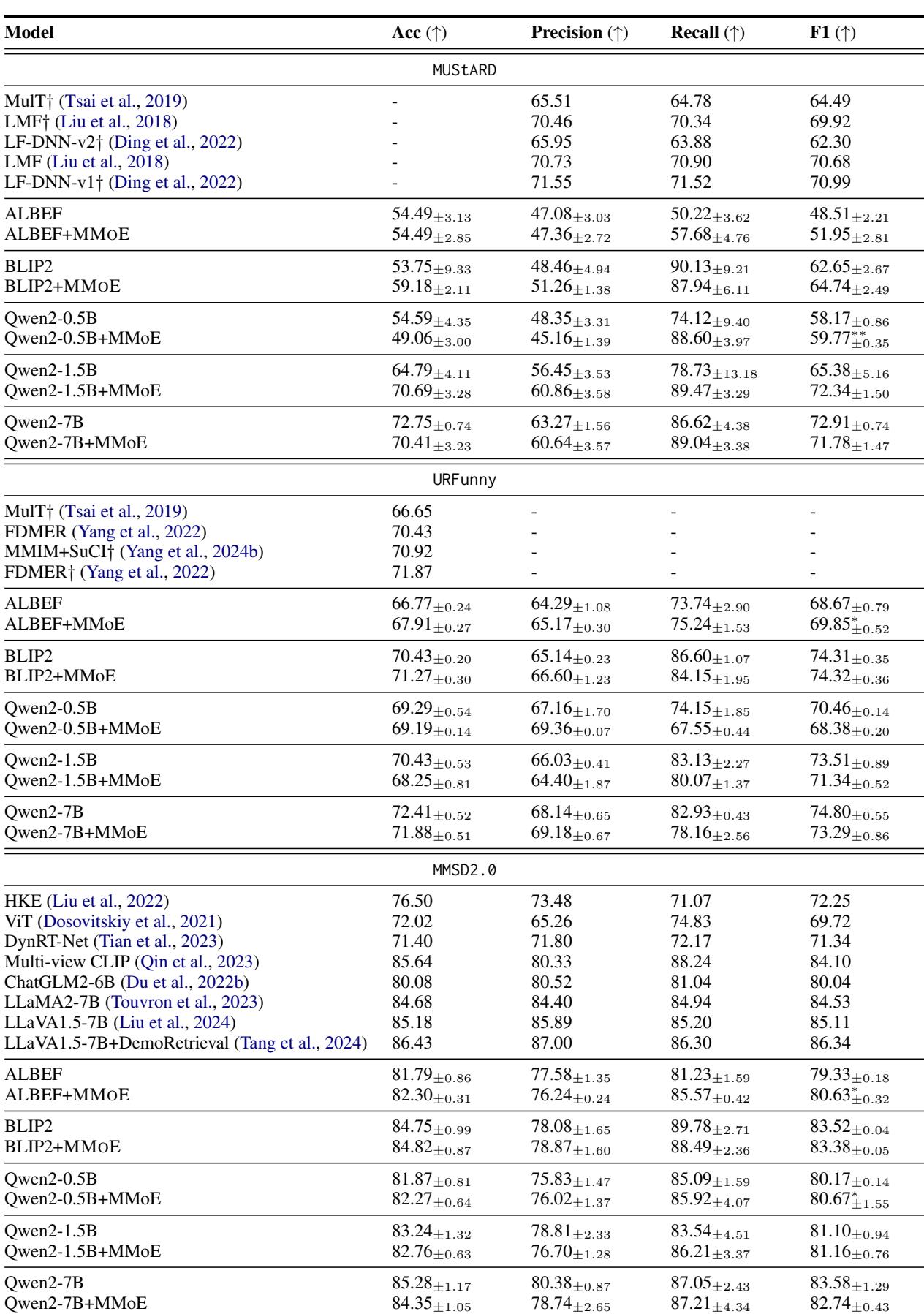
查看 表 6 (在图像组中为 images/018.jpg) ,我们可以看到一致的提升。例如,在 MUStARD 讽刺数据集上:
- Qwen2-1.5B 单独获得了 65.38 的 F1 分数。
- Qwen2-1.5B + MMOE 跃升至 72.34 。
这意味着专门的专家确实捕捉到了单一基线模型错过的信号。
破解协同性密码
这项工作的主要动机是模型在处理协同性方面的失败。MMOE 解决这个问题了吗?
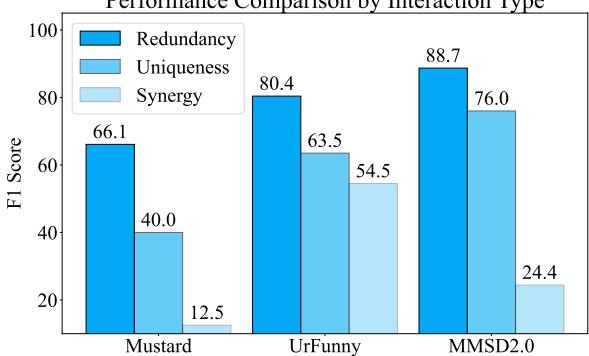
图 6 按交互类型细分了性能。虽然“协同性” (深蓝色条) 仍然是最难的类别 (绝对分数最低) ,但请注意趋势: 单一模型通常在协同性上几乎完全失败。通过显式训练协同专家 (\(f_s\)) ,系统保留了处理这些复杂情况的能力,比通才模型要好得多。
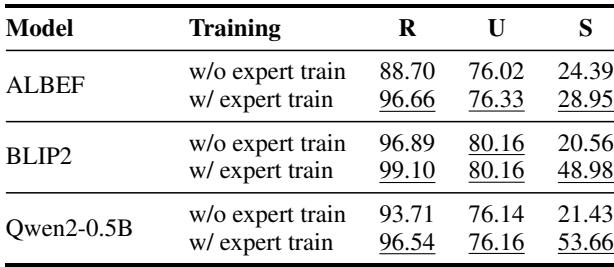
此外,当研究人员单独测试专家时 (论文中的表 2) ,他们发现协同专家在协同性数据点上明显优于基线。这验证了专业化很重要的假设。
缩放定律: 小模型大获全胜
论文中一个有趣的发现与模型大小有关。人们可能假设,只要把模型做得足够大 (像 GPT-4) ,它最终就能学会所有交互。
然而,研究人员发现 MMOE 对较小的模型特别有效。
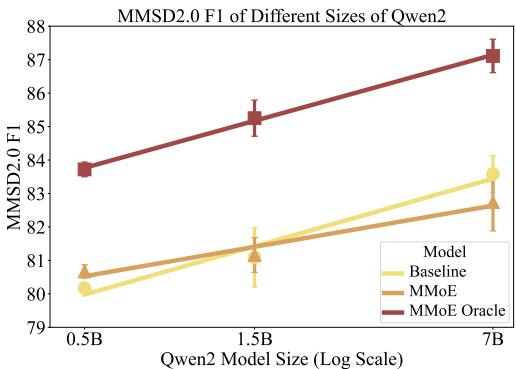
图 8 显示了随着模型大小增加 (从 0.5B 到 7B 参数) ,F1 分数的变化。
- 黄线 (基线) 随着模型变大而提高。
- 橙线 (MMOE) 为 0.5B 和 1.5B 模型提供了巨大的提升,显著击败了基线。
这表明,如果你资源受限,无法部署 700 亿参数的模型,使用较小模型的混合专家方法可以让你实现越级表现。
结论
MMOE 框架强调了多模态 AI 中的一个关键细微之处: 理解模态如何交互与模态本身同样重要。通过摆脱“一刀切”的训练目标,并承认冗余、独特和协同信息之间的差异,我们可以构建对人类交流复杂性 (如讽刺和反语) 更鲁棒的模型。
关键要点
- 协同性是瓶颈: 标准模型擅长匹配 (冗余性) ,但在推理冲突输入 (协同性) 方面表现糟糕。
- 分而治之: 对训练数据进行分类允许专门的专家模型胜过通才模型。
- 模型无关: MMOE 可以作为 VLM、MLLM 和 LLM 的“即插即用”增强功能。
- 效率: MMOE 允许较小的模型达到与大得多的基线模型相媲美的性能。
随着我们迈向需要应对复杂社交情境的 AI 代理,检测“未言之意” (协同性) 将至关重要。MMOE 为如何实现这一目标提供了一个充满希望的蓝图。