](https://deep-paper.org/en/paper/2312.00276/images/cover.png)
“记忆的敌人是其他的记忆。”——大卫·伊格曼
神经科学家大卫·伊格曼的这句观察精准地揭示了人工智能领域最顽固的挑战之一: 灾难性遗忘 。
想象一下,你教一个神经网络识别猫。它学得很好,准确率很高。现在,你教同一个网络识别狗。它掌握了新任务——但当你再次给它看猫的图片时,它却一无所知。“狗”的知识覆盖了“猫”的知识。
这是实现真正通用人工智能系统的最大障碍之一。我们希望智能体能够在其整个生命周期中持续学习,在不断变化的环境中积累技能,就像人类一样。但是,用梯度下降等标准优化算法训练的传统神经网络,天生不适合终身学习。它们被设计为一次解决一个问题——在完成当前任务时,会抹去过去的记忆。
几十年来,研究人员尝试通过设计各种学习技巧来防止遗忘: 加入正则化项、冻结重要权重或重放旧数据。但如果,我们不是去设计一个解决方案,而是让 AI 自己学习解决方案呢?
这正是 Irie、Csordás 和 Schmidhuber 在论文 《元学习持续学习算法》 中提出的大胆设想。研究人员提出了 自动化持续学习 (ACL) , 这是一种训练自我修改神经网络的方法,使其能够发现自身的持续学习算法。通过将持续学习问题建模为一个长序列处理任务,ACL 学会了一套内部学习规则: 在掌握新任务的同时明确地保留旧知识。
本文将解析 ACL 是如何让神经网络学会自己记忆的。我们将探讨:
- 持续学习的挑战及情境学习的理念
- 使模型能够重写自身权重的独特自我参照网络架构
- 编码“记忆”目标的元目标函数
- 展示 ACL 优于众多手工设计算法的实验结果
背景: 自学习系统的构建基石
要理解 ACL,我们首先回顾三个关键概念: 它要解决的问题( 持续学习 )、它采用的范式( 将元学习视为序列学习 )以及它所依托的架构工具( 自我参照权重矩阵 )。
1. 挑战: 持续学习 (CL)
持续学习 (CL) ——也称终身学习——旨在让模型能够按顺序学习多个任务而不忘记早期任务。
一个优秀的 CL 系统通常通过三项指标来评估:
- 任务表现: 模型对每个新任务的学习效果如何?
- 反向迁移: 学习新任务对旧任务性能有何影响?负向反向迁移是灾难性遗忘;正向反向迁移意味着新知识有助于旧任务表现。
- 正向迁移: 以往学习如何帮助未来任务?正向迁移说明模型随时间学习得更快、更好。
现有的 CL 方法很多。有的通过回放记忆储存旧数据,有的通过冻结或正则化权重来保持稳定。ACL 与它们不同: 它不使用外部记忆,模型大小保持不变。它从学习算法本身这个根源入手来解决遗忘问题。
2. 范式: 将元学习视为序列学习
ACL 的核心洞见是: 学习本身可以被视为序列处理。
在元学习中——或称“学习如何学习”——模型不再只是解决某个固定任务,而是学习如何学习多个任务。这正是少样本学习与现代大语言模型 (LLM) 中的情境学习机制背后的原理。
其工作方式如下: 想象一个序列模型 (如 Transformer) ,它处理一连串输入与标签对——即某个任务的演示。在处理完这些演示后,我们输入一个没有标签的新样本 (查询) ,模型必须输出预测结果。
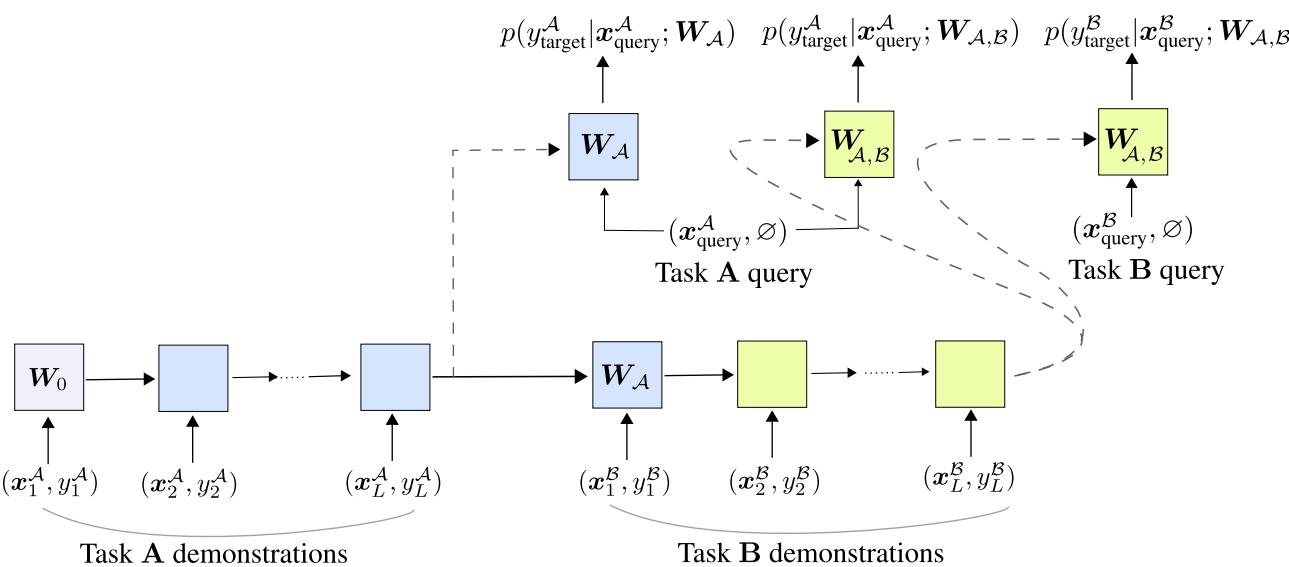
图: 情境学习器接收一系列 (图像,标签) 对作为演示,然后为新查询预测标签。
在元训练阶段,模型会看到数千个这样的片段,每个片段代表不同任务 (分类不同物体、字符等) 。它通过梯度下降优化,以便在处理完演示后能对未见过的查询表现良好——不需要显式“训练”循环。
实质上,模型在其权重内部学会了一种学习算法 。 学习的过程发生在前向传播中: 当它处理样本时,会隐式地更新内部表示。
3. 工具: 自我参照权重矩阵 (SRWM)
为了构建能终身适应的情境学习器,作者引入了一种特殊的层——自我参照权重矩阵 (SRWM) 。
SRWM 并非静态参数;它是一个能随着数据流动自动更新的矩阵。它属于线性 Transformer 家族,也称为 快速权重编程器 (FWP) 。 与标准 Transformer 的复杂度随序列长度呈二次方增长不同,SRWM 的扩展线性且保持恒定状态大小——非常适合连续、终身学习场景。
在每个时间步 \(t\),矩阵 \(W_{t-1}\) 接收输入 \(\boldsymbol{u}_t\),生成输出 \(\boldsymbol{o}_t\),同时产生内部组件——查询 \(\boldsymbol{q}_t\)、键 \(\boldsymbol{k}_t\) 以及自生成学习率 \(\beta_t\)。更新规则如下:
\[ W_t = W_{t-1} + \sigma(\beta_t) (\boldsymbol{v}_t - \bar{\boldsymbol{v}}_t) \otimes \phi(\boldsymbol{k}_t) \]这背后的直觉很简单: 网络学会根据新输入自行修改权重。
只有初始权重矩阵 \(W_0\) 被直接训练——它编码了学习的“元算法”。在元训练过程中,梯度下降会优化 \(W_0\),让后续的每一步自我更新 \((W_t)\) 实现理想的持续学习效果。
自动化持续学习 (ACL)
ACL 方法将持续学习问题与情境学习框架结合。
如果一个任务可表示为一系列样本,那么多个任务 (任务 A 接着任务 B) 就可表示为一个长的连接序列:
\[ (\text{任务 A 演示}, \text{任务 B 演示}) \]基于 SRWM 的模型从左到右处理该长序列。在处理任务 A 样本后,其状态变为 \(W_A\);处理任务 B 后,状态更新为 \(W_{A,B}\)。
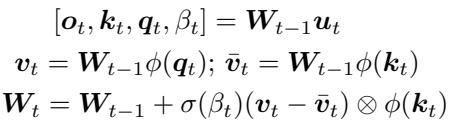
图: ACL 的序列处理框架。模型在旧任务和新任务上均被评估,以促进反向与正向迁移。
ACL 的目标函数
在每个任务边界处,ACL 都会测试模型在所有已学任务上的表现。训练时,它最小化以下综合目标:
[
- \Big[ \log p(y_A | x_A; W_A) + \log p(y_B | x_B; W_{A,B}) + \log p(y_A | x_A; W_{A,B}) \Big] ]
含义如下:
- \(p(y_A | x_A; W_A)\) — 正常学习任务 A
- \(p(y_B | x_B; W_{A,B})\) — 利用已有经验学习任务 B,促进正向迁移
- \(p(y_A | x_A; W_{A,B})\) — 在学习任务 B 后保持任务 A 的记忆,促进反向迁移
第三项是关键: 它将“记忆”直接嵌入学习目标中。元训练使梯度下降发现可自我更新而不丢失旧知识的内部学习规则。
训练完成后,ACL 可自主运行。其权重会递归演化——在适应新数据的同时保留先前学到的技能。
实验: 学习如何记忆
1. 证明情境遗忘确实存在
作者首先展示了普通情境学习器 (未使用 ACL) 同样会发生灾难性遗忘。他们用两个连续任务 (如 Omniglot → Mini-ImageNet) 对比了是否包含反向迁移项的模型。
结果揭示出显著差异。
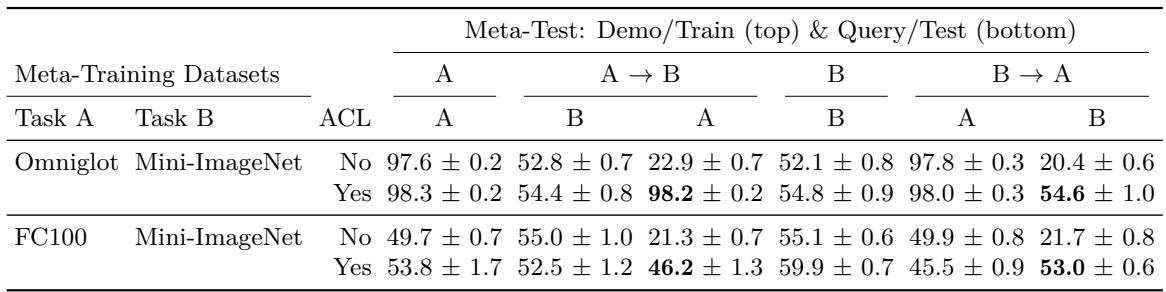
图: ACL 能防止跨任务的灾难性遗忘。
未使用 ACL 时,模型学习任务 B 后在任务 A 上的准确率降至约22%;而使用 ACL 后,任务 A 准确率保持在 98% 以上,记忆保留显著。
在 MNIST 和 CIFAR-10 等未见数据集上测试时结果类似:
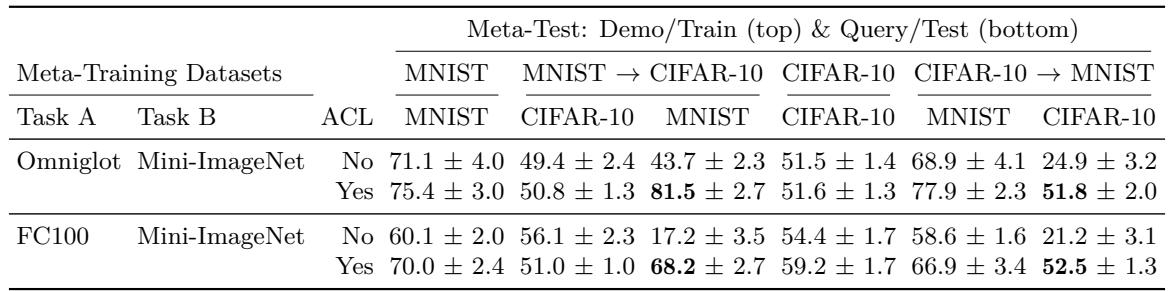
图: ACL 能很好泛化到未见数据集,防止情境遗忘。
2. 诊断遗忘原因
为理解情境学习器为何遗忘,作者跟踪了元训练过程中每个数据集的损失变化。
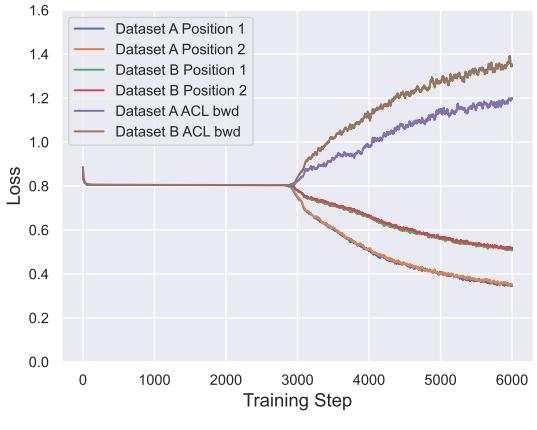
图: 相互竞争的力量——没有 ACL 的反向迁移项时,学习新任务会导致遗忘。
他们发现,模型在学习新任务的同时,旧任务的损失上升——也就是学习与记忆之间的权衡。ACL 的额外损失项解决了这一冲突,使各任务表现更平衡。
3. Split-MNIST 基准测试
为评估泛化能力,作者在 Split-MNIST 基准上测试了 ACL 模型: 这是五个连续的二分类任务 (0–1, 2–3, 4–5, 6–7, 8–9) 。
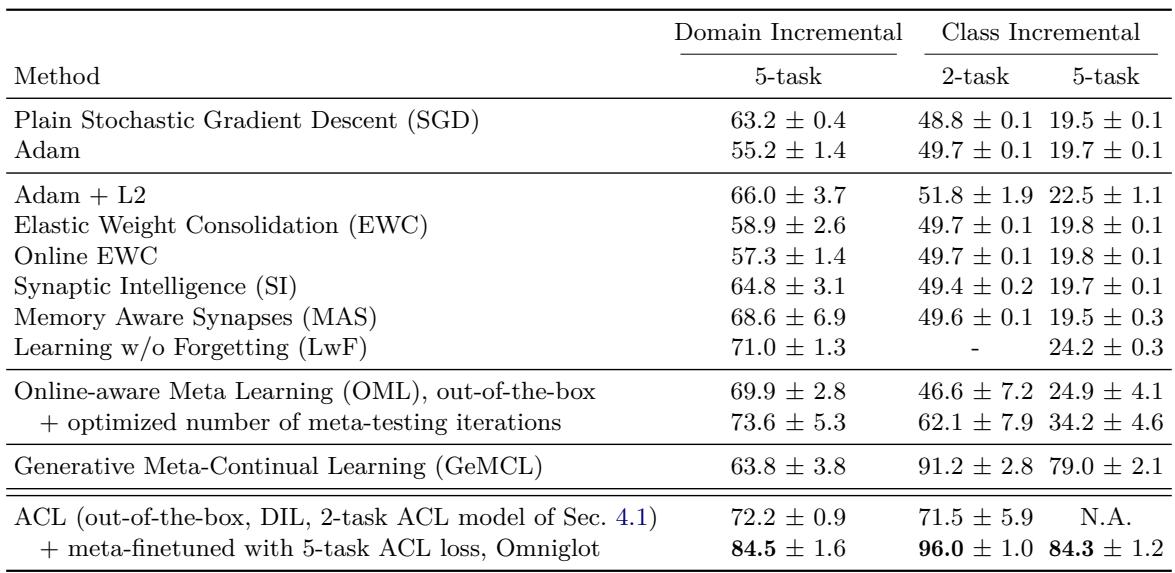
图: Split-MNIST 结果。ACL 达到最先进的无回放准确率。
即使仅在其他数据集 (如 Omniglot 与 Mini-ImageNet) 上训练,ACL 学到的算法也具备竞争力。经过 5 个任务的元微调后,ACL 超越所有现有无回放算法,准确率达 84–96% , 远优于经典方法如 EWC、SI 和基于 Adam 的优化。
4. 扩展到更复杂任务
现代持续学习基准常基于大型预训练视觉 Transformer (ViT) 并结合提示方法 (如 L2P、DualPrompt) 。作者在冻结 ViT 的情况下测试 ACL,以探索其扩展性。
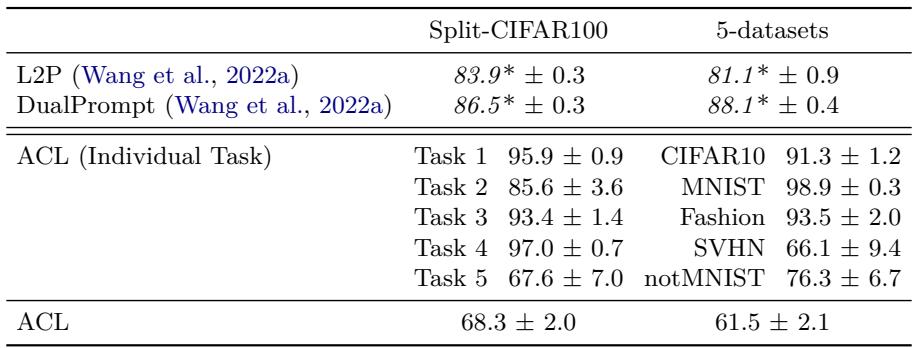
图: Split-CIFAR100 与 5-Datasets 基准结果。
在这些复杂情境下,ACL 性能有所下降。原因显而易见——元训练数据集有限 (仅 Omniglot 与 Mini-ImageNet) 。情境学习器需要更多样的元训练经历才能广泛泛化。扩大 ACL 的元训练数据规模可能弥合这一差距。
解读所学算法
ACL 的学习行为完全源自 SRWM 层内的自修改动态。那么内部究竟发生了什么?
作者将模型在处理任务序列时的权重矩阵演化过程进行了可视化。

图: 任务1学习期间 SRWM 权重可视化。

图: 任务2学习期间的 SRWM 动态。
这些复杂模式展示了丰富的时序动态。尽管难以直接解释,但它们暗示了自组织的学习机制——或许类似于人类突触适应。让这些模式变得可解释,是未来研究的一个有前景方向。
更广泛的启示
1. 算法设计自动化
ACL 标志着自动化 AI 研究迈出关键一步: 让神经网络自己发掘学习规则。不再需要人工手工设计防遗忘方案——而是梯度下降本身学会了持续学习该有的样貌。
2. 学到的算法是黑箱
SRWM 中的学习机制难以剖析——提醒我们强大的元学习系统可能会创造出人类尚未理解的策略。未来的可解释性研究可以尝试从这些网络中提取出可读的算法原理。
3. 与大语言模型的联系
ACL 为现代 LLM 卓越的情境学习能力提供了重要线索: LLM 在庞大、多样的序列上训练,具备持续的情境适应能力。现实世界数据可能天然带来类似 ACL 的目标,使大型模型成为“天然的”持续学习者。
结论
自动化持续学习 (ACL) 使神经网络能够学习如何持续学习。通过将持续学习的核心目标——记住旧任务并掌握新任务——直接嵌入元目标中,ACL 让梯度下降发现一种可行的自我参照学习规则。
训练完成后,ACL 能自主运行,在遇到新任务时修改自身权重,无需外部记忆或人为技巧。实验表明,它能克服灾难性遗忘,甚至在标准基准上超越传统方法。
尽管当前的 ACL 模型规模较小,但其愿景宏大: 构建可扩展、自我改进、能随时间演化自身学习算法的系统。这是未来的一瞥——AI 不仅能学习,还能随着成长而学会更好地学习。