](https://deep-paper.org/en/paper/2312.14069/images/cover.png)
你是否遇到过因为接收者听不到你说话的语气而误解短信的情况?句子 “I never said he stole my bag” (我从没说过他偷了我的包) 根据你重读这七个单词中的哪一个,会有七种完全不同的含义。
- “I never said he stole my bag” 暗示是别人说的。
- “I never said he stole my bag” 暗示你可能这么想过,但没说出口。
- “I never said he stole my bag” 暗示他可能是借走的。
这种细微差别被称为 韵律 (prosody) , 通常被描述为“语言的音乐”。它包括节奏、音高和响度。虽然现代 AI 在语音到语音 (S2S) 翻译和生成方面取得了巨大进步 (想想实时翻译设备或声音克隆) ,但它往往无法捕捉这一关键的意义层。大多数模型都是“平淡”的——它们把字词说对了,但意图却错了。
在这篇文章中,我们将深入探讨一篇解决这一确切问题的研究论文。研究人员介绍了 EmphAssess , 这是一个新的基准,旨在评估 S2S 模型是否能听出输入中的重音词,并将其正确地转移到输出中,即使是在语言之间进行翻译时也是如此。
背景: 韵律差距
在看解决方案之前,我们需要了解当前技术的不足。
自监督学习 (SSL) 彻底改变了语音处理。像 AudioLM 或 GSLM 这样的模型可以在不需要大量标记文本的情况下生成语音。然而,评估通常集中在内容 (模型说的词对吗?) 或说话人相似度 (听起来像原声吗?) 上。
评估 韵律——特别是像单词重音这样的 局部韵律 (local prosody)——非常困难,原因有二:
- 主观性: 人工评估是黄金标准,但它昂贵、缓慢且主观。一个人听起来像是有重音的,另一个人可能觉得很正常。
- 对齐问题: 在语音到语音翻译 (例如,英语到西班牙语) 中,你不能只是检查时间戳。如果输入强调的是 “red car” 中的 “red”,输出就需要强调 “coche rojo” 中的 “rojo”。单词的位置发生了变化,简单的声学指标无法完美对齐。
我们需要一种客观、自动的方法来衡量这种“重音转移”。这就是 EmphAssess 发挥作用的地方。
EmphAssess 流程
这篇论文的核心贡献是一个模块化的评估流程。目标很简单: 获取一个具有特定重音的输入音频文件,通过语音模型运行它,并检查输出音频是否在相应的正确单词上保持了该重音。
研究人员将其分解为一个系统化的过程。

如上图 1 所示,该流程主要分为两个阶段:
1. 输出生成 (左侧面板)
这是标准的推理步骤。你将输入音频 (例如,“The man saw a red car”) 输入到你想要测试的 S2S 模型中。模型生成一个输出波形。
2. 输入-输出重音比较 (右侧面板)
这是见证奇迹的时刻。评估系统需要“听”输出并进行评分。这涉及五个不同的步骤:
- ASR (自动语音识别): 首先,系统使用像 WhisperX 这样的模型将输出音频转录为文本。
- 强制对齐 (Forced Alignment): 它将文本与音频对齐,以找到输出中每个单词的确切时间边界 (开始和结束时间) 。
- 重音分类 (Emphasis Classification): 这是流程中技术上最新颖的部分。系统分析每个单词的波形片段,并判断它是否被重读。 (我们将在下一节详细介绍分类器 EmphaClass) 。
- 词对词对齐 (Word-to-Word Alignment): 如果模型执行了翻译 (例如,英语到西班牙语) ,系统必须映射单词。它使用对齐工具 (SimAlign) 来理解源语言中的 “red” 对应目标语言中的 “rojo”。
- 评估: 最后,它比较结果。如果输入的重音在 “red” 上,并且分类器检测到 “rojo” 上有重音,则为成功。如果重音落在了 “coche” (car) 上或完全缺失,则为失败。
核心引擎: EmphaClass
为了使这个流程正常工作,研究人员需要一种可靠的方法来通过程序检测重音。现有的方法通常依赖于手工设计的特征 (如查看原始响度或音高曲线) ,这些方法在不同的声音或录音条件下泛化能力较差。
作者介绍了 EmphaClass , 这是一个专门为此任务设计的深度学习分类器。
架构
他们没有从头开始构建模型,而是使用了 XLS-R , 这是一个基于 Wav2Vec 2.0 架构的大型多语言自监督模型。他们在一个二元分类任务上对该模型进行了微调: 查看 20 毫秒的音频帧并预测“这是重音吗?”
推理
为了确定整个单词是否被重读,模型会聚合该单词时间边界内所有帧的分数。如果一个单词中超过 50% 的帧被分类为重音,则该单词被标记为正样本。
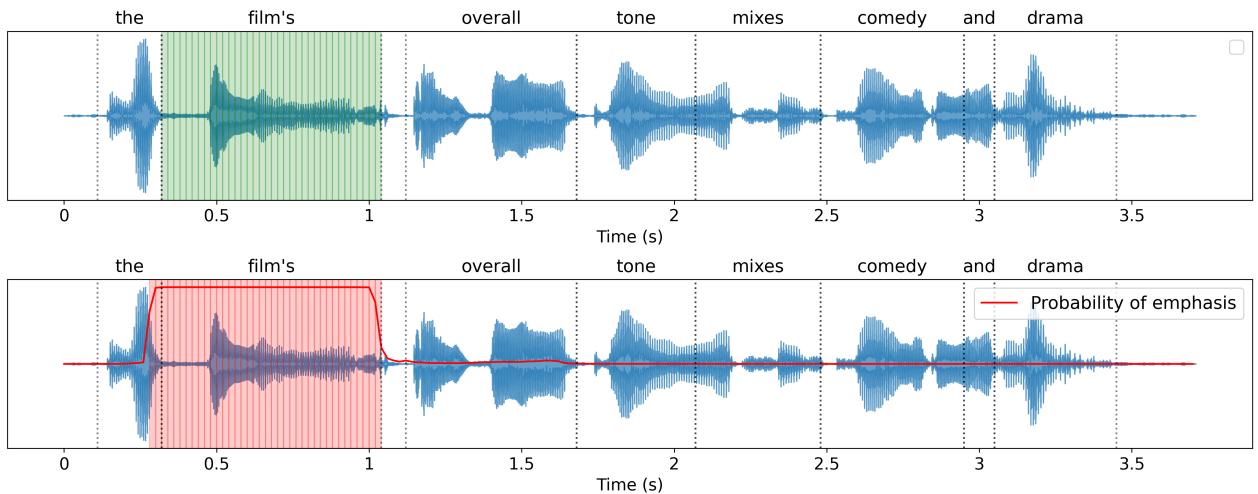
图 2 展示了 EmphaClass 的实际应用。顶部波形显示了基本真值 (ground truth)——单词 “film’s” 被重读。底部波形显示了模型的输出概率 (红线) 。你可以看到在 “film’s” 的时间段内出现了一个明显的概率峰值。这表明该模型不仅是看整个句子;它能够精确定位局部的韵律变化。
分类器性能
这个裁判有多可靠?研究人员在他们自己的合成数据集 (EmphAssess) 和自然语音数据集 (Expresso) 的子集上测试了 EmphaClass。
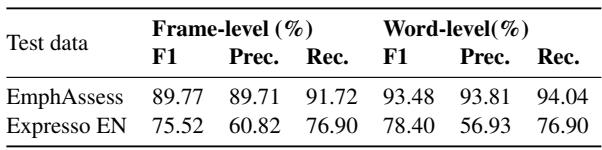
如表 1 所示,性能令人印象深刻。在 EmphAssess 数据集上,分类器达到了 93.48% 的词级 F1 分数 。 在 Expresso 数据集上的性能有所下降 (78.4%),这可能是因为真实的人类语音比基准测试中使用的合成声音更混乱、更微妙。然而,对于模型基准测试的目的而言,EmphAssess 上的高准确率提供了一个坚实的基础。
实验与结果
构建好流程并训练好分类器后,研究人员对几个最先进的模型进行了基准测试。他们关注两个任务: 语音重合成 (英语到英语) 和 语音翻译 (英语到西班牙语) 。
他们使用 精确率 (Precision)、召回率 (Recall) 和 F1 分数 来为模型评分。
- 精确率: 当模型添加重音时,是在正确的单词上吗?
- 召回率: 模型是否遗漏了本应重读的单词?
英语到英语结果
研究人员将“上限基准 (Topline)” (给定数据集约束下的理论最高分) 与三个模型进行了比较:
- GSLM (生成式口语语言模型): 一个标准的基线。
- pGSLM: 明确使用韵律特征 (音高和时长) 训练的 GSLM 版本。
- Seamless M4T: 一个大型多语言翻译模型。
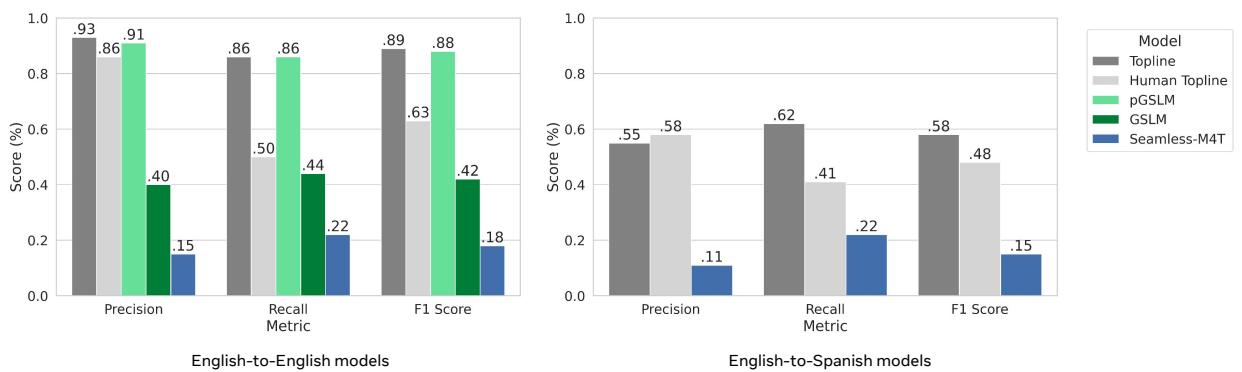
图 3 左侧的图表揭示了性能上的巨大差异:
- pGSLM (绿色柱): 表现几乎与上限基准一样好。因为它在训练时有明确的韵律目标,所以非常擅长保留重音。
- GSLM (深绿色): 性能显著下降 (F1 ~42%)。没有明确的韵律训练,模型丢失了大部分的细微差别。
- Seamless M4T (蓝色): 这个模型表现非常挣扎 (F1 ~18%)。虽然在翻译方面表现出色,但它似乎充当了一个“文本到语音”系统,转述了内容但完全丢弃了原始音频的风格线索。
英语到西班牙语结果
图 3 右侧的图表显示了翻译的结果。这是一个更难的任务。模型必须理解英语中的重音,翻译句子结构,并将重音应用到正确的西班牙语单词上。
- 上限基准 (Topline) 本身下降到了 58% F1 左右。这表明即使是“黄金标准”的西班牙语合成语音也没有完美地产生可检测到的重音,或者翻译过程引入了对齐误差。
- Seamless M4T 在这里表现也很差 (F1 ~14%)。它本质上是对翻译后的文本进行了平淡的朗读。
跨语言泛化能力
一个最有趣的次要发现是 EmphaClass 分类器在不同语言间的鲁棒性。研究人员在英语或西班牙语上训练分类器,并在越南语、意大利语和葡萄牙语等其他语言上进行了测试。
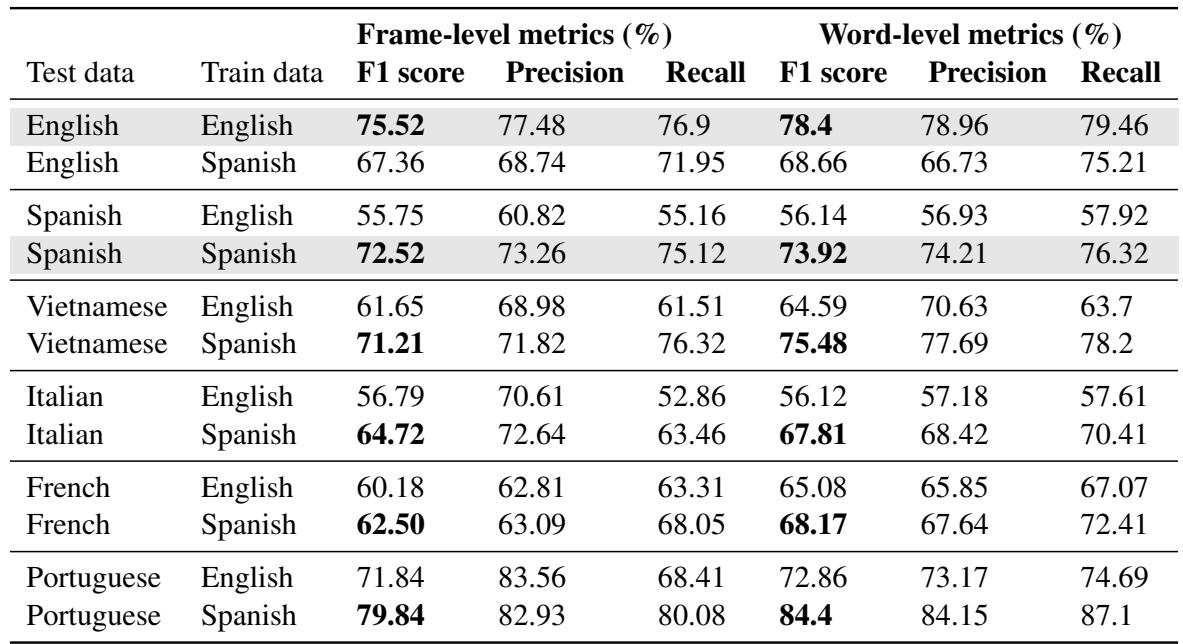
上表 (对应论文中的表 2) 展示了一些迷人的东西: 在西班牙语上训练的分类器 (“Train data” 为 Spanish 的行) 在其他罗曼语族语言 (意大利语、法语、葡萄牙语) 甚至越南语上都泛化得非常好。这表明“重要性”的声学线索 (更响、更长、音高更高) 可能在人类语言中共享通用的属性,或者至少 XLS-R 的表示足够鲁棒,能够捕捉到它们。
结论
EmphAssess 论文强调了当前语音 AI 中的一个关键“盲点”。虽然模型在说什么方面变得越来越流利,但它们仍在学习怎么说。
这项工作的关键要点是:
- 重音很重要: 它改变了含义,而当前的“最先进”翻译模型 (如 Seamless M4T) 实际上从信号中清除了这些信息。
- 我们可以测量它: EmphAssess 流程证明了我们不需要完全依赖昂贵的人工评估。我们可以构建自动化系统来追踪韵律转移。
- 韵律感知训练是有效的: pGSLM 的成功证明,如果我们明确告诉模型要关注音高和时长,它们是可以学会保留重音的。
随着我们迈向更自然的 AI 助手和实时翻译器,像 EmphAssess 这样的基准测试将至关重要。它们迫使开发者超越简单的词错误率,确保当 AI 说话时,它能传达信息的完整意图。