](https://deep-paper.org/en/paper/2312.17235/images/cover.png)
简介
想象一下,你正在观看一段三分钟的视频,视频内容是一个人组装一件复杂的家具。看完后,我问你: “这个人拿起的第一个工具是什么?”要回答这个问题,你需要回忆视频的开头,理解动作的顺序,并识别出那个物体。
对人类来说,这轻而易举。但对 AI 来说,这极其困难。
虽然计算机视觉已经精通了短片段 (5-10秒) 的处理,但理解“长时” (Long-range) 视频 (几分钟甚至几小时) 仍然是一个巨大的障碍。传统方法试图将海量的视觉数据塞进记忆库或复杂的时空图中,但这往往会遭遇计算瓶颈。
在这篇文章中,我们将探讨 LLoVi (Language-based Long-range Video Question-Answering,基于语言的长时视频问答) ,这是由北卡罗来纳大学教堂山分校 (UNC Chapel Hill) 的研究人员提出的一个框架。他们的方法出奇地简单: 与其构建一个更大、更复杂的视频模型,不如把视频变成一本书。通过将视觉数据转换为文本,并利用大型语言模型 (LLM) 的推理能力,LLoVi 无需任何训练步骤就取得了业界领先 (SOTA) 的结果。

如图 1 所示,传统的模型如 FrozenBiLM 难以捕捉长时间活动 (清洁狗垫) 的完整序列,而 LLoVi 则准确地综合了逐步的过程。
长时视频的问题
为什么长时视频问答 (LVQA) 如此困难?归根结底在于“上下文窗口”和信息密度。视频是由成千上万张图像 (帧) 组成的序列。每分钟处理每一帧的每一个像素需要巨大的计算内存。
为了解决这个问题,之前的研究人员开发了复杂的架构,包括:
- 记忆队列 (Memory Queues) : 存储过去的特征以便稍后调用。
- 状态空间层 (State-Space Layers) : 用于压缩序列的数学模型。
- 图神经网络 (Graph Neural Networks) : 映射跨时间的对象之间的关系。
然而,该领域还受到第二个问题的困扰: 数据集本身。许多“视频”数据集允许模型作弊。
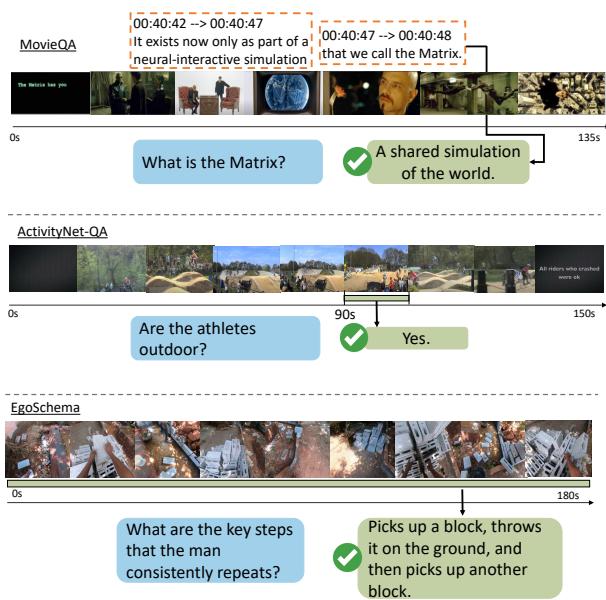
如图 4 所示,像 MovieQA 这样的数据集通常依赖字幕,这意味着模型只是在读剧本,而不是在看电影。其他如 ActivityNet-QA 提出的问题,只需看一眼 1 秒钟的片段就能回答 (例如,“他们在户外吗?”) ,这使得长期推理变得毫无必要。
LLoVi 论文重点关注 EgoSchema , 这是一个旨在“无法作弊”的基准测试。它由非常长的第一视角 (自我中心) 视频组成,答案需要综合整个时间线上的信息,且无法仅靠语言偏差来解决。
LLoVi 框架: 两阶段方法
LLoVi 的核心洞察在于,我们要的不是一个新的视频架构,而是一种将视频与现有智能系统连接起来的更好方式。该框架将 视觉感知 (看到正在发生什么) 与 时间推理 (理解它们如何关联) 解耦。
该方法分两个不同的阶段运行,且无需训练。
第一阶段: 短期视觉描述生成 (Visual Captioning)
首先,长视频被切分成密集的短片段 (范围从 0.5 到 8 秒) 。这些片段被输入到一个专门的“视觉描述生成器”——一个经过训练的模型,可以查看图像或短片段并用文本描述它。
这里使用的模型包括:
- LaViLa: 一个专门针对第一视角 (自我中心) 视频的模型,非常擅长描述动作。
- BLIP-2 / LLaVA: 强大的基于图像的模型,用于描述静态场景。
第二阶段: LLM 推理
一旦视频被转换为按顺序排列的文本描述 (Captions) 列表,“视觉”问题就转化为“长上下文语言”问题。这些描述按时间顺序拼接在一起,并输入到大型语言模型 (如 GPT-4 或 GPT-3.5) 中。然后,通过提示 (Prompt) 让 LLM 根据这些描述讲述的“故事”来回答问题。
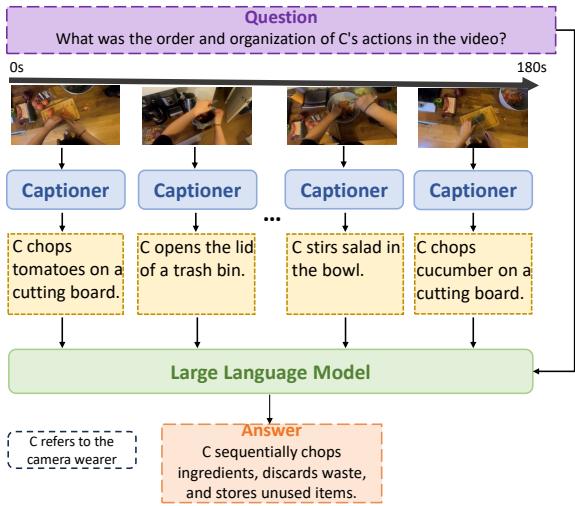
图 2 展示了这个流程。系统获取一段 180 秒的烹饪视频,将其分解为细粒度的描述 (例如,“切番茄”、“搅拌沙拉”) ,然后 LLM 推导出动作的逻辑顺序。
这种方法绕过了处理像素的内存瓶颈。文本是轻量级的。一个 LLM 可以轻松阅读 10 分钟视频的描述,而视觉 Transformer 试图处理原始帧时可能会崩溃。
“多轮摘要”提示 (Multi-Round Summarization Prompt)
仅仅将数百条描述丢给 LLM 并不能保证得到好的答案。生成的描述往往充满噪声、重复,或者与所问的具体问题无关。
例如,如果问题是“他在加盐之后加了什么配料?”,但描述中充满了关于厨房瓷砖或厨师衬衫颜色的细节,LLM 可能会分心 (产生幻觉) 。
为了解决这个问题,作者引入了 多轮摘要提示 (Multi-Round Summarization Prompt) 。
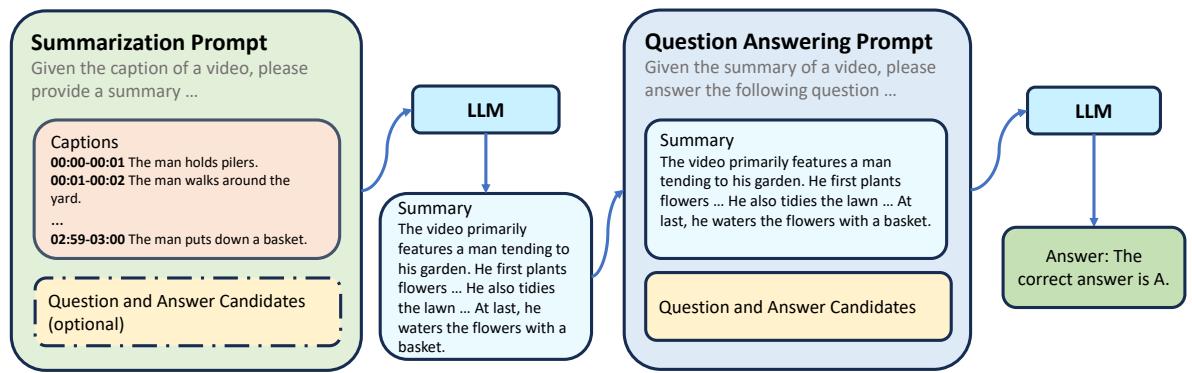
如图 3 所示,该策略将推理分为两步:
- 摘要轮: 给 LLM 提供原始描述和问题 (\(Q\)) 。要求它生成一个专门针对回答 \(Q\) 相关的视频摘要。
- 问答轮: 给 LLM 提供干净的摘要 (来自步骤 1) ,并要求其提供最终答案。
这起到了过滤器的作用。通过先要求 LLM 进行总结,强制模型筛选噪声并识别关键事件,在尝试解决逻辑难题之前丢弃无关细节。
实证分析: 是什么让 LLoVi 有效?
研究人员在 EgoSchema 数据集上进行了广泛的实验,以确定哪些组件最重要。
1. 视觉描述生成器的选择
并非所有的描述生成器都是一样的。该研究对比了通用图像描述生成器 (如 BLIP-2) 与视频专用描述生成器 (如 EgoVLP 和 LaViLa) 。

上表 11 中的定性比较凸显了差异。 LaViLa (专为第一视角视频开发) 生成简洁、以动作为核心的描述 (例如,“Person B talks to C”) 。相比之下,像 BLIP-2 这样的基于图像的模型通常专注于物体 (例如,“一件蓝色衬衫”) ,而不是事件的时间流。
定量来看,LaViLa 达到了最高的准确率( 55.2% ),证明了从视频到文本的“翻译”质量是该框架的瓶颈。
2. LLM 性能与成本
大脑重要吗?是的。研究人员测试了带有不同 LLM 的 LLoVi。
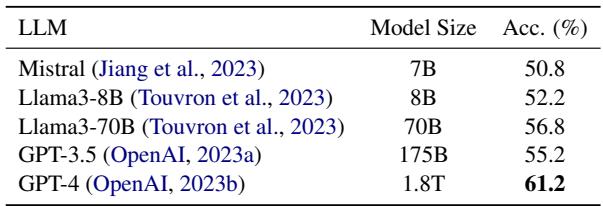
GPT-4 显著优于其他模型,达到了 61.2% 的准确率 (表 2) 。这证实了一旦视觉数据被文本化,长时视频理解很大程度上就是一个推理任务。不过,GPT-3.5 以 55.2% 的成绩成为了一个强大且具有成本效益的竞争者。
3. 视频采样策略
我们应该多久看一次视频?研究人员分析了片段长度和采样率。

表 3 显示 1 秒的片段 产生的性能最好。较长的片段 (例如 8 秒) 会导致细粒度细节的丢失。

然而,表 4 揭示了一个有趣的效率技巧。你不需要对每一秒都生成描述。每 8 秒采样一个 1 秒的片段 (留出空隙) ,准确率仅下降 2.0%,但系统速度提高了 8 倍 。 这种权衡对于速度优先的实际应用至关重要。
4. 提示词的影响
LLoVi 中最重要的软件创新是前面讨论的提示策略。

表 5 证实了这一假设: 标准提示 (仅给出描述 + 问题) 的准确率为 55.2%。然而, (C, Q) \(\rightarrow\) S 策略 (给定问题 \(Q\) 总结描述 \(C\),然后回答) 将准确率提高到了 58.8% 。 这表明 LLM 在总结视频日志时需要知道它在寻找什么。
定性结果: 成功与失败
查看具体示例有助于理解多轮摘要提示如何修复错误。

在图 9 中,标准提示失败了。原始描述充斥着重复的动作 (“拿起衣服”、“放下衣服”) 。LLM 感到困惑,猜测用户是在“打包行李”。
然而,在多轮方法 (底部) 中,LLM 首先生成了一个摘要: “在整个视频中,可以看到 C 从事与洗衣相关的任务……”这一抽象层使得第二阶段能够正确地将活动识别为“洗衣服”。
泛化到其他基准
虽然 EgoSchema 是主要的测试平台,但 LLoVi 并不是只能解决单一问题。研究人员将该框架应用于其他具有挑战性的数据集,如 NExT-QA (识别因果和时间关系) 和 IntentQA (理解人类意图) 。
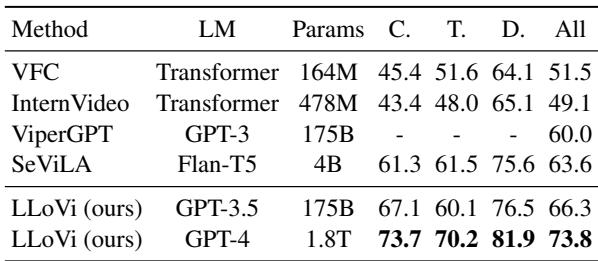
在 NExT-QA (表 8) 上,LLoVi 达到了 73.8% 的准确率,以 10.2% 的优势粉碎了之前的最先进技术 (SeViLA) 。在计算机视觉领域,这是一个巨大的优势。
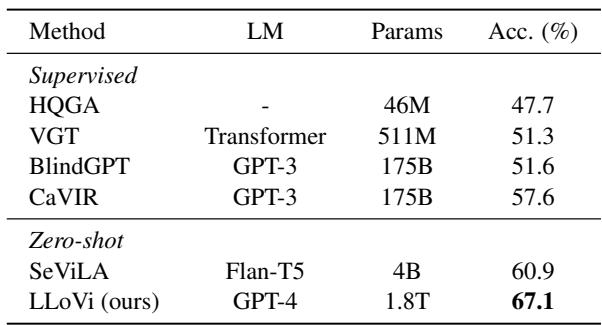
同样,在 IntentQA (表 9) 上,LLoVi 在监督和零样本基线上都占据主导地位。
结论
LLoVi 论文教会了我们关于现代 AI 的一个宝贵教训: 简单和模块化往往胜过复杂。
LLoVi 没有训练需要昂贵硬件和专门数据集的庞大端到端视频网络,而是分解了问题。它让计算机视觉做它最擅长的事 (描述场景) ,让 LLM 做它最擅长的事 (对长信息序列进行推理) 。
关键要点:
- 分解是强大的: 将 LVQA 拆分为“描述生成”和“推理”阶段,允许在两方面都使用最先进的工具。
- 无需训练的 SOTA: 你并不总是需要重新训练模型。LLoVi 仅通过正确的提示,就在 EgoSchema 和 NExT-QA 上取得了顶级结果,无需微调。
- 提示工程很重要: “多轮摘要”策略表明,你如何向 LLM 提问与你给它什么数据同样重要。
随着视觉描述生成器变得更加详细,以及 LLM 变得更聪明 (且更便宜) ,像 LLoVi 这样的框架很可能成为分析每天产生的海量视频数据的标准。