](https://deep-paper.org/en/paper/2401.05072/images/cover.png)
引言
像 GPT-4 这样的大型语言模型 (LLM) 彻底改变了我们与文本交互的方式。我们将它们视为无所不知的先知——能够回答复杂问题、编写代码并总结小说。自然地,我们期望它们也是杰出的翻译家。如果一个 LLM 在问答环节中知道某个特定的名人是谁,那么当要求它翻译包含该名人名字的句子时,它理应能做到,对吧?
令人惊讶的是,答案往往是否定的。
最近的研究发现了一个有趣但棘手的现象: LLM 的一般理解能力 (直接提问时它所知道的) 与其翻译特定的理解能力 (被要求翻译时它的表现) 之间存在错位 (misalignment) 。 模型可能非常清楚一个事实,但当置于翻译任务的语境中时,它会遭遇“泛化失败”,退化为字面翻译或错误的翻译。
看看下面的例子。当直接询问时,LLM 正确地识别出“文章” (Wen Zhang) 是一位中国演员。然而,当翻译包含该名字的句子时,模型将“文章”按字面意思处理为“article” (文章/论文) ,导致翻译结果不知所云。

为了解决这个问题,来自哈尔滨工业大学和鹏城实验室的研究人员提出了一种名为 DUAT (Difficult words Understanding Aligned Translation,难词理解对齐翻译) 的新颖框架。通过模仿高级人类译员的工作流程——识别难点概念、进行解释,然后再翻译——DUAT 显著提高了翻译质量。
在这篇文章中,我们将解构 DUAT 论文,探索它是如何弥合 LLM 的知识与其翻译输出之间的鸿沟的。
问题所在: 理解错位
在深入探讨解决方案之前,我们需要理解核心问题。LLM 接受了海量数据的训练,这赋予了它们广博的世界知识和特定的语言技能。然而,这两种能力并不总是相互沟通的。
当你提示 LLM 进行翻译时,它通常会根据训练中学到的模式进入一种特定的“模式”。它可能会像一个初级译员那样行事,专注于逐词替换,而不是利用它实际上拥有的深层理解。
研究人员将此称为泛化失败 (Generalization Failure) 。 在他们的实验中,他们发现这些失败占所有误译的 16% 到 32% 。 模型并不缺乏知识;它只是未能在“翻译模式”下调用这些知识。
传统方法与差距
标准的基于 LLM 的机器翻译通常依赖于 上下文学习 (In-Context Learning, ICL) 。 你为模型提供几个例子 (演示) 和源句子,并要求它生成目标句子。
在数学上,这看起来像这样:
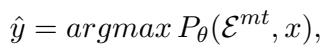
这里,模型试图在给定例子 (\(\mathcal{E}^{mt}\)) 和源句子 (\(x\)) 的情况下最大化翻译结果 (\(\hat{y}\)) 的概率。虽然这种方法对简单的句子有效,但它鼓励模型只是“遵循模式”,往往绕过了处理复杂隐喻、习语或实体所需的深度理解。
解决方案: DUAT
研究人员提出 DUAT,旨在强制模型在确立翻译之前先访问其一般理解能力。这个过程模仿了一位高级译员,当遇到棘手的短语时,他会停下来分析其在上下文中的含义,然后再进行翻译。
DUAT 框架包含三个不同的步骤:
- 难词检测 (Difficult Word Detection) : 找出句子中容易出错的部分。
- 跨语言解释 (Cross-Lingual Interpretation) : 要求模型解释这些词。
- 解释质量控制 (Interpretation Quality Control, IQC) : 过滤掉糟糕的解释,以指导最终翻译。
让我们看看完整的工作流程:
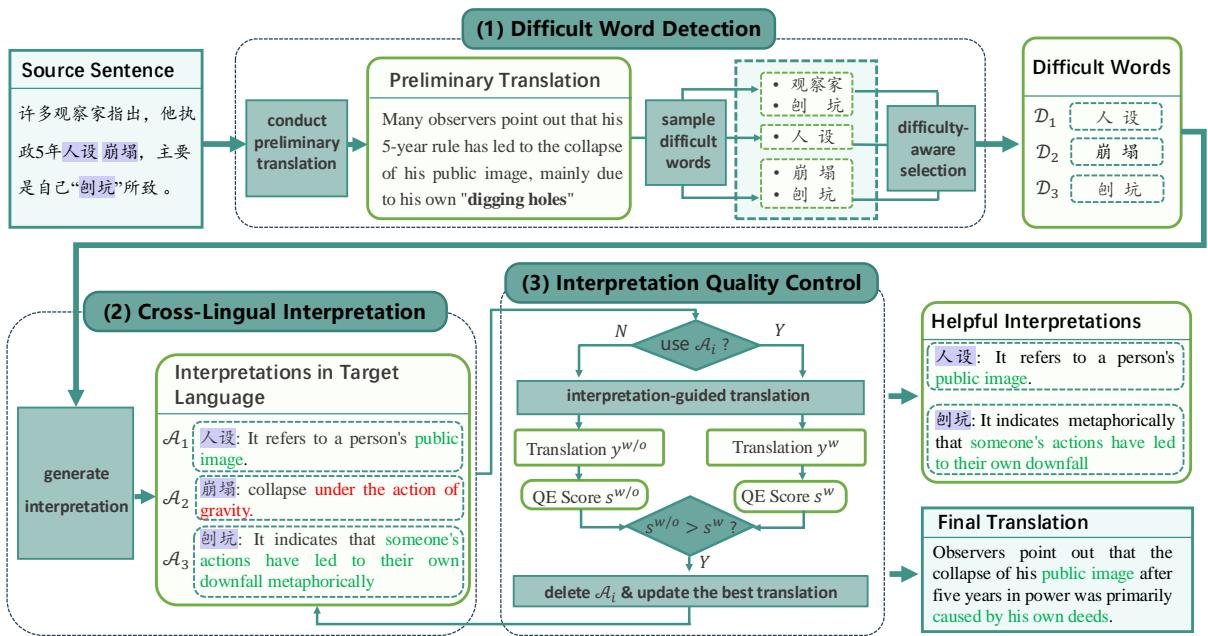
如上所示,系统首先识别难词 (如“人设”或特定的隐喻) ,生成解释 (例如,“它指的是一个人的公众形象”) ,并利用该解释生成更细致的翻译,而不是字面翻译。
第一步: 难词检测
模型怎么知道哪些词是“难词”?研究人员开发了两种方法: DUAT-I (内在) 和 DUAT-E (外在) 。
DUAT-I 只是简单地要求 LLM 基于草稿翻译识别难词。然而,LLM 经常有过度自信的问题——它们并不总是知道自己不知道什么。
DUAT-E 是更稳健的方法。它使用外部工具和采样策略。 首先,模型通过多次采样输出 (使用温度设置来鼓励多样性) 生成多个难词候选集。
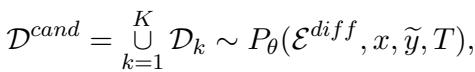
接下来,为了确定哪些词确实有问题,系统使用了词元级质量评估 (Token-level Quality Estimation, QE) 。 通常,QE 用于在不需要参考人工翻译的情况下检查翻译是否良好。在这里,研究人员反其道而行之: 他们使用 QE 来检查源词与草稿翻译的对齐程度。
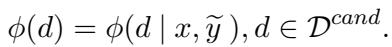
如果一个源词具有较高的错位分数 (\(\phi(d)\)) ,这意味着草稿翻译很可能未能捕捉到它的含义。这些词会被标记出来进入下一步。
第二步: 跨语言解释
一旦难词 (\(D\)) 被识别出来,模型就会被提示去解释它们。至关重要的是,DUAT 要求模型用目标语言提供这些解释。
为什么要用目标语言?如果我们是将中文翻译成英文,用英文解释一个中文习语有助于将模型的内部理解直接对齐到输出空间。
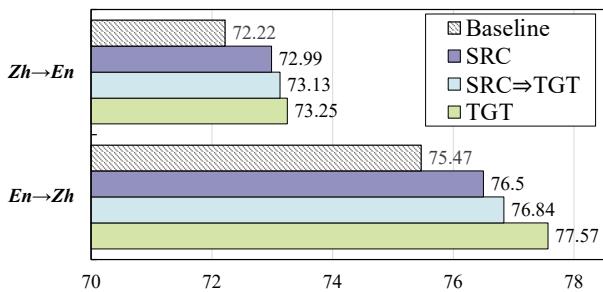
研究人员发现,这种“跨语言解释”比用源语言定义词语要有效得多。如下面的分析所示,目标语言的解释 (蓝色柱状图) 始终优于源语言的解释 (紫色柱状图) 。
第三步: 解释质量控制 (IQC)
这里存在一个风险: 如果 LLM 产生幻觉怎么办?如果模型生成了错误的解释,它可能会误导翻译,导致更糟糕的输出。
为了防止这种情况,DUAT 采用了解释质量控制 。 系统执行一个优化过程。它尝试使用解释来进行翻译。然后,它使用句子级质量评估评分器对结果进行评分。
如果移除某个特定的解释能提高 QE 分数,那么该解释就会被丢弃。最终的翻译仅使用“有帮助”的解释来生成。
实验设置: Challenge-WMT
标准的翻译基准测试对现代 LLM 来说通常太容易了,掩盖了它们的泛化失败。为了真正测试 DUAT,作者构建了一个名为 Challenge-WMT 的新基准。
他们收集了历史翻译比赛 (WMT) 中多个最先进系统 (如 Google 翻译和 ChatGPT) 历来表现不佳的句子。
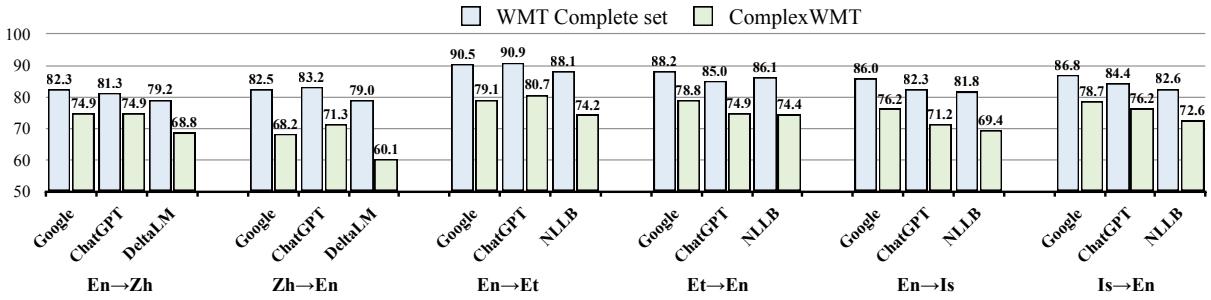
如上图 8 所示,与标准数据集 (蓝色柱) 相比,在这个数据集 (绿色柱) 上的性能显著下降,这证实了 Challenge-WMT 有效地针对了出现对齐问题的“困难”案例。
结果与分析
Challenge-WMT 上的结果令人信服。研究人员将 DUAT 与标准的零样本翻译 (Zero-shot) 、少样本 (ICL) 和思维链 (CoT) 提示进行了比较。
定量提升
DUAT 在高资源 (英-中) 和低资源 (英-爱沙尼亚语/冰岛语) 语言对上均优于基线。
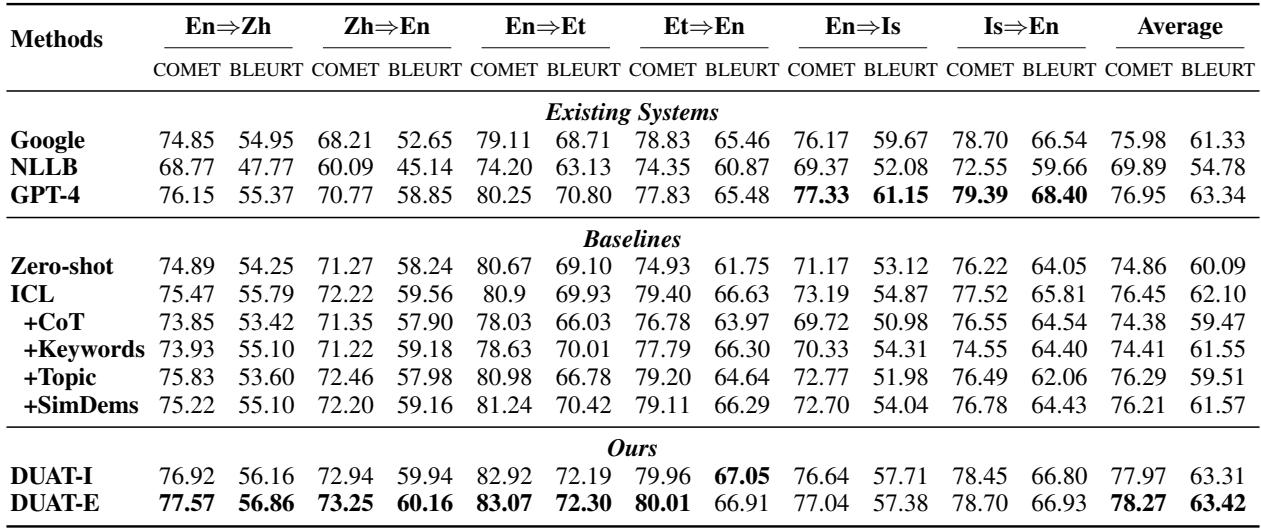
表 1 中的主要结论:
- DUAT-E (外在) 始终获得最高分 (加粗显示) 。
- 思维链 (CoT) 实际上损害了翻译任务的性能 (分数低于标准 ICL) 。作者认为这是因为 CoT 使模型模仿了过于啰嗦的“初级”译员,而 DUAT 模仿的是分析含义的“高级”译员。
- MAPS (一种使用关键词的竞争方法) 表现不佳,这表明专注于“难词”比关注广泛的关键词更有效。
定性成功案例
DUAT 的真正威力在实际例子中表现得最为明显。
案例 1: 隐喻 在下面的例子中,短语“刨坑” (digging holes) 是一个中文隐喻,意指自我破坏。标准翻译将其按字面意思处理 (物理上的挖坑) 。DUAT 正确地将其隐喻地解释为“某人的行为导致了自己的垮台”,从而得出了正确的翻译。

案例 2: 术语 在法律语境中,特定的首字母缩略词很重要。在这里,DUAT 正确识别了“ABH” (Actual Bodily Harm,实际身体伤害) ,而基线模型失败了,从而确保了翻译的法律准确性。

人工评估
像 COMET 和 BLEU 这样的指标很有用,但人工判断才是金标准。专业译员对输出结果进行了评估并对错误进行了分类。

表 4 显示,DUAT 显著减少了泛化失败 (即模型知道概念但误译的情况) 。此外,它还降低了直译度 (Literalness) (逐字翻译) ,从而产生了更自然、更像人类的文本。
消融实验: 我们需要所有部分吗?
你可能会想,复杂的“质量控制”或“草稿翻译”步骤是否是必要的。消融实验证实了它们确实必不可少。
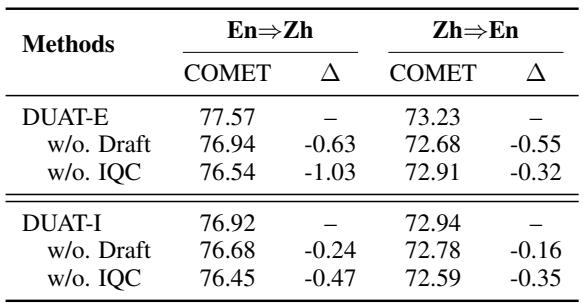
移除草稿翻译 (用于检测) 或 IQC (质量控制) 都会导致整体性能下降。IQC 尤为重要;没有它,糟糕的解释就会溜进来并混淆模型。
“难度”阈值
最后,研究人员分析了系统在检测难词时应该有多敏感。这由阈值参数 \(\tau\) (tau) 控制。
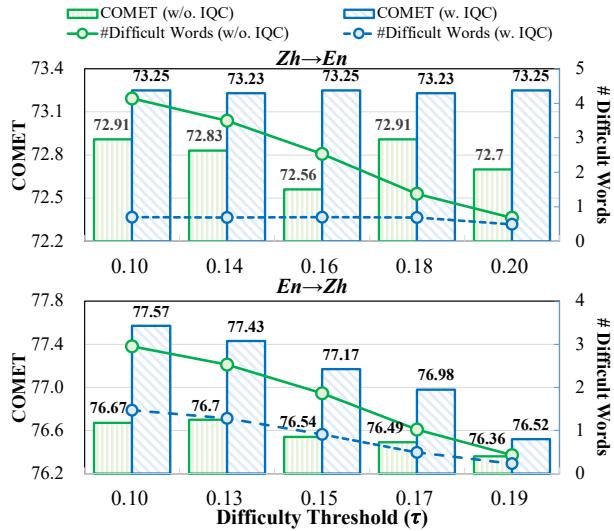
分析显示了一个清晰的趋势: 使用 IQC (蓝线) 允许模型解释更多的词而不会损失性能。不使用 IQC (绿线) 时,试图解释太多的词会引入噪音并降低质量。这证明了过滤解释与生成解释同样重要。
结论
DUAT 框架强调了关于大型语言模型的一个关键见解: 拥有知识并不保证能应用知识。 仅仅因为 LLM 在问答环境中“知道”一个事实,并不意味着它会在翻译过程中使用该事实。
通过明确地强制模型:
- 识别它觉得困惑的内容,
- 解释这些概念成目标语言,以及
- 验证这些解释,
DUAT 有效地将模型的深层一般理解能力与其翻译能力对齐。它使机器翻译从简单的模式匹配转向了更类似于人类专业知识的认知分析过程。
对于 NLP 领域的学生和研究人员来说,DUAT 提醒我们,提示工程和管道设计不仅仅是要求模型“做 X”。它是关于理解模型的内部认知失调,并设计能够弥合这些鸿沟的架构。