](https://deep-paper.org/en/paper/2401.10440/images/cover.png)
破除诅咒: X-ELM 如何让多语言 AI 走向大众化
想象一下,你正试图收拾一个要去环球旅行的行李箱。你需要准备去俄罗斯的冬装、去埃及的轻薄亚麻衣服,以及去伦敦的雨具。如果你只有一个行李箱,空间迟早会不够用。你不得不做出妥协——也许得把雨伞留下,或者带一件薄一点的外套。这就是多语言的诅咒 (Curse of Multilinguality) 。
在自然语言处理 (NLP) 的世界里,我们通常训练庞大的、“稠密”的多语言模型 (如 BLOOM 或 XGLM) ,试图用单一的一组参数同时学习 100 多种语言。结果呢?竞争。各种语言在模型内部争夺容量。因此,这些多语言巨头在特定语言 (如斯瓦希里语) 上的表现,往往不如仅针对该语言训练的较小模型。
但是,如果我们不再只用一个巨大的行李箱,而是拥有一支协调一致的旅行团队,每个人都携带针对特定地区的装备,那会怎样呢?
这就是跨语言专家语言模型 (X-ELM) 的前提。在一篇来自华盛顿大学和查理大学的精彩论文中,研究人员提出了一种模块化方法,它打破了多语言的诅咒,在同等计算预算下击败了标准的稠密模型,并使较小的研究实验室也能进行模型训练。
背景: 稠密模型的瓶颈
在剖析 X-ELM 之前,我们需要了解现状。标准的多语言大型语言模型 (LLM) 是稠密 (dense) 的。这意味着对于处理的每一个文本 token (无论是英语、中文还是阿拉伯语) ,模型都会激活其所有参数。
这种方法有两个主要的缺点:
- 语言间竞争: 如前所述,高资源语言 (如英语) 往往会在模型权重中占据主导地位,导致低资源语言出现“灾难性遗忘”或表现不佳。
- 硬件要求: 训练一个稠密模型需要同时在数百个 GPU 之间同步梯度。如果你没有超级计算机集群,就无法参与这场游戏。
为了解决这个问题,作者改编了一种称为分支-训练-合并 (Branch-Train-Merge, BTM) 的技术。BTM 的核心思想很简单: 与其在所有数据上训练一个模型,不如在不同的数据子集上独立训练几个“专家”模型,然后将它们合并。
X-ELM 架构
X-ELM 专门针对多语言环境扩展了 BTM 范式。该过程包括四个关键阶段: 数据分配、分支、训练和合并。
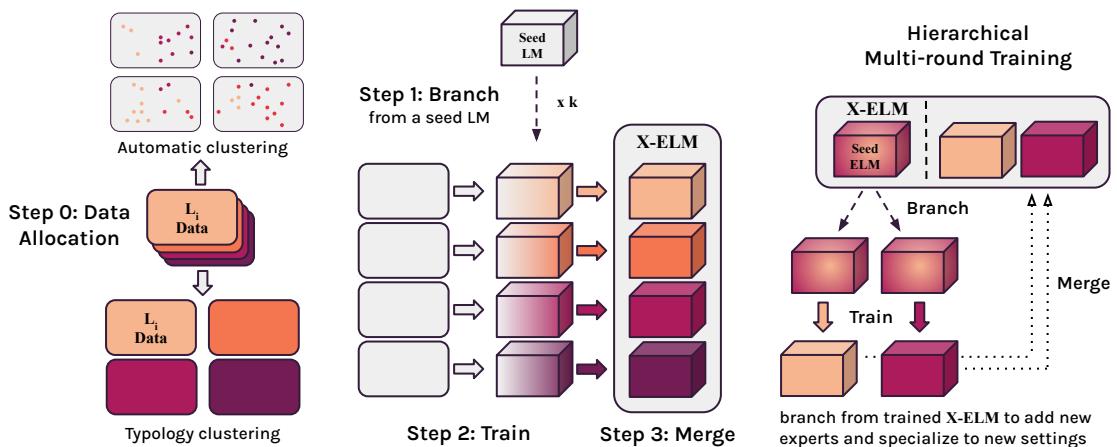
1. 数据分配: 定义专家
第一个挑战是决定如何分割多语言数据。如果我们想训练 \(k\) 个不同的专家,哪个专家获得哪些数据?研究人员探索了两种聚类方法:
A. 平衡 TF-IDF 聚类: 这种方法利用文本的统计特性。文档基于词语重叠进行分组。这在理论上是语言无关的,但倾向于根据词汇表对文本进行聚类。
B. 语言类型学聚类 (胜出者) : 这是基于语言学动机的方法。研究人员没有让算法盲目地对文档进行分类,而是使用了基于语言相似性的层级树。他们使用了 LANG2VEC 工具,该工具根据语言特征 (如句法和音系) 来衡量相似性。
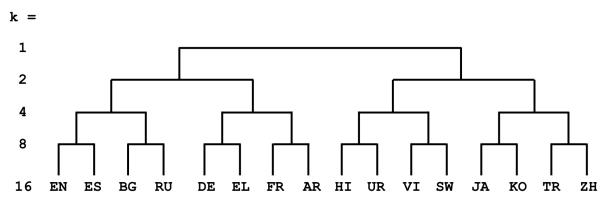
如上图 2 所示,语言按语族分组。例如,在有 4 个专家 (\(k=4\)) 的情况下,“罗曼语族”专家可能处理法语和西班牙语,而“斯拉夫语族”专家处理俄语和保加利亚语。这确保了专家可以从相关语言中学习,从而实现正向迁移 (例如,懂西班牙语有助于你对法语进行建模) 。
2. 分支、训练和合并
一旦数据分配完毕,训练过程就会出奇地高效:
- 分支 (Branch) : 不需要从头开始。每个专家都从一个“种子”模型 (本文中为 XGLM-1.7B) 初始化。这确保了专家已经对语言有了通用的理解。
- 训练 (Train) : 每个专家在其分配的数据集群上独立训练。这一点至关重要。因为它们是独立的,专家 A 不需要与专家 B 通信。你可以在不同的时间、不同的硬件或不同的实验室里训练它们。这创造了异步训练,大大降低了准入门槛。
- 合并 (Merge) : 最后,这些专家被收集成一个集合,即 X-ELM。
3. 推理: 让团队协同工作
当我们希望 X-ELM 生成文本或回答问题时,我们必须决定询问哪个专家。论文提出了几种方法:
- Top-1 专家: 我们简单地选择最专精于目标语言的专家。如果我们要评估德语,就使用在日耳曼语族集群上训练的专家。
- 集成 (Ensembling) : 我们可以同时使用所有专家,根据它们对输入的适应程度来加权它们的贡献。
集成概率通过以下公式计算:
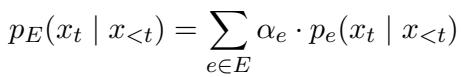
在这里,\(\alpha_e\) 代表特定专家的权重。如果输入看起来像西班牙语,经过西班牙语训练的专家会获得高 \(\alpha\) (权重) ,而经过中文训练的专家则获得低权重。
实验: 它有效吗?
研究人员使用 mC4 数据集在 16 种语言上测试了 X-ELM。他们通过确保 X-ELM 集成模型与稠密基线模型之间的计算预算 (看到的 token 总数) 相同来控制实验。
寻找最佳平衡点 (\(k\))
是拥有 16 个单语言专家 (每种语言一个) 更好,还是拥有更少但共享语言的专家更好?
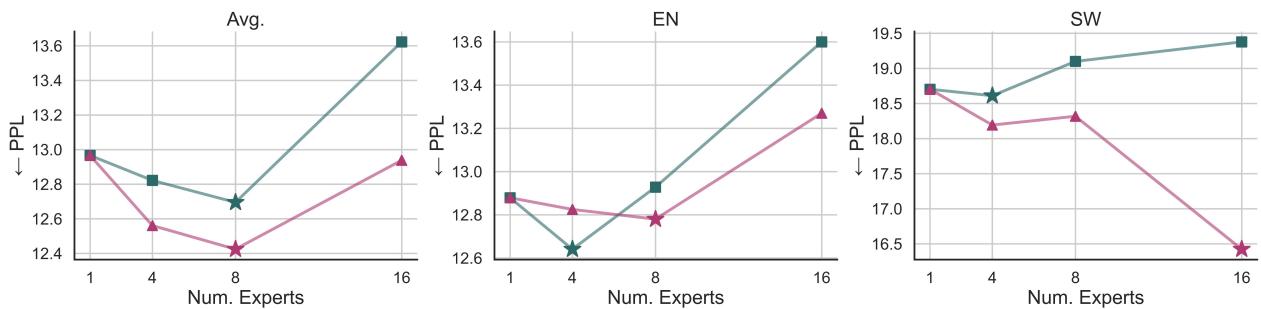
图 3 揭示了一个有趣的“金发姑娘 (Goldilocks) ”区域 (即最佳平衡点) 。
- 左侧 (Avg): 平均困惑度 (越低越好) 在 \(k=8\) 个专家时最低。
- 右侧 (SW - 斯瓦希里语): 虽然斯瓦希里语更喜欢专用专家 (\(k=16\)) ,但大多数语言受益于与相关语言共享参数 (\(k=8\)) 。
值得注意的是, 类型学聚类 (三角形) 的表现始终优于 TF-IDF 聚类 (正方形) 。这证实了按语族对语言进行分组比按原始词汇统计数据分组更有效。
性能提升
结果是决定性的。在同等计算预算下:
- X-ELM 的表现优于稠密基线模型 , 这在所有 16 种考虑的语言中都成立。
- 类型学很关键: 单语言专家 (\(k=16\)) 的表现通常不如按类型学聚类的专家 (\(k=8\)) 。这表明“语言针对性的多语言能力”优于纯粹的单语言训练。
对低资源语言的公平性
对多语言模型的一个普遍批评是,它们偏向英语而抛弃了低资源语言。X-ELM 能解决这个问题吗?
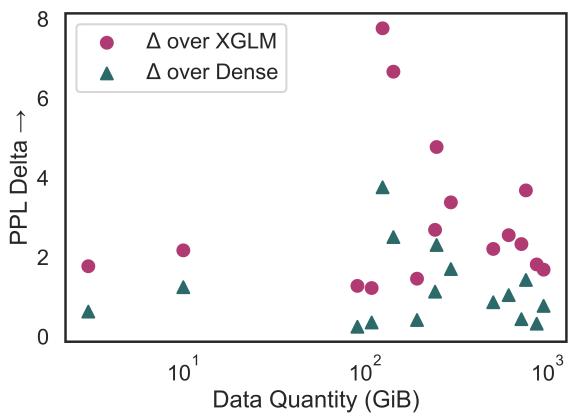
图 4 绘制了性能提升 (Delta PPL) 与可用数据量的关系。
- 青色三角形显示了相对于稠密基线的提升。
- 趋势相对平坦或略呈负相关,这意味着 X-ELM 为高资源语言和低资源语言都提供了实质性的收益。它并没有不成比例地偏向“富裕”语言。
下游任务 (上下文学习)
困惑度 (模型预测下一个词的能力) 并不总是能转化为任务表现。为了验证他们的发现,作者在 XNLI (自然语言推理) 和 XStoryCloze 等任务上评估了 X-ELM。
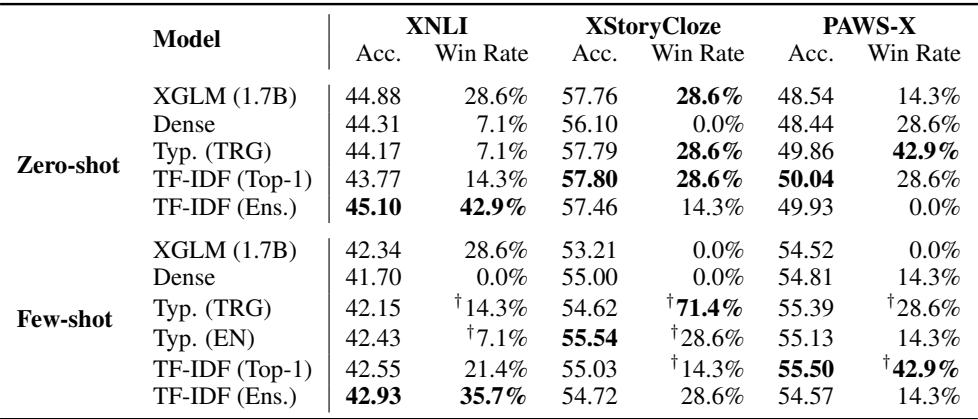
如表 3 所示,X-ELM (类型学) 模型在零样本和少样本设置下,都比稠密基线模型实现了更高的准确率和“胜率”。这证实了语言建模能力的提升转化为了更好的推理和理解能力。
HMR: 适应新语言
这篇论文最令人兴奋的贡献可能就是分层多轮 (Hierarchical Multi-Round, HMR) 训练。
标准的稠密模型很难更新。如果你想在一个用英语和俄语训练的模型中加入阿塞拜疆语,你通常必须继续训练整个庞大的模型,这会面临“灾难性遗忘”的风险,即模型为了学习阿塞拜疆语而忘记了英语。
利用 X-ELM 和 HMR,你可以利用语言树 (见图 2) 作为优势。
- 确定一个捐赠 (Donor) 语言 (例如,土耳其语在语言学上与阿塞拜疆语相似) 。
- 选取在土耳其语集群上训练的专家。
- 从该专家分支出一个副本。
- 在阿塞拜疆语上训练这个新副本。
研究人员在四种未见过的语言上进行了测试: 阿塞拜疆语、希伯来语、波兰语和瑞典语。
结果: HMR 的表现优于标准的语言适应性预训练 (LAPT) 。通过从相关专家分支,模型能更快、更有效地学习新语言,且不会降低原始专家的性能。
分析: 数据分布与遗忘
为了理解 X-ELM 为什么有效,我们可以看看数据的分布方式以及专家实际上记住了什么。
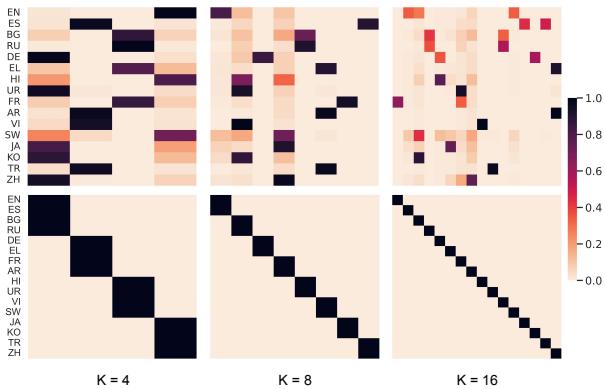
图 5 可视化了数据分割。底行 (类型学) 显示了清晰、硬性的分配——每种语言归属于一个专家。顶行 (TF-IDF) 显示了更混乱的分布。类型学方法的清晰分离最大限度地减少了远距离语言之间的负面干扰 (例如,中文和英语不会在同一个专家内部争夺空间) 。
然而,专业化是有代价的: 遗忘 。
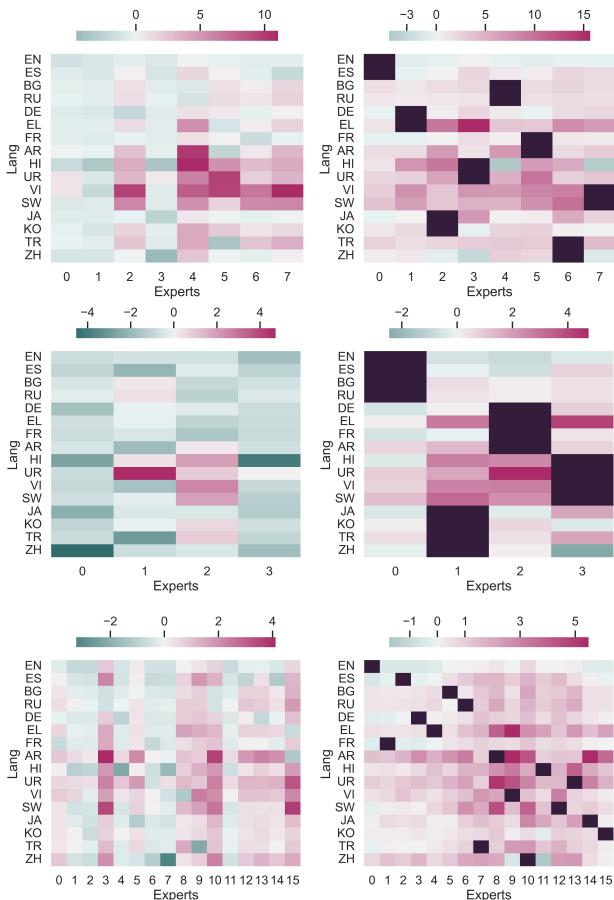
在图 6 中,深红色区域表示专家“遗忘”了的语言 (与种子模型相比困惑度增加) 。
- 右侧 (类型学) : 你可以看到明显的区块。专注于欧洲语言的专家遗忘了亚洲语言,反之亦然。
- 这是一个特性,而不是漏洞。 因为我们在推理时集成这些专家,所以“亚洲专家”忘记法语并不重要,因为“欧洲专家”记得它。这种高效的“遗忘”使得每个专家能够最大限度地发挥其针对指定语言的容量。
结论与启示
“多语言的诅咒”长期以来一直暗示我们必须做出选择: 要么是一个庞大、昂贵但在各方面表现平平的模型,要么是许多无法相互交流的专用模型。X-ELM 证明了还有第三条路。
通过结合分支-训练-合并与语言类型学 , X-ELM 提供了:
- 更好的性能: 在相同预算下击败稠密模型。
- 效率: 允许异步训练 (无需庞大的 GPU 集群) 。
- 灵活性: 可以通过 HMR 添加新语言,而无需重新训练整个系统。
这种方法让多语言 NLP 走向了大众化。它允许较小的研究小组向更大的集成系统贡献“专家”,从而逐步构建一个能力更强的全球系统。我们现在不必再拖着一个沉重的行李箱,而是可以携带一套组织完美的专用行李,随时准备应对世界上任何一种语言。