](https://deep-paper.org/en/paper/2402.01348/images/cover.png)
想象一下,你教你的智能家居助手识别家庭成员。它完美地学会了识别你的父母、兄弟姐妹和伴侣。然后,你带回家一只新小狗,并教它认识这只宠物。第二天,当你让它识别你的妈妈时——它突然不知道她是谁了。它已经完全忘记了。
这个令人沮丧的场景揭示了人工智能领域一个被称为灾难性遗忘的现象。深度神经网络虽然功能强大,但在不丢失先前知识的情况下,很难按顺序学习新信息。这一局限性阻碍了人工智能实现真正的终身学习——即像人类一样持续获取、整合并应用知识的能力。
最近的一篇论文《CORE: 通过认知回放缓解持续学习中的灾难性遗忘》 (“CORE: Mitigating Catastrophic Forgetting in Continual Learning through Cognitive Replay”) 正面解决了这一问题。研究人员从人脑的记忆系统中汲取灵感,提出了一种更智能的方法,称为认知回放 (COgnitive REplay,简称 CORE) 。这种方法不仅帮助模型记忆,还能让它进行策略性记忆——关注遗忘了什么以及学习内容被强化的深度。
本文将解析 CORE 的核心思想,看看它如何架起神经科学与机器学习之间的桥梁,打造更持久、更接近人类的 AI 记忆。
挑战: 在学习中避免遗忘
持续学习 (Continual Learning,CL) 是一种机器学习范式,模型在这种范式下从连续的数据流中顺序学习各个任务。它在现实场景中至关重要——例如,自动驾驶汽车遇到新的路标,或网络安全系统识别新型的网络钓鱼模式。
问题在于灾难性遗忘。当神经网络针对一个新任务进行训练时,它会调整数百万个内部参数,以在该任务上表现出色。但这些调整往往会覆盖此前任务学到的参数,导致旧知识消失。
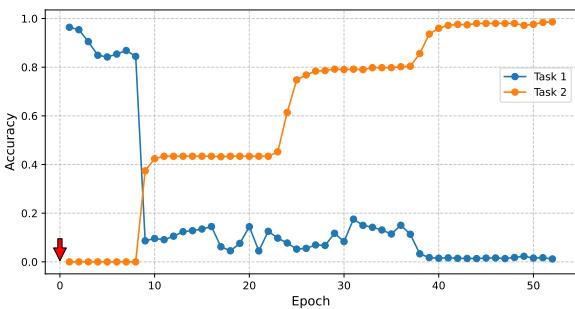
图 1: 当模型开始训练任务 2 时,任务 1 的准确率急剧下降——这是灾难性遗忘的典型例证。
这种准确率的剧烈下降使得持续学习特别具有挑战性。要设计能够随时间持续学习的 AI,我们必须打破这种学习与遗忘的破坏性循环。
研究人员如何防止遗忘
当前主要有三种方法来应对灾难性遗忘:
- 参数隔离 (Parameter Isolation) : 为每个任务分配独立的网络参数或模块 (如渐进式神经网络) 。虽然有效,但扩展性较差——内存占用随任务数量线性增长。
- 正则化 (Regularization) : 惩罚那些显著改变对过去任务重要参数的更新。这类方法 (如 EWC、LwF) 依赖于准确评估参数重要性,而在大型网络中这非常困难。
- 数据回放 (Data Replay) : 将部分旧数据保存到“回放缓冲区”中。当训练新任务时,模型同时学习新旧数据,实现“复习”。
数据回放模仿了人类的学习习惯,但多数现有回放策略对所有任务和样本都一视同仁。这种一刀切做法浪费了缓冲空间在模型已经记得牢的任务上,而忽略了那些正在快速遗忘的任务。
CORE 的突破性理念是让回放过程变得认知自适应: 为逐渐遗忘的任务分配更多“复习时间”,并确保回放数据既多样又具代表性。
向大脑学习: 认知启示
人类的记忆受两种主要遗忘机制影响:
- 认知过载 (Cognitive Overload) : 当新信息太多时,由于系统容量有限,旧记忆被挤出。
- 干扰 (Interference) : 新信息与旧记忆重叠或冲突,因共享表征而削弱记忆提取能力。
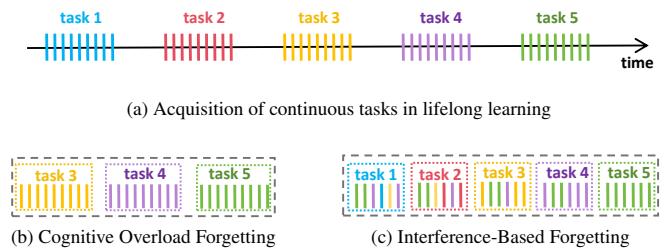
图 2: 人类的持续学习过程,包括 (a) 顺序任务学习,(b) 认知过载,以及 (c) 基于干扰的遗忘。
人类会自然地使用以下策略来抵消这些效应:
- 目标性回忆 (Targeted Recall) : 将注意力集中在薄弱或逐渐消退的记忆上。
- 间隔重复 (Spaced Repetition) : 以递增的间隔复习学习材料。
- 加工深度 (Levels of Processing) : 深度参与内容,形成更丰富、更持久的记忆痕迹。
CORE 将这些认知原理直接融入其学习系统设计中。
CORE 方法: 智能回放
CORE 通过两项关键创新改进基于回放的学习:
- 自适应数量分配 (Adaptive Quantity Allocation,AQA) ——决定每个过去任务该保留多少数据用于复习。
- 高质量数据选择 (Quality-Focused Data Selection,QFDS) ——挑选最能代表每个任务的样本。
这两者共同让回放缓冲区成为一个具有认知智能的“复习者”。
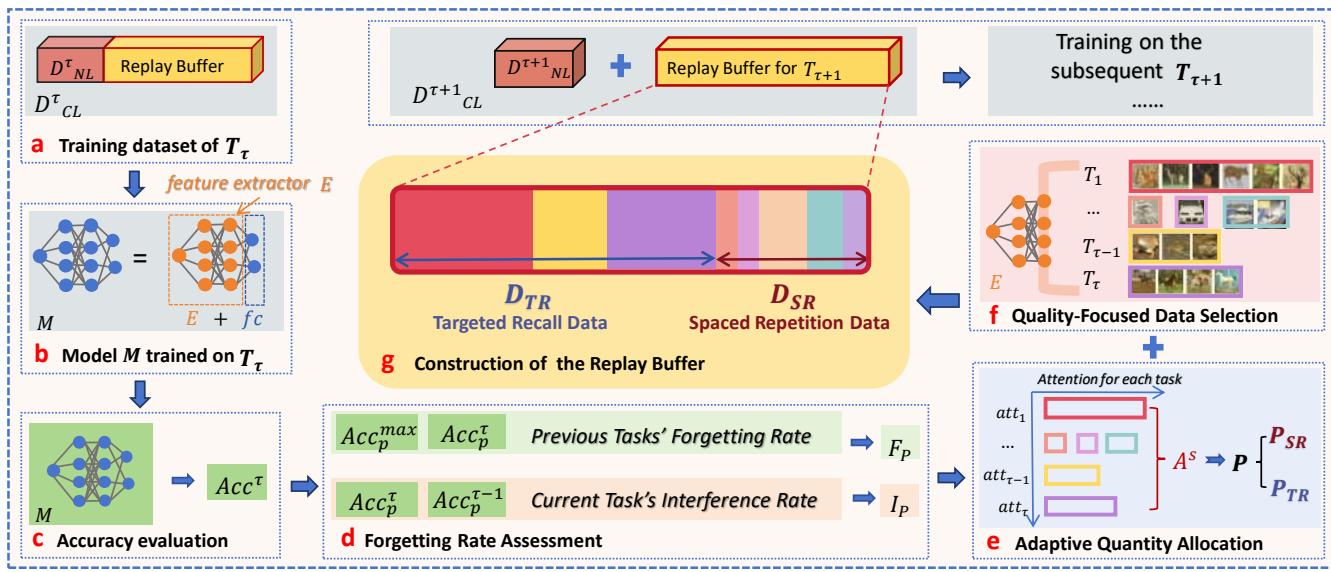
图 3: CORE 的整体流程。系统在学习完一个任务后,测量遗忘与干扰程度,并通过自适应分配与高质量数据选择构建回放缓冲区。
步骤 1: 诊断遗忘
在模型完成当前任务 \(T_{\tau}\) 的训练后,CORE 会测量每个先前任务被遗忘的程度。
过去任务的遗忘率: 对于每个早期任务 \(p\),CORE 计算其准确率从历史最佳到当前值的降幅:
\[ F_{\mathcal{P}} = \left\{ f_p = \max_{i \in \{1, \dots, \tau-1\}} Acc_p^i - Acc_p^{\tau} \mid p \in \mathcal{P} \right\} \]较高的 \(f_p\) 表示遗忘速度快。
当前任务的干扰率: 由于新任务尚未经历遗忘,CORE 通过其对旧任务性能的影响来估计其干扰性。干扰越大,未来被遗忘的风险越高:
\[ I_{\mathcal{P}} = \left\{ i_p = \frac{e^{Acc_p^{\tau-1} - Acc_p^{\tau}}}{\sum_{p' \in \mathcal{P}} e^{Acc_{p'}^{\tau-1} - Acc_{p'}^{\tau}}} \mid p \in \mathcal{P} \right\} \]该归一化指标揭示了任务间的相互作用。
步骤 2: 规划复习时间——自适应数量分配 (AQA)
在诊断出遗忘情况后,CORE 会智能地分配缓冲区资源。
注意力计算: 每个任务的“注意力分数”与其遗忘或干扰严重程度成正比:
\[ att_p = -\log(1 - f_p) \]\[ att_{\tau} = -\log\left(1 - \sum_{p \in \mathcal{P}} f_p \cdot i_p \right) \]随后,对分数进行归一化,将任务划分为两类:
\[ p \in \begin{cases} \mathcal{P}_{SR}, & \text{if } att_p^s \le \frac{1}{\lambda | \mathcal{P} |} \\ \mathcal{P}_{TR}, & \text{if } att_p^s > \frac{1}{\lambda | \mathcal{P} |} \end{cases} \]- 目标性回忆 (\(\mathcal{P}_{TR}\)): 被遗忘严重的任务获得集中复习。
- 间隔重复 (\(\mathcal{P}_{SR}\)): 稳定任务获得定期轻量复习。
缓冲区容量随后分配如下:
\[ \hat{att}_p = \frac{1}{\lambda |\mathcal{P}|}, \quad \text{if } p \in \mathcal{P}_{SR} \]\[ \hat{att}_p = \left(1 - \frac{|\mathcal{P}_{SR}|}{\lambda |\mathcal{P}|}\right) \cdot \frac{att_p^s}{\sum_{p' \in \mathcal{P}_{TR}} att_{p'}^s}, \quad \text{if } p \in \mathcal{P}_{TR} \]这一策略确保了最容易遗忘的任务被优先复习——相当于 AI 的“记住最难的部分”。
步骤 3: 选择最佳学习材料——高质量数据选择 (QFDS)
AQA 决定数量,而 QFDS 保障质量。CORE 不再随机存储样本,而是利用模型的潜在特征空间,从各类别中挑选出具代表性且多样化的样本。
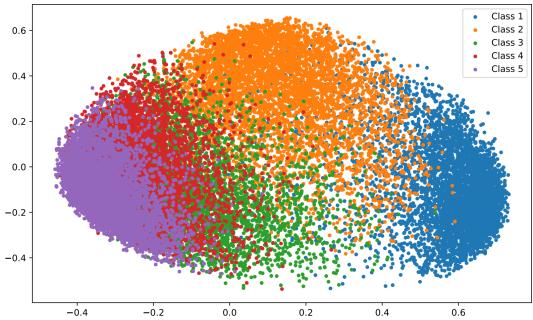
图 4: 特征空间表示——不同类别形成反映结构模式的簇。
CORE 计算每个类别的平均特征向量,并迭代选择能让子集均值最接近完整类别均值的样本,避免冗余选择,确保特征空间的平衡覆盖。

图 5: (a) 随机选择导致样本聚类和偏差。(b) CORE 的 QFDS 方法挑选均匀分布于类别中心周围的样本。
这一方法呼应了人类学习中的深度加工原理——复习材料越多样、越具代表性,记忆就越扎实。
它真的有效吗?
研究团队在标准基准数据集上验证了 CORE: split-MNIST、split-CIFAR10 和 split-CIFAR100。他们采用以下指标评估模型表现:
- 平均准确率 (\(Acc_{avg}\))——所有任务的平均性能
- 最低准确率 (\(Acc_{min}\))——任务中最低表现,体现学习平衡性与公平性
| 数据集 | 指标 | iCaRL | ER | DGR | LwF | EWC | CORE (Ours) | 上限值 |
|---|---|---|---|---|---|---|---|---|
| split-MNIST | Acc_avg Acc_min | 88.00 78.97 | 92.39 87.47 | 85.46 63.85 | 10.00 0.00 | 10.00 0.00 | 94.52 89.94 | 97.81 95.64 |
| split-CIFAR10 | Acc_avg Acc_min | 32.62 5.80 | 29.74 10.00 | 13.00 0.00 | 10.00 0.00 | 10.00 0.00 | 37.95 16.30 | 65.03 44.30 |
| split-CIFAR100 | Acc_avg Acc_min | 24.02 15.50 | 25.41 18.70 | 6.31 0.00 | 10.35 0.10 | 6.14 0.00 | 27.24 20.40 | 37.95 32.60 |
CORE 在平均与最低准确率上均表现更优,显示其学习效果更稳健、知识保留更强。尤其最低准确率提升了 6.30%,这是记忆平衡性的有力体现。
长期表现
作者还跟踪了第一个任务在随后任务增加时的保留效果。
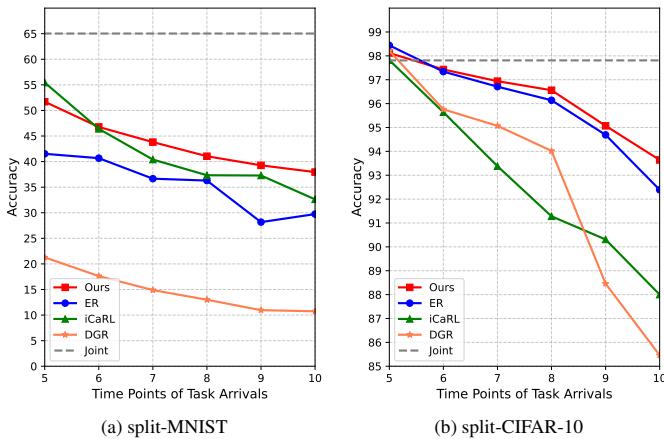
图 6: 连续任务中的准确率变化。CORE (红色) 保持显著更好的记忆保留水平。
相比其他方法迅速下降的曲线,CORE 的准确率缓慢下降,证明其回放策略在保护早期知识方面非常有效。
消融研究: CORE 的关键要素
为验证各组件的作用,作者在 split-CIFAR10 数据集上进行消融实验。
| 方法 | Acc_avg | Acc_min |
|---|---|---|
| CORE (完整) | 37.95 | 16.30 |
| CORE w/o AQA | 32.78 | 11.00 |
| CORE w/o QFDS | 31.52 | 12.40 |
| CORE w/o AQA+QFDS | 29.74 | 10.00 |
移除 AQA 会显著降低最差任务的表现,而省略 QFDS 则使整体平均准确率下降最明显。两者结合后效果最佳——AQA 保证平衡,QFDS 保证质量。
结论: 迈向真正的 AI 终身学习
灾难性遗忘长期阻碍着人工智能实现终身学习的愿景。CORE 框架通过汲取人类记忆机制的灵感,为这一难题提供了优雅解决方案。
依托自适应数量分配 (智能缓冲区管理) 与高质量数据选择 (代表性样本挑选) ,CORE 将传统回放过程转化为认知驱动的复习机制。它不只是机械复习数据——而是有策略地、有质量地记住关键内容。
融合神经科学启发与工程精度,CORE 让我们更接近能像人类一样持续学习与记忆的人工智能系统。