](https://deep-paper.org/en/paper/2402.01619/images/cover.png)
引言
大语言模型 (LLM) 彻底改变了我们与信息交互的方式。然而,它们都有一个众所周知的缺陷: 幻觉 (hallucination) 。当被问及具体的事实数据——例如某位研究人员的引用次数,或某个小镇的具体铁路网络——LLM 往往会给出令人信服但错误的猜测,而不是准确的回答。
为了解决这个问题,研究人员将 LLM 连接到外部知识库 (Knowledge Bases, KBs) 。 LLM 不再直接回答,而是充当翻译器的角色。它将自然语言问题 (例如: “小勒布朗·詹姆斯和他的父亲谁更高?”) 转换为逻辑程序 (例如: Find(LeBron James Jr.) -> Relate(Father) -> ...) 。这个过程被称为程序归纳 (Program Induction, PI) 。
但这其中存在一个陷阱。要教 LLM 为特定的知识库 (如 Wikidata 或私有公司数据库) 编写程序,通常需要成千上万个训练样本 (问题-程序对) 。对于“低资源”知识库——定制数据库或电影、学术等特定领域——这些数据根本不存在。
我们如何跨越这道鸿沟?如何教会 LLM 查询一个它从未见过的数据库,而无需昂贵的标注数据?
KB-Plugin 应运而生。在最近的一篇论文中,研究人员提出了一种模块化框架,将推理的“技能”与特定数据库模式的“知识”分离开来。通过使用轻量级、可插拔的模块,KB-Plugin 允许 LLM 瞬间掌握新的知识库。本文将拆解该框架的工作原理,解释为何它能胜过比自身大 25 倍的模型,并探讨这对结构化推理的未来意味着什么。
问题: 高昂的适配成本
想象一下,你是一名精通 Python 的软件工程师。如果你加入一家新公司,你不需要重新学习 Python;你只需要学习该公司特定的代码库和变量命名。
现有的程序归纳方法通常无法区分这一点。它们为每个新的知识库重新训练整个模型 (或其大部分) 。如果你想查询电影知识库,你就在电影问题上进行训练。如果你切换到学术知识库,一切都要从头开始。这对大多数实际应用来说是不切实际的,因为它需要为每个领域提供海量的标注数据集。
研究人员发现,主要的挑战不在于逻辑——LLM 已经理解了诸如“过滤 (filter) ”或“关联 (relate) ”等概念——而在于模式对齐 (schema alignment) 。 模型很难将问题中的“效力于 (plays for) ”一词映射到数据库中特定的关系 ID basketball_team.roster.player。
解决方案: KB-Plugin
KB-Plugin 的核心理念是模块化。该框架假设 LLM 的参数可以编码特定任务的知识。因此,我们应该能够使用可插拔模块 (具体来说是低秩适应,即 LoRA) 来注入特定知识。
KB-Plugin 将问题拆分为两个独立的插件:
- 模式插件 (KB 专用) : 该模块充当特定知识库的“字典”。它编码了详细的模式信息 (关系、概念和结构) 。
- PI 插件 (可迁移) : 该模块充当“推理器”。它通过在模式插件中查找信息,学习将问题转换为程序的一般技能。
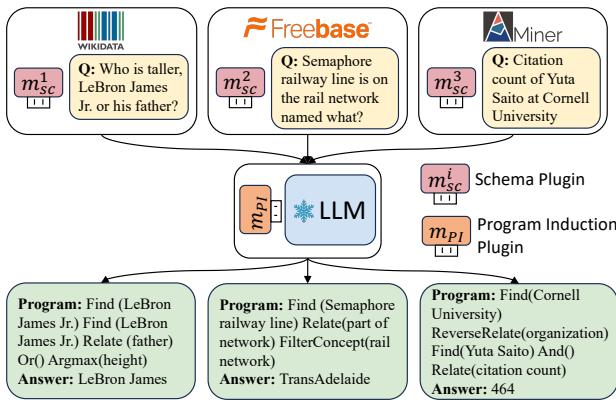
如上图 1 所示,该架构非常优雅。你有一个中心 LLM (冻结状态) 。当一个针对 Wikidata 的问题出现时,你插入 Wikidata 模式插件。当一个针对自定义 Miner 知识库的问题出现时,你将其换成 Miner 模式插件。PI 插件保持不变,负责处理通用的逻辑。
在数学上,针对目标知识库 (\(T\)) 的最终模型如下所示:

这里,\(M\) 是基础 LLM,\(m_{sc}^T\) 是目标的模式插件,\(m_{PI}\) 是可迁移的推理插件。
核心方法: 它是如何工作的
KB-Plugin 的精妙之处在于这两个模块的训练方式。研究人员必须解决两个问题:
- 如何在没有问答 (Q&A) 数据的情况下训练模式插件?
- 如何训练 PI 插件使其具有“通用性”,而不去死记硬背特定的数据库?
该框架利用了一个四步流程,如下图所示:
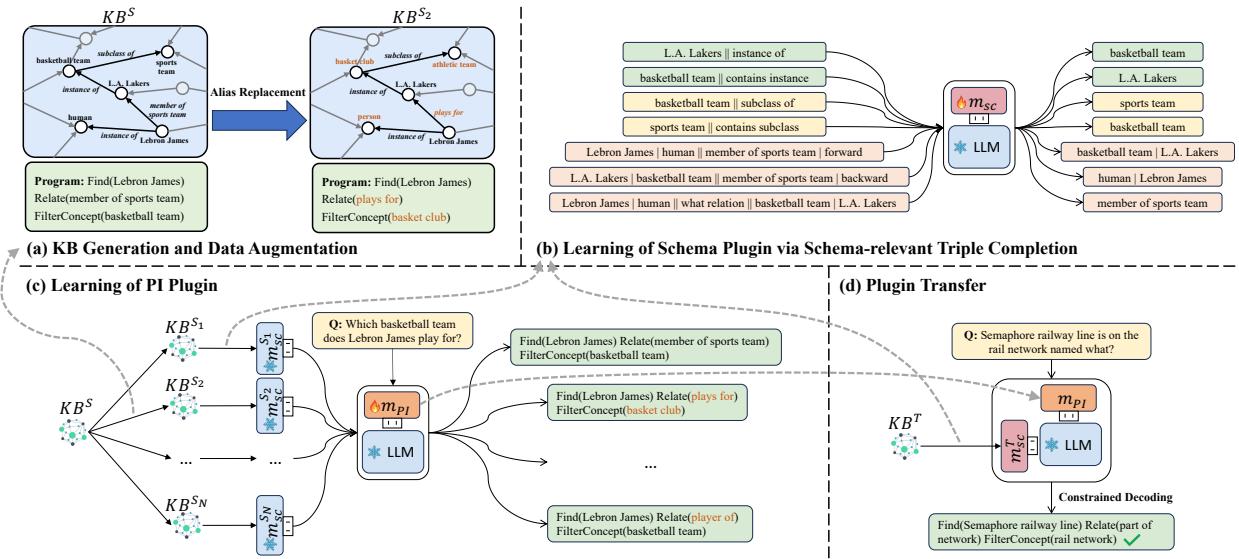
让我们拆解这些独特的阶段。
1. 架构: LoRA
在深入训练步骤之前,了解所使用的工具很重要。这些插件是使用 LoRA (低秩适应) 实现的。LoRA 不会更新庞大 LLM 中的所有权重,而是将小型的、可训练的秩分解矩阵注入到模型的不同层中。
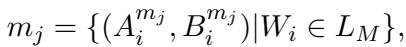
这使得“模式插件”非常小 (大约 40MB) ,却能有效地修改 LLM 的行为以理解特定的数据集。
2. 学习模式插件 (自监督)
研究人员需要一种方法,仅使用知识库本身的数据来教插件有关该知识库结构的知识。他们设计了一个自监督三元组补全任务 (Self-Supervised Triple Completion Task) 。
模型被赋予数据库中的一个事实,并被要求将其补全。这迫使插件记住概念和实体之间的关系。
例如,为了学习“概念 (Concept) ” (如城市或机场) ,模型在“实例属于 (instance of) ”三元组上进行训练:

在这里,模型看到一个实体必须预测其概念,或者看到一个概念并预测一个实体。
为了学习“关系 (Relations) ” (如 flight_to 或 born_in) ,系统构建了涉及前向和后向推理的更复杂的查询:

目标函数最大化预测正确模式项的可能性:
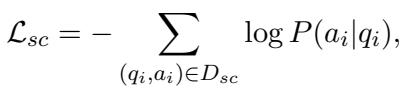
通过在成千上万个这类自动生成的示例上进行训练, 模式插件有效地将整个数据库结构“下载”到了它的参数中。它学会了“罗马”通过“首都”关系连接到“意大利”,而无需见过任何人类编写的问题。
3. 学习 PI 插件 (通用推理器)
现在我们需要一个懂得如何阅读这张地图的司机。我们有一个丰富的源数据集 (例如 Wikidata) ,其中包含许多问题和程序。然而,如果我们只在 Wikidata 上训练 PI 插件,它会死记硬背 Wikidata 特定的关系名称,并在迁移到新数据库时失败。
为了防止死记硬背,研究人员使用了基于别名替换的数据增强 (Data Augmentation via Alias Replacement) 。
他们采用了源知识库并生成了多个“伪”知识库 (\(S_1, S_2, \dots S_N\)) 。在每个变体中,他们使用别名随机重命名关系和概念 (例如,将“basketball team”更改为“basket club”或“hoops squad”) 。
然后,PI 插件被训练来回答这些不同模式变体下的相同问题。
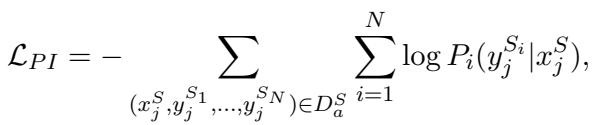
因为模式名称不断变化,PI 插件无法死记硬背。相反,它被迫学习更高层次的技能: “看问题,看当前的模式插件,然后提取匹配的关系。” 这是可迁移性的关键。
4. 零样本迁移
最后,为了处理一个新的、低资源的目标知识库 (\(T\)) :
- 为 \(T\) 训练一个模式插件 (使用步骤 2 中的自监督方法) 。
- 将其与预训练的 PI 插件一起插入 LLM。
- 模型现在可以回答关于知识库 \(T\) 的问题,即使 PI 插件以前从未见过它。
实验与结果
研究人员使用 Llama2-7B 作为骨干模型测试了 KB-Plugin。他们使用 KQA Pro (Wikidata) 作为丰富的源数据集,并在五个不同的低资源数据集上进行了测试,包括 WebQSP 和 GraphQ (Freebase) 、MetaQA (电影) 和 SoAyBench (学术) 。
主要性能
结果令人印象深刻。KB-Plugin 与 Pangu 和 KB-BINDER 进行了比较,这些是最先进的方法,使用的是像 Codex (175B 参数) 这样的巨大模型。
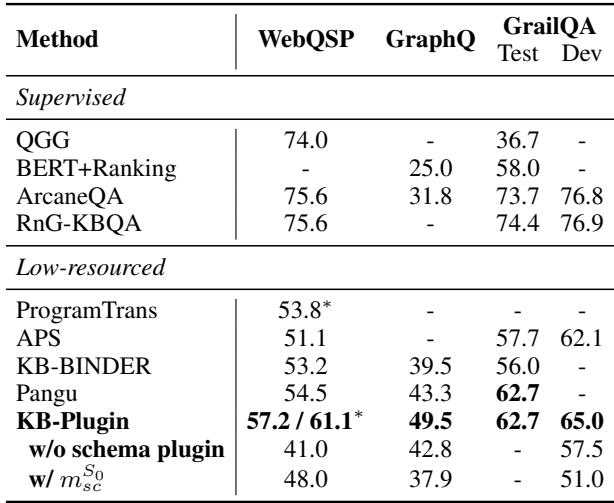
如表 2 所示,KB-Plugin (仅使用 7B 模型) 取得了与 Pangu (175B) 更好或相当的性能 。 在 GraphQ 数据集上,它将 F1 分数提高了超过 6%,在 WebQSP 上提高了近 3%。这是一个巨大的效率提升——用小 25 倍的模型实现了 SOTA 结果。
特定领域的迁移
该框架不仅在通用知识 (Freebase) 上证明了其有效性,在特定领域也同样有效。
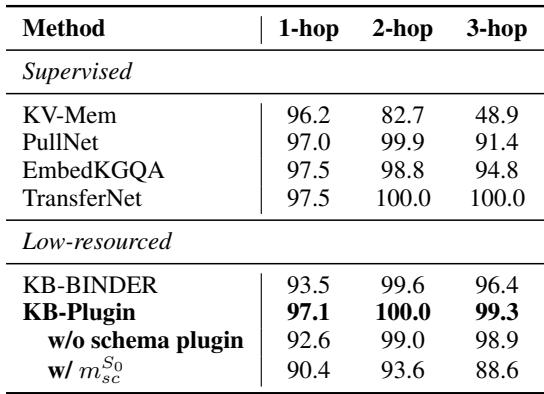

在学术领域 (SoAyBench,表 4) ,KB-Plugin 达到了 90.8% 的准确率 , 优于基于 GPT-4 的方法。这突显了模式插件的威力: GPT-4 拥有通用知识,但 KB-Plugin 拥有特定学术数据库结构的精确注入知识。
为什么模式插件很重要
你可能会问: “我们真的需要模式插件吗?PI 插件不能自己搞定吗?”研究人员进行了一项消融实验来找出答案。
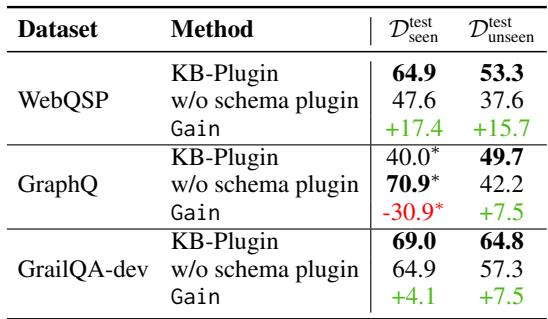
表 5 显示,当移除模式插件时,性能急剧下降,特别是对于“未见 (unseen) ”测试用例 (涉及训练数据中未出现的关系的问题) 。在 GraphQ 上,未见数据的性能下降了 7.5 分,在 WebQSP 上下降了近 16 分。模式插件本质上是一座桥梁,使模型能够“理解”它未被明确教导使用的关系。
合成知识库的效果
最后,研究人员验证了他们的数据增强策略。创建那些“伪”源知识库真的有帮助吗?
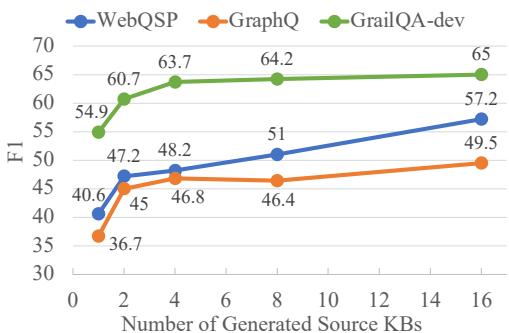
图 3 证实,仅使用一个源知识库进行训练会导致迁移效果差 (模型会死记硬背) 。随着生成的源知识库数量增加 (从 1 到 16) ,F1 分数稳步攀升。这证明在训练期间让 PI 插件接触变化的模式对于学习真正的可迁移性至关重要。
结论与启示
KB-Plugin 代表了我们处理知识库问答 (KBQA) 方式的重大转变。该框架不再将 LLM 视为静态的事实存储库,也不需要为每个新任务进行大规模微调,而是将它们视为模块化引擎。
主要收获:
- 解耦行之有效: 将“模式知识”与“推理技能”分离开来,可以实现灵活、即插即用的 AI。
- 规模不是一切: 拥有正确模块化架构的 7B 参数模型可以胜过 175B 参数的通才模型。
- 数据稀缺是可以解决的: 通过对模式使用自监督学习,并对推理使用合成数据增强,我们可以有效地解决低资源领域的问题。
对于学生和开发人员来说,这意味着在未来,将 LLM 适配到私有公司数据库或小众科学档案库,不需要数千小时的数据标注。你只需插入模式插件,剩下的交给模型即可。