](https://deep-paper.org/en/paper/2402.02420/images/cover.png)
我们都有过这样的经历。你向 ChatGPT 或 Claude 询问关于某个历史事件或冷门科学概念的具体问题。答案行云流水般涌现,格式完美,听起来极其权威。但当你再次核对某个日期或名字时,你意识到: 模型是在瞎编。
大型语言模型 (LLM) 彻底改变了我们搜索、提取和整合信息的方式。它们让我们无需打开二十个标签页就能找到一个简单的答案。然而,它们的效用受到一个主要缺陷的严重限制: 真实性 (Factuality) 。
在研究论文 “Factuality of Large Language Models: A Survey” 中,来自 MBZUAI、莫纳什大学、Google 等机构的研究人员全面综述了 LLM 为何无法说真话、我们如何衡量这些失败,以及目前正在使用的最前沿修复方法。
本文将这篇综述拆解为一个连贯的故事,旨在帮助学生了解 LLM 真实性的现状。
核心问题: 流畅性 vs. 真实性
理解 LLM 错误的第一个障碍是术语。在 AI 社区中,你经常会听到两个词: 幻觉 (Hallucination) 和 真实性 (Factuality) 。 虽然它们有重叠,但作者认为区分它们对于解决问题至关重要。
幻觉 vs. 真实性
在传统的自然语言处理 (NLP) 中,“幻觉”意味着生成的文本与源文本不匹配 (例如,摘要中包含了原文中不存在的细节) 。
在 LLM 时代,这个定义变得模糊了。作者提出了一个更清晰的区分:
- 幻觉 (Hallucination) : 当 LLM 生成的内容荒谬或不忠实于提供的源头时,就会发生这种情况。模型可能会因为跑题或添加未被要求的“废话” (fluff) 而产生幻觉,即使这些废话在技术上是真实的。
- 真实性错误 (Factuality Error) : 这是生成内容与可验证的现实世界事实之间的差异。这表现为事实不一致 (与已知现实相矛盾) 或捏造 (发明不存在的事物) 。
关键点: 一个模型可以是事实正确的,但仍然产生幻觉 (通过不忠实于提示词) 。反之,一个模型可以忠实于提示词 (如果提示词包含谎言) ,但在事实上是错误的。
为了理解这篇特定综述在更广泛的学术对话中的位置,作者提供了现有文献的对比。
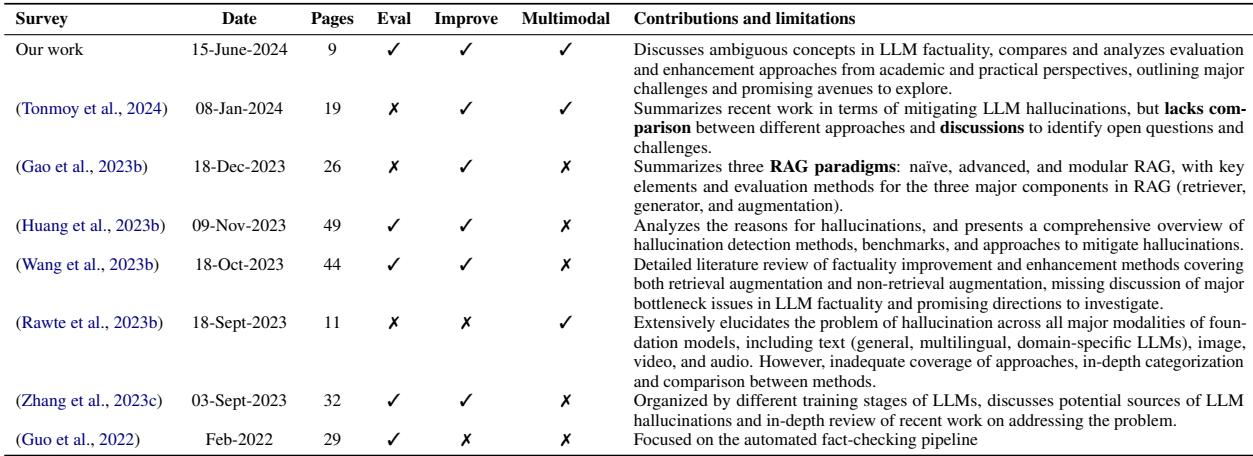
如表 1 所示,其他综述主要集中在特定的缓解技术上,如检索增强生成 (RAG) ,而本文旨在涵盖整个生命周期: 从评估到各个训练阶段的改进,包括常被忽视的多模态 (图像/文本) 真实性领域。
评估真实性: 我们如何给真相打分?
如果你想提高模型的真实性,首先需要一种衡量它的方法。这比听起来要难。如果 LLM 写了一篇关于科学家的传记,没有一个单一的“黄金标准”句子可以用来对比。这篇传记可以有一千种不同的写法,并且都是准确的。
研究人员将评估数据集分为四种不同的类型,从易于自动化到极难自动化。
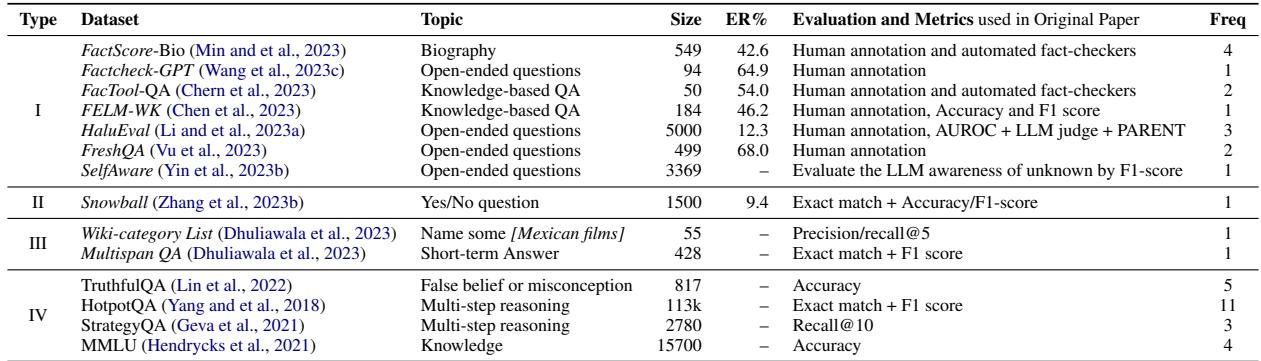
第一类: 开放式生成 (最难)
这代表了现实世界的用例: “告诉我居里夫人的早年生活。”
- 挑战: 输出是长篇、自由形式的文本。没有 A/B/C/D 标签。
- 评估: 这通常需要人类专家或复杂的“自动事实核查器” (稍后详述) 。
- 示例数据集: FactScore-Bio, Factcheck-GPT。
第二类: 是/否问题
- 挑战: 较简单,但容易靠猜。
- 评估: 二元分类指标 (准确率,F1 分数) 。
- 示例数据集: Snowball。
第三类: 短语回答
- 挑战: 模型必须生成特定的实体 (例如名字或日期) 或列表。
- 评估: 精确匹配或 Recall@K (正确答案是否出现在前 K 个建议中?) 。
- 示例数据集: Wiki-category List。
第四类: 多项选择 (最简单)
- 挑战: 标准化测试。
- 评估: 高度自动化。我们可以轻松计算准确率。
- 示例数据集: MMLU, TruthfulQA。
虽然第四类很容易运行,但第一类才是行业发展的方向。我们不只是希望 LLM 通过多项选择测试;我们希望它们撰写可靠的报告。这推动了对更好的 自动事实核查器 (Automatic Fact-Checkers) 的需求。
自动事实核查器的解剖
因为人类无法阅读数百万条 LLM 的输出来检查准确性,我们正在构建 AI 系统来检查其他 AI 系统。作者描述了这些自动化流程的标准框架。
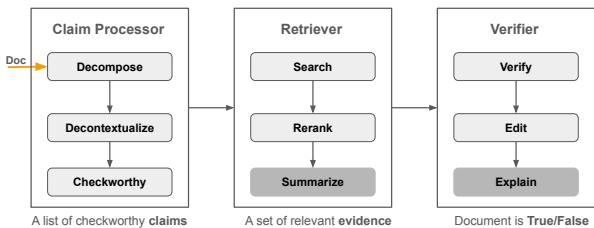
如图 1 所示,该流程包含三个关键阶段:
主张处理器 (分解与检测) : 系统获取 LLM 生成的长文档,并将其分解为“原子主张” (atomic claims) 。例如,句子“奥巴马于 1961 年出生在夏威夷”可能会被拆分为两个主张: “奥巴马出生在夏威夷”和“奥巴马出生于 1961 年”。然后,它会过滤出“值得核查”的主张 (忽略观点或问候语) 。
检索器 (搜索) : 系统查询知识库 (如维基百科或开放网络) 以查找与这些原子主张相关的证据。它会对搜索结果进行重排序,以找到最相关的信息。
验证器 (裁判) : 使用检索到的证据,系统 (通常是另一个 LLM) 确定该主张是
True(真) 、False(假) 还是Not Enough Info(信息不足) 。一些先进的系统,如 Factcheck-GPT,甚至提供“编辑”步骤来修正错误。
瓶颈: 这里的主要限制是“先有鸡还是先有蛋”的问题。如果我们使用 GPT-4 来验证 ChatGPT 的真实性,我们就依赖于 GPT-4 的真实性。如果验证器产生幻觉,评估就是有缺陷的。
提高真实性的方法
一旦我们要知道模型在撒谎,我们该如何修复它?综述根据 LLM 的生命周期分解了解决方案: 预训练 (Pre-training) 、微调 (Tuning) 和 推理 (Inference) 。
1. 预训练: “垃圾进,垃圾出”
提高真实性最根本的方法是确保模型在初始训练期间阅读高质量的文本。
- 数据过滤: 研究人员正从盲目抓取网络数据转向更精细的方法。现在的技术包括过滤数据集,优先考虑可靠来源 (如教科书或维基百科) ,而不是随机论坛。
- 检索增强预训练: 像 RETRO 这样的模型是从头开始带着内置搜索引擎进行训练的。它们不只是记忆文本;它们在学习过程中学会从数据库中查找 token。
2. 微调: 教导模型举止得体
预训练后,模型会经过监督微调 (SFT) 和强化学习 (RLHF) 。
- 知识注入: 你可以在特定的知识图谱或实体摘要上微调模型,以更新其内部数据库。
- 拒绝意识 (Refusal-Awareness) : 幻觉的最大原因之一是模型在不知道答案时试图提供帮助。R-tuning 教导模型说“我不知道”,而不是编造听起来合理的谎言。
- 阿谀奉承问题 (The Sycophancy Problem) : 模型通常被调整为取悦人类。如果用户问了一个前提错误的问题 (例如,“为什么地球是平的?”) ,急切的模型可能会产生幻觉来满足用户。新的微调方法使用合成数据来教导模型,真实性比用户的认可更重要。
3. 推理: 更好的解码策略
即使是训练有素的模型,如果在生成文本时使用了错误的设置,也会产生幻觉。
- 解码策略: 标准的“核采样 (nucleus sampling) ” (基于概率选择下一个词) 引入了随机性以使文本具有创造性。然而,随机性会扼杀真实性。像 Factual-Nucleus Sampling 这样的新方法会随着句子变长动态减少随机性。
- DoLa (通过层对比进行解码) : 这是一项迷人的技术,模型将其成熟 (后期) 层的输出与其不成熟 (早期) 层的输出进行对比。理论是事实知识存在于特定的层中,通过放大这些信号,我们可以剔除噪音。
- 上下文学习 (ICL) : 简单地在提示词中提供“演示示例”会有所帮助。如果你向模型展示如何验证事实或如何承认无知的例子,它通过模仿会表现得更好。
检索增强生成 (RAG) 的角色
也许目前行业中最流行的方法是 RAG。综述将其视为适用于所有阶段的跨领域解决方案。
在 RAG 系统中,LLM 连接到一个外部数据库。当你提问时,它会检索相关文档并使用它们来生成答案。
- 生成前 RAG: 模型在开始写作之前获取文档。这限制了输出空间,使其紧贴文档中发现的事实。
- 雪球效应 (Snowballing) : 论文指出的一个主要风险是“幻觉雪球效应”。如果 LLM 在句子早期犯了一个小错误,它通常会在随后的句子中加倍强调该错误以保持一致性。RAG 可以有所帮助,但如果检索到的文档有偏差或模型误解了它,雪球效应仍然可能发生。
多模态真实性: 眼见未必为实
综述不仅限于文本,还讨论了多模态 LLM (MLLM) ——即能看又能说的模型 (如 GPT-4V) 。这里的真实性错误有所不同:
- 存在真实性: 声称图像中有某个物体,实际上没有。
- 属性真实性: 弄错了颜色、形状或大小。
- 关系真实性: 误解了物体之间的相互作用 (例如,说杯子在桌子上,而实际上它是悬停在桌子上方) 。
改善这一点涉及使用负面示例进行“指令微调”——专门训练模型针对图像不该说什么。
结论与未来方向
论文总结道,虽然我们已经取得了巨大的进步,但仍存在三大挑战:
- LLM 是概率性的,而非逻辑性的。 它们被训练来预测下一个词,而不是验证真理。改变这一基本目标是困难的。
- 评估很混乱。 我们缺乏一个每个人都同意的统一、自动化的框架。我们仍然过分依赖昂贵的人工评估或不完美的基于 AI 的裁判。
- 延迟。 实时事实核查和检索需要时间。与机器人聊天的用户期望即时回复,但严格的事实核查循环可能需要几秒钟甚至几分钟。
LLM 真实性的未来可能在于 校准 (calibration) ——让模型意识到自己的局限性,从而自信地陈述它们所知道的,并谦虚地承认它们不知道的。在此之前,像 RAG 和自动事实核查管道这样的技术仍然是我们防御数字助手自信幻觉的最佳手段。