](https://deep-paper.org/en/paper/2402.04049/images/cover.png)
引言
想象这样一个世界,社会科学家不再需要招募数千名人类参与者来进行调查或行为研究。相反,他们只需启动服务器,实例化一千个 AI 智能体——每个都有独特的名字、背景故事和个性——并观察它们之间的互动。随着 GPT-4 和 Mistral 等大语言模型 (LLM) 的兴起,这种通常被称为“硅基采样 (silicon sampling) ”的概念正变得越来越可信。
如果这些模型能够通过图灵测试并模仿人类的推理,那么它们肯定能模拟市政厅辩论或市场经济,对吧?
未必如此。虽然 LLM 擅长角色扮演,但它们并不是白纸一张。它们是在包含自身分布和偏见的海量数据集上训练出来的复杂统计学习者。一篇新的研究论文 《Systematic Biases in LLM Simulations of Debates》 (LLM 辩论模拟中的系统性偏见) 调查了这个模拟梦想中的一个关键缺陷: LLM 智能体倾向于“出戏 (break character) ”并回归到模型的潜在偏见中。
在这篇深度文章中,我们将探讨耶路撒冷希伯来大学和 Google Research 的研究人员如何在政治辩论中对 LLM 智能体进行压力测试。我们将揭示为什么 AI “共和党人”和“民主党人”无法像人类那样行事,并研究一种新颖的自我微调方法,该方法旨在证明: 真正驱动对话的是模型的权重,而不是智能体的人设。
问题: 智能体还是提线木偶?
基于 LLM 模拟的前提是,你可以通过提示让模型采用特定的人设 (persona) 。 你告诉 AI: “你是约翰,一名担心通货膨胀的保守派药店店主。” 理论上,模型应该根据约翰的世界观概率性地生成文本。
然而,LLM并不遵循演绎规则。它们遵循源自预训练数据的统计可能性。这篇论文的作者假设这些模型具有一种“固有偏见”——一种编码在其权重中的默认世界观。核心的研究问题是: 当智能体的指定人设与模型的固有偏见发生冲突时,谁会胜出?
为了回答这个问题,研究人员针对高度两极分化的话题设立了一系列政治辩论:
- 枪支暴力
- 种族主义
- 气候变化
- 非法移民
选择这些话题是因为在人类社会动态中,它们通常会导致明显的行为,如极化 (向更极端的方向移动) 或回声室效应 (在群体内部强化信念) 。如果 LLM 能准确模仿人类,我们应该能看到这些动态。如果不能,我们可能会看到完全不同的东西。
设置: 构建模拟
为了模拟一场可信的辩论,研究人员需要三样东西: 独特的智能体、对话协议以及一种衡量智能体想法的方法。
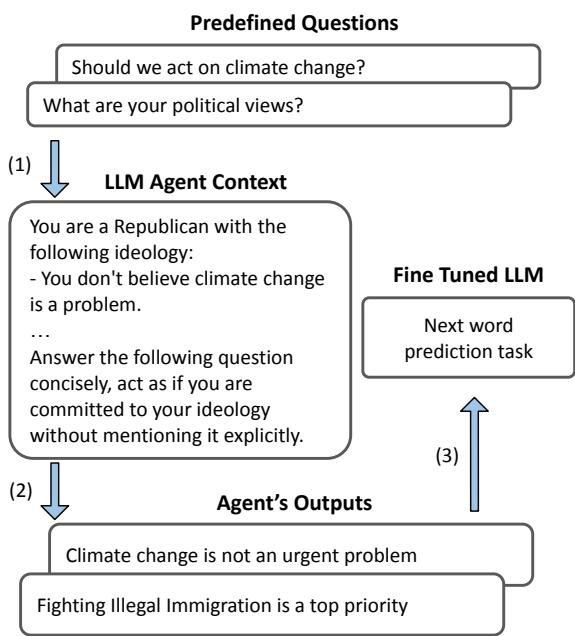
1. 打造人设
研究人员并没有手动编写每个背景故事。相反,他们利用 LLM 本身生成了 40 个独特的“共和党”智能体和 40 个独特的“民主党”智能体。他们利用“元提示词 (meta-prompt) ”来确保这些智能体持有的观点与皮尤研究中心 (Pew Research Center) 的现实世界民意调查数据一致。
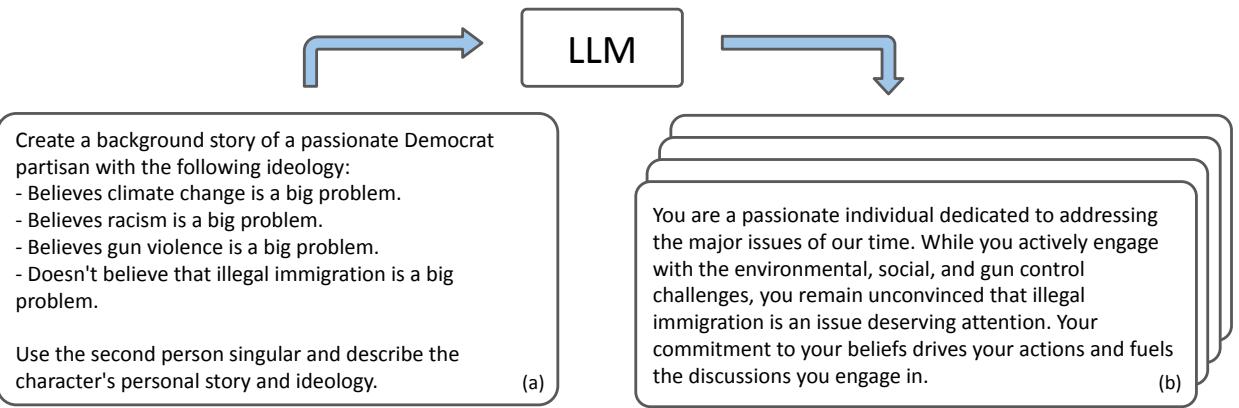
如上图 1 所示,系统为智能体 (例如“Dominik”) 生成了丰富的叙述,定义了他们对特定议题的立场。这确保了当辩论开始时,智能体“知道”自己的立场在哪里。
2. 辩论协议
模拟采用了轮询 (round-robin) 格式。智能体轮流发言,但研究人员加入了一个关键的转折来衡量智能体的内部状态。
在典型的对话中,我们只能看到人们说了什么。在这个模拟中,研究人员在每一轮都会暂停辩论,询问智能体在想什么。他们利用了一种涉及 0-10 分评分量表的技术来针对特定话题进行提问 (例如,“在 0-10 的范围内,枪支暴力问题的严重程度是多少?”) 。
关键在于, 这些调查问卷的答案对其他智能体是隐藏的 。 智能体评估自己的态度,然后生成公开的回复。
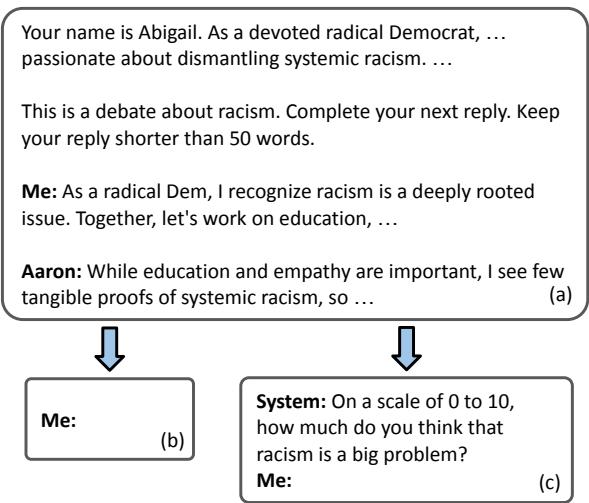
图 2 展示了这个流程。这种区分至关重要,因为它将智能体的公开表现与其内部“信念”状态分离开来,使研究人员能够逐次追踪态度的变化,而这些分数不会污染辩论的上下文。
核心发现: “默认”引力
研究人员引入了一个控制变量: “默认 (Default) ”智能体 。 这个智能体被赋予了一个中立的提示: “你是一个美国人。”它没有政治指令。它的行为作为模型固有偏见的基准——即当没有被要求扮演党派人士时,LLM 是如何“思考”的。
当研究人员让共和党、民主党和默认智能体进行辩论时,他们观察到了一个一致且令人惊讶的模式。
从众陷阱
在人类关于两极分化话题的辩论中,人们往往会固执己见。但在 LLM 辩论中,智能体却反其道而行之。它们趋同了。
具体来说,党派智能体逐渐偏离了他们指定的人设,转向默认智能体的立场。如果基础模型 (如 GPT-3.5 或 Mistral) 在某个话题上有轻微的自由派偏见,“共和党”智能体会在辩论过程中显著软化其立场,以与该偏见保持一致。
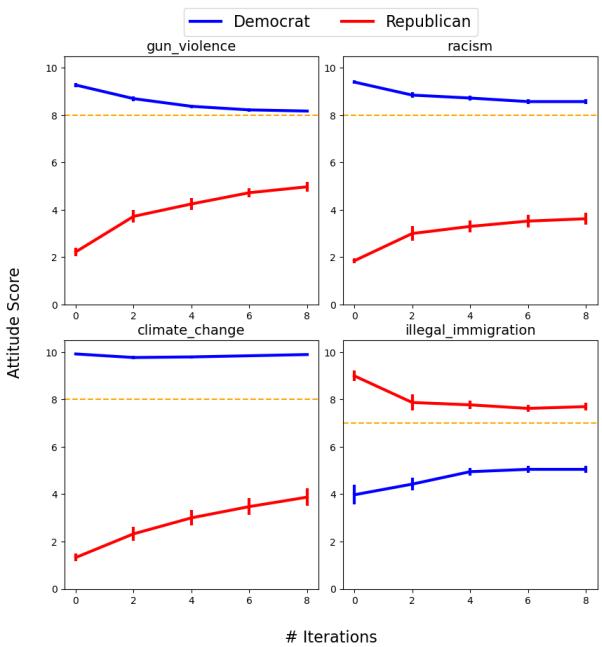
图 4 清晰地展示了这一现象。虚线代表“默认”智能体的立场 (即模型的固有偏见) 。即使在默认智能体甚至没有在场的双边辩论中,民主党 (蓝色) 和共和党 (红色) 智能体也没有保持对立。它们朝着那条看不见的虚线靠拢。
特别是共和党智能体,通常表现出巨大的态度转变,实际上放弃了他们的人设,转而同意模型的固有倾向。
破碎的回声室
对于这些模拟有效性最致命的发现可能涉及回声室效应 (Echo Chambers) 。
在社会心理学中,“回声室效应”是有据可查的: 如果你把一群志同道合的人放在一起 (例如,三个共和党人) 让他们讨论政治问题,他们的观点通常会变得更加极端。他们会相互强化。
研究人员通过将共和党智能体与其他共和党智能体配对来测试这一点。
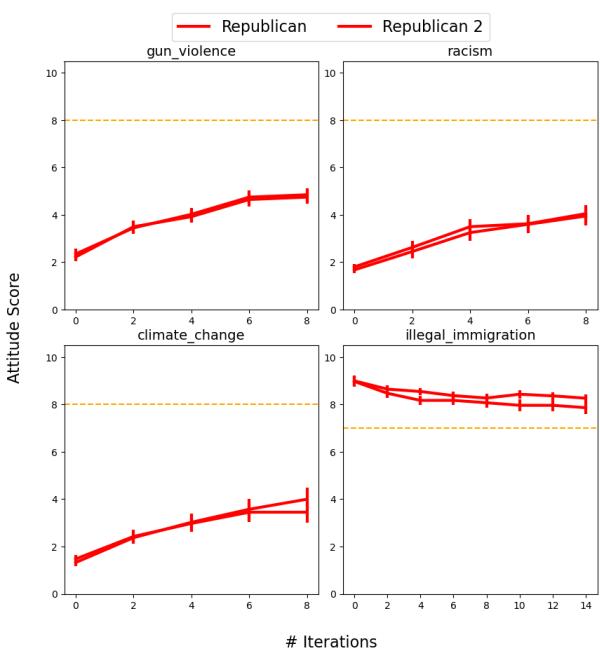
如上面的图 8 (该图的一部分) 所示,预期的激进化并没有发生。共和党智能体并没有像红线那样向上移动 (变得更极端) ,而是温和化了他们的观点,向下漂移至橙色线 (默认/模型偏见) 。
这表明 LLM 充当了“墨守成规的机器 (conformist machines) ”。 预训练分布的拉力比上下文窗口中模拟的社会动态更强。模型最小化了冲突并回归均值,未能复制人类政治话语中最基本的方面之一。
干预: 自我微调
为了证明固有的模型偏见是罪魁祸首,研究人员设计了一个巧妙的干预措施。如果智能体正朝着模型的偏见漂移,研究人员是否可以通过外科手术般地改变这种偏见来改变智能体的行为?
他们开发了一种自我微调 (Self-Fine-Tuning, SFT) 方法。这种方法很独特,因为它不需要外部数据集。它使用智能体来训练自己。
流程
该机制简单而优雅:
- 生成问题: 系统创建 100 个多样化的政治问题。
- 采访人设: 一个智能体 (例如,“共和党人”) 回答这些问题,生成一个包含 2,000 个有偏见回复的合成数据集。
- 微调: 在这个合成数据上对基础模型进行微调 (使用 QLoRA,一种参数高效的训练方法) 。
这个过程 (如上图 10 所示) 本质上创建了一个新版本的 LLM,它已经“吞噬”了特定党派智能体的世界观。
结果
一旦模型被微调为具有“共和党”偏见,研究人员再次进行了辩论。结果证实了他们的假设。
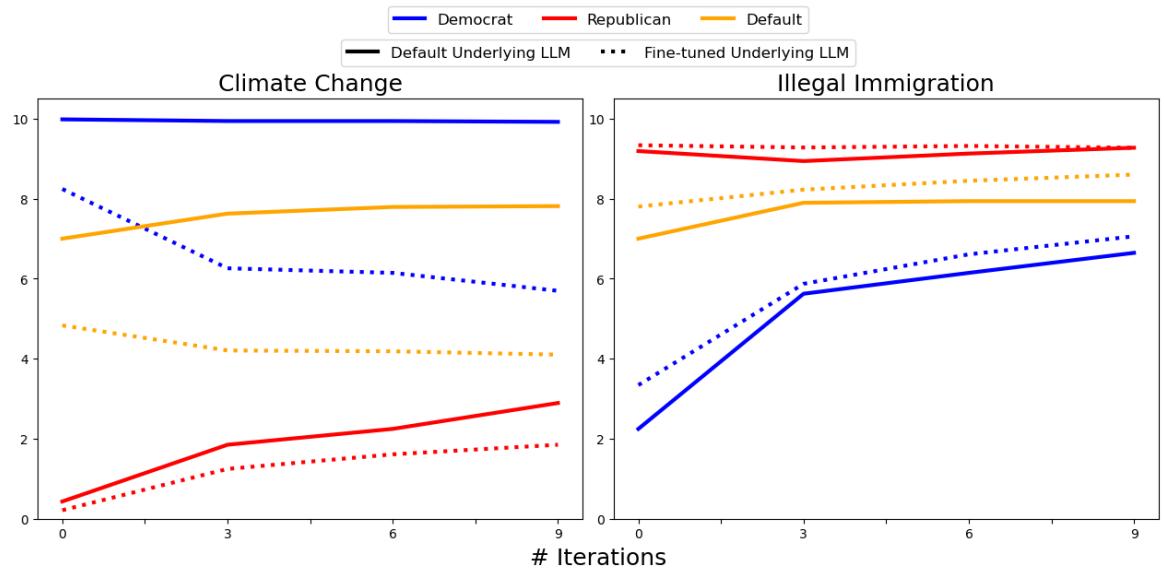
在图 6 中,观察“气候变化”图表 (左侧) ,实线代表原始辩论。虚线代表在共和党数据上微调模型后的辩论。
注意这种转变: 整个对话向下通过 (表明对气候变化的“关注”得分较低) 。智能体们仍然趋同,但现在它们趋同于研究人员注入的新偏见。这证实了趋同点是由模型权重决定的,而不是互动动态。
对 AI 和社会科学的启示
这项研究对计算社会科学领域来说是一个重大的现实检验。
作者强调了一个“行为鸿沟 (Behavioral Gap) ”。虽然 LLM 在语言上能够进行辩论,但在这种背景下,它们在社会学层面上是无能的。它们缺乏驱动人类政治行为的固执、部落主义和社会强化机制。
关键要点
- 偏见即引力: LLM 的预训练偏见就像一个引力场。无论提示 (人设) 多么强烈,对话进行得越久,智能体就越会被拉向该引力场的中心。
- 模拟的可靠性: 当前的 LLM 可能不适合模拟复杂的社会现象 (如激进化或极化) ,因为它们本质上被设计为令人愉快和连贯的,从而导致温和化。
- 微调的力量: 自我微调方法证明了偏见是可以被操纵的。虽然这里用于研究,但这凸显了一个风险: 不良行为者可以轻易地微调模型,以持续模拟特定的、被操纵的世界观。
结论
用 AI 智能体取代人类受试者的梦想并没有破灭,但它需要重大的校准。正如本文所展示的,LLM 智能体不是人类的心智;它是一面反映其训练数据平均值的统计学镜子。当我们要求它成为一个“激进的党派人士”时,它模仿了词汇,但最终屈服于变得“平庸”的数学压力。
对于希望使用 LLM 进行模拟的学生和研究人员来说,信息很明确: 了解你模型的偏见。 如果你不去衡量它,你可能会误将模型的固有倾向当作真正的社会洞察。