](https://deep-paper.org/en/paper/2402.08680/images/cover.png)
引言
像 LLaVA、mPLUG-Owl 和 GPT-4V 这样的大型视觉语言模型 (LVLM) 的迅速崛起,彻底改变了机器理解世界的方式。通过将视觉编码器与强大的大型语言模型 (LLM) 对齐,这些系统可以看图说话、回答关于图像的复杂问题,甚至通过视觉进行推理。然而,尽管它们的能力令人印象深刻,这些模型却存在一个关键且令人尴尬的缺陷: 物体幻觉 (Object Hallucination) 。
当 LVLM 自信地描述图像中根本不存在的物体时,就会发生物体幻觉。对于普通用户来说,这可能只是产生一个好笑的标题。但在安全至关重要的领域——如医学影像分析或自动导航——模型“看到”不存在的肿瘤或不存在的停车标志,会带来严重的风险。
以往解决这一问题的尝试往往依赖于昂贵的方案。一些研究人员通过整理海量的高质量数据集来微调模型,这对计算资源和成本的要求都很高。另一些人则使用“生成后修正”,要求像 GPT-4 这样的专有模型来复查 LVLM 的工作,这增加了显著的延迟和 API 成本。
在论文 Mitigating Object Hallucination in Large Vision-Language Models via Image-Grounded Guidance 中,研究人员引入了一种名为 MARINE 的新颖框架。MARINE 代表“Mitigating hallucinAtion via image-gRounded guIdaNcE” (通过基于图像的引导来缓解幻觉) 。MARINE 最显著的特点是它既 无需训练 (training-free) 也 无需 API (API-free) 。 它通过利用开源视觉模型来引导 LLM,从而在推理阶段减少幻觉,确保生成的文本基于视觉现实。
背景: LVLM 为什么会产生幻觉?
要理解 MARINE 的工作原理,我们首先需要诊断“病人”。为什么能力如此强的模型会凭空捏造物体?作者指出了标准 LVLM 架构中的三个主要根本原因 (缺陷) :
- 视觉上下文不足: LVLM 使用的视觉编码器 (通常基于 CLIP) 非常擅长捕捉图像的整体“氛围”或语义含义,但往往缺乏细粒度的物体级精度。
- 信息丢失: 当视觉特征被投影到文本嵌入空间 (将“像素”转化为“Token”) 时,关键细节可能会被扭曲或丢失。
- LLM 先验知识: 语言模型组件就像一个强大的自动补全工具。如果它看到一张餐桌的照片,它的统计先验可能会预测接下来会出现“叉子”和“刀”,即使图像中并没有这些具体的物体。
MARINE 专门针对前两个问题,通过在生成过程中注入高质量、明确的视觉信息来解决。
MARINE 框架
MARINE 的核心理念是: 如果 LVLM 的内部眼睛 (视觉编码器) 有点模糊,我们就应该给它配一副眼镜。这副“眼镜”就是现成的、开源的物体检测模型。
1. 视觉工具箱 (The Vision Toolbox)
MARINE 不仅仅依赖 LVLM 原生的视觉编码器,而是引入了一个“视觉工具箱”。这个工具箱包含专门用于物体落地 (Object Grounding) 的模型——例如 DETR (DEtection TRansformer) 或 RAM++ (Recognize Anything Model)。
与 LVLM 中的通用编码器不同,这些专用模型经过训练,只擅长做一件事: 检测并列出图像中存在的物体。
如下图所示的架构,系统接收输入图像并通过两条并行路径进行处理。标准路径通过 LVLM 的视觉编码器。辅助路径则通过视觉工具箱中的“引导模型 (Guidance Models) ”。
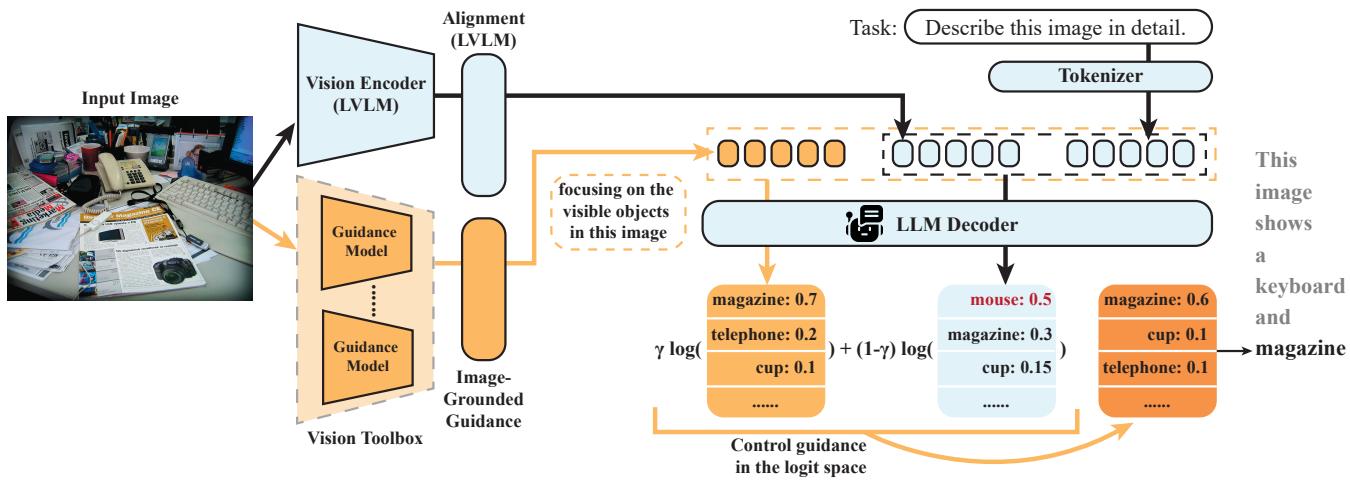
引导模型检测物体 (例如“键盘”、“鼠标”、“杯子”) 并将它们聚合成文本上下文。这个聚合信息充当了关于实际可见内容的可靠“基本事实 (Ground Truth) ”列表。
2. 用于文本生成的无分类器引导
MARINE 如何强制 LVLM 关注这个新的物体列表?它使用了一种受 无分类器引导 (Classifier-Free Guidance, CFG) 启发的技术,这是一种在图像生成模型 (如 Stable Diffusion) 中流行的方法,用于使图像更贴合文本提示。
MARINE 将其调整用于文本生成。它将检测到的物体列表视为一个 控制条件 (\(c\)) 。
在推理过程中,模型会为句子中的下一个词计算两组概率 (Logits) :
- 无条件 Logits: 基于图像特征 (\(v\)) 和文本提示 (\(x\)) 的标准预测。
- 有条件 Logits: 基于图像特征 (\(v\))、文本提示 (\(x\)) 以及 聚合的物体引导 (\(c\)) 的预测。
该方法实际上是用有条件预测减去无条件预测,以放大引导的影响。更新后的概率分布的数学公式为:
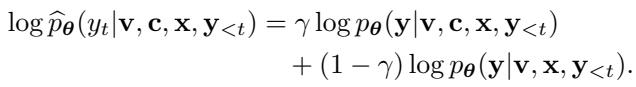
在这个公式中:
- \(\log \widehat{p}_{\theta}\) 是下一个潜在词的最终调整分数。
- \(\mathbf{c}\) 代表视觉引导 (检测到的物体列表) 。
- \(\gamma\) (gamma) 是 引导强度 。
如果 \(\gamma = 1\),模型完全依赖引导。如果 \(\gamma = 0\),它的行为就像标准模型。通过调整 \(\gamma\) (通常在 0.3 到 0.7 之间) ,作者找到了一个“最佳平衡点”,即模型利用外部物体检测来抑制幻觉,同时不丧失编写连贯、流畅句子的能力。
本质上,如果标准 LLM 想要预测“叉子”,因为它是关于餐桌句子的补全,但物体检测模型 没有 看到叉子 (意味着“叉子”的有条件概率很低) ,该公式将严厉惩罚“叉子”这个 Token,从而防止幻觉产生。
实验与结果
研究人员使用标准的幻觉基准测试,在五个流行的 LVLM (包括 LLaVA、MiniGPT-v2 和 InstructBLIP) 上测试了 MARINE。
减少幻觉 (CHAIR 指标)
使用的主要指标是 CHAIR (Caption Hallucination Assessment with Image Relevance,图像相关性标题幻觉评估) 。该指标计算标题中提到的物体有多少百分比在基本事实标注中实际不存在。分数越低越好。
下表详细列出了性能比较。MARINE 在几乎所有模型架构中都实现了最低的幻觉率 (最佳结果加粗显示) 。
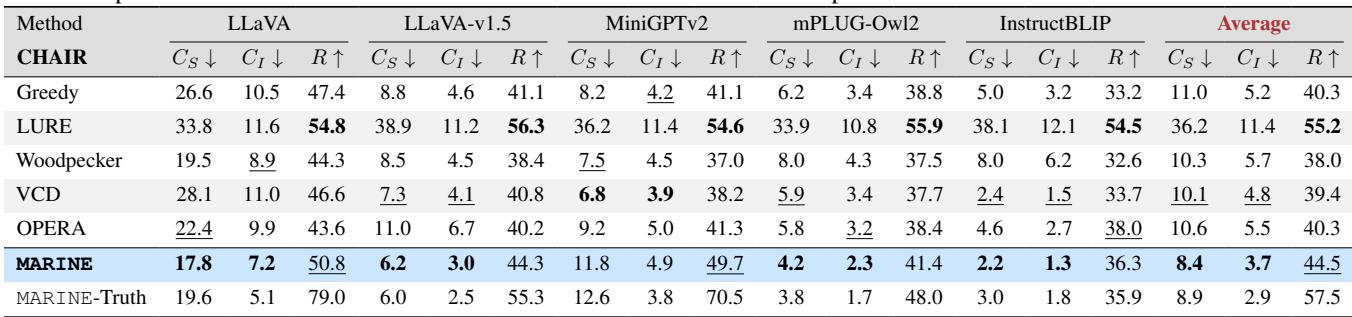
例如,看 LLaVA 模型,标准版本的 \(CHAIR_S\) (句子级幻觉) 得分为 26.6。配备 MARINE 后,这一分数降至 17.8 。 这是一个巨大的改进,显著优于 LURE 或 Woodpecker 等其他基线方法。
“是”的偏见 (POPE 指标)
测试幻觉的另一种常见方法是 POPE (Polling-based Object Probing Evaluation,基于轮询的物体探查评估) 基准。这涉及问模型“是/否”的二元问题,例如“图像中有一张餐桌吗?”
LVLM 存在严重的过度信任或“是偏见 (Yes bias) ”——如果物体在上下文中很可能出现,它们往往会回答“是”,即使该物体并不存在。
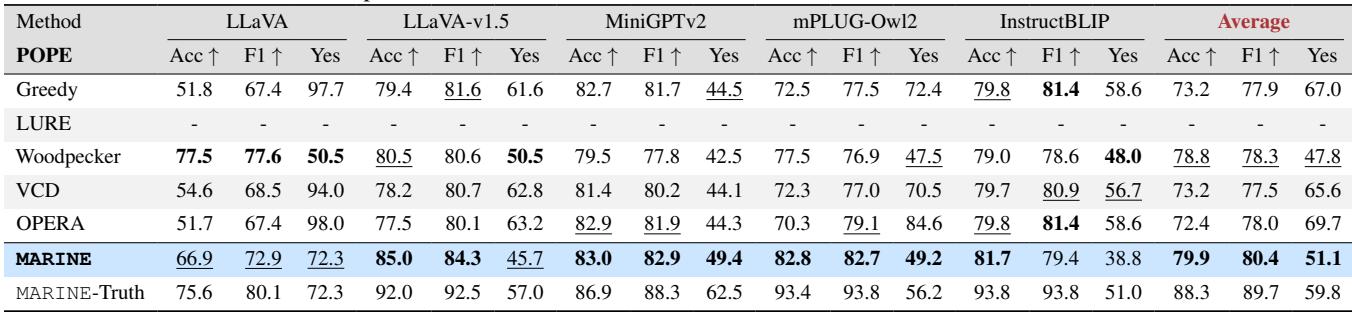
表 2 中的结果显示,MARINE 显著提高了准确性。更重要的是,请看 “Yes” ratio (“是”的比例) 。 一个完美的无偏见模型在回答对抗性问题 (其中 50% 的物体不存在) 时,“是”的比例应该接近 50%。标准 LLaVA 的“是”比例高达 97.7% , 这意味着它几乎总是声称物体存在。MARINE 将此比例降至 72.3% , 反映了更加基于事实且诚实的决策过程。
定性示例
数据固然重要,但眼见为实。下图展示了 MARINE 如何实时修正错误。

在顶部关于鸟的例子中,标准 LLaVA 模型产生了一个“白色椅子”的幻觉,仅仅因为这只鸟是白色的且正栖息在某物上。MARINE 正确地识别出“图像中没有椅子”,只关注这只鸟。在厨房场景 (底部) 中,MARINE 阻止了模型列出不可见的通用厨房用品,而是准确地列出了微波炉和咖啡机。
它会损害文本质量吗?
对于引导方法,一个常见的担忧是它们可能会使输出文本变得机械或重复。研究人员使用 BLEU 和 ROUGE 等指标 (衡量与人类参考标题的相似度) 评估了通用文本质量。
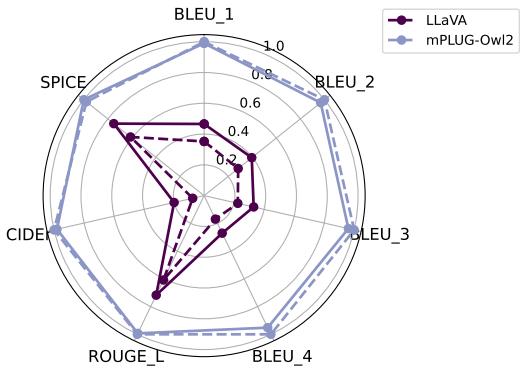
如雷达图所示,实线 (MARINE) 几乎完美覆盖或超过了虚线 (原始模型) 。这证实了 MARINE 在 不 降低语言生成的流畅性或丰富性的前提下减少了幻觉。
消融实验: 调整引导
研究人员还进行了消融研究,以了解不同组件如何影响性能。一个关键因素是 引导强度 (\(\gamma\)) 。
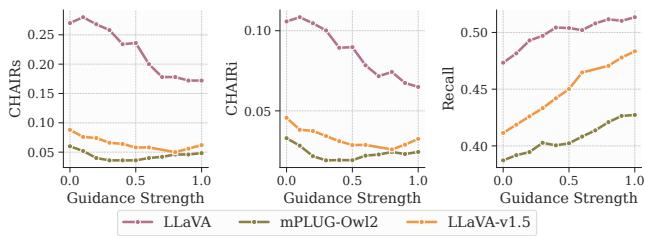
上面的图表显示,随着引导强度增加 (在 x 轴上向右移动) ,幻觉 (CHAIR 分数) 下降。然而,如果 \(\gamma\) 太高 (接近 1.0) ,模型可能会变得过于僵化。研究表明,采取中间值是在准确性和遵循指令之间取得平衡的最佳方案。
此外,他们发现使用不同视觉模型检测结果的 交集 (例如结合 DETR 和 RAM++) 比使用并集能提供更好的结果。取交集可以过滤掉噪音——只有当多个专家模型都同意时,一个物体才被认为是“存在的”。
效率
最后,MARINE 的一个主要优势是速度。像 Woodpecker 这样的后处理方法需要将数据发送给 GPT-4V 或运行第二个大型模型来重写标题,这很慢。

MARINE 在解码过程中直接工作。如表 5 所示,延迟开销极小 (大约是标准贪婪解码的 2 倍,而 LURE 或 OPERA 等方法则为 7 倍) 。这使得它在实时应用中具有可行性。
结论与启示
MARINE 框架为多模态 AI 迈出了引人注目的一步。通过承认通用视觉语言模型存在“盲点”,作者设计了一种方法,用专门的、基于图像的工具来增强它们。
主要收获包括:
- 无需训练: MARINE 可以立即改进 LLaVA 和 InstructBLIP 等现有模型,而无需昂贵的重新训练或微调数据集。
- 模块化: 它与各种外部视觉模型兼容。随着物体检测技术的进步,MARINE 也会自动随之改进。
- 有效: 它针对幻觉的根本原因 (缺乏视觉依据) 而非仅仅治疗症状,在幻觉基准测试中取得了最先进的结果。
对于进入该领域的学生和研究人员来说,MARINE 阐释了一个重要的教训: 有时解决方案不是更大的模型或更多的数据,而是一个允许不同专业系统协作的更智能的架构。通过将语言生成建立在经过验证的视觉证据之上,我们离不仅流畅而且真实的 AI 系统更近了一步。