](https://deep-paper.org/en/paper/2402.08702/images/cover.png)
超越单步: PROMST 如何掌握多步提示工程
如果你曾经使用过像 GPT-4 或 Claude 这样的大型语言模型 (LLM) ,你应该对提示工程 (Prompt Engineering) 这门“玄学”并不陌生。你在这里改一个词,在那里加一个约束条件,然后祈祷模型能输出你想要的结果。
对于简单的任务 (比如总结邮件或解决数学题) ,这种试错过程还是可控的。但当涉及到构建自主智能体 (Autonomous Agents) 时,这就成了一场噩梦。想象一下,一个 LLM 正在控制仓库中的机器人,或者一个网络智能体正在浏览复杂的电商网站。这些都是多步任务 。 它们需要规划、长程推理以及遵守严格的环境约束。
如果机器人在第 15 步撞墙了,是提示词错了吗?还是只是运气不好?当反馈循环如此漫长且复杂时,你该如何优化指令?
在这篇文章中,我们将深入探讨 PROMST (多步任务中的提示优化) , 这是一篇提出稳健框架以自动化此过程的研究论文。通过结合人类设计的反馈规则与学习到的评分模型,PROMST 展示了我们如何从手动修补转向自动化的、高性能的智能体设计。
多步挑战
在剖析解决方案之前,我们必须先理解问题所在。
大多数现有的自动提示优化 (APO) 研究都集中在单步任务上。例如,在一个数学应用题数据集中,模型接收输入并产生输出。如果答案是错的,“损失”是立即且清晰的。
多步任务引入了三个复合难点:
- 复杂性: 提示词通常很长 (300+ token) ,包含关于有效移动、库存管理和安全协议的详细说明。
- 信用分配 (Credit Assignment) : 如果智能体未能完成任务,很难确定是提示词的哪一部分导致了失败。是智能体误解了“拾取”命令,还是未能规划好通往物体的路径?
- 偏好: 不同的用户可能希望以不同的方式完成任务。有人可能优先考虑速度,而另一个人可能优先考虑安全性 (避免碰撞) 。
人类很难优化这些提示词,因为搜索空间是无限的。然而,人类非常擅长一件事: 发现错误 。 我们可以很容易地查看日志并指出: “智能体陷入了死循环”或“智能体试图穿墙”。
PROMST 利用了这种人类的批评能力,结合 LLM 的重写能力,创建了一个强大的优化循环。
PROMST 框架
PROMST 的核心思想是将提示工程视为一个进化搜索问题,但通过特定的反馈和启发式方法来引导它,从而使其高效。
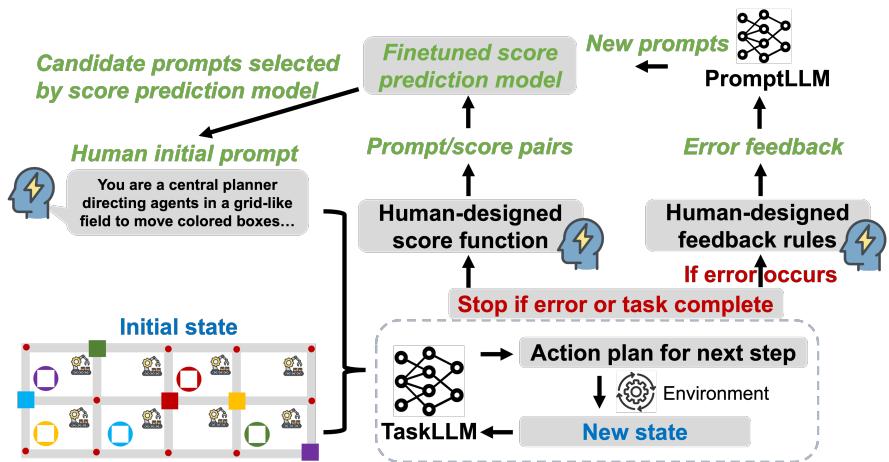
如图 1 所示,该框架在一个循环中运行,涉及三个主要组件:
- TaskLLM: 与环境交互的智能体 (例如 GPT-3.5 或 GPT-4) 。
- PromptLLM: 一个独立的 LLM,负责分析反馈并生成改进后的提示词。
- 分数预测模型 (Score Prediction Model) : 一个启发式模型,用于在我们要浪费资源进行测试之前过滤掉糟糕的提示词。
让我们分解这些部分是如何协同工作的。
1. 反馈循环: 人类规则遇上 AI 推理
在一个典型的优化循环中,LLM 可能会查看失败案例并尝试“猜测”出了什么问题。然而,在复杂环境中,LLM 经常会对错误原因产生幻觉。
PROMST 通过使用人类设计的反馈规则来稳定这一过程。这些不是复杂的代码,而是对错误进行分类的简单模板。
如上图 (左侧) 所示,系统将错误分类为特定类型:
- 语法错误 (Syntactic Error) : 模型输出与所需的 JSON 或文本格式不匹配。
- 陷入循环 (Stuck in a Loop) : 智能体重复相同的动作序列而没有任何进展。
- 碰撞 (Collision) : 智能体试图移动到被占用的空间。
- 无效动作 (Invalid Action) : 智能体试图使用它没有的工具。
当 TaskLLM 失败时,系统不会只说“失败”。它会填充这些模板之一。例如: “错误: 陷入循环。你执行了‘向北移动’动作 5 次而状态未改变。”
这种结构化的反馈被传递给 PromptLLM 。 PromptLLM 随后充当“元优化器”。它读取当前的提示词,读取特定的错误反馈,并重写提示词以明确解决该故障模式。
2. 目标函数
在数学上,目标是找到一个提示词 \(P^*\),使其在一组任务中最大化期望回报。
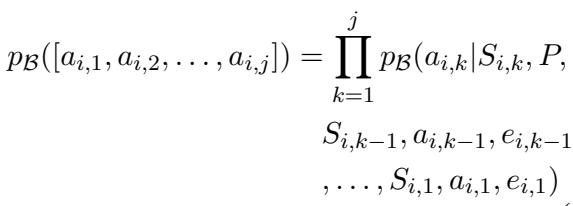
上面的方程表示动作序列的概率。PROMST 框架寻求在所有测试试验 \(U\) 中最大化评分函数 \(R\):
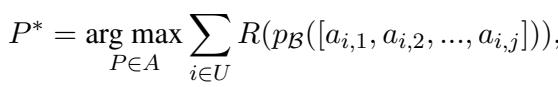
在这里,\(R\) 通常是“任务进度得分”——已完成的子目标与总子目标之比。
3. 效率黑客: 分数预测模型
提示优化的最大瓶颈之一是成本。验证多步任务的提示词非常昂贵。你必须让智能体通过模拟运行,这可能需要几十个步骤 (以及 API 调用) 。如果你生成了 100 个候选提示词,你无法承担全部测试的费用。
PROMST 引入了一个分数预测模型来解决这个问题。
这是一个经过微调的模型 (基于 Longformer) ,它可以学习仅通过阅读提示词文本来预测提示词的表现。
- 第一阶段 (探索) : 在早期几代中,系统运行昂贵的测试以收集数据。它收集
(提示词文本, 实际分数)对。 - 第二阶段 (利用) : 一旦收集了足够的数据,就会训练分数预测模型。对于随后的几代,PromptLLM 生成许多候选者,但分数预测模型充当看门人。
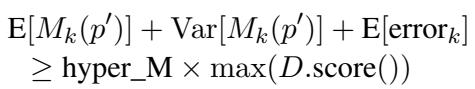
如上式所示,只有当候选提示词 \(p'\) 的预测分数 (加上方差和误差幅度) 超过相对于当前最佳分数的特定阈值时,它才会被选中进行真实世界的测试。这使得 PROMST 能够广泛地探索提示词空间,而不会将 API 额度浪费在明显糟糕的提示词上。
实验设置
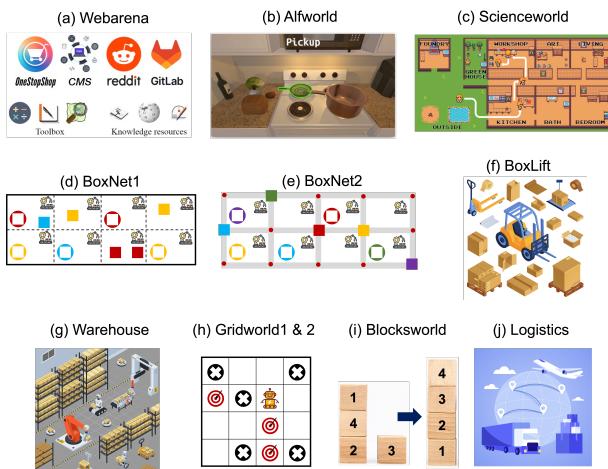
研究人员在 11 个代表性的多步任务上评估了 PROMST,范围从数字智能体到具身机器人模拟。这些环境 (如图集中的图 3 所示) 包括:
- WebArena: 真实的网页浏览模拟 (购物、Reddit、CMS) 。
- ALFWorld: 基于文本的家庭任务 (例如,“清洗苹果并将其放入冰箱”) 。
- BoxLift / Warehouse / Logistics: 涉及移动物体、避开碰撞和协调多个智能体的网格世界规划任务。
- ScienceWorld: 一个需要科学推理的复杂文本冒险游戏。
他们将 PROMST 与几个强大的基准进行了比较,包括:
- APE (Automatic Prompt Engineer)
- APO (Automatic Prompt Optimization)
- PromptAgent (一种使用蒙特卡洛树搜索的最先进方法)
- PromptBreeder (进化算法)
关键结果: 主导基准测试
结果具有统计学意义。PROMST 始终优于人类设计的提示词和自动化基准。
在 GPT-3.5 和 GPT-4 上的表现
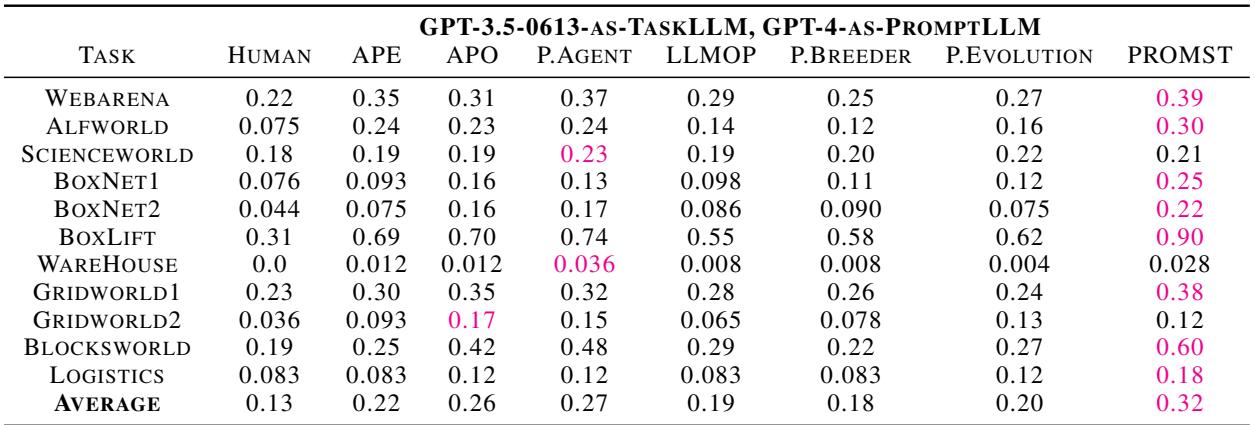
下表详细列出了使用 GPT-3.5 作为任务智能体时的表现。PROMST 获得了最高的平均分 (0.32) ,显著击败了第二好的方法 PromptAgent (0.27) 。
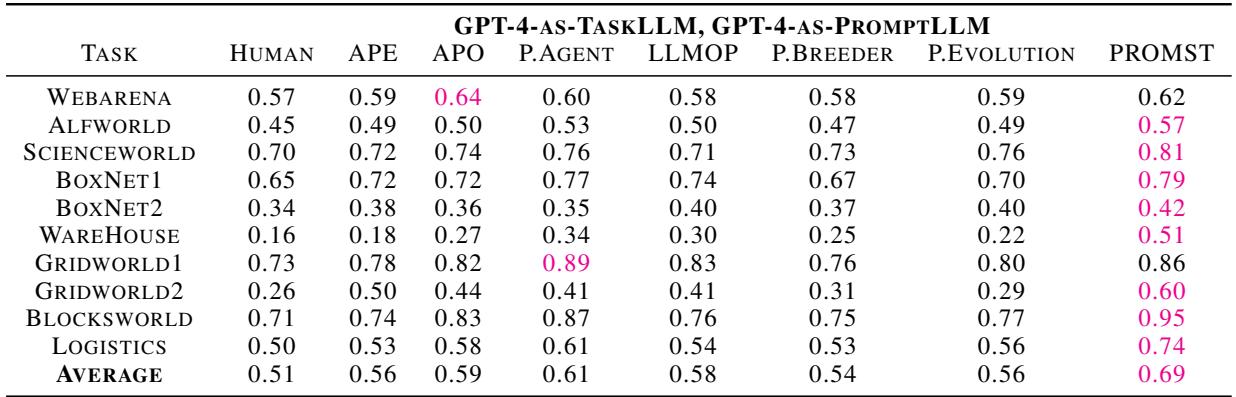
当使用 GPT-4 时,领先优势进一步扩大。PROMST 获得了 0.69 的平均分,而人类基准为 0.51,PromptAgent 为 0.61。
显著的胜利包括:
- BoxLift: 在 GPT-3.5 上从 0.31 (人类) 大幅跃升至 0.90 (PROMST) 。
- Blocksworld: 在 GPT-4 上从 0.71 (人类) 提高到 0.95 (PROMST) 。
- Gridworld: 寻路逻辑的一致性改进。
为什么它有效?组件的影响
为了理解 PROMST 为什么有效,作者进行了消融研究——移除系统的部分组件以观察哪些部分会崩溃。
1. 分数预测模型的力量
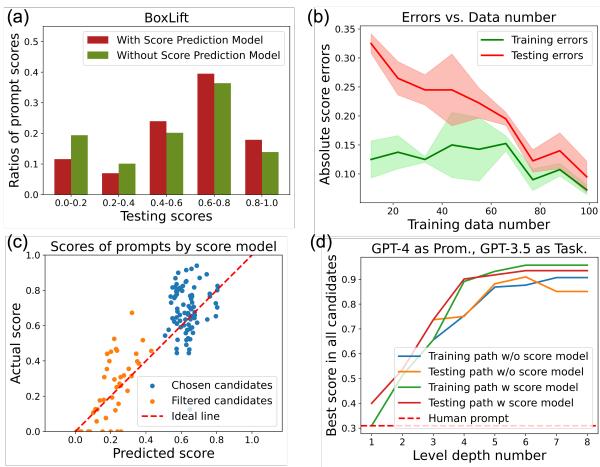
图 4(a) 显示了分数的分布。红色条形 (有分数模型) 与绿色条形 (无分数模型) 相比显着向右移动。这证明该模型成功过滤掉了低质量的提示词。
图 4(d) 展示了优化轨迹。绿色线条 (使用分数模型训练) 比蓝色线条 (不使用分数模型训练) 收敛得更快且得分更高。这本质上“加速”了进化。
2. 人类反馈的必要性
人类反馈规则集真的是必要的吗?LLM 能不能自己搞定?
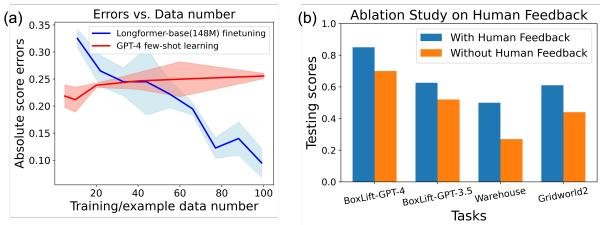
图 5(b) 给出了一个鲜明的答案。在像 BoxLift 和 Warehouse 这样的任务中,移除人类反馈 (橙色条) 导致性能与完整的 PROMST 方法 (蓝色条) 相比大幅下降。这验证了一个假设: 虽然 LLM 是优秀的优化器,但它们需要结构化的、真实的 (ground-truth) 错误信号来知道优化什么。
深入探讨: 什么造就了“好”的提示词?
这项研究最有趣的一个方面是对生成的提示词的分析。PROMST 究竟写了什么让智能体表现得更好?
1. 越长 (通常) 越好
与简洁的提示词能提高 token 效率的观念相反,PROMST 发现在多步推理中, 细节很重要 。
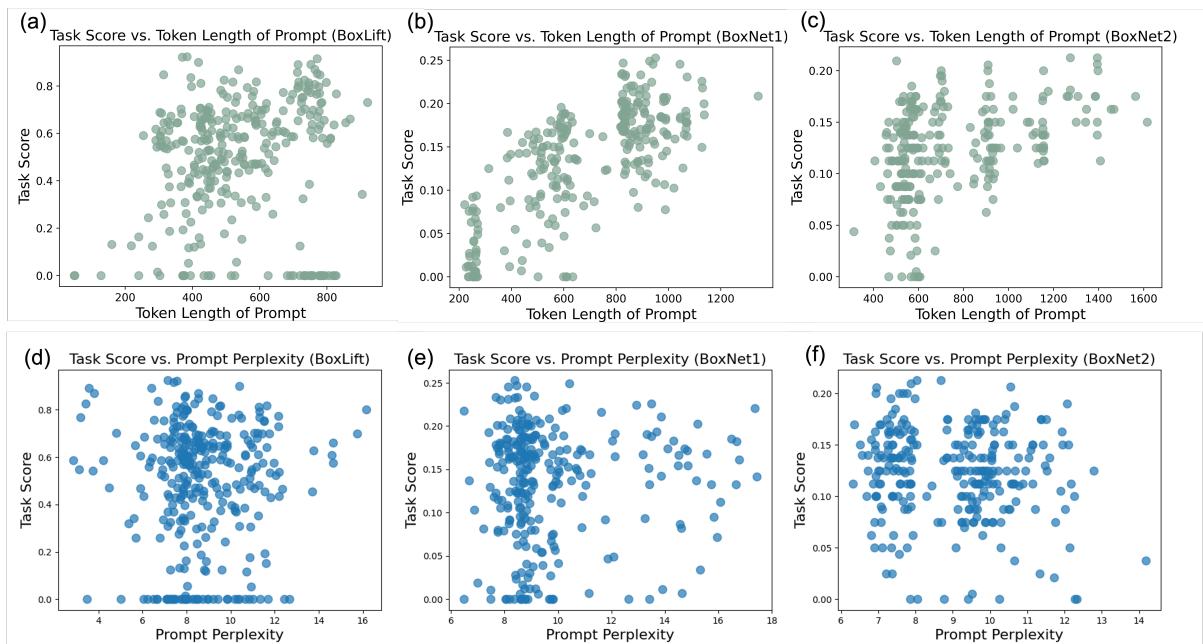
如图 13 (第一行) 所示,提示词长度与任务得分之间普遍存在正相关关系。优化后的提示词倾向于包含明确的检查清单、边缘情况处理和逐步推理协议。
2. 清晰度和结构
研究人员发现,最好的提示词通常会“清晰地逐一列出注意事项”。为了验证这一点,他们选取了 PROMST 生成的最佳提示词,并要求 GPT-4 对其进行总结 (缩短) 。
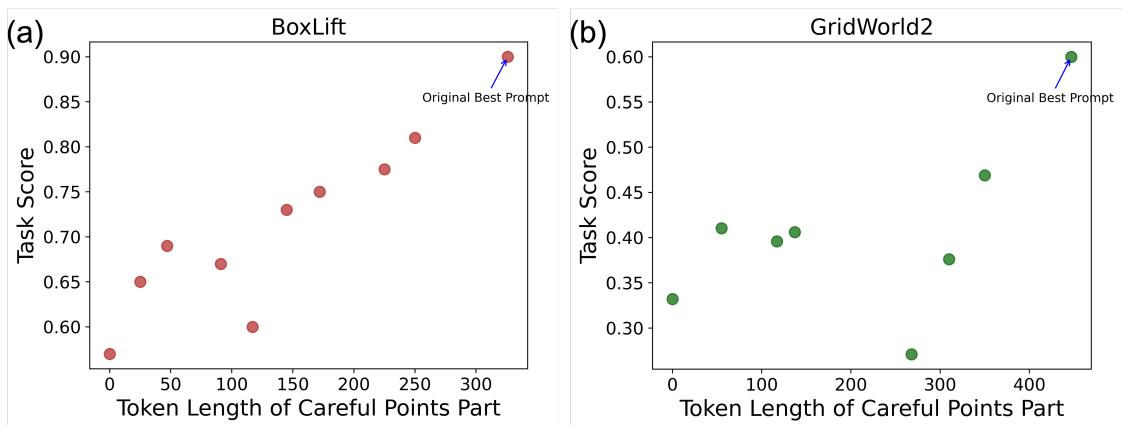
图 14 显示了直接的线性关系: 当你压缩指令 (减少 token 长度) 时,得分也会下降。这表明“冗长”并非废话——它是模型必要的认知支架。
3. 与人类偏好对齐
一个能完成目标的提示词,如果效率低下或危险,可能仍然是“糟糕”的。例如,在机器人导航任务中,我们可能关心最小化步数和避免差点发生的碰撞。
论文探讨了修改评分函数以包含对不良行为 (如高步数或碰撞) 的惩罚。
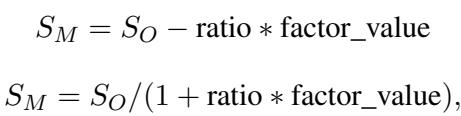
通过调整评分公式 (如上所示) 来惩罚步数计数 (step_num) 或碰撞计数 (factor_value) ,PROMST 成功地引导了优化方向。
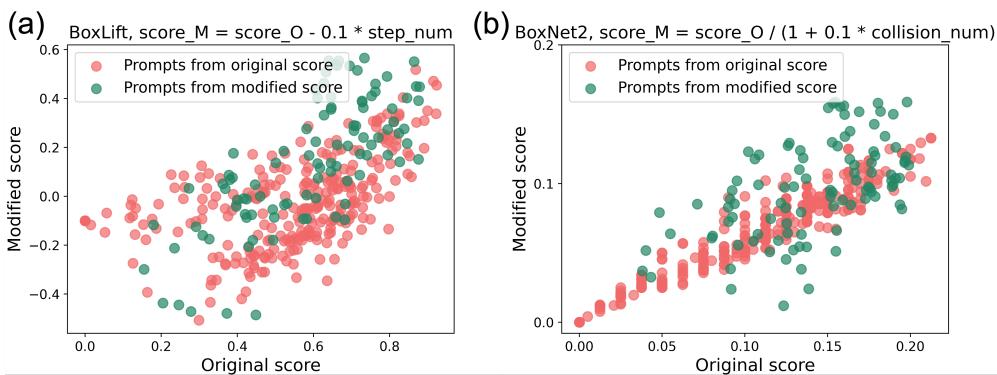
图 12 显示了这种对齐的结果。绿点代表使用修改后的评分规则优化的提示词。在图 12(a) 中,绿点在 Y 轴 (修改后得分) 上聚集得较低,但保持了较高的完成率,表明模型学会了在仅仅完成任务和高效完成任务之间进行权衡。
结论与未来展望
PROMST 代表了在使自主智能体变得可靠方面迈出的重要一步。它承认虽然 LLM 很强大,但在复杂环境中它们尚未能完全自我纠正。通过注入少量的人类领域知识 (通过反馈规则) 并使用智能采样 (通过分数模型) ,我们可以解锁手动工程根本无法比拟的性能能力。
给学生和从业者的关键启示:
- 不要依赖通用反馈: 对于复杂的智能体,创建特定的错误类别 (循环、语法、逻辑) 。
- 评估是瓶颈: 如果你能建立一个更便宜的启发式方法来预测提示词质量,那就去做。这能让你搜索更大的空间。
- 冗长有其价值: 在多步规划中,明确、详细的指令往往优于简洁的指令。
随着我们迈向更通用的智能体,像 PROMST 这样的框架可能会成为将高级人类意图“编译”为可执行智能体行为的标准。猜测和检查提示词的时代正在结束;优化它们的时代才刚刚开始。