](https://deep-paper.org/en/paper/2402.11129/images/cover.png)
大语言模型 (LLM) 彻底改变了我们处理信息的方式,在摘要、对话和问答方面充当了强有力的助手。然而,任何深度使用过它们的人都知道它们的软肋: 它们并不是无所不知的。它们的知识被冻结在训练的那一刻,而且它们可能会自信地产生错误事实的“幻觉”。
为了解决这个问题,AI 社区采用了检索增强生成 (RAG) 。 这个想法很简单: 在 LLM 回答之前,它会搜索数据库 (如维基百科) ,找到相关文档,并利用这些信息生成答案。
但标准的 RAG 已经遇到了瓶颈。当用户提出复杂的多跳问题 (即需要连接两个不同信息片段的问题) 时,标准检索往往无法找到正确的文档。此外,如果检索器带回了不相关的“噪声”,LLM 就会感到困惑并给出糟糕的答案。
在这篇文章中,我们将深入探讨一个名为 BlendFilter 的新框架。这种方法由纽约州立大学奥尔巴尼分校、普渡大学、佐治亚理工学院和亚马逊的研究人员提出,通过引入两种巧妙的机制显著推进了 RAG 的发展: 查询生成混合 (Query Generation Blending) 用于扩大信息搜索范围,以及知识过滤 (Knowledge Filtering) 用于精细地从噪声中分离出有用数据。
标准检索的问题
要理解为什么 BlendFilter 是必要的,我们首先需要看看当前方法的不足之处。
1. 复杂查询的挑战
想象一下问 LLM: “哪部电影先上映,《盲井》还是《傅满洲的面具》?”
标准检索器会按字面意思处理这个查询。它会寻找包含这些关键词的文档。然而,复杂问题通常需要“隐性”知识。如果检索器错过了《盲井》的上映日期,LLM 就无法回答这个问题。标准 RAG 依赖于使用用户原始输入进行一次性检索,这对于那些在搜索之前就需要推理的问题来说往往是不够的。
2. 噪声问题
当前的方法通常会检索前 K 个文档 (例如,前 5 或 10 个匹配项) 。但检索并不完美。可能其中只有 2 个文档是相关的,而其他 3 个是关于完全不同主题但包含相似关键词的文档。当你将不相关的“噪声”输入到 LLM 中时,它通常会试图强行建立某种不存在的联系,从而导致幻觉。
以前解决这个问题的尝试包括训练单独的“重写”模型或复杂的分类器来过滤数据。这些方法计算成本高昂且难以实施。BlendFilter 提供了一个更优雅的解决方案。
BlendFilter 框架
BlendFilter 旨在回答这个问题: 我们如何确保检索到所需的一切,而又不让 LLM 淹没在噪声中?
解决方案是一个三步流程:
- 查询生成混合: 创建多个增强版本的查询,以确保找到所有相关文档。
- 知识过滤: 利用 LLM 自身的推理能力来丢弃不相关的文档。
- 答案生成: 仅使用高质量、经过过滤的数据生成最终回复。
在详细拆解之前,让我们先将其架构可视化:
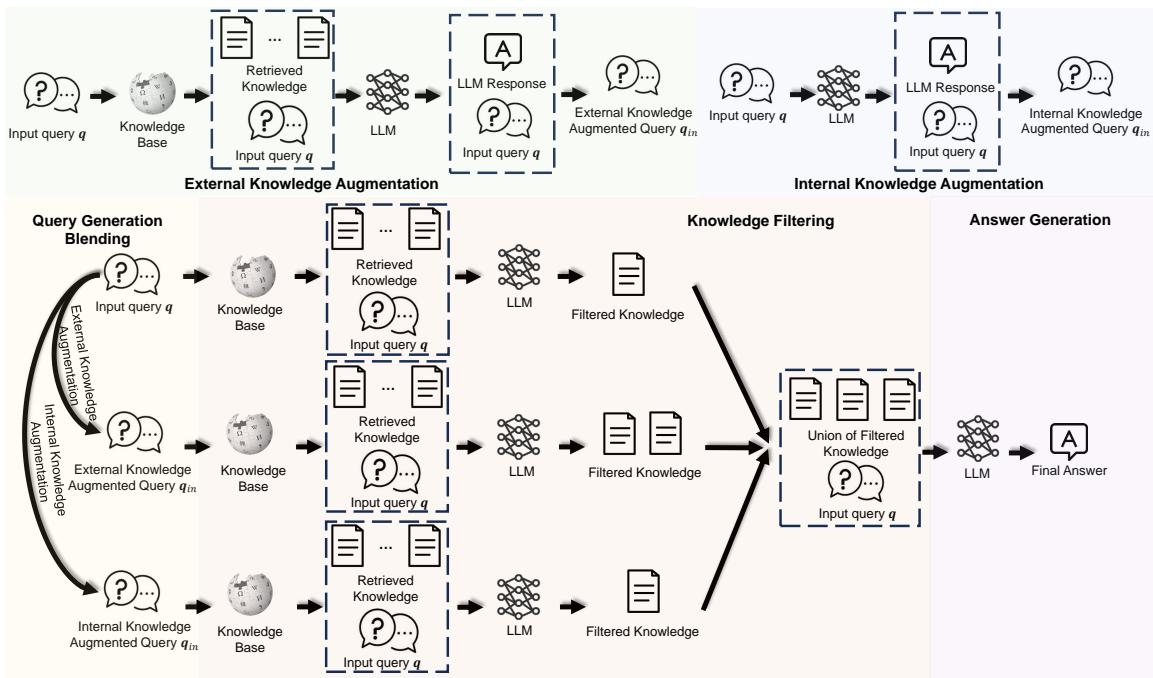
如图 1 所示,该过程分为汇聚到过滤阶段的并行路径 (增强) 。让我们详细探讨这些组件。
第一部分: 查询生成混合
研究人员意识到,依赖单一来源进行查询增强是有风险的。如果你只使用外部知识,你可能会错过 LLM 已经知道的逻辑联系。如果你只使用 LLM 的内部知识,通过幻觉产生错误的风险就会增加。
BlendFilter 采用混合方法,结合了三种不同的查询类型:
1. 原始查询 (\(q\))
这是用户的原始输入。保留它是为了确保在过程中永远不会丢失原始意图。
2. 外部知识增强 (\(q_{ex}\))
这处理的是“未知的未知”。对于复杂问题,模型会执行初步检索。
- 系统根据原始查询检索文档。
- LLM 基于这些文档生成初步答案或“思维链”推理。
- 生成的推理与原始查询连接,形成 \(q_{ex}\)。
这本质上是一个“两跳”推理技巧。通过让模型“思考”第一批文档,它会生成可能对找到答案的其余部分至关重要的新关键词。
3. 内部知识增强 (\(q_{in}\))
LLM 已经记住了大量的知识。即使它们不能完美地回答具体问题,它们可能知道有助于检索的背景信息。
- 系统要求 LLM 仅使用其内部记忆生成一段回答问题的段落。
- 生成的段落与原始查询连接,形成 \(q_{in}\)。
通过混合这三种查询 (\(q\)、\(q_{ex}\) 和 \(q_{in}\)) ,系统创建了一个涵盖外部数据库和内部语义理解的综合搜索策略。
第二部分: 知识过滤
通过使用三种不同的查询,我们撒下了一张非常大的网。虽然这确保了我们很可能捕捉到了正确的答案,但也意味着我们很可能拉入了大量不相关的文档 (噪声) 。
如果我们简单地将所有这些文档输入到 LLM 中,噪声就会掩盖信号。这就是知识过滤模块发挥作用的地方。
BlendFilter 没有训练单独的 BERT 分类器或复杂的神经网络来判断相关性,而是提示 LLM 本身充当过滤器。研究人员将检索到的文档和原始查询输入到 LLM 中,并给出特定指令: 识别并仅选择与回答此查询相关的文档。
这针对每个查询流独立进行:
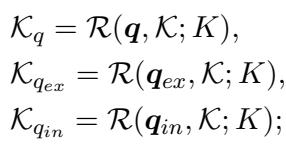
一旦为每个流检索到知识,就会对其进行过滤。最后,系统取这些过滤后集合的并集 :
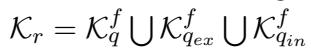
这产生了一个相关性高且噪声低的精选文档列表 (\(K_r\)) 。
与其他方法的比较
了解 BlendFilter 与其他流行的 RAG 技术 (如 ReAct 或 ITER-RETGEN) 的区别很有帮助。
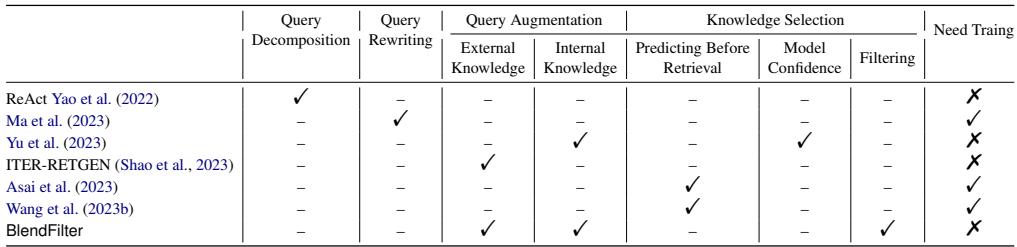
如表 6 所示,BlendFilter 的独特之处在于它结合了外部和内部增强,并且包含一个特定的过滤步骤,所有这些都不需要训练辅助模型。
实验与结果
为了证明 BlendFilter 的有效性,作者在三个具有挑战性的开放域问答基准上对其进行了测试:
- HotPotQA: 需要多跳推理。
- 2WikiMultihopQA: 另一个需要连接多个事实的数据集。
- StrategyQA: 侧重于隐性推理策略。
他们使用三种不同的 LLM 骨干模型测试了该框架: GPT-3.5-turbo-Instruct、Vicuna 1.5-13b 和 Qwen-7b 。
主要性能表现
结果全面令人印象深刻。下面是使用 GPT-3.5-turbo-Instruct 的性能表。
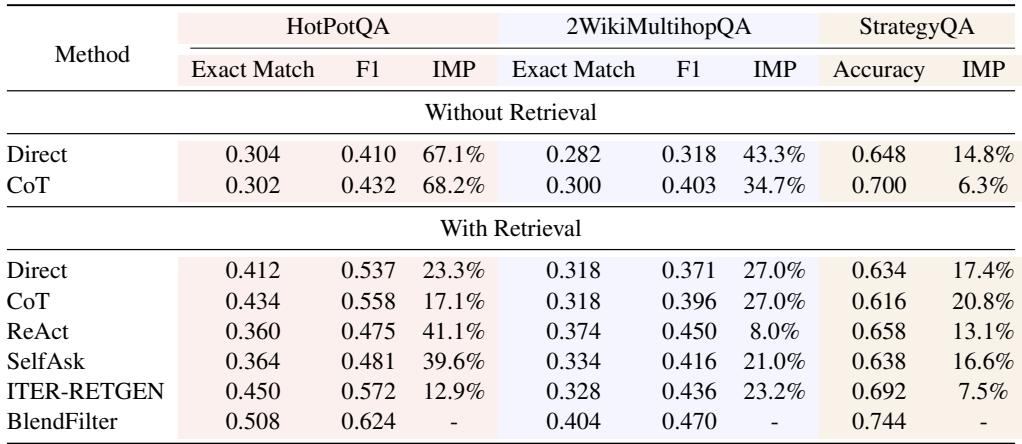
在 HotPotQA 上,BlendFilter 实现了 0.508 的精确匹配 (EM) 得分,显著优于最先进的 ITER-RETGEN (0.450) 和标准的带检索 CoT (0.434)。提升 (IMP) 列突出了相对于各种基线近 13-40% 的收益。
这对于较小的开源模型是否适用?是的。
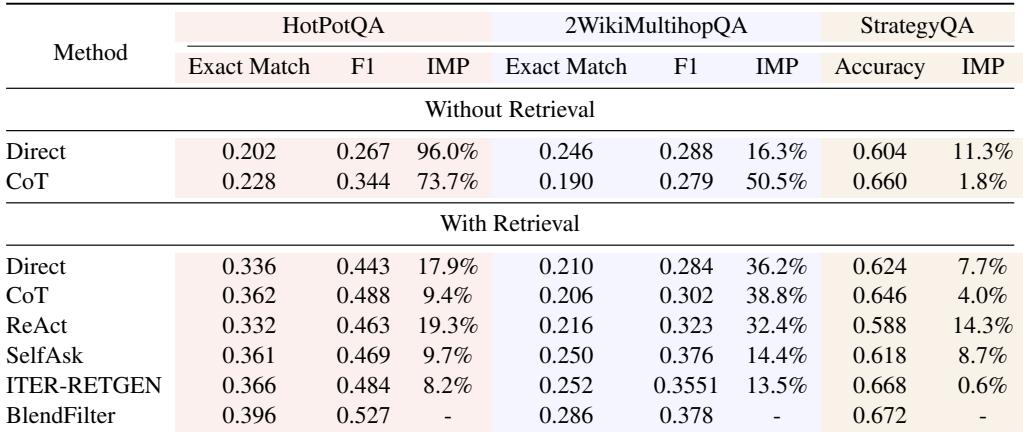
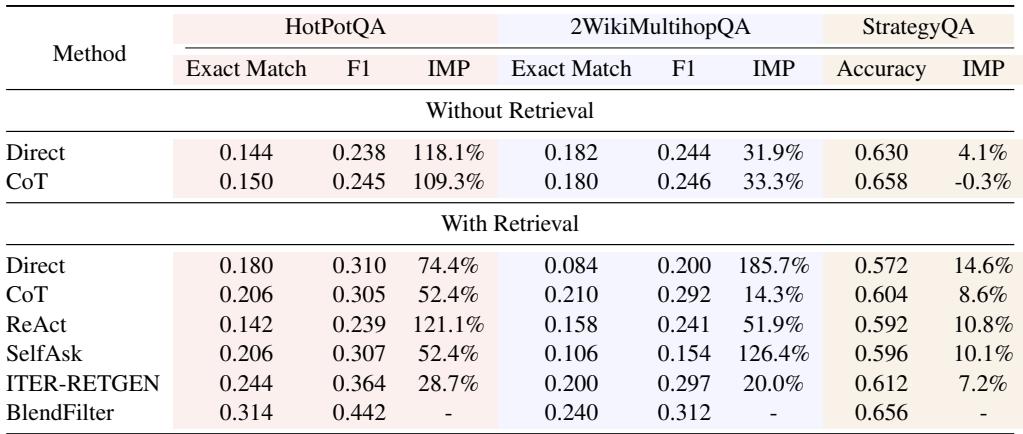
如表 2 (Vicuna) 和表 3 (Qwen) 所示,BlendFilter 始终提供最佳性能。这表明该方法是模型无关的;它改善了大型专有模型和较小开源模型的推理能力。
过滤真的有效吗?
人们可能会问: 改进是来自于“混合” (更多查询) 还是“过滤”?答案是两者兼有,但过滤对于精确度至关重要。
研究人员使用雷达图分析了检索质量,测量了精确率 (Precision) 、召回率 (Recall) 和“S-精确率” (与黄金相关文档的匹配度) 。
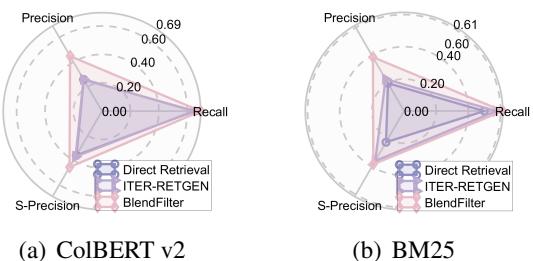
在图 2 中,观察 ColBERT v2 图表 (左) ,我们可以看到 BlendFilter (粉红线) 在保持高召回率 (找到正确文档) 的同时保持了高精确率。ITER-RETGEN 虽然召回率不错,但精确率较低,这意味着它引入了太多噪声。
消融实验: 我们需要所有三种查询吗?
是否有必要生成外部和内部增强查询?研究人员进行了一项消融研究,移除了特定类型的查询以查看性能如何下降。
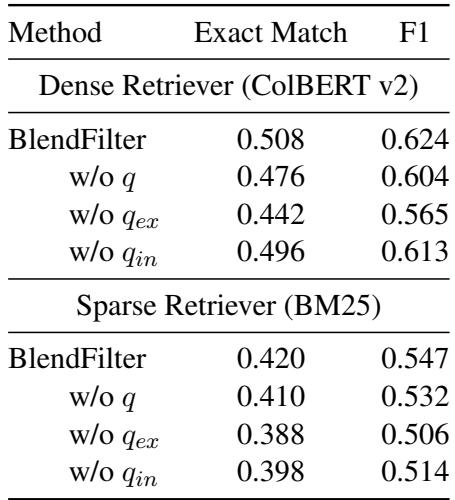
表 5 显示,移除三种查询类型中的任何一种都会导致性能下降。
- 移除 \(q_{ex}\) (外部) 影响显著,因为模型失去了“两跳”搜索能力。
- 移除 \(q_{in}\) (内部) 也有影响,证实了 LLM 的内部记忆提供了外部搜索引擎可能错过的背景信息。
文档数量 (K) 的影响
我们应该检索多少个文档?在标准 RAG 中,增加文档数量 (\(K\)) 在达到一定点后往往会损害性能,因为噪声变得压倒性。
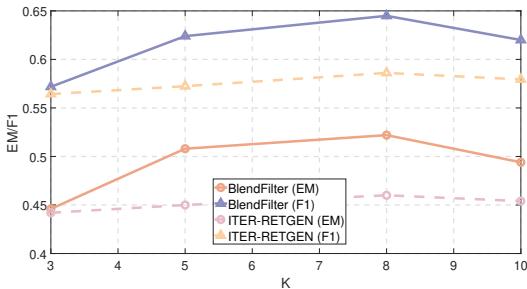
图 3 揭示了 BlendFilter 的一个关键优势。虽然 ITER-RETGEN (紫线) 随着 \(K\) 的增加收益微乎其微或停滞不前,但 BlendFilter (粉红线) 在 \(K=8\) 之前持续改进。因为 BlendFilter 有主动过滤机制,它可以处理更大的检索文档池而不会感到困惑,从而有效地从更大的搜索空间中提取价值。
一致性和采样
最后,研究人员检查了模型是仅仅“侥幸”还是持续表现更好。他们测试了采样多个答案时的性能 (Top-P 采样) 。
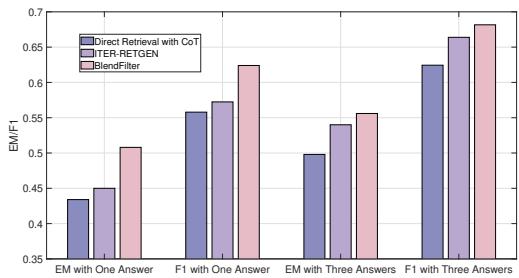
图 4 显示,无论是检查“单次回答的 EM”还是“三次回答的 EM”,BlendFilter 都优于竞争对手。它表现出更低的方差,意味着它在生产环境中更可靠。
结论与启示
BlendFilter 论文为检索增强生成提供了一个更复杂的论证。它指出 RAG 的两个最大瓶颈是搜索范围有限 (通过混合解决) 和信息过载 (通过过滤解决) 。
给学生和从业者的关键要点:
- 不要相信单一查询: 用户查询通常是不完美的。利用外部搜索结果和内部模型知识对其进行增强,可以创建一个稳健的搜索策略。
- LLM 是优秀的过滤器: 你并不总是需要专门的分类器。一个提示得当的 LLM 可以有效地评判其检索到的数据,将相关背景与噪声分离。
- 泛化能力: 该框架适用于不同的模型架构和检索类型 (稀疏 BM25 和密集 ColBERT) ,使其成为 AI 工程的通用工具。
随着 LLM 继续融入复杂的工作流程,像 BlendFilter 这样的技术对于超越简单的聊天机器人,迈向能够进行严谨、多步研究和推理的系统将至关重要。