](https://deep-paper.org/en/paper/2402.13593/images/cover.png)
超越复制粘贴: 利用知识图谱编辑大语言模型
想象一下,你正在阅读一本由大语言模型 (LLM) 生成的勒布朗·詹姆斯 (LeBron James) 传记。模型正确地陈述道: “勒布朗·詹姆斯效力于洛杉矶湖人队。”但是当你问: “勒布朗·詹姆斯在洛杉矶工作吗?”模型却犹豫了,或者更糟糕的是,自信地回答: “不,他在迈阿密工作。”
这种不一致性凸显了当前 AI 系统中的一个致命缺陷。LLM 存储了海量的世界知识,但这些知识可能会过时或在事实层面出现错误。虽然我们有办法“编辑”特定的事实——就像更新数据库条目一样——但 LLM 很难处理这些编辑带来的连锁反应 (Ripple Effects) 。 改变球队归属逻辑上应该同时改变工作城市、队友和主场场馆。
在这篇文章中,我们将深入探讨一篇名为 《Knowledge Graph Enhanced Large Language Model Editing》 (知识图谱增强的大语言模型编辑) 的研究论文,该论文介绍了一种名为 GLAME 的新方法。这种方法不仅仅是修补单一事实;它利用知识图谱 (KGs) 来理解和更新围绕该事实的关系网,确保模型在处理新信息时保持一致并具备推理能力。
问题所在: 连锁反应
模型编辑是指在不重新训练整个模型 (因为成本过高) 的情况下,修改 LLM 参数以纠正特定知识的过程。现有的方法如 ROME (秩一模型编辑) 和 MEMIT 在更新单一事实方面已经非常成功,例如将 \((s, r, o)\) 更改为 \((s, r, o^*)\)。
然而,知识很少是孤立的。它是相互关联的。
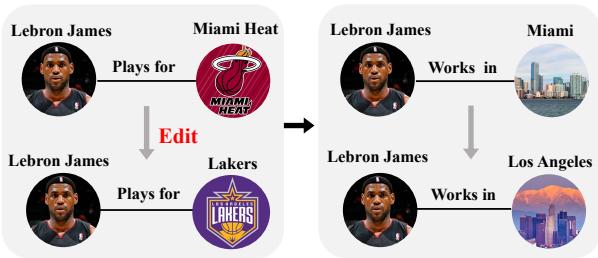
如上图 1 所示,如果我们将勒布朗·詹姆斯效力的球队从迈阿密热火队更新为洛杉矶湖人队,模型必须也能推断出他现在在洛杉矶工作。如果模型更新了显式事实但未能更新相关的隐含信息,模型就会变得内部不一致。这种失败限制了编辑后 LLM 的泛化能力 。
研究人员认为,LLM 的“黑盒”特性使得在内部检测这些关联变得非常困难。因此,他们建议引入一张外部地图: 知识图谱。
背景: 模型编辑是如何工作的
要理解 GLAME,我们需要先了解它建立的基础: 秩一模型编辑 (Rank-One Model Editing, ROME) 。
ROME 方法基于这样一个假设: Transformer 层内的前馈神经网络 (FFNs) 充当键值记忆 (Key-Value Memories) 。 在这个概念框架中,特定的主体 (如“勒布朗·詹姆斯”) 充当*键 (key) ,而该层的输出充当值 (value) * (如“效力于湖人队”等属性) 。
在数学上,第 \(l\) 层 FFN 对第 \(i\) 个 token 的输出描述为:
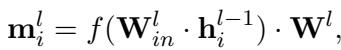
这里,\(\mathbf{h}_i^{l-1}\) 是来自上一层的输入。运算的第一部分创建一个“键” (\(\mathbf{k}\)) ,第二个权重矩阵 \(\mathbf{W}^l\) 将其转换为“值” (\(\mathbf{m}\)) 。
优化目标
在编辑模型时,目标是找到一个新的权重矩阵 \(\hat{\mathbf{W}}\),以满足一个特定的约束: 当模型看到主体的键 (\(\mathbf{k}_*\)) 时,它应该输出代表新事实的特定目标向量 (\(\mathbf{m}_*\)) 。同时,我们希望尽可能少地改变权重,以避免破坏其他知识。
这被公式化为一个约束最小二乘问题:
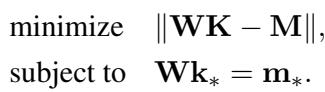
这里,\(\mathbf{K}\) 和 \(\mathbf{M}\) 代表我们想要保留的所有其他知识,而约束 \(\mathbf{Wk}_* = \mathbf{m}_*\) 确保我们的特定编辑生效。
ROME 提供了一个闭式解来计算新的权重:
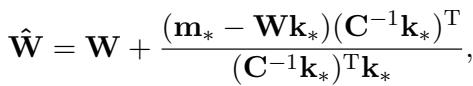
在这个方程中,\(\mathbf{C}\) 是从文本语料库 (如维基百科) 预先计算出的键的协方差矩阵。
ROME 的局限性: ROME 通过仅针对特定目标事实 (勒布朗 -> 湖人队) 进行优化来计算目标向量 \(\mathbf{m}_*\)。它没有明确地查看邻居节点 (湖人队 -> 洛杉矶) 。这正是 GLAME 介入的地方。
核心方法: GLAME
GLAME (Graphs for LArge language Model Editing,用于大语言模型编辑的图) 通过使用知识图谱显式建模“连锁反应”来增强编辑过程。其架构分为两个主要模块:
- 知识图谱增强 (KGA): 寻找关联知识。
- 基于图的知识编辑 (GKE): 将这种结构注入模型。
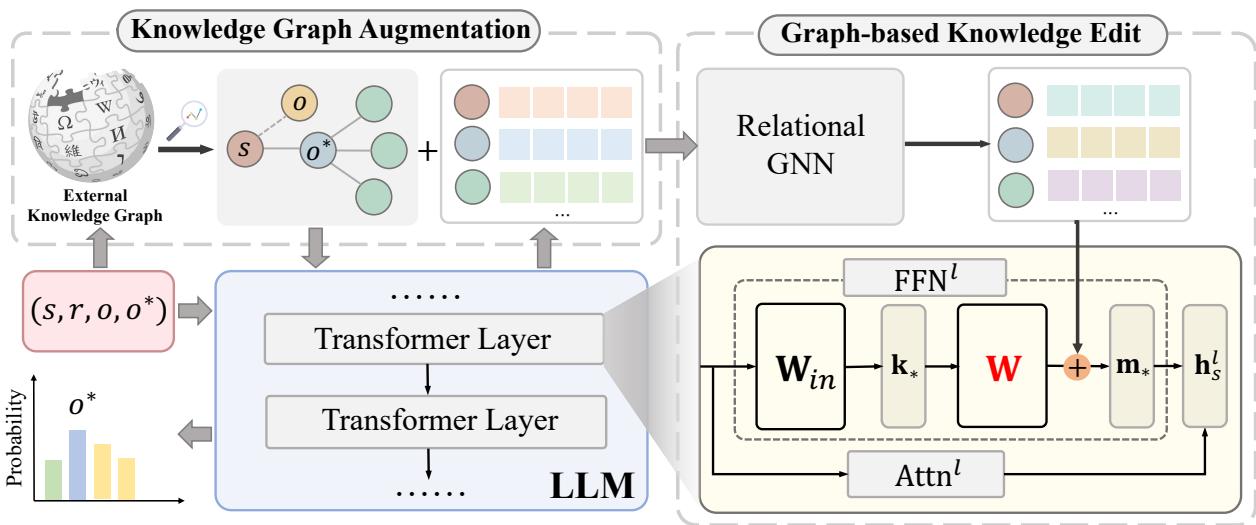
让我们拆解图 2 中展示的架构。
模块 1: 知识图谱增强 (KGA)
当系统接收到一个编辑请求 \(e = (s, r, o, o^*)\) 时,它不仅仅是看文本。它会查询外部知识图谱 (如 Wikidata) 以找到新对象 \(o^*\) 及其邻居。
例如,如果 \(o^*\) 是“洛杉矶湖人队”,KGA 模块可能会提取像 * (湖人队,位于,洛杉矶) * 或 * (湖人队,属于,NBA) * 这样的三元组。它构建了一个包含这些新高阶关系的子图 。
但仅有原始图数据是不够的;LLM 需要用自己的语言“理解”这些实体。研究人员利用 LLM 本身来初始化该子图中实体的表示。他们将实体的文本输入 LLM,并从早期层提取隐藏状态:
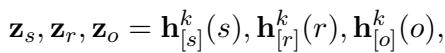
通过使用来自早期层 (第 \(k\) 层) 的隐藏状态 \(\mathbf{h}_{[s]}^k\),他们获得了一个与 LLM 内部嵌入空间对齐的向量表示。
模块 2: 基于图的知识编辑 (GKE)
现在我们有了一个代表新上下文的子图,我们需要对其进行编码。研究人员采用了关系图神经网络 (RGNN) 。
RGNN 聚合来自邻居的信息以更新主体 \(s\) 的表示。这有效地“教导”了主体向量关于其新连接的信息。
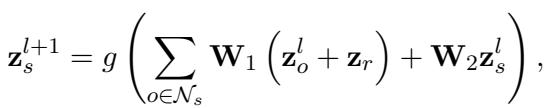
在这个方程中:
- \(\mathcal{N}_s\) 是邻居的集合。
- \(\mathbf{W}_1\) 和 \(\mathbf{W}_2\) 是 GNN 的可学习权重。
- 该函数聚合邻居向量 \(\mathbf{z}_o\) 和关系向量 \(\mathbf{z}_r\) 来更新主体 \(\mathbf{z}_s\)。
这个过程创建了一个主体的“上下文感知”表示,记为 \(\mathbf{z}_s^n\)。
注入知识
这是最巧妙的部分。GLAME 没有优化一个随机向量作为目标 \(\mathbf{m}_*\),而是将目标向量定义为受图编码偏移后的主体原始记忆:
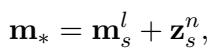
这个方程表明: “这个主体的新记忆应该是它的旧记忆 (\(\mathbf{m}_s^l\)) 加上从知识图谱中获得的信息 (\(\mathbf{z}_s^n\)) 。”
优化
GLAME 在训练阶段不直接更新 LLM 的参数。相反,它训练 RGNN 参数以产生完美的 \(\mathbf{m}_*\)。
损失函数由两部分组成。首先, 预测损失确保修改后的记忆实际上导致模型预测新对象 \(o^*\):
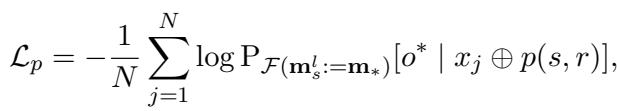
其次, 正则化损失 (KL 散度) 确保主体的一般表示保持稳定 (例如,“勒布朗是一名篮球运动员”这一点不应改变,即使他的球队变了) 。
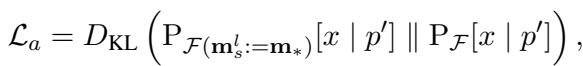
总损失结合了这两者:
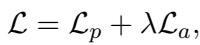
一旦 RGNN 经过训练使该损失最小化,我们就得到了最优的 \(\mathbf{m}_*\)。我们还使用标准方法计算键向量 \(\mathbf{k}_*\):
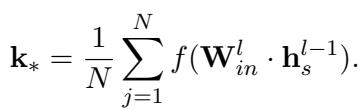
最后,利用 (经图增强的) 最优 \(\mathbf{m}_*\) 和 \(\mathbf{k}_*\),GLAME 使用与 ROME 完全相同的闭式更新方程 (见公式 3) 来更新 LLM 的权重。
实验与结果
研究人员在 GPT-2 XL (15亿参数) 和 GPT-J (60亿参数) 上评估了 GLAME。他们使用了三个数据集:
- COUNTERFACT: 单次编辑的标准基准。
- COUNTERFACTPLUS: 一个需要推理的更难的数据集。
- MQUAKE: 专门用于多跳问题的数据集。
指标解释
- 功效分数 (Efficacy Score): 编辑成功了吗? (它说“湖人队”了吗?)
- 转述分数 (Paraphrase Score): 如果我换个说法提问,它还有效吗?
- 邻域分数 (Neighborhood Score): 我们是否破坏了无关的事实?
- 可移植性分数 (Portability Score): 模型能利用新事实进行推理吗? (这是 GLAME 最关键的指标) 。
性能比较
下表 1 显示了主要结果。
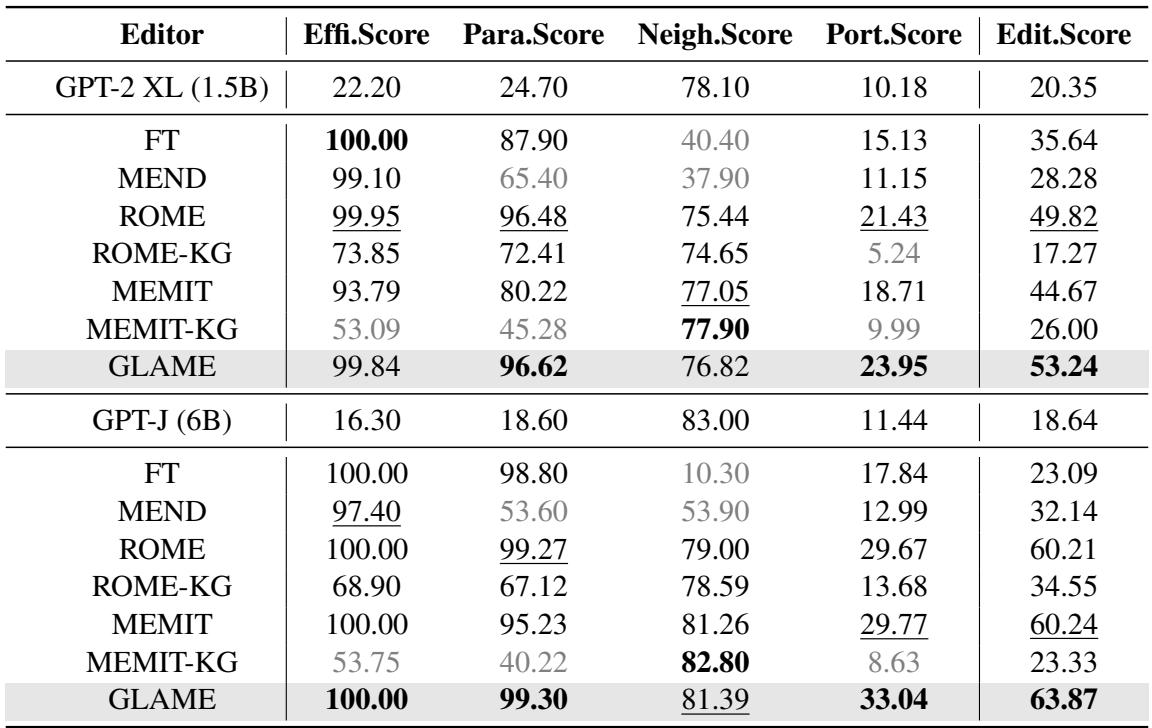
关键结论:
- 可移植性为王: GLAME 在可移植性分数上显著优于所有基线模型。对于 GPT-J,GLAME 的得分为 33.04%,而 ROME 为 29.67%,MEMIT 为 29.77%。这证明包含知识图谱有助于模型推理性地处理编辑的后果。
- 高编辑分数: GLAME 在两个模型上都取得了最高的整体“编辑分数” (指标的调和平均数) 。
- 基线的失败: 看看“ROME-KG”和“MEMIT-KG”。这些是作者尝试简单地将图三元组作为文本编辑强行灌输给 ROME/MEMIT 的基线。性能急剧下降。这表明仅仅拥有数据是不够的;你需要 GLAME 中 RGNN 提供的结构化集成。
消融研究: 我们需要图吗?
作者对 GLAME 进行了精简,以查看哪些部分至关重要。
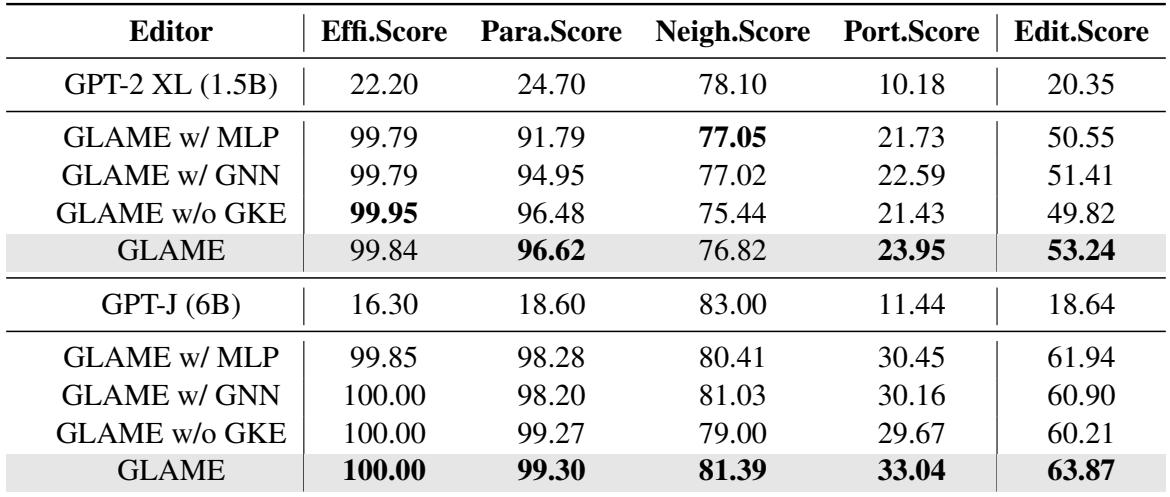
- GLAME w/ MLP: 用简单的 MLP 替换了图神经网络 (忽略了图结构) 。性能下降。
- GLAME w/o GKE: 完全移除了图模块 (本质上退化为 ROME) 。性能下降。
- 结论: GNN 处理的结构关系对于捕捉连锁反应至关重要。
敏感性分析
知识图谱应该有多复杂?
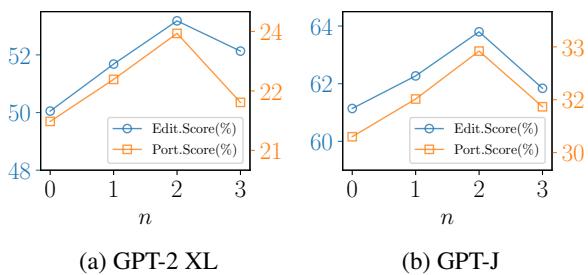
图 3 显示了子图阶数 (\(n\)) 的影响。\(n=1\) 意味着直接邻居,\(n=2\) 意味着邻居的邻居。结果表明 \(n=2\) 是最佳点 。 再深入 (\(n=3\)) 会引入噪声并损害性能。
同样,观察邻居的数量 (\(m\)) :
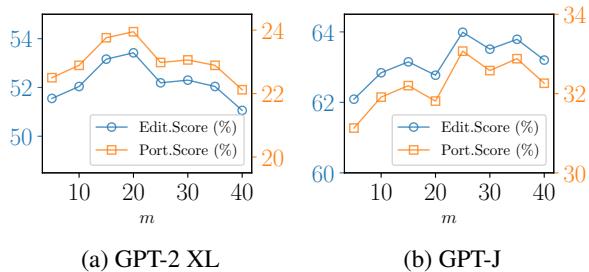
图 4 表明采样约 20-25 个邻居是最佳的。太少会丢失上下文;太多则信号会被噪声淹没。
MQUAKE 结果: 终极推理测试
最后,作者在 MQUAKE 上进行了测试,这是一个专为多跳推理设计的数据集 (例如,“[艺术家]相关的音乐流派起源于哪个国家,该国的国家元首是谁?”) 。
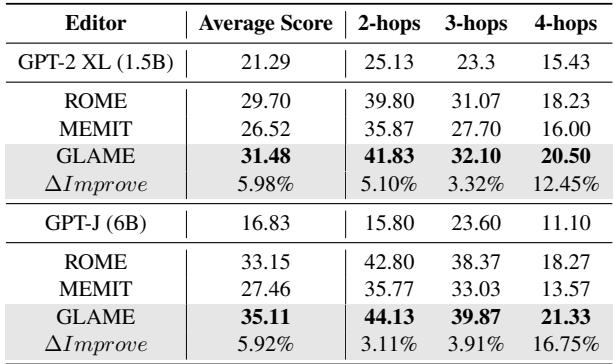
GLAME 在 2 跳、3 跳和 4 跳问题上均优于 ROME 和 MEMIT。在 4 跳问题上差距扩大,这表明对于高度复杂的推理链,结构化的知识注入明显优于简单的事实编辑。
结论与启示
“GLAME” 论文在使大语言模型更加可靠和可维护方面迈出了引人注目的一步。通过承认事实并非存在于真空中,研究人员已经超越了简单的“查找和替换”式编辑。
关键要点如下:
- 上下文很重要: 编辑单个事实需要更新关联知识网络以保持一致性。
- 图是强大的: 外部知识图谱提供了 LLM 难以自行推断的结构化上下文。
- 结构化注入: 简单地在图文本上进行训练效率低下。使用 GNN 对图进行编码并修改内部记忆向量是一种更有效的策略。
随着 LLM 越来越融入关键应用,在无需昂贵的重新训练的情况下准确更新其知识库的能力将变得至关重要。GLAME 证明,符号 AI (知识图谱) 和神经 AI (LLM) 之间的桥梁是通往更智能、适应性更强模型的充满希望的道路。