](https://deep-paper.org/en/paper/2402.15343/images/cover.png)
命名实体识别 (NER) 是自然语言处理中最基础的任务之一。无论是从财经新闻中提取股票代码,识别生物医学论文中的蛋白质,还是解析法律合同中的日期,NER 无处不在。
多年来,构建自定义 NER 模型的标准工作流程一直非常僵化: 采用一个预训练的基础模型 (如 BERT 或 RoBERTa) ,雇佣人工为你特定的实体标注数千个示例,然后微调模型。这个过程缓慢、昂贵且缺乏灵活性。
随着 GPT-4 等大型语言模型 (LLM) 的兴起,我们有了一个新的选择: 直接要求 LLM 找出实体。虽然这种方法效果不错,但在大规模运行时,计算量大且成本高昂。你肯定不想仅仅为了解析数百万张发票就耗尽 GPT-4 的额度。
这就引出了一篇引人入胜的论文: “NuNER: Entity Recognition Encoder Pre-training via LLM-Annotated Data” 。 研究人员提出了一种混合方法,结合了海量 LLM 的智能与小型编码器的高效。通过使用 LLM 标注一个巨大的通用数据集,他们创建了 NuNER , 这是一个紧凑的模型,其性能优于同类模型,并能与体积大 50 倍的模型相抗衡。
在本文中,我们将拆解 NuNER 的工作原理,为什么其“对比”训练方法是 NER 领域的游戏规则改变者,以及这对特定任务基础模型的未来意味着什么。
概念: 特定任务基础模型
要理解 NuNER,我们首先需要了解当前的迁移学习格局。
- 通用基础模型: 像 BERT 或 RoBERTa 这样的模型是在原始文本上训练的 (掩码语言建模) 。它们理解英语的句法和语义,但在你对其微调之前,它们不知道什么是“蛋白质”或“法律被告”。
- 特定领域模型: 像 BioBERT 这样的模型是在生物医学文本上预训练的。它们理解行话,但仍需要针对特定任务进行微调。
NuNER 引入了一个不同的类别: 特定任务基础模型 。 这是一个小型模型 (基于 RoBERTa) ,专门针对命名实体识别这一概念在所有领域进行了预训练。它的训练目标不仅仅是发现人名或地名,而是识别任何实体,这使得它只需很少的数据就能针对你的特定问题进行微调。
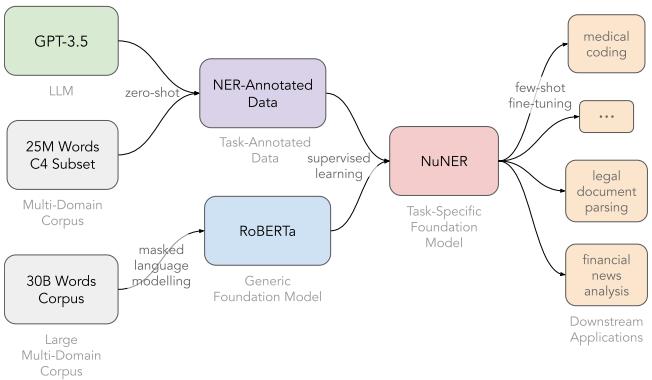
如上图 1 所示,该流程依赖于蒸馏。研究人员利用一个巨大的智能模型 (GPT-3.5) ,通过一个大型中间数据集来教导一个小型高效模型 (RoBERTa) 。
第一步: 使用“开放”标注创建数据集
训练 NER 模型的一大瓶颈是缺乏多样化的标注数据。人工数据集通常很小,且仅限于几种类型,如 PER (人名) 、ORG (组织) 和 LOC (地点) 。为了构建一个真正通用的 NER 模型,研究人员需要一个包含万物的数据集。
他们选择了 C4 语料库 (大规模网络爬虫数据) ,并使用 GPT-3.5 对其进行标注。然而,他们并没有只要求标准的实体。他们采用了一种无约束标注策略 。

正如你在提示词 (图 2) 中看到的,他们指示 LLM “标注尽可能多的实体、概念和想法”,并“发明新的实体类型”。这一点至关重要。通过不将 LLM 限制在预定义的标签列表中,他们捕获了丰富的语义景观。
结果是一个数据集,其中 GPT-3.5 充当了一个高精确度、低召回率的老师。它可能会遗漏一些实体,但它找到的实体通常是正确的,并带有描述性标签。

图 3 展示了一个标注示例。请注意,它将 “Steven Means” 识别为 NFL player (非常具体) ,将 “2018” 识别为 year (年份) 。
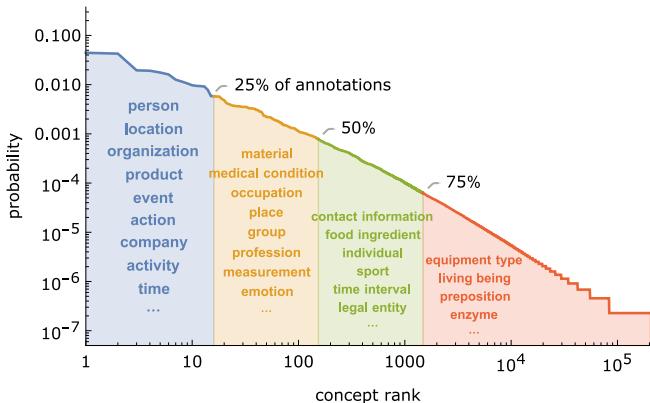
最终得到的数据集非常庞大且极具多样性。它包含 438 万个标注 , 覆盖 200,000 种独特的概念类型 。 这种分布是“长尾”的,意味着有少数非常常见的概念 (如“人”) ,以及成千上万个稀有、小众的概念。
第二步: 核心方法——对比学习
这篇论文的主要技术创新就在这里。如何训练一个包含 200,000 种不同实体类型的模型?
标准的 NER 模型在末端使用分类层 (softmax) ,输出维度等于标签的数量 (例如 5 个标签: B-PER, I-PER 等) 。你不可能拥有一个带有 200,000 个输出的分类层;这在计算上是不可能的,而且非常稀疏。
NuNER 通过将 NER 视为一个相似度问题而非分类问题来解决这个问题。他们使用了一种具有两个独立编码器的架构:
- 文本编码器 (NuNER) : 接收句子并为每个 token 生成一个向量。
- 概念编码器: 接收概念的名称 (例如 “NFL player”) 并生成单个向量。
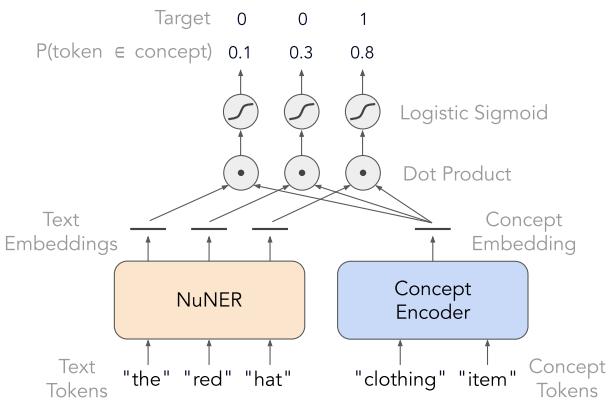
如图 5 所示,模型的训练目标是最大化 token 的文本嵌入 (如 “hat”) 与其标签的概念嵌入 (如 “clothing item”) 之间的相似度 (点积) 。
这种对比学习方法将模型与固定的标签集解耦。文本编码器学会将 token 投射到一个“语义空间”中,在这个空间里,实体根据其含义聚集在一起。
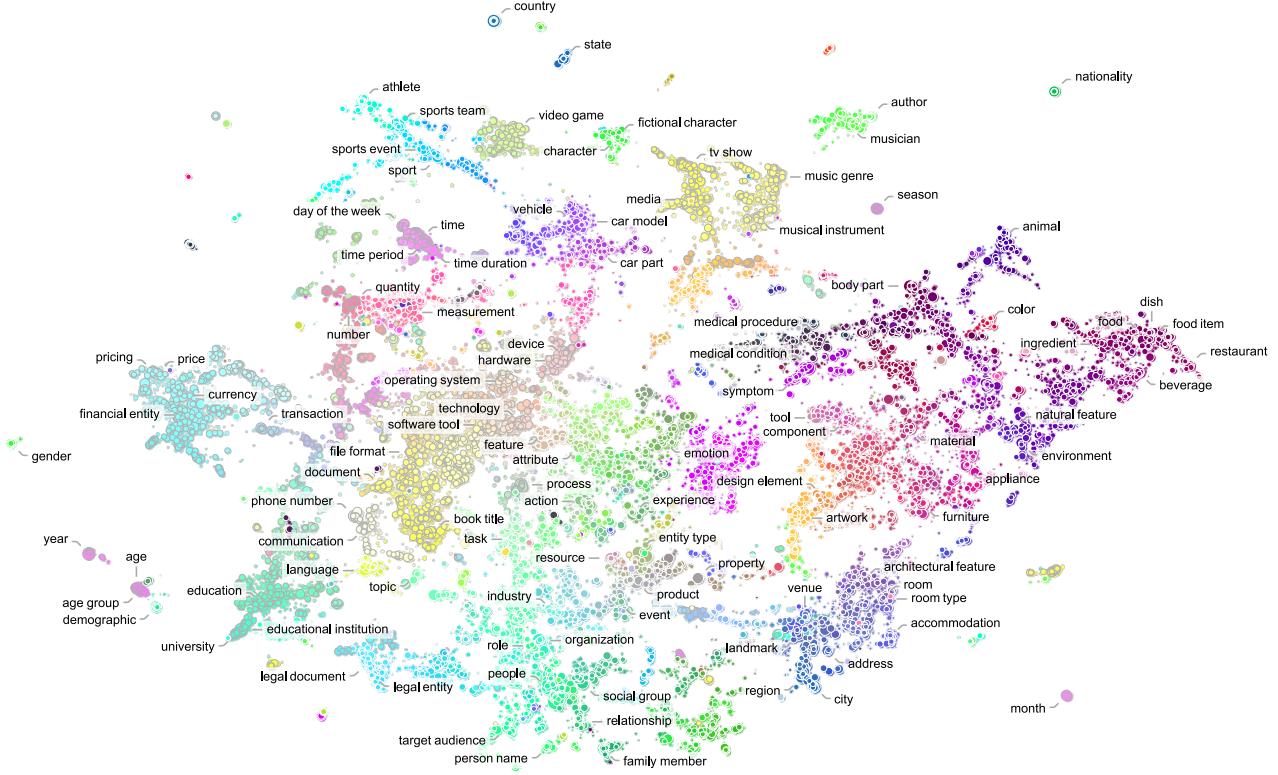
图 6 可视化了这个学习到的空间。请注意概念是如何自然分组的——医疗状况、食品和车辆各自形成簇。因为 NuNER 理解这些关系,所以针对特定任务 (如识别汽车零件) 对其进行微调变得容易得多。模型已经知道“化油器”和“活塞”在语义上接近“车辆零件”。
实验结果: 大卫对战歌利亚
研究人员在少样本迁移学习设置中评估了 NuNER。这模拟了现实世界的情景,即开发人员针对其特定问题只有少量示例 (10 到 100 个) 。
他们比较了三个模型:
- RoBERTa: 标准基线。
- RoBERTa w/ NER-BERT: 在较旧的大型 NER 数据集 (源自维基百科锚点) 上预训练的 RoBERTa 模型。
- NuNER: 提出的模型。
1. 卓越的少样本性能
结果按数据集 (BioNLP, MIT Movie, MIT Restaurant, OntoNotes) 和训练样本数量 (\(k\)) 进行了细分。
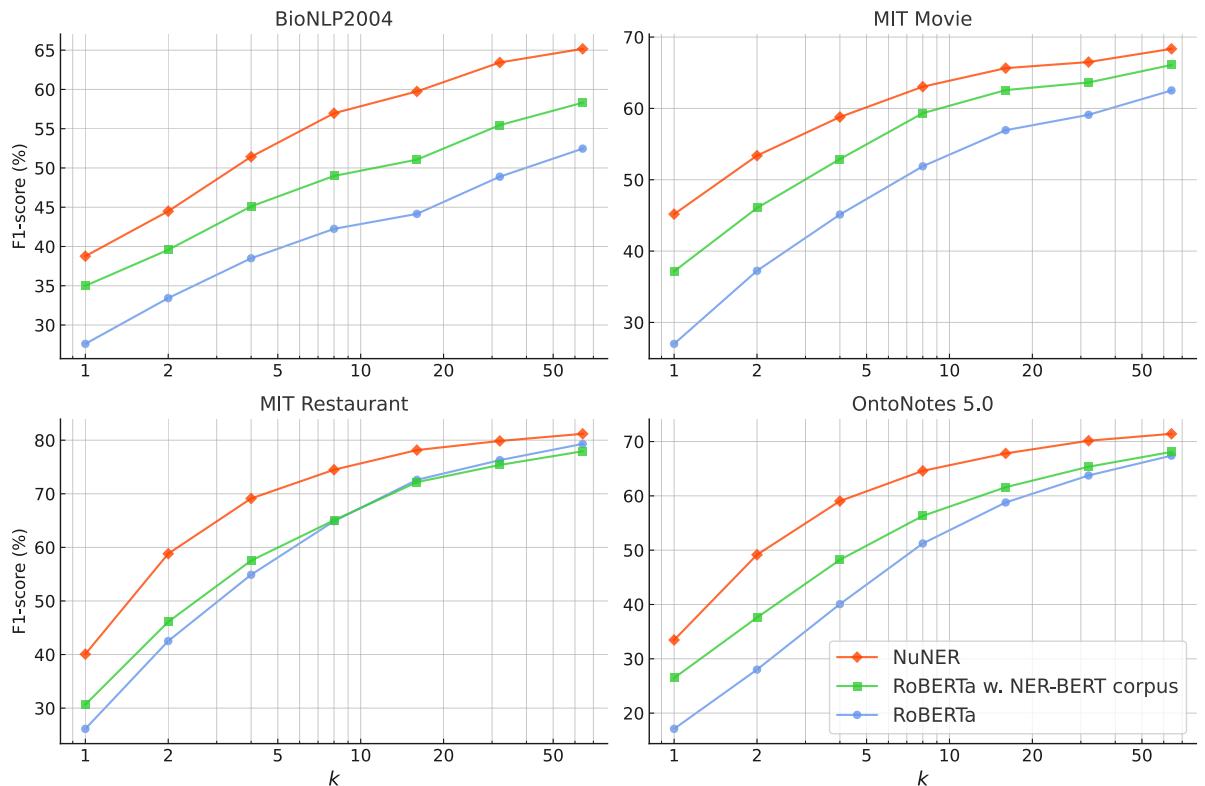
NuNER (图 13 中的橙色线) 在所有数据集上始终优于标准 RoBERTa 和之前的 SOTA 模型 NER-BERT。当数据稀缺 (\(k\) 很低) 时,差距尤为明显。这证实了在混乱、多样化、LLM 标注的数据上进行预训练,比干净但有限的维基百科数据能提供更坚实的基础。
2. 匹敌大型语言模型
也许最令人惊讶的结果是 NuNER 如何与帮助创建它的模型进行较量。研究人员将 NuNER (1.25 亿参数) 与 UniversalNER (70 亿参数) 以及通过提示词使用的 GPT-3.5 进行了比较。
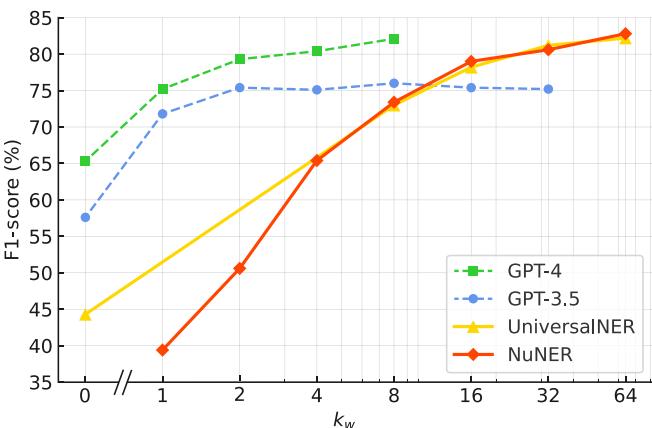
图 12 揭示了一个引人入胜的趋势:
- 零样本 (Zero-shot) : 像 GPT-4 这样的大型模型起步很高 (在 \(k=0\) 时 F1 分数很高) ,因为它们拥有丰富的通用知识。NuNER 起步为零,因为它需要微调。
- 少样本 (Few-shot) : 一旦你提供大约 8 到 16 个示例, NuNER 就会迎头赶上 。 它超越了 GPT-3.5,并达到了 UniversalNER 的性能水平。
这是一个巨大的效率胜利。NuNER 以比 UniversalNER 小 56 倍、比 GPT-3.5 小数千倍的模型实现了 LLM 级别的性能,使其适合在标准硬件上以低延迟部署。
为什么有效? (消融研究)
论文深入探讨了 NuNER 为何如此有效。是网络文本的原因?标签的数量?还是数据的大小?
关键不在于文本来源
研究人员比较了在 Wikipedia 与 C4 (网络文本) 上的训练效果,同时保持标注方法不变。
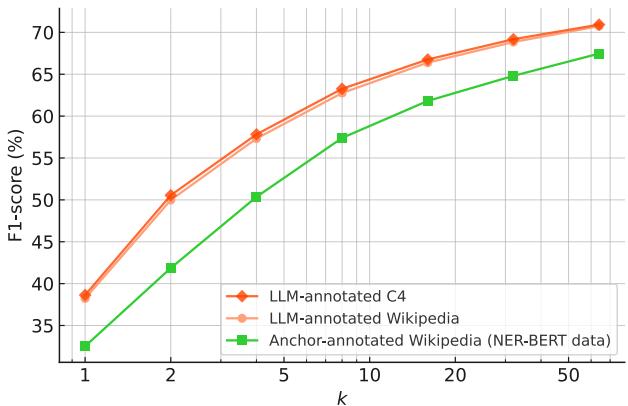
图 8 显示 C4 和 Wikipedia 的曲线高度重合。底层文本来源的重要性不如标注。
关键在于概念多样性
这是一个关键发现。研究人员人为地限制了预训练数据中的概念类型数量,以观察其对下游性能的影响。
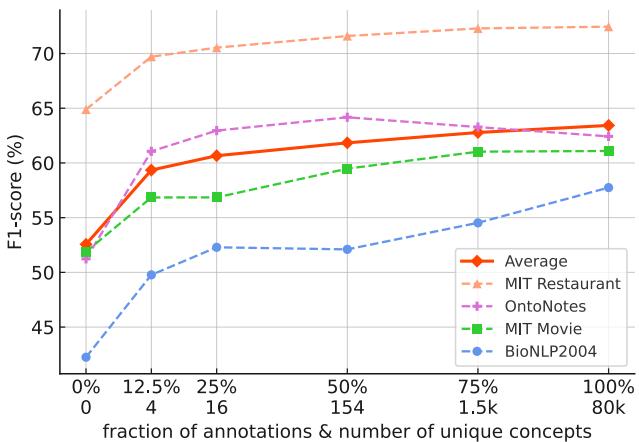
如图 9 所示,如果模型仅在少量实体类型集上进行训练 (图表的左侧) ,性能会显著下降。该模型的能力源于在预训练期间见识了成千上万种不同的概念——从“乐器”到“分子结构”。这种多样性迫使模型学习什么是“实体”的稳健、通用的表示。
规模至关重要 (数据和模型)
自然地,数据越多越好。图 10 (如下) 显示,随着数据集大小从 1k 增加到 1M 个示例,性能呈对数增长。
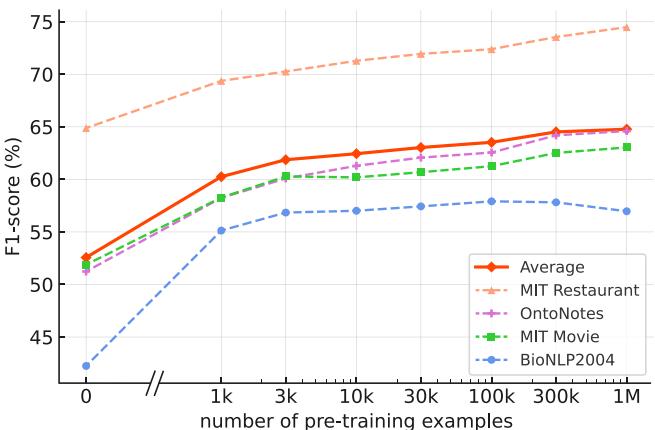
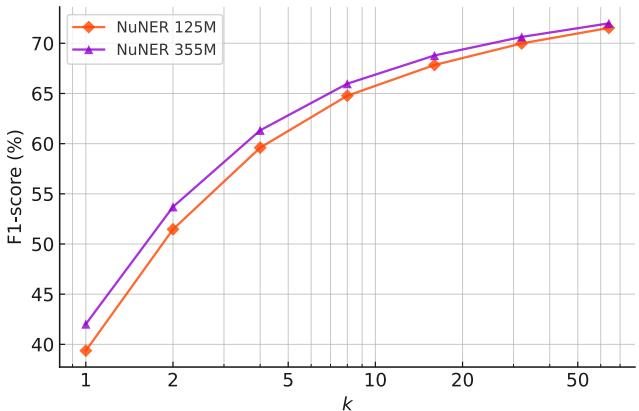
同样,将模型本身从 NuNER-base (125M) 扩展到 NuNER-large (355M) 也会产生持续的收益,如图 11 所示。
结论
NuNER 展示了 NLP 中一种强大的新范式: 通过标注进行蒸馏 。 我们不是用 LLM 来取代小型模型,而是可以用它们来赋能小型模型。
通过使用 GPT-3.5 生成海量、多样化、嘈杂的数据,并采用对比学习来处理种类繁多的概念,作者创建了一个表现远超其同量级选手的模型。
对于学生和从业者来说,结论很明确:
- 数据多样性 > 文本数量: 拥有 200,000 种实体类型比文本的来源更重要。
- 架构很重要: 从 Softmax 分类转换为对比学习,使模型能够从开放式的标签集中学习。
- 效率: 你并不总是需要一个 70B 参数的模型。一个经过正确预训练的专用 100M 参数模型,可以以极低的成本提供 SOTA 结果。
NuNER 为“特定任务基础模型”家族铺平了道路——不仅针对 NER,潜在地也适用于情感分析、摘要生成以及更多领域。