](https://deep-paper.org/en/paper/2402.16315/images/cover.png)
如果你试玩过最近的大型视觉语言模型 (LVLMs) ,比如 GPT-4V、LLaVA 或 InstructBLIP,你可能会印象深刻。你可以上传一张凌乱房间的照片并询问“桌子上有什么?”,或者上传一张梗图并问“这有什么好笑的?”,模型通常能给出极其准确的回答。这些模型已经架起了像素与文本之间的桥梁,实现了高层次的推理和描述。
然而,这里有个陷阱。虽然这些模型是出色的通才,但在专业领域却表现得惊人地差。如果你上传一张鸟的照片问“这是一只鸟吗?”,模型会说是。但如果你问“这是*天蓝色林莺 (Cerulean Warbler) 还是黑喉蓝林莺 (Black-throated Blue Warbler) *?”,模型往往会崩溃。
这种特定的挑战被称为细粒度视觉分类 (Fine-Grained Visual Categorization, FGVC) 。 最近一篇题为 “Finer: Investigating and Enhancing Fine-Grained Visual Concept Recognition in Large Vision Language Models” 的论文对这一现象进行了调查。研究人员揭示了最先进模型中存在的显著“模态鸿沟 (modality gap) ”,并提出了一种新颖的基准测试和训练策略来解决这个问题。
在这篇文章中,我们将剖析他们的研究,以理解为什么强大的 AI 模型会在细节上失败,以及我们要如何教会它们看得更清楚。
能力的假象
要理解这个问题,我们首先需要看看这些模型通常是如何被评估的。大多数基准测试测试的是通用理解能力: 描述场景、读取图像中的文本 (OCR) 或回答逻辑问题。
然而,科学和现实世界的应用往往需要精确的识别。生物学家看到的不仅仅是“植物”,而是“*龟背竹 (Monstera deliciosa) *”。汽车爱好者看到的不仅仅是“轿车”,而是“2018 款现代圣达菲 (Hyundai Santa Fe) ”。
研究人员在涉及鸟类、狗、汽车和飞机的六个细粒度数据集上测试了五个主要模型 (包括 LLaVA、InstructBLIP 和 GPT-4V) 。结果非常鲜明。
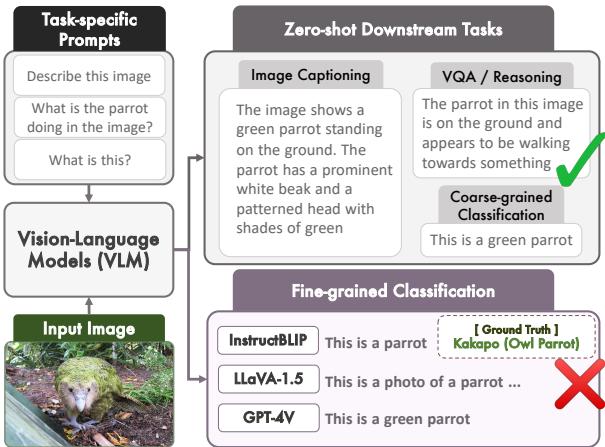
如上图 1 所示,像 LLaVA 这样的模型非常擅长生成一段描述鹦鹉的文字。但当被要求执行分类任务——识别具体的品种或物种时——它们经常产生幻觉或退回到通用的回答。
性能断崖
该论文使用一种称为“精确匹配” (Exact Match, EM) 的指标来量化这种失败,该指标检查模型是否能生成正确的具体类别名称。研究人员将标签分为三个层级:
- 上位 (Superordinate) : 高级类别 (例如,“鸟”) 。
- 粗粒度 (Coarse) : 中级类别 (例如,“猫头鹰”) 。
- 细粒度 (Fine) : 具体类别 (例如,“大角以此猫头鹰”) 。
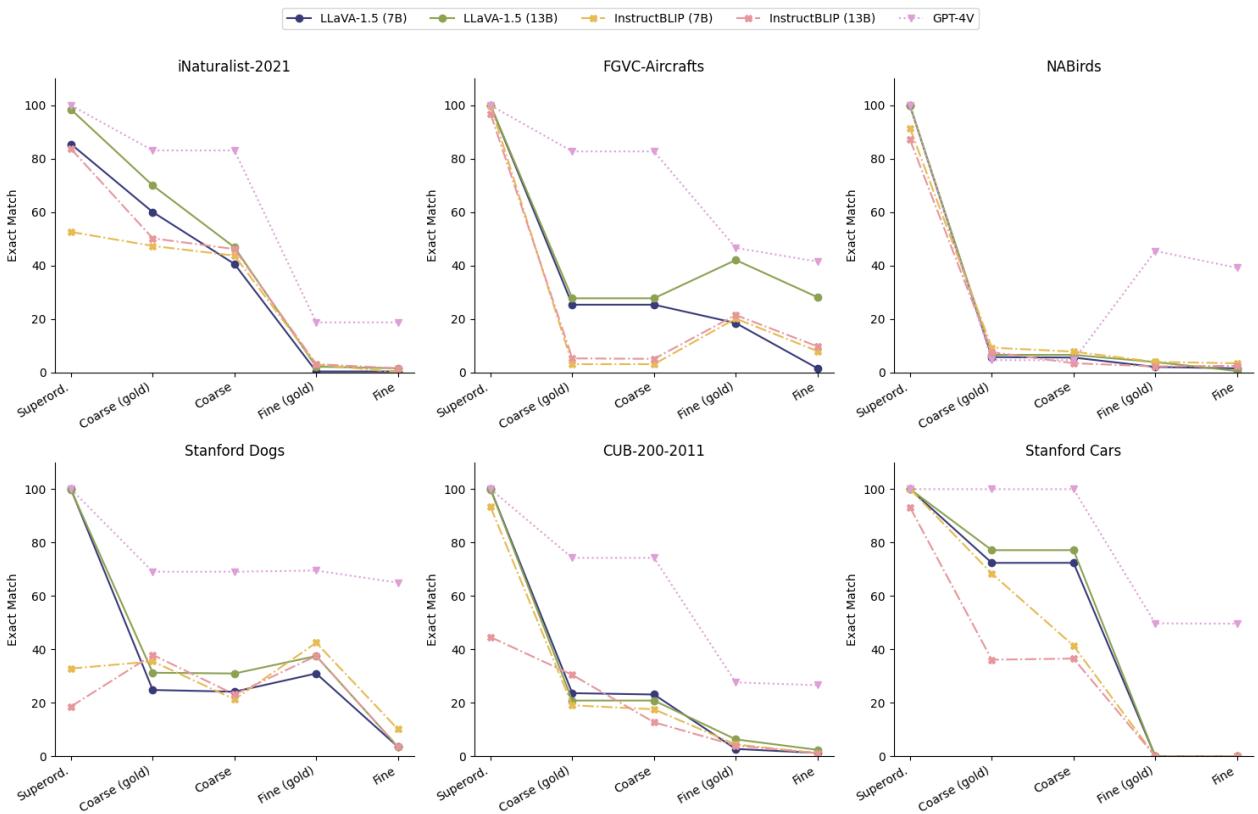
图 2 展示了一个戏剧性的“性能断崖”。看第一张图 (iNaturalist-2021) 上的蓝线 (LLaVA-1.5 7B) 。该模型在上位类别上的准确率接近 100%。在粗粒度类别上,它下降到 40% 左右。但对于细粒度类别呢?它骤降至接近 0% 。
即使是目前被认为是最先进的 GPT-4V (紫色虚线) ,随着任务从粗粒度识别转向细粒度识别,准确率也出现了显著下降。
诊断“模态鸿沟”
为什么会发生这种情况?是因为这些架构内部的大型语言模型 (LLM) 不知道“天蓝色林莺”是什么吗?
为了找出答案,研究人员进行了一项引人入胜的“知识探测”实验。他们通过两种不同的方式测试模型:
- 仅图像 (Image-only) : 展示照片给模型看,并询问物种。
- 仅文本 (Text-only) : 为模型提供视觉属性的文本列表 (例如,“蓝色上半身”、“白色腹部”、“黑色项圈”) ,并询问物种。
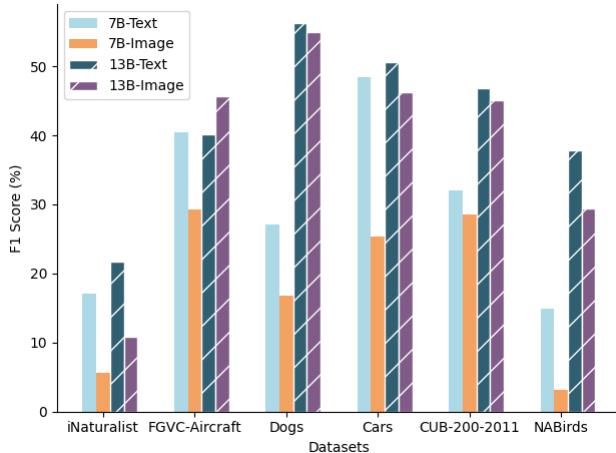
图 4 中的结果发人深省。当 LLaVA-1.5 (7B) 获得文本描述 (浅蓝色条) 时,其准确率显著高于其观看图像 (橙色条) 时。
这证实了一个关键假设: 模型拥有知识。 LLM 组件已经阅读了整个互联网;它知道鸟类和汽车的分类学。失败在于模态鸿沟 。 视觉编码器 (“眼睛”) 未能提取出触发 LLM (“大脑”) 中正确知识所需的具体细节。
翻译中的信息丢失
大多数 LVLM 使用视觉编码器 (如 CLIP) 将图像转换为数字 (嵌入) ,然后通过一个“投影层”将这些数字“翻译”成 LLM 能理解的语言空间。
研究人员发现,这个投影过程是“有损的”。
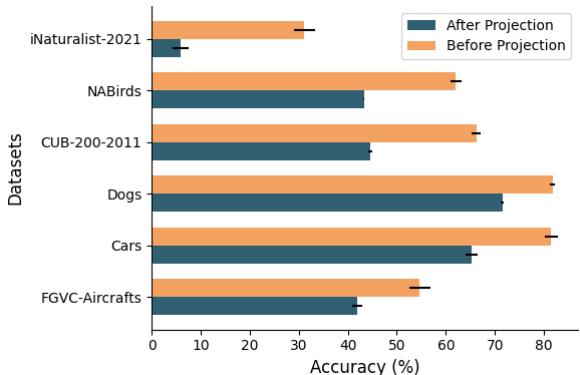
如图 5 所示,研究人员进行了线性探测——在数据上训练一个简单的分类器——分别在投影层之前和之后进行。橙色条代表来自编码器的原始视觉数据,而深青色条代表投影给 LLM 后的数据。
在每个数据集中,投影后的准确率都下降了。从“视觉语言”到“文本语言”的转换抹平了区分所需的锐利、细粒度的细节。这就好比模型在试图阅读小字之前戴上了一副雾蒙蒙的眼镜。
解决方案: FINER 和 ATTRSEEK
发现问题只是战斗的一半。研究人员提出了一个以“如果模型略过了细节,我们必须强迫它仔细观察”为核心思想的解决方案。
他们引入了 FINER (一个新的基准和训练混合数据集) 和 ATTRSEEK (一种提示策略) 。
1. FINER 基准
要训练模型注意细节,你需要强调细节的数据。研究人员通过聚合六个现有的细粒度数据集 (如用于鸟类的 CUB-200 和斯坦福汽车数据集) ,并利用从维基百科提取的丰富文本属性对其进行了增强,从而构建了 FINER 数据集。
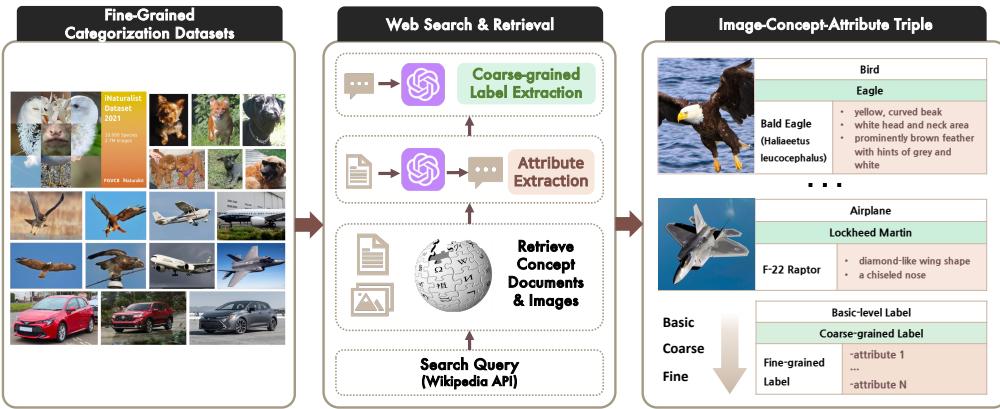
如图 6 所示,他们不仅仅抓取标签;他们使用 GPT-4V 提取“概念指示性属性”。对于一只秃鹰 (Bald Eagle) ,数据集包含了关于其黄色喙、白色头部和深褐色身体的结构化数据。这建立了一座桥梁: 它不仅将视觉概念与名称 (标签) 联系起来,还与其描述 (属性) 联系起来。
2. ATTRSEEK 流程
有了这些属性丰富的数据,研究人员开发了一种新的推理方法,称为 ATTRSEEK (属性搜寻) 。
标准提示会问: “这是什么鸟?” ATTRSEEK 会问: “你看到了什么视觉属性?” \(\rightarrow\) “基于这些属性,这是什么鸟?”
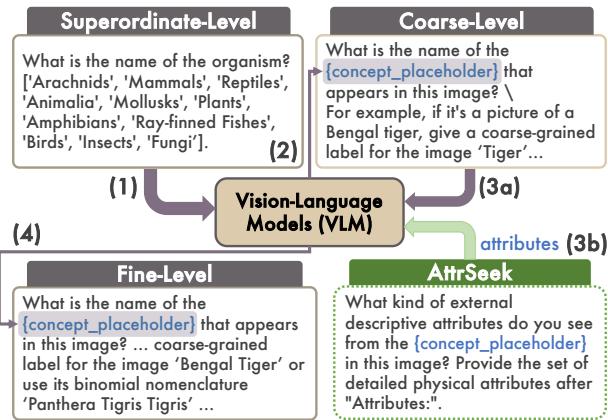
如图 3 所示,这个过程强迫模型在得出结论之前先用语言表达视觉证据。这模仿了人类专家的工作方式: 首先观察翼斑和喙的形状,然后查阅脑海中的图鉴。
它有效吗?
结果表明,显式地对属性建模有助于弥合模态鸿沟。
定性分析
首先,让我们看看模型实际上“看到”了什么。研究人员比较了标准模型生成的属性 (仅图像) 与 FINER 数据集中定义的实际独特属性 (仅文本参考) 。
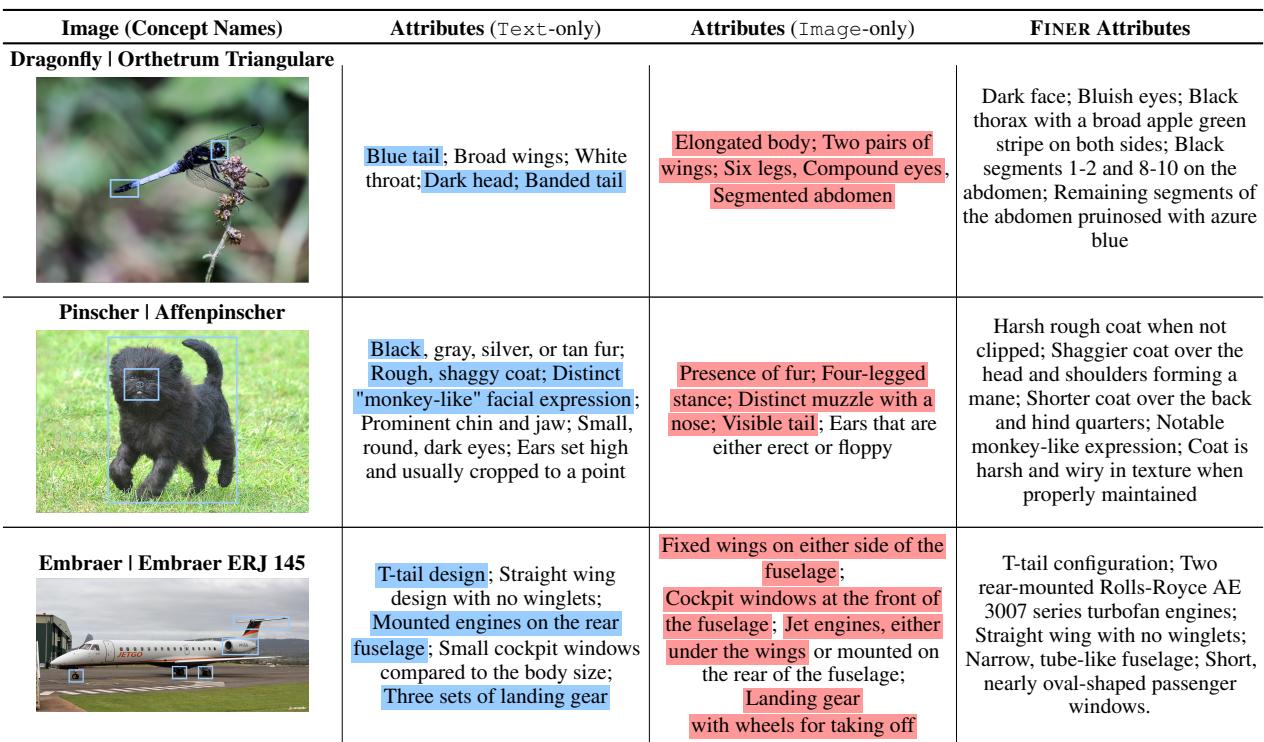
在表 3 (如上所示) 中,看看蜻蜓 (Orthetrum Triangulare) 的例子。
- 仅图像 (标准 VLM) : 看到“细长的身体”、“两对翅膀”、“复眼”。这些是正确的,但它们很通用。它们描述了所有蜻蜓。
- FINER 属性: 描述了“黑色胸部两侧有宽阔的苹果绿条纹”、“蓝色尾巴”。这些是具体的。
当通过 ATTRSEEK 强迫模型寻找这些特定属性时,它的幻觉减少了,并且将其推理建立在实际的像素数据上。
定量提升
当 LLaVA-1.5 在 FINER 训练混合数据集上进行微调 (教它寻找属性) 后,细粒度任务上的零样本性能显著提高。

表 4 突出了这些收益。“Direct Prediction” (直接预测) 是训练模型的标准方式 (图像 \(\to\) 标签) 。“FINER”是新方法 (图像 \(\to\) 属性 \(\to\) 标签) 。
- 在 Stanford Dogs 上,性能从 22.9% 跃升至 36.3% 。
- 在 Stanford Cars 上,从 24.6% 上升至 30.0% 。
通过教模型阐述为什么它认为图像属于特定类别,研究人员有效地减少了之前发现的信息丢失。
结论与关键要点
论文 “Finer” 揭示了现代 AI 中一个关键的盲点。虽然我们对视觉语言模型的对话能力感到眼花缭乱,但它们往往缺乏处理专业任务所需的“视觉敏锐度”。
以下是给学生和从业者的关键要点:
- 模态鸿沟是真实的: 仅仅因为 LLM 知道一个事实,并不意味着视觉编码器能触发那个事实。文本知识和视觉表征之间存在脱节。
- 投影是有损的: 将图像转换为文本嵌入的架构层简化了图像,往往丢弃了专家识别所需的细粒度纹理和图案信息。
- 提示很重要: 像 ATTRSEEK 这样的技术证明,我们可以通过简单地改变过程而不改变模型架构来提高性能。强迫模型在回答之前“展示其推导过程” (描述属性) 起到了纠错的作用。
- 数据质量: FINER 基准表明,为了获得更高水平的 AI 性能,我们需要超越简单的
(图像, 标签)对的数据。我们需要(图像, 属性, 标签)三元组来教会模型现实世界的细微差别。
随着我们迈向更自主的 AI 智能体,细粒度理解将至关重要。机器人药剂师需要区分两种外观相似的药丸;农业无人机需要区分作物和杂草。像 Finer 这样的研究为我们实现这一目标提供了路线图。