](https://deep-paper.org/en/paper/2402.18191/images/cover.png)
引言: 质量与数量的困境
在当前大语言模型 (LLM) 的发展格局中,普遍存在一种假设,即“越多越好”。我们通常认为,要让模型更聪明,就必须给它投喂更多的 token、更多的文档和更多的指令。这在预训练阶段通常是正确的,因为模型在这一阶段学习语言的统计结构。然而,在指令微调 (Instruction Tuning, IT) 阶段——即教导模型充当有用助手的最后润色阶段,规则发生了显著变化。
在指令微调期间,数据的质量往往比纯粹的数量重要得多。最近的研究 (例如 LIMA 论文) 表明,仅用 1,000 个精心挑选的样本微调出的模型,其表现可以优于用 50,000 个嘈杂样本训练的模型。但瓶颈在于: 创建这 1,000 个“黄金”样本通常需要昂贵的人工标注。
理想情况下,我们希望能将其自动化。我们希望能获取一个巨大的、嘈杂的数据集 (如 Alpaca-52k) ,并通过算法将其过滤为最好的 2%。以前的尝试 (如 Alpagasus) 试图使用 GPT-3.5 作为裁判来做到这一点。虽然效率很高,但这种方法引入了“机器偏差”——LLM 倾向于偏爱冗长的答案或听起来像它们自己的答案,而不是人类专家实际偏好的答案。
聚类与排序 (Clustering and Ranking, CaR) 方法应运而生。在一篇引人入胜的新论文中,研究人员提出了一种工业界友好的方法,通过与人类专家而非仅与其他 AI 模型对齐来选择高质量的指令数据。通过结合质量评分机制和保持多样性的聚类算法,他们成功地仅使用了原始 Alpaca 数据集的不到 2% 进行训练,得到了一个显著优于原始模型的模型——AlpaCaR 。
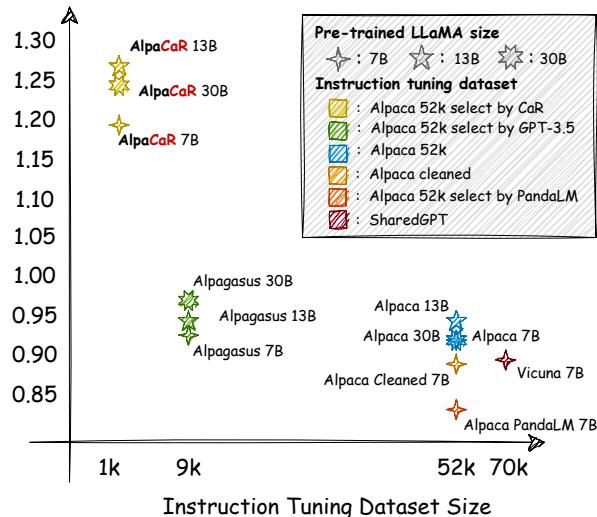
如上图 1 所示,尽管使用的训练数据极少,AlpaCaR 在多个基准测试 (Vicuna, Self-Instruct 等) 中仍取得了卓越的性能。在这篇文章中,我们将剖析 CaR 的工作原理,为什么多样性是小数据训练的秘密武器,以及如何用一小部分的计算预算实现最先进的结果。
背景: 指令微调全景
在深入研究该方法之前,让我们先建立背景。指令微调是将预训练的基础模型 (如 LLaMA) 在 (指令, 输出) 对上进行微调的过程。
Alpaca 数据集的发布彻底改变了社区,它使用了“Self-Instruct” (自指令) 方法。本质上,他们要求一个强大的模型 (GPT-3/text-davinci-003) 生成 52,000 个指令-响应对。这是一个突破,因为它既便宜又快。然而,机器生成的数据是嘈杂的。它包含错误、幻觉和重复的任务。
现有过滤方法的问题
自然地,研究人员开始尝试过滤这些数据。最常见的方法是 LLM-as-a-Judge (LLM作为裁判) 。 简单来说,就是让一个强大的模型 (如 GPT-4) 对训练对的质量进行评分,并保留排名靠前的部分。
然而,CaR 论文的作者指出了这种标准方法的两个关键缺陷:
- 系统性偏差 (Systematic Bias) : GPT 模型表现出“自我增强偏差”。它们更喜欢听起来像自己的输出。GPT-4 可能会因为风格相似而给 GPT-3 生成的回复打高分,即使其实际内容平平。此外,它们还受到“冗长偏差”的影响,倾向于更长的答案,即使那是废话。
- 多样性缺失 (Loss of Diversity) : 如果你仅仅根据质量分数对 52,000 条指令进行排名并选取前 1,000 条,你可能会得到 1,000 个创意写作提示,而没有数学题。如果高质量数据不能覆盖 LLM 需要执行的任务广度,那么它就是无用的。
CaR 框架的设计初衷正是为了解决这两个问题: 获得关于质量的专家意见,并确保数据集保持多样性。
核心方法: 聚类与排序 (CaR)
CaR 方法是一个优雅的两步流程。其目标是将一个大型、嘈杂的数据集 (如 Alpaca-52k) 过滤为一个用于训练最终模型的“高质量子数据集”。
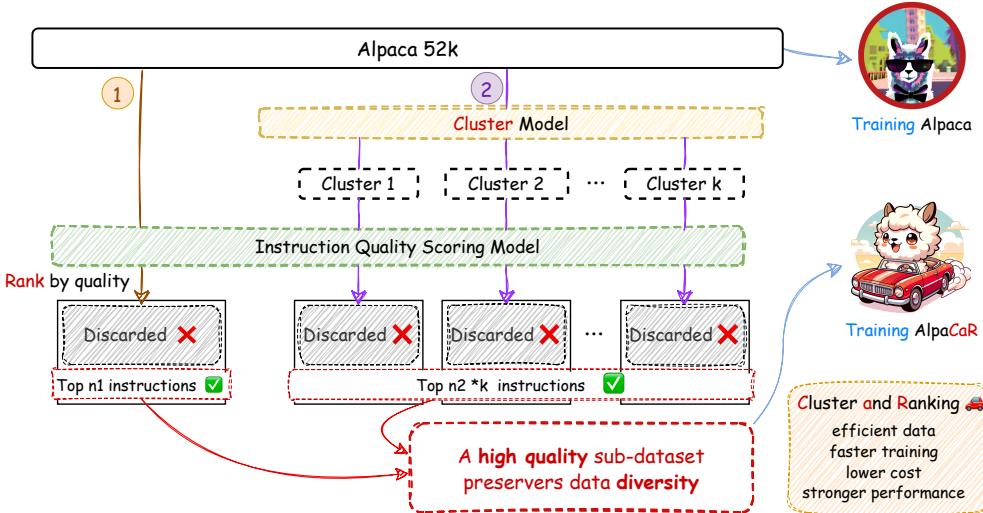
如图 2 所示,该过程如下:
- 排序 (质量评估) : 一个专门的模型对数据集中的每一对指令进行评分。
- 聚类 (保持多样性) : 根据语义含义将指令分组为若干个簇。
- 选择: 系统选择绝对最好的指令 (\(n_1\)) 以及从每个簇中选出的最好指令 (\(n_2\)) 。
- 训练: 这些被选中的指令构成了 AlpaCaR 的新数据集。
让我们详细分解这些组件。
第一步: 专家对齐的质量评估 (IQE)
第一个挑战是弄清楚哪些指令是“好的”。研究人员没有依赖通用的 GPT-4 提示词,而是引入了一个新概念: 指令对质量评估 (Instruction Pair Quality Estimation, IQE) 。
他们训练了一个专门的轻量级模型 (5.5亿参数) ,称为指令质量评分 (IQS) 模型。这里的关键区别在于训练数据。他们使用了一个由语言专家人工修订 Alpaca 指令的数据集,以提高流畅性、准确性和连贯性。
这使得模型能够学习到一个特定的边界: 与其接受原始的 GPT 生成内容,人类专家更偏好什么?
IQS 架构
为了构建 IQS 模型,研究人员采用了在机器翻译评估中广泛使用的 Comet 框架。他们尝试了两种架构。
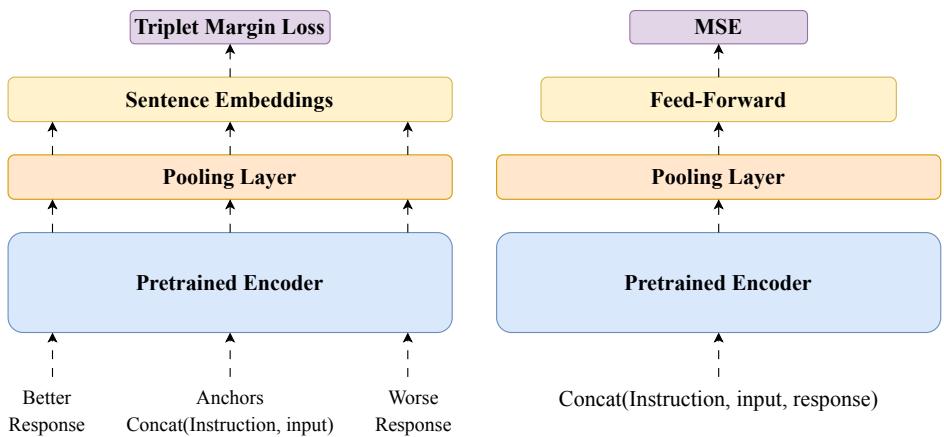
- Comet-Instruct (图 10 左侧) : 这使用了三元组损失 (triplet loss) 。它观察一条指令,并将“较好”的回复与“较差”的回复进行比较,试图最小化与好回复的距离。虽然有效 (准确率 72.44%) ,但这并不是他们能做到的最好结果。
- IQS 模型 (图 10 右侧) : 这种更简单的架构证明更有效。它获取指令和回复,将它们拼接起来,并通过一个预训练的编码器 (XLM-RoBERTa) 。然后,一个回归头 (regression head) 预测直接的质量分数。
这个小型的 IQS 模型在与专家偏好的一致性上达到了 84.25% 的准确率,显著优于 GPT-4 (63.19%) 。这是一个至关重要的发现: 一个在人类专家数据上训练的小型专用模型,比一个大型的通用 LLM 更能判断质量。
第二步: 通过聚类保持多样性
一旦每条指令都有了质量分数,我们可以直接选取前 1,000 条。但如前所述,这会扼杀多样性。为了解决这个问题,研究人员使用了 \(k\)-均值聚类 (\(k\)-Means Clustering) 。
他们使用句子转换器 (sentence-transformer) 将所有 52,000 条指令嵌入到向量空间中。语义相似的指令 (例如 Python 编程问题) 会在空间中聚在一起,而不同的任务 (例如写诗) 则形成自己的簇。
他们根据数据集大小使用启发式方法确定了最佳簇数 (\(k\)) ,结果是 Alpaca 数据集被分为了 161 个不同的簇。
第三步: 混合选择策略
这就是“聚类与排序”名称的由来。最终的选择逻辑结合了全局质量和局部的多样性。
算法分两轮筛选数据:
- 全局前 \(n_1\): 从整个数据集中选择得分最高的 \(n_1\) 条指令。这确保了无论主题如何,绝对最高质量的数据都被包含在内。
- 每簇前 \(n_2\): 从 \(k\) 个簇中的每一个簇里,选择得分最高的 \(n_2\) 条指令。这确保了每一种单一的主题/任务类型都在最终数据集中有所代表。
最终的数据集大小大约是 \(n_1 + (k \times n_2)\)。在他们的主要实验中,他们发现一个非常小的数据集就足够了: 总共大约 1,000 条指令。
实验与结果
研究人员将他们的 AlpaCaR 模型 (在子集上训练) 与几个基线模型进行了比较:
- Alpaca: 在完整的 52k 数据集上训练。
- Alpaca-Cleaned: 社区手动清洗数据集的成果。
- Alpagasus: 之前的最先进技术,使用 GPT-3.5 过滤。
- Vicuna: 在 ChatGPT 对话数据上训练的强大基线。
主要性能比较
结果使用“胜率分数” (Winning Score, WS) 相对于参考回复进行评估,由 PandaLM 和 GPT-4 进行评判。
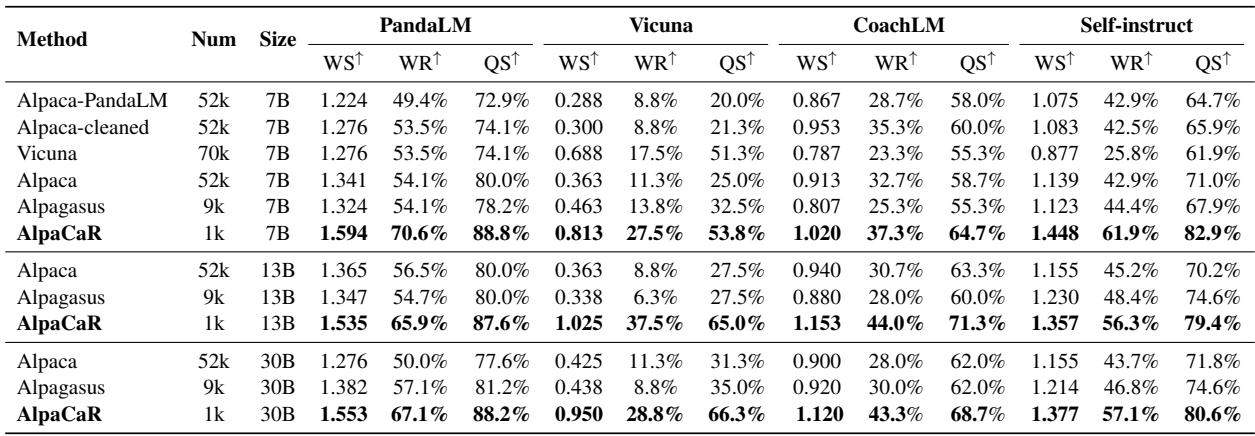
表 2 展示了决定性的结果。在 7B 参数规模下:
- Alpaca (52k 数据): WS 为 1.341。
- Alpagasus (9k 数据): WS 为 1.324。
- AlpaCaR (1k 数据): WS 为 1.594 。
AlpaCaR 仅使用了约 2% 的数据 (1k 样本) ,却大幅超越了在完整数据集上训练的模型。它还在 13B 和 30B 参数模型上有效地扩展,始终击败基线。这证实了这样一个假设: 少量专家对齐的数据比大量嘈杂数据有效得多。
为什么质量很重要 (消融实验)
研究人员测试了如果通过包含排名较低的指令来增加数据集大小会发生什么。
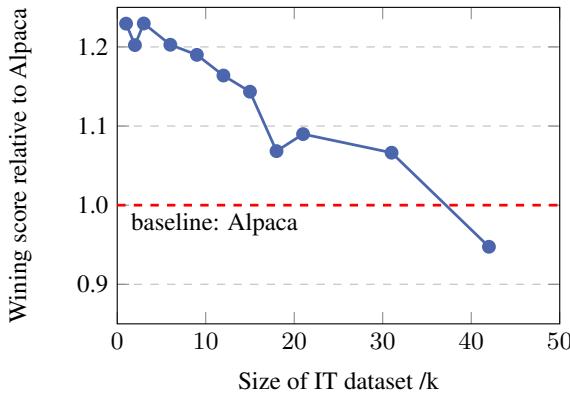
图 4 展示了一个反直觉的现象。随着他们添加更多数据 (x 轴从 1k 移动到 50k) ,模型的性能 (y 轴) 实际上下降了。曲线在 1k 处开始很高,然后稳步下降到基线以下。这强有力地证明了 Alpaca 数据集的“长尾”不仅无用——而且对模型性能有积极的害处。
为什么多样性很重要 (消融实验)
仅仅挑选高分就够了吗?研究人员测试了改变参数 \(n_2\) (从每个簇中选取的样本数) 。
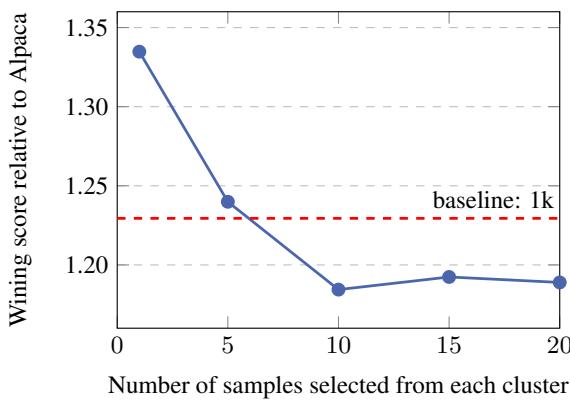
图 5 显示,从每个簇中仅选取一个高质量样本 (\(n_2=1\)) 提供了最佳的性能提升。增加每簇的样本数 (\(n_2=5, 10, 20\)) 导致性能下降。这表明 LLM 是非常高效的学习者;它们只需要一个或两个特定任务类型 (如“写俳句”) 的强力示例就能学会该技能。给它们 20 个相同任务的变体通过会产生边际收益递减和潜在的过拟合。
下表进一步巩固了多样性的重要性:
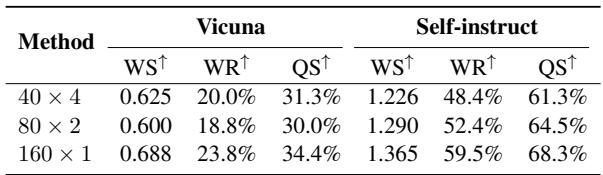
表 3 比较了选择策略。策略 \(160 \times 1\) (从 160 个不同的簇中各选 1 个例子) 明显优于 \(40 \times 4\) (仅从 40 个簇中各选 4 个例子) 。广泛的任务覆盖范围至关重要。
成本效益
CaR 最令人信服的论点之一是成本。训练 LLM 很昂贵,将数据集大小减少 98% 对预算有巨大影响。
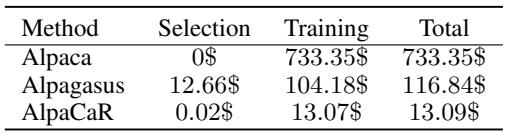
表 6 分解了 30B 模型规模的成本。
- Alpaca: 训练费用 733 美元。
- Alpagasus: 116 美元 (包括用于过滤的 API 成本) 。
- AlpaCaR: 13.09 美元 。
CaR 方法将资金支出降低到现有过滤方法的仅 11.2% , 并且只是全量训练的一小部分。对于学生或小型初创公司来说,这使得训练高性能的 30B 模型变得真正触手可及。
分析: 人类与 GPT 评估
LLM 的评估众所周知地困难。为了确保他们的结果不仅仅是某个特定裁判的人为产物,研究人员使用了多种评估方法。
GPT-4 评估
他们使用 GPT-4 进行了正面对决比较。
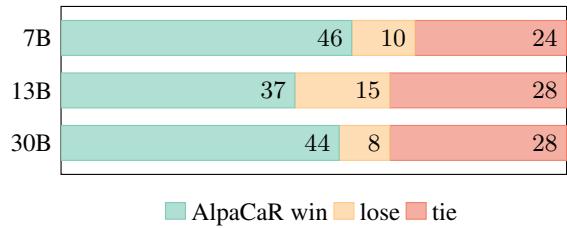
图 7 显示,在 Vicuna 基准测试中,跨越 7B、13B 和 30B 尺寸,AlpaCaR (青色) 战胜基线 Alpaca 模型的次数明显多于失败的次数。
人类专家评估
也许最重要的是,他们聘请了人类语言专家来盲审输出结果。
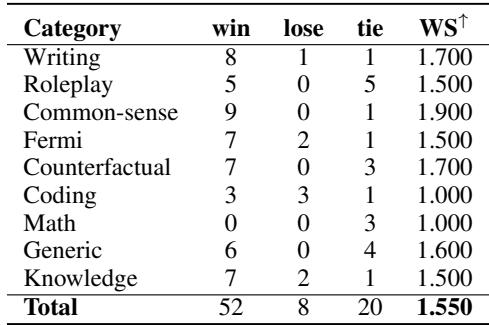
表 4 显示了对 30B 模型的人类评估。AlpaCaR 获胜 52 次,而 Alpaca 仅获胜 8 次。这是一场压倒性的胜利,特别是在“常识”、“知识”和“写作”等类别中。
案例研究: 推理 vs. 幻觉
对输出的定性观察揭示了为什么 AlpaCaR 得分更高。

在表 7 所示的数学示例中,模型被要求求一个函数的值。
- Alpaca: 简单地猜测“f(2) 的值是 3。” (错误且没有过程) 。
- AlpaCaR: 尝试逐步推导。虽然专家将其标记为“平局” (可能是由于微小的计算错误或严格的评分) ,但 AlpaCaR 展示了 思维链 (Chain of Thought, CoT) 推理。它理解了如何解决问题,而 Alpaca 将其视为简单的检索任务。这种行为表明,IQS 模型成功地优先考虑了包含逻辑推理步骤的指令,并将这种能力转移到了最终模型中。
泛化性: 这适用于 LLaMA 2 和 3 吗?
AI 研究中的一个常见批评是,针对旧模型 (如 LLaMA 1) 开发的方法可能不适用于更新、更强的基础模型。研究人员通过在 LLaMA 2 和 LLaMA 3 上测试 CaR 来解决这个问题。
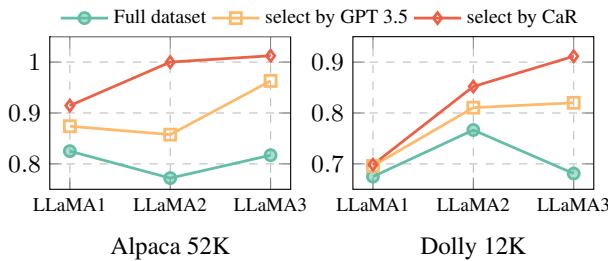
图 8 (左) 显示了在 LLaMA 1、2 和 3 上的结果。红线 (CaR) 始终位于青线 (完整数据集) 之上。这证明了数据选择是一个一致的范式。 即使基础模型变得更聪明 (在数万亿更多 token 上训练) ,它们仍然受益于精心策划、高质量、多样化的微调数据集,而不是海量的嘈杂数据集。
有趣的是,他们发现 LLaMA 3 对数据质量可能更敏感,与精心策划的 CaR 子集相比,在完整、嘈杂的数据集上训练时表现出更剧烈的性能下降。
结论与启示
“聚类与排序” (CaR) 论文为 LLM 社区提供了一个引人注目的叙事转变。我们正在从“大数据”时代迈向“智能数据”时代。
关键要点:
- 专家胜过算法: 一个在专家数据上训练的小型评分模型,在判断质量方面比像 GPT-4 这样的大型通用模型更有效。
- 多样性不可商量: 你不能只挑选“最好”的数据;你必须挑选“每种类型中最好”的数据。聚类为此提供了一种无监督、可扩展的方法。
- 效率: 你可以使用约 2% 的标准训练数据达到最先进水平 (SOTA) 的性能,将成本降低近 90%。
对于学生和研究人员来说,这是令人振奋的。这意味着你不需要 H100 GPU 集群来训练具有竞争力的模型。你需要的是一个聪明的选择算法和对数据质量的关注。随着模型继续扩展,在数据大海中通过算法识别“金针”的能力可能会成为 AI 工程领域最有价值的技能。