](https://deep-paper.org/en/paper/2402.19467/images/cover.png)
想象一下,你正在看美剧《老友记》 (Friends) 中的一幕。钱德勒 (Chandler) 说了一句讽刺的话,莫妮卡 (Monica) 翻了个白眼。你立刻就明白莫妮卡生气了。但你是如何得出这个结论的?你结合了视觉线索 (翻白眼) 、听觉信息 (钱德勒的语气) 以及你对社交动态的理解。
现在,想象一下问一个人工智能模型: “莫妮卡感觉如何?”
现代视频语言模型可能会正确回答: “她很生气。”但如果你问为什么,模型通常无法告诉你。它是一个“黑盒”——它摄入了像素和文本,并基于统计相关性吐出了答案,而不是通过可追踪的逻辑链条。
这种可解释性的缺乏是人工智能领域的一大障碍。如果我们想要信任机器去理解世界,我们需要它们展示其思考过程。
在这篇文章中,我们将深入探讨一篇引人入胜的论文,题为 “TV-TREES: Multimodal Entailment Trees for Neuro-Symbolic Video Reasoning” (TV-TREES: 用于神经符号视频推理的多模态蕴涵树) 。研究人员提出了一种新颖的系统,它不仅能回答关于视频的问题,还能构建一个结合对话和视觉帧的证据逻辑树,以证明其答案。
问题所在: 不可解释的多模态模型
我们要生活在一个视频为先的世界里。从 YouTube 教程到监控录像,视频数据无处不在。为了处理这些数据,我们使用 VideoQA (视频问答) 模型。这些通常是在海量数据集上训练的大型 Transformer 模型。
虽然这些模型令人印象深刻,但它们有两个主要缺陷:
- 它们是不透明的: 它们无法解释得出答案的推理步骤。
- 它们是懒惰的: 研究表明,这些模型通常严重依赖一种模态 (通常是文本/对话) 而忽略视频,或者反之亦然,而不是真正地在两者之间进行推理。
这篇论文的作者认为,要解决这个问题,我们需要从纯粹的“黑盒”神经网络转向 神经符号 (Neuro-Symbolic) 系统。这些系统结合了神经网络 (如大型语言模型) 的能力和符号逻辑的结构。
TV-TREES 登场
提出的解决方案是 TV-TREES (Transparent Video-Text REasoning with Entailment System,即透明视频文本推理蕴涵系统) 。
核心思想是 蕴涵树 (Entailment Tree) 。 该系统不再直接从问题跳转到答案,而是构建一个逻辑树。
- 根节点: 假设 (我们想要证明的答案) 。
- 分支节点: 更小、更简单的子假设。
- 叶节点: 在视频或成绩单中直接找到的原子证据。
如果叶节点为真,它们就“蕴涵” (逻辑上证明) 了分支节点,进而分支节点蕴涵了根假设。
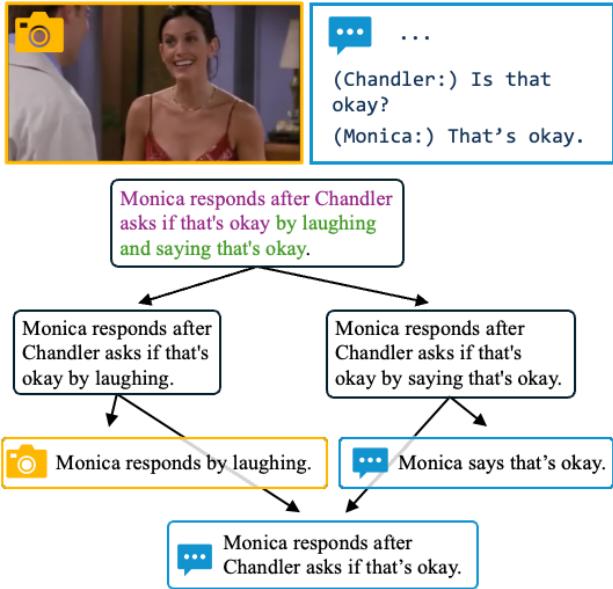
如 图 1 所示,在观看《老友记》的一个场景时,模型不仅仅是猜测“莫妮卡通过大笑来回应”。它通过找到她微笑的具体帧和她说话的具体台词来证明这一点。
它是如何工作的: 流水线
TV-TREES 是一种递归搜索算法。它的行为就像通过侦探破案: 它寻找证据,如果证据太复杂,它就将问题分解为更小、可解决的部分。
该架构分为三个主要模块: 检索、过滤和分解 。
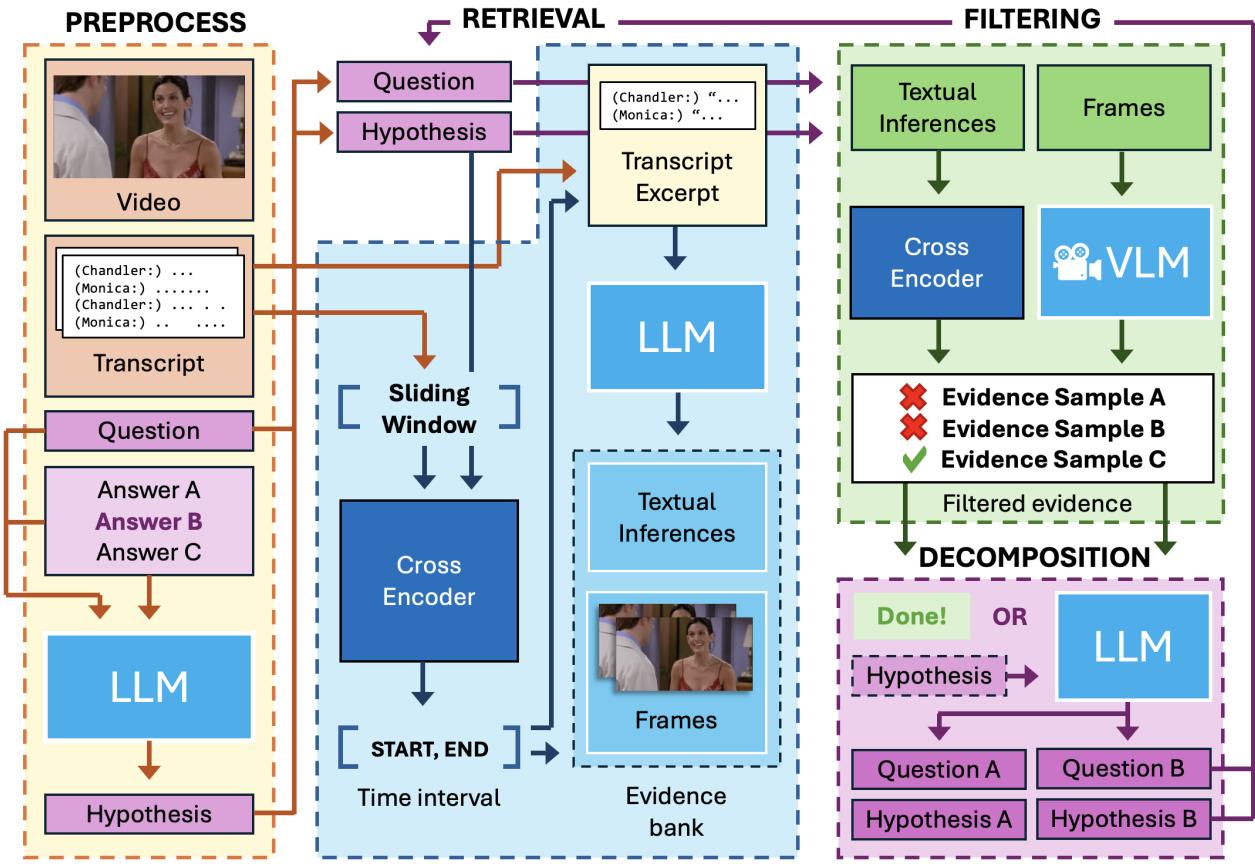
让我们分解 图 2 中展示的流水线:
1. 预处理和假设生成
过程始于一个问题和一个候选答案。系统将这对问答转换为一个单一的陈述句,称为 假设 (Hypothesis) 。
例如:
- *问题: * “莫妮卡如何回应?”
- *答案: * “她笑了。”
- *假设: * “莫妮卡通过大笑来回应。”
然后,系统定位视频和成绩单中的相关时间窗口,以集中搜索。
2. 检索: 寻找事实
系统需要证据。然而,原始对话往往是混乱的,充满俚语,或依赖于上下文。现有的逻辑模型难以处理原始脚本。
为了解决这个问题,TV-TREES 使用 GPT-3.5 生成“原子推论”——从成绩单中提取的简单、独立的用语。
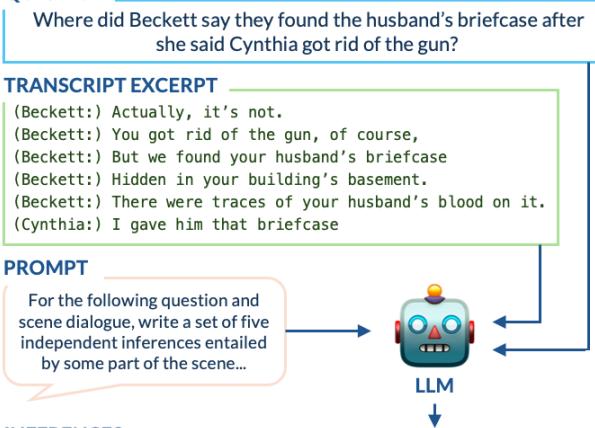
在 图 3 中,你可以看到这一过程。模型读取了一段关于“丈夫的公文包”的复杂互动,并提取了清晰的事实,如*“在公文包上发现了丈夫的血迹。”* 这些简单的句子比原始对话更容易验证。
3. 过滤: 检查事实
仅仅因为模型生成了推论并不意味着它们是有用的。 过滤 模块检查两件事:
- 相关性: 这个事实真的有助于证明我们的假设吗?
- 真实性: 这个事实真的有视频或文本支持吗?
系统使用特定的“交叉编码器 (Cross-Encoder) ”模型 (经训练用于判断两个句子之间关系的模型) 来过滤掉不相关或幻觉产生的信息。
4. 视觉推理
如果文本不够用,TV-TREES 会查看视频。它使用一个视觉语言模型 (VLM) ,具体来说是 LLaVA-7B。它向 VLM 询问关于特定帧的是/否问题。
至关重要的是,为了防止模型瞎猜,研究人员指示 VLM 如果不确定则回答“信息不足”。这种保守的方法有助于减少幻觉——这是人工智能经常“看”到不存在东西的一个常见问题。
5. 分解: 递归的魔法
这是最关键的一步。如果系统试图寻找证据证明“莫妮卡很生气”,但找不到任何明确说明这一点的句子或图像,会发生什么?
系统执行 分解 (Decomposition) 。 它使用大语言模型 (LLM) 将高层假设分解为两个更简单的子假设。
- *高层假设: * “莫妮卡很生气,因为钱德勒开了一个玩笑。”
- *分解 1: * “钱德勒开了一个玩笑。”
- *分解 2: * “莫妮卡看起来很生气。”
然后系统对这两个新子假设重新启动整个过程 (检索和过滤) 。它继续这种递归,直到触及可以通过一行文本或一个视频帧直接证明的“原子”事实,或者直到达到最大深度 (通常是 3 层) 。
评估逻辑
我们如何知道一棵蕴涵树实际上是“好”的?研究人员认为,简单的准确率 (是否得到了正确答案?) 是不够的。我们需要评估 推理的质量。
他们借鉴了 非形式逻辑理论 的概念,创建了三个关键指标:
1. 可接受性 (Acceptability)
叶节点 (底层证据) 实际上是真的吗?
\[ \begin{array} { c } { { I ( h ) \in [ 0 , 1 ] \forall h \in T } } \\ { { I ( h \mid V \cup D ) = 0 \forall h \in T _ { \mathrm { l e a v e s } } . } } \end{array} \]这个方程实际上是在问: 在给定视频 (\(V\)) 和对话 (\(D\)) 的情况下,假设的概率是否很高?如果叶节点是幻觉产生的,这棵树就无法通过此检查。
2. 相关性 (Relevance)
子节点实际上与父节点相关吗?如果证据是真实的但不相关,证明就是无效的 (例如,证明“天空是蓝色的”并不能解释为什么“莫妮卡很生气”) 。
\[ \begin{array} { r } { I ( h \mid h _ { 1 } , h _ { 2 } ) < I ( h \mid h _ { 2 } ) \ \forall ( h , e ) \in T _ { \mathrm { b r a n c h e s } } } \\ { I ( h \mid h _ { 1 } , h _ { 2 } ) < I ( h \mid h _ { 1 } ) \ \forall ( h , e ) \in T _ { \mathrm { b r a n c h e s } } } \end{array} \]这个公式检查 信息增益 。 它确保结合假设 1 和假设 2 比单独使用任何一个都能让我们对父假设更有把握。
3. 充分性 (Sufficiency)
解释是否完整?如果你结合子假设,它们是否完全蕴涵了父假设?
\[ I ( h _ { 0 } \mid h _ { 1 } , h _ { 2 } ) = 0 \ \forall ( h _ { 0 } , ( T _ { 1 } , T _ { 2 } ) ) \in T . \]这个方程表明,如果我们知道子假设 (\(h_1\) 和 \(h_2\)) 为真,父假设 (\(h_0\)) 的不确定性应该为零。
通过平均这些分数,研究人员计算出每棵树的总构成分数 (\(S\)):
\[ S = \frac { 1 } { 3 } ( a + s + 0 . 5 ( d + r ) ) \]实验与结果
团队在 TVQA 上测试了 TV-TREES,这是一个包含《生活大爆炸》 (The Big Bang Theory) 、《灵书妙探》 (Castle) 和《老友记》 (Friends) 等剧集片段的挑战性数据集。
定量成功
结果令人印象深刻。如 表 1 所示,TV-TREES 优于现有的“零样本 (zero-shot) ”方法 (即未在 TVQA 训练集上专门训练过的模型) 。
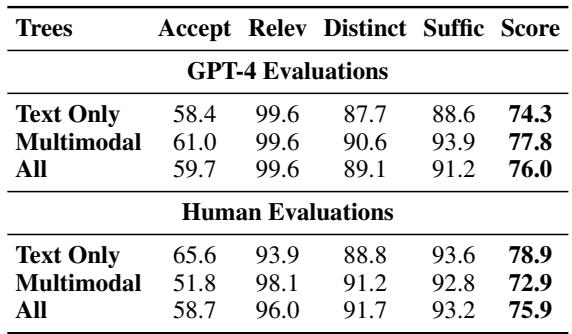
请注意,与使用完整片段的 FrozenBiLM 或 SeVILA 等标准零样本模型相比,性能有明显提升。这验证了蕴涵树“分而治之”策略的有效性。
多模态的力量
最重要的发现之一来自他们的消融实验 (移除系统的部分组件以观察结果) 。他们测试了系统仅使用文本 (对话) 和仅使用视觉的情况。
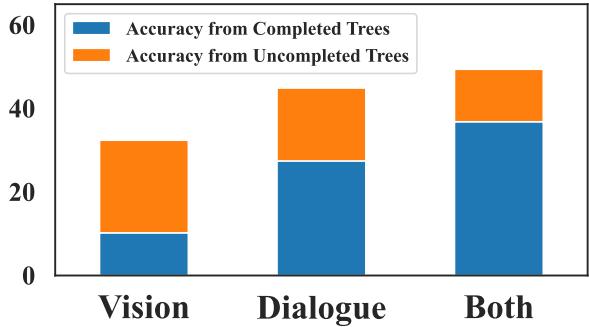
图 4 清楚地表明,“两者” (多模态) 设置表现最好。
- 仅视觉 很吃力,因为仅从像素中很难提取复杂的叙事。
- 仅对话 会遗漏物理动作和反应。
- 结合两者 , 系统可以完成更多的树并正确回答更多的问题。
“黄金标准”树
当系统运行完美时,它会产生美妙的结果: 一个完全可解释的证明。
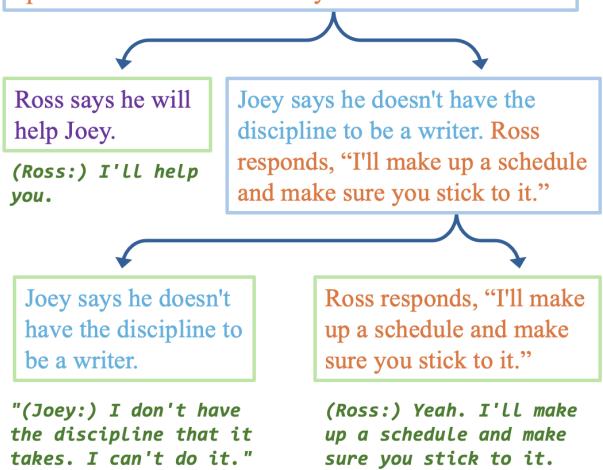
在 图 5 中,请注意系统是如何分解罗斯 (Ross) 和乔伊 (Joey) 之间复杂互动的。它将乔伊的承认 (“我没有纪律”) 与罗斯的提议 (“我会制定一个时间表”) 区分开来。它在成绩单中找到了支持每个分支的确切引语。人类看一眼就能立即验证人工智能的逻辑。
当它出错时: 失败模式
没有人工智能系统是完美的。TV-TREES 的可解释性使我们能够确切地看到它 为什么 会失败,这在黑盒模型中是不可能的。研究人员确定了几种常见的错误类型。

如 图 6 和 表 3 (下文) 所详述,最常见的错误源于视觉推理模块。
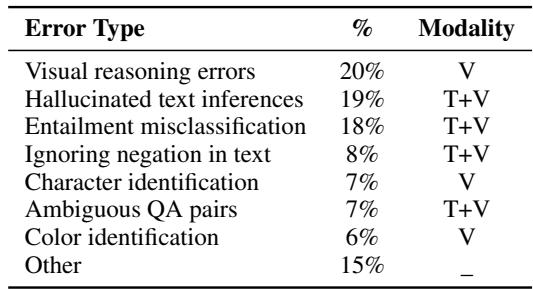
- 视觉推理错误 (20%): VLM 可能会误解手势或物体。
- 幻觉 (19%): 有时 LLM 会生成听起来合理但从未在对话中发生过的“事实”。
- 否定 (8%): 人工智能在处理“不 (not) ”这个词时很吃力。如果一个角色说“我不开心”,模型有时会因为关键词重叠而将其匹配到“开心”。
结论
TV-TREES 代表了在使人工智能具有可解释性方面迈出的重要一步。通过迫使模型通过蕴涵树“展示其工作过程”,研究人员创建了一个不仅在准确性上具有竞争力,而且在其成功和失败方面都透明的系统。
这种 神经符号 方法——结合 LLM/VLM 的生成能力与逻辑树的严格结构——提供了一种“两全其美”的解决方案。它使我们能够验证人工智能的决策,更容易地调试错误,并确信模型是基于实际证据进行推理,而不仅仅是统计噪声。
随着多模态模型的不断发展,像 TV-TREES 这样的系统对于确保我们的人工智能助手不仅聪明,而且负责任至关重要。