](https://deep-paper.org/en/paper/2403.01554/images/cover.png)
引言: 一个不断变化的世界带来的挑战
如今,大多数机器学习模型都是在静态数据集 (如 ImageNet 或维基百科) 上训练,然后作为固定系统进行部署。这种设置依赖于独立同分布 (i.i.d.) 假设 : 即认为真实世界中的数据分布与训练数据相似。但实际上,我们的世界是动态的、不断变化的。股票价格每秒都在波动,语言在持续演变,自动驾驶汽车的摄像头永远不会两次看到完全相同的场景。
一个使用去年数据训练的模型可能在几周内就会失去相关性。这时, 在线持续学习 (online continual learning) 就显得尤为重要——这是一种为连续、顺序学习而设计的范式。在这种范式中,模型一次接收一个数据样本,随时从每个实例中学习,并不断调整。其目标是在整个数据序列上最小化累积误差 , 从而在生命周期内持续学习与提升。
Transformer 已经彻底改变了对序列数据 (如文本和音频) 的深度学习方式,甚至在图像分类等非序列任务中也表现出色。它们具备执行上下文学习 (in-context learning) 的能力——即在输入的上下文中学习新任务,使其极具灵活性。但这些特性是否能扩展到在线持续学习领域?
研究论文 Transformers for Supervised Online Continual Learning 正是对此进行了探讨。作者提出了一种混合方法,将 Transformer 快速的上下文适应能力与基于梯度的渐进式长期学习相结合。他们的研究成果在一个复杂而现实的基准测试上取得了显著提升,展示了 Transformer 如何能够“永不止步地学习”。
背景: 两种学习模式
要理解这项研究的核心思想,首先需要了解在线持续学习的机制以及 Transformer 学习的双重属性。
在线持续学习: 边走边学
设想一个连续的数据点序列 \((x_1, y_1), (x_2, y_2), \dots, (x_T, y_T)\)。在每个时间步 \(t\),模型必须:
- 接收一个输入 \(x_t\)
- 做出预测 \(\hat{y}_t\)
- 观察真实标签 \(y_t\)
- 根据预测计算损失
- 在处理 \(x_{t+1}\) 之前更新参数
与传统训练不同,模型不会重新访问过去的数据。它必须在保持已学知识的同时适应新信息。这种方法直接衡量模型最小化累积预测误差的能力,并奖励其快速适应与抵抗灾难性遗忘 (即神经网络在学习新任务时遗忘旧知识的倾向) 。
Transformer: 上下文学习 vs. 权重学习
Transformer 凭借其注意力机制在序列建模中表现卓越,该机制能在处理上下文时有选择地关注相关令牌。这让 Transformer 能够进行上下文学习 (in-context learning) ——一种基于输入的临时学习。例如,一个预训练的 Transformer 只需看到几个示例对,就能立即执行英法翻译,而无需更新其参数。
这种短暂学习能力与权重学习 (in-weight learning) 形成对比,后者通过跨越大量样本的梯度下降实现缓慢的参数化学习。权重学习在模型参数中存储通用知识,而上下文学习则依赖于当前上下文表示的动态作用。
本研究的目标是结合这两种学习方式 :
- 上下文学习 : 快速适应短期变化。
- 权重学习 : 通过持续的梯度更新实现长期巩固与稳定。
核心方法: 混合式 Transformer 学习器
提出的方法对 Transformer 进行了修改,使其能够实现在线学习,同时结合上下文条件和梯度下降的权重更新。作者探索了两种面向序列监督预测的主要架构变体。
两种用于在线预测的架构
双令牌 (2-Token) 方法 在这种配置中,每个输入-标签对 \((x_t, y_t)\) 由两个连续的令牌表示。Transformer 处理完整的序列 \(x_1, y_1, x_2, y_2, \dots\),忽略 \(x_t\) 令牌的损失,仅训练模型预测对应的 \(y_t\)。 这种结构简单而有效,将监督学习自然地转化为序列建模问题。
特权信息 (pi) Transformer pi-transformer 对标准 Transformer 模块进行了修改。每个输入图像 \(x_t\) 作为一个令牌输入,其对应标签 \(y_t\) 提供了额外的特权信息,影响注意力机制。标签的投影被添加到键 (keys) 和值 (values) 中,但不添加到查询 (queries) 。 重要的是,一个对角线为零的注意力掩码会阻止模型在时间步 \(t\) 访问自己的标签,从而确保因果预测,同时保留对所有先前标签投影 \(y_{< t}\) 的访问。
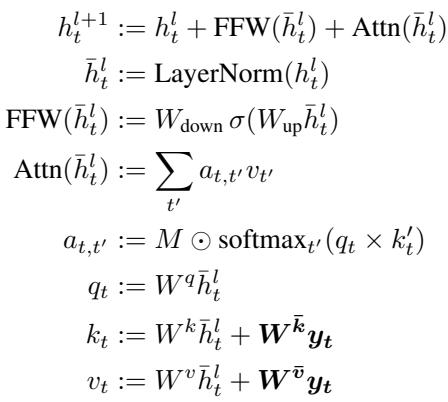
pi-transformer 通过额外的键和值投影将标签信息引入注意力机制,同时掩盖未来标签以保持序列的因果性。
训练: Transformer-XL 与重放流结合
在连续数据流上进行训练计算量很大,尤其是当数据量达到数千万时。研究人员采用了 Transformer-XL 风格的方法 (Dai 等人,2019) ,将训练拆分为较小的顺序片段 (如 100 个令牌) 。与此同时,通过 KV-cache 机制,注意力模块可以关注更大的窗口 (如 1024 个令牌) ,在不显著增加计算成本的前提下保留长期上下文。
为了保持流学习的效果,作者引入了重放流 (replay streams) ——这是对经验重放的创新改编。模型同时在多个并行“数据流”上训练:
- 流 0 按时间顺序处理新数据,并用于性能评估。
- 其他流 则随机重置到较早的位置,重放旧数据。
这种随机重放有效模拟了多轮 (multi-epoch) 学习,同时保持时间顺序一致性。它促使模型构建能在当前和过去上下文中都表现良好的参数,与元学习原理高度契合。
实验: 从玩具世界到真实数据
作者在两种主要场景中验证了方法: 合成的分段平稳数据集与真实的大规模持续学习基准。
玩具数据: Split-EMNIST
为了观察模型的适应行为,作者使用了 Split-EMNIST 数据集,它被分为 100 个任务。每个任务随机将 10 类图像映射到 10 个标签。当新任务开始时,映射关系会完全改变——造成突发的分布偏移。
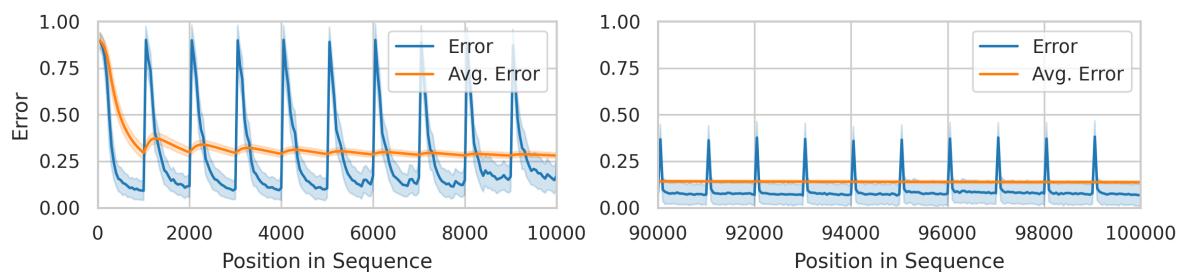
图 1: 预测误差在任务边界处激增,但很快稳定,显示模型能在标签映射突然变化后快速适应。
随着时间的推移,模型从早期任务中的困难逐渐过渡到后期任务的优异表现。
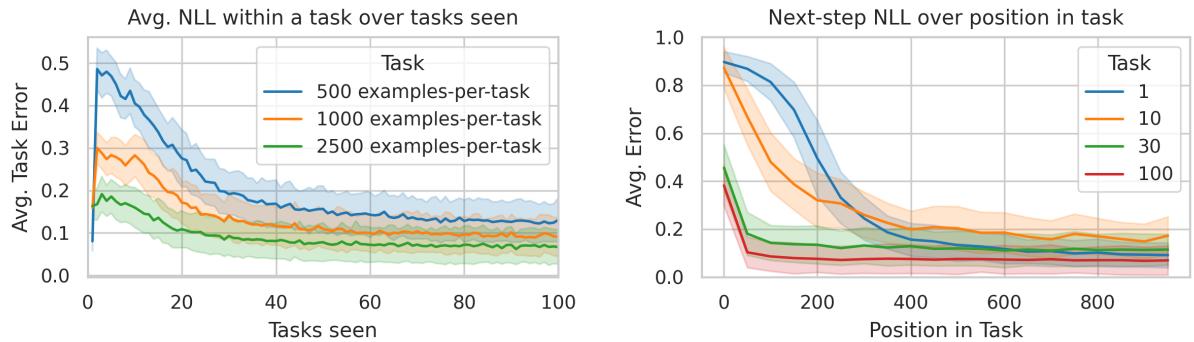
图 2: 随着 Transformer 不断“学会学习”,任务间的性能稳步提升——在约 30 个任务后展现出小样本适应能力。
重放机制在此起到了关键作用。没有重放时,模型性能会急剧下滑,如下图所示。
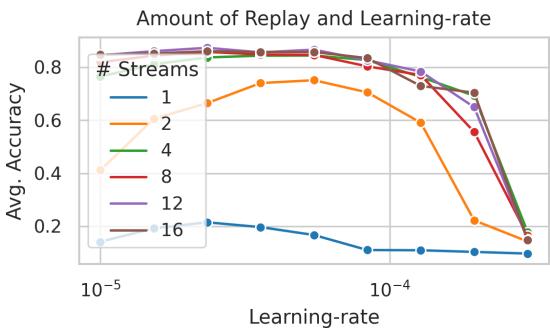
图 3: 重放流通过重访过去序列,使在线模型达到稳定且高准确率的表现。
该实验揭示了元学习行为的出现——模型学会了在任务内分布变化时高效适应。
真实世界基准: CLOC 数据集
最终测试使用了 CLOC (Continual Localization) 数据集,包含约 3700 万张按时间顺序排列的图像,这些图像按地理位置标注。数据高度非平稳,体现了自然的时间与空间漂移。本任务要求模型具备极佳的泛化与适应能力。
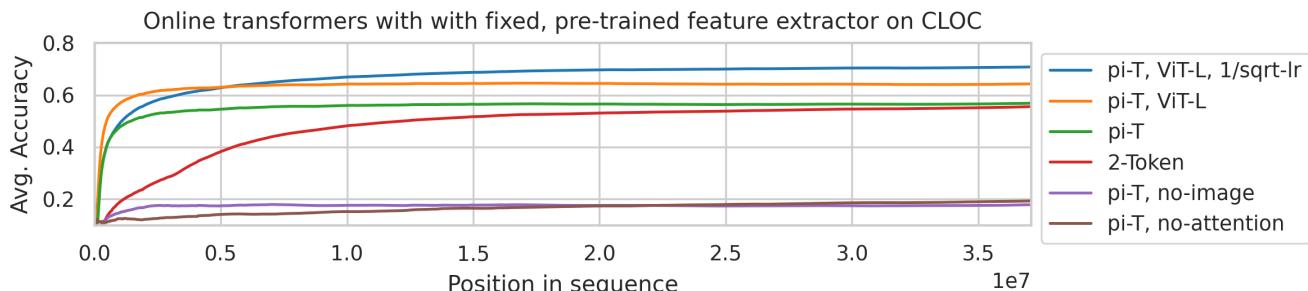
图 4: 在使用预训练特征的 CLOC 任务上,pi-transformer 达到了近乎之前最佳两倍的准确率。
结果总结
| 方法 | 预训练 | 微调 | 平均准确率 |
|---|---|---|---|
| Experience Replay (Cai et al., 2021) | ✓ | ✓ | 20% |
| Approx. kNN (Prabhu et al., 2023) | ✓ | - | 26% |
| Replay Streams (Bornschein et al., 2022) | ✓ | - | ~38% |
| Kalman Filter (Titsias et al., 2023) | ✓ | - | 30% |
| 我们的 pi-Transformer (ResNet 特征) | ✓ | - | 59% |
| 我们的 pi-Transformer (MAE ViT-L 特征) | ✓ | - | 70% |
| 我们的 Transformer (从零开始学习) | - | ✓ | 67% |
性能飞跃十分显著——尤其在采用现代预训练特征 (如 MAE ViT-L) 时,pi-transformer 大幅超越此前方法。
剖析学习动态
1. 上下文 vs. 权重学习的贡献
为了评估两种学习机制的作用,作者在处理一定数量样本后冻结模型权重,从而强制模型仅依赖上下文学习。
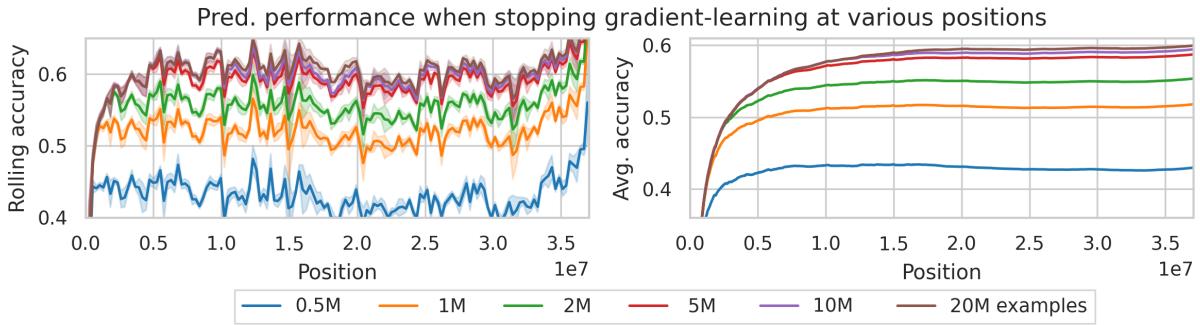
图 5: 即便处理数百万样本后,基于梯度的权重学习仍在持续带来性能提升。
两者均有显著贡献: 上下文学习应对即时变化,而梯度更新确保长期稳定。
2. 超参数影响
更大的注意力窗口 (\(C\)) 与更多的重放流均能带来更好结果。
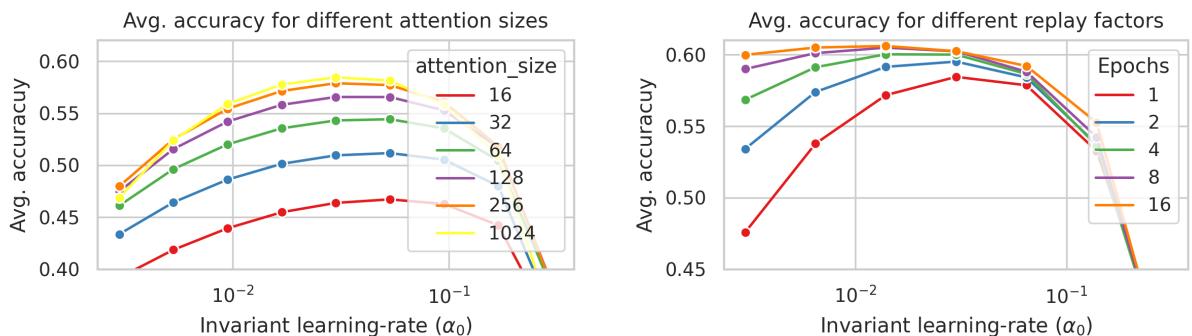
图 6: 注意力大小与重放数量共同影响模型的稳定性与预测性能。
3. 从零开始训练
当模型从零开始训练 (同时学习特征提取器与 Transformer) 时,依然保持竞争力,达到约 67% 的准确率,几乎媲美预训练版本。
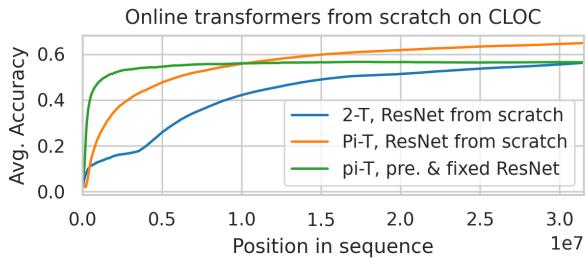
图 11: 从零开始训练的模型性能几乎与基于预训练特征的模型相当。
4. pi-Transformer vs. 双令牌模型
两种架构展现出不同的学习动态。双令牌模型出现离散阶跃——可能与归纳头 (induction head) 的形成相关——而 pi-transformer 则表现出平滑改进。
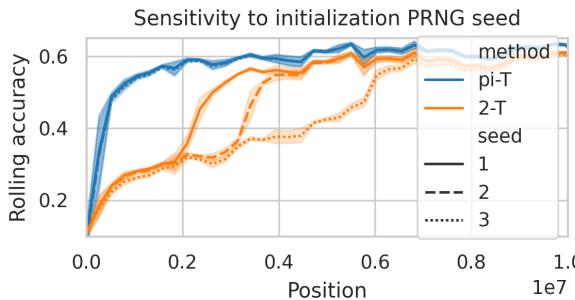
图 8: pi-transformer 学习过程更稳定,而双令牌变体则经历明显的性能突变,可能反映了归纳头的涌现。
5. 效率比较
研究团队还分析了计算成本与准确率之间的权衡,绘制帕累托前沿。
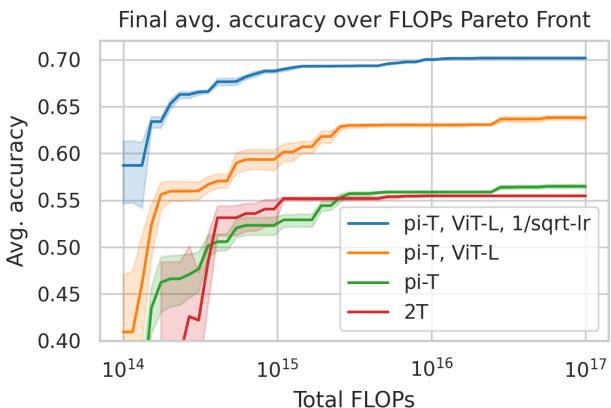
图 7: 帕累托分析显示,两种架构在宽范围的计算量下均具出色效率。
结论与展望
本研究表明,Transformer 的确能够有效实现监督式在线持续学习 。 通过结合短期上下文适应与长期权重优化,所提出的方法在合成与真实任务上都达到了当前最优的表现。
主要结论如下:
- 混合学习有效 : 快速上下文适应与缓慢参数学习的结合能构建强大的持续学习模型。
- 架构创新 : pi-transformer 提出了一种在遵循因果约束的同时融合标签信息的原则性设计。
- 重放机制至关重要 : 多流重放在严格顺序数据流中高效模拟多轮训练。
- 可扩展与鲁棒 : 该方法在处理大规模数据 (数千万样本) 和多样超参数时依然表现稳定。
总体而言,这项研究弥合了大型 Transformer 涌现的元学习能力与应对非平稳序列数据学习挑战之间的差距,为构建能够持续学习与改进的自适应人工智能系统铺平了道路,真正拥抱了现实世界信息不断变化的本质。