](https://deep-paper.org/en/paper/2403.02281/images/cover.png)
引言: “情感大杂烩”
想象一下你今天过得很糟糕。当朋友问你感觉如何时,你会怎么说?你会回答因为项目停滞而感到“沮丧”,因为即将到来的截止日期而感到“焦虑”,还是对同事感到“失望”?或者,你只是简单地说感觉“很糟”或“压力很大”?
这种区别——即识别并具体标记情绪的能力——正是心理学家所称的情绪粒度 (Emotion Granularity, EG) 。
拥有高情绪粒度的人是情感专家。他们以高清模式体验世界,能清晰区分愤怒、悲伤和恐惧等截然不同的感受。相反,情绪粒度低的人体验到的情绪是模糊的——就像一种“情感大杂烩”,所有的负面感受都混杂成一种笼统的不适感。
这有什么重要的?几十年来,心理学研究表明,高情绪粒度是心理健康的超能力。如果你确切地知道自己的感受,你就知道如何调节它。你会用自我关怀来处理“悲伤”,用冲突解决策略来应对“愤怒”。如果你只是感觉“很糟”,你可能会诉诸适应不良的应对机制,如药物滥用或攻击行为。
直到现在,测量情绪粒度仍需要繁琐的“经验采样”方法——要求人们连续几周每天多次填写问卷。但是,如果我们仅仅通过分析我们在网上输入的文字就能测量这种心理特征呢?
在研究论文 《从文本看情绪粒度: 心理健康的群体层面指标》 (Emotion Granularity from Text: An Aggregate-Level Indicator of Mental Health) 中,来自多伦多大学、Vector Institute 和北卡罗来纳大学教堂山分校的研究人员提出了一种新颖的计算方法来实现这一目标。他们分析社交媒体的时间线,看看我们情感语言的“分辨率”是否可以作为心理健康状况的指标。
背景: 从心理学到自然语言处理
在深入探讨算法之前,我们需要了解心理学基础。在情感科学中,粒度的测量通常是通过要求人们反复评估各种情绪 (如愤怒、恐惧、快乐) 的强度来进行的。
如果一个人每次被问到时,对“愤怒”和“悲伤”的强度评分总是一样的,那么他们本质上是将这些词视为同义词。他们的粒度很低。如果对“愤怒”和“悲伤”的评分独立变化——意味着他们有时感到愤怒但并不悲伤,反之亦然——他们的粒度就很高。
历史上,心理健康领域的自然语言处理 (NLP) 主要集中在情感分析 (这段文字是积极的还是消极的?) 或流行度 (这个人说“悲伤”的频率有多高?) 。虽然有用,但这些指标忽略了情绪之间的结构关系。
这篇论文背后的研究人员认为,重要的不仅仅是你表达了多少悲伤,而是这种悲伤与其他负面情绪有多大的区别。他们假设我们可以通过分析用户社交媒体帖子的时间序列来估算情绪粒度。
数据: 在社交媒体上挖掘心理健康信息
为了验证这一假设,作者需要一个庞大的数据集,其中包含已知的心理健康状况 (MHC) 个体以及作为对比的对照组。他们使用了两个主要数据集:
- Twitter-STMHD: 一个通过严格的正则表达式和人工验证,识别出自我披露诊断结果 (例如,“我被诊断出患有双相情感障碍”) 的用户数据集。
- Reddit eRisk: 一个包含自我披露抑郁症的用户数据集,用于早期风险预测任务。
数据规模非常大。如下方表 1 所示,该研究涵盖了心理健康状况 (MHC) 组中近 20,000 名用户,诊断范围包括多动症 (ADHD) 、焦虑症、双相情感障碍、重度抑郁症 (MDD) 、强迫症 (OCD) 、产后抑郁症 (PPD) 和创伤后应激障碍 (PTSD) 。
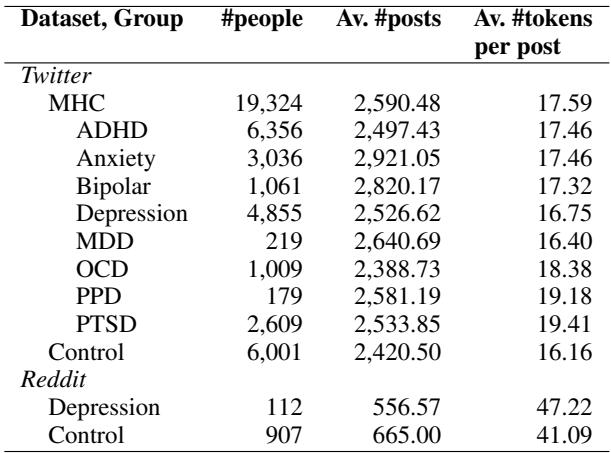
研究人员进行了严格的预处理。他们过滤掉了转推以专注于原创内容,删除了包含 URL 的帖子 (通常缺乏上下文) ,并排除了发帖数过少无法形成可靠时间线的用户。这确保了分析侧重于个人真实、长期的声音。
方法论: 构建情绪弧线
这是论文的核心创新点。如何将一系列推文转化为“情绪粒度”的数学评分?该过程包括三个主要阶段: 情绪评分、弧线构建和粒度计算。
1. 使用词典进行情绪评分
研究人员使用了 NRC 情绪强度词典 (NRC Emotion Intensity Lexicon) , 该词典将大约 10,000 个英语单词与八种情绪的实数值 (0 到 1) 关联起来: 愤怒、期待、厌恶、恐惧、快乐、悲伤、惊讶和信任 。
然而,社交媒体语言是独特的。像 “shook” 这样的词在字典里可能意味着“摇晃”,但在 Twitter 上可能意味着“惊讶/震惊”。为了使工具稳健,研究人员整理了一份特定领域的停用词列表——这些词在标准英语中有情绪关联,但在网络上使用方式不同或过于通用。

如表 3 所示,像 “chaotic evil” (一种迷因格式) 或像 “vibe” 这样的粘合词被移除以防止噪音。他们还移除了明确的心理健康术语 (如 “anxiety”、“depression”) ,以便模型检测潜在的情绪模式,而不仅仅是识别诊断关键词。
2. 构建情绪弧线
一旦文本被清理,推文将按时间顺序排列。然后,研究人员计算每个话语 (推文) 或单词窗口的“情绪得分”。
通过将这些分数随时间绘制出来,他们创建了情绪弧线 (Emotion Arcs) 。 情绪弧线代表了特定情绪在用户时间线上的波动强度。

图 1 完美地展示了这一概念。蓝线追踪“愤怒”,橙线追踪“恐惧”,展示了一名用户在大约 120 条推文中的变化。
- 观察模式: 在某些地方,蓝色和橙色的峰值同时出现。在其他地方,它们分道扬镳。这两条线之间的关系正是定义粒度的关键。
3. 计算粒度: 反向相关性
这是研究的数学关键。为了测量粒度,研究人员计算了情绪弧线对之间的 斯皮尔曼相关系数 (Spearman correlation) 。
- 高相关性: 如果“愤怒”弧线和“悲伤”弧线总是同时上下波动,则相关性很高。这意味着用户在共同表达这些情绪。用心理学术语来说,这就是低粒度 。
- 低相关性: 如果弧线是独立的,则相关性很低。这意味着用户区分了这些情绪。这就是高粒度 。
因此,情绪粒度 (EG) 的计算指标定义为相关性的负值 。
\[ \text{Emotion Granularity} \approx -1 \times \text{Correlation(Emotion A, Emotion B)} \]研究人员针对不同的分组计算了这一指标:
- EG(pos): 积极情绪 (快乐与信任) 之间的粒度。
- EG(neg): 消极情绪 (愤怒、恐惧、悲伤、厌恶) 之间的粒度。
- EG(overall): 所有相同效价配对的平均值。
关键对照实验: 仅仅是词汇量的问题吗?
怀疑论者可能会问: “也许患有心理健康疾病的人只是总体上使用的语言更简单?也许他们不知道那些具体的词汇?”
为了排除这一点,作者进行了一项测量术语具体性 (Term Specificity) 的对照实验。他们使用 WordNet 层级结构计算了 MHC 组和对照组使用的名词和动词的“信息量”。
结果如何? 没有显著差异。 MHC 组的用户并未比对照组使用更通用的名词或动词。这证实了观察到的情绪表达差异并非源于一般语言的简单性——它们特异于情绪的体验和处理方式。
结果: 心理健康的特征
研究结果提供了令人信服的证据,表明基于文本的情绪粒度是心理健康的生物社会标记。
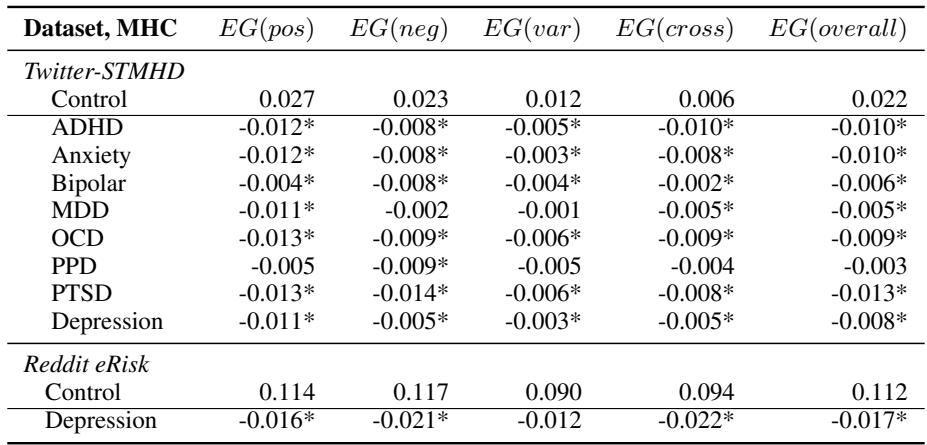
研究人员比较了 MHC 组与对照组的 EG 分数。如下方表 2 总结的那样,对比鲜明。
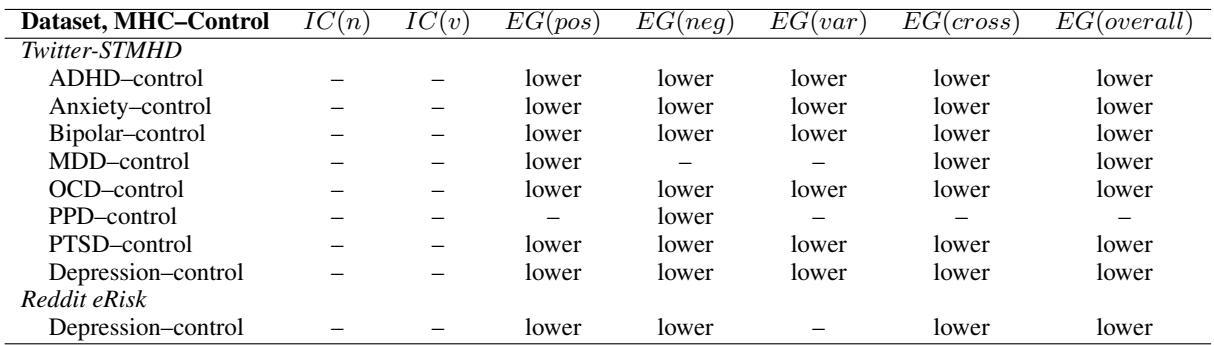
1. 消极情绪粒度 (EG neg)
这是历史上最重要的指标。如表所示,与对照组相比,几乎每种心理健康状况的 EG(neg) 都显著较低 (由单词 “lower” 表示) 。
- ADHD、焦虑、双相、抑郁、强迫症、PTSD: 所有这些群体在区分愤怒、恐惧和悲伤等负面情绪方面的能力都表现出下降。
- 含义: 这些用户在统计上更有可能成群地表达负面情绪。当他们发布关于悲伤的内容时,他们很可能同时将其描述为愤怒和恐惧。
2. 积极情绪粒度 (EG pos)
有趣的是,这种模式也适用于积极情绪。患有焦虑症、多动症、强迫症和抑郁症的用户在快乐和信任之间表现出显著较低的粒度。这表明,在心理健康状况中情绪状态的“模糊化”并不局限于糟糕的感觉——它也影响积极体验的处理。
3. 整体及跨效价粒度
EG(overall) 列作为底线指标: 总体而言 (此特定表中产后抑郁症除外) ,患有 MHC 的个体具有较低的总体情绪粒度。
EG(cross) 列测量对立情绪 (例如,快乐与悲伤) 之间的关系。这里的分数较低表明 MHC 用户更有可能同时表达积极和消极情绪——这种现象被称为辩证性 (dialecticism) 。 虽然解释起来很复杂,但这进一步突显了与对照组截然不同的情绪处理风格。
发现的稳健性
为了确保这些结果不仅仅是特定窗口大小 (一次查看一条推文) 的偶然现象,研究人员使用更大的滑动窗口 (100 个词和 500 个词) 重复了实验。
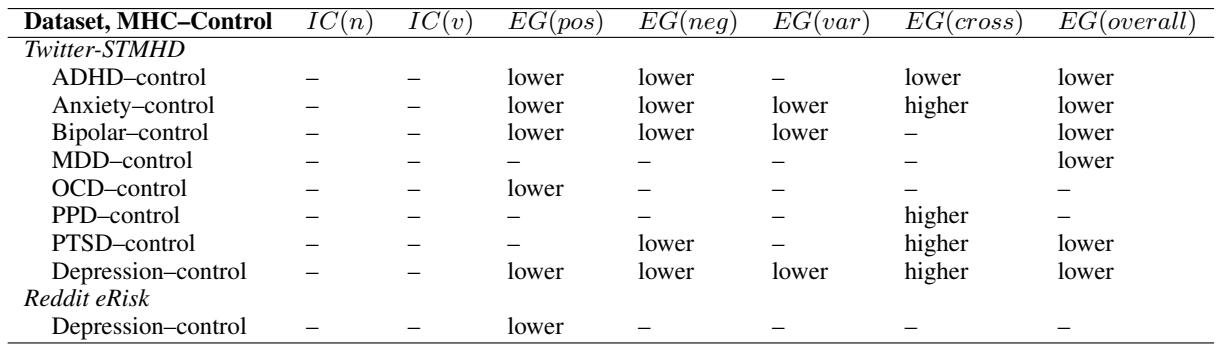
如表 9 (使用 500 词窗口) 所示,趋势基本保持一致。ADHD、焦虑、双相和抑郁组继续显示出显著较低的粒度。这证实了无论你是看单条推文还是更广泛的意识流,信号都是存在的。
深入挖掘: 哪些情绪混淆在一起?
研究人员并没有止步于总分。他们按具体的情绪配对分解了相关性,以确切查看区分是在哪里失效的。
表 10 提供了对这些配对的细致 (双关语) 观察。
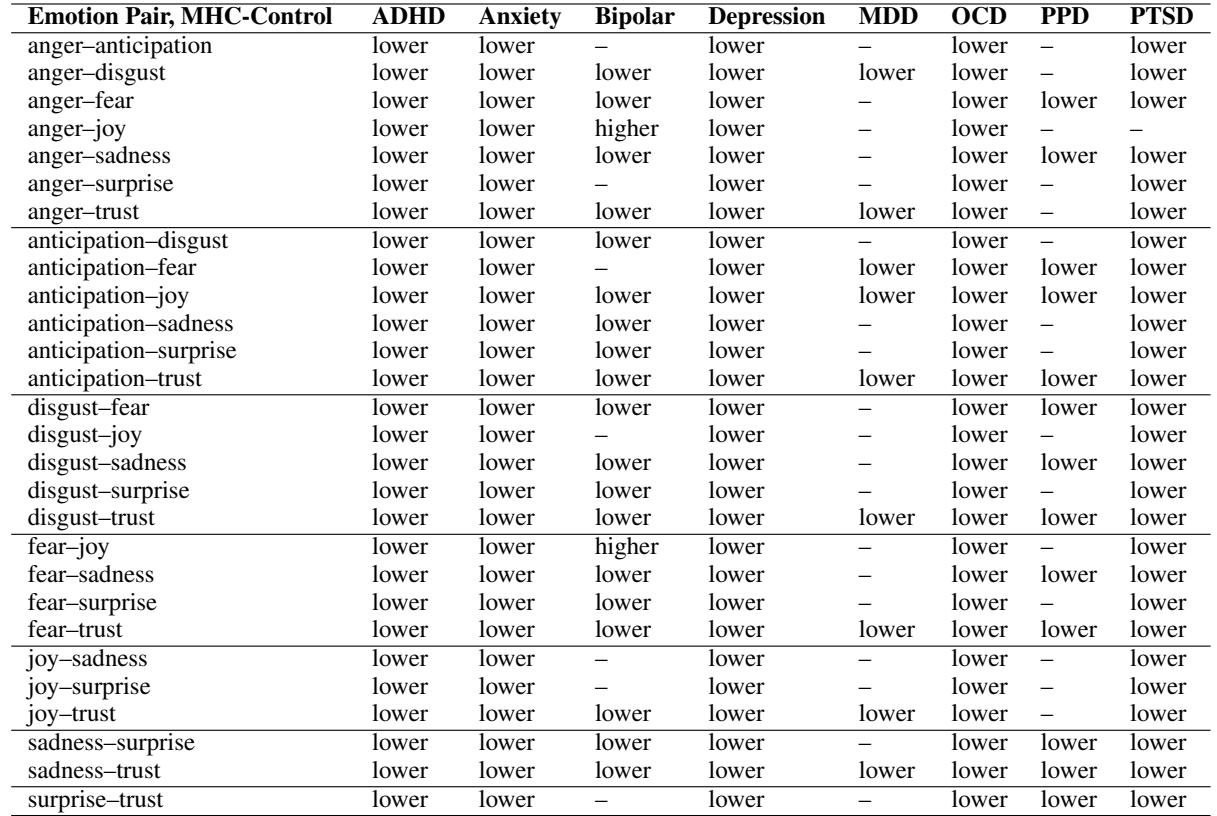
关键观察:
- 愤怒-悲伤 (Anger-Sadness): 这一配对在几乎所有状况下 (ADHD、焦虑、双相、抑郁、强迫症、PTSD) 粒度都较低。这是适应不良调节的典型指标——混淆了愤怒的高唤醒状态与悲伤的低唤醒状态。
- 焦虑与抑郁: 这些群体在几乎每一对配对中都显示出“更低”的粒度。情绪图谱被高度压缩。
- 双相情感障碍的异常: 请看双相组的 愤怒-快乐 (Anger-Joy) 和 恐惧-快乐 (Fear-Joy) 行。它们被标记为“higher” (更高) 。这表明双相情感障碍用户实际上比对照组更多地区分这些跨效价情绪。这与双相情感障碍的临床理解一致,其特征是明显的、循环的躁狂 (快乐) 和抑郁阶段,而不是两者的浑浊混合。
为了可视化这些差异的幅度,我们可以查看表 12 中的原始相关系数。
“Control” (对照组) 行显示了基准相关性。下方的行显示了增量 (差异) 。
- 注意各疾病中 EG(neg) 和 EG(pos) 的负值。
- 由于粒度是相关性的负值,此表中的负增量意味着 MHC 组的相关性更高,证实了他们的粒度确实更低。
结论与未来展望
这项研究标志着计算语言学和数字健康领域迈出了重要一步。通过超越简单的情感分析,作者成功地仅利用社交媒体文本就将一个复杂的心理学构念——情绪粒度——进行了操作化。
研究表明:
- 文本反映心理: 我们在 Twitter 和 Reddit 上构建情感语言的方式反映了临床环境中观察到的情绪分化模式。
- 粒度是一种标记: 较低的情绪粒度是多种心理健康状况 (特别是抑郁和焦虑) 的强有力的群体层面指标。
- 它是结构性的: 差异在于情绪词汇之间的关系,而不仅仅是词汇量的大小。
这对未来意味着什么? 虽然作者强调这不是针对个人的诊断工具 (出于道德和准确性的考虑,你不能根据推文诊断单个用户) ,但它为群体层面的心理健康监测提供了一个强有力的视角。公共卫生官员可能会追踪社区的“情绪分辨率”,以便在精神困扰转化为危机统计数据之前识别出上升的趋势。
此外,它也为治疗干预打开了大门。如果在文本中可以检测到低粒度,也许可以设计写作工具或治疗应用程序来帮助个人更好地区分他们的情绪——引导用户从“感觉很糟”转变为“对 X 感到焦虑,对 Y 感到悲伤”,从而潜在地培养粒度所提供的情绪韧性。